Amazon Web Services ブログ
OpsCenter – IT オペレーションを合理化する新機能
AWS チームは常にお客様の声に耳を傾け、お客様の生産性向上のためにどのように私たちのサービスを改善すればよいかを考えています。こうした弊社のアプローチを実証するべく、OpsCenter という AWS Systems Manager の新しい機能を開発し、お客様がサービス上での問題、イベント、アラートを一体化できるようにしました。この新機能により、1 か所にアクセスすれば問題を表示、調査、修正することが可能となり、複数の異なる AWS サービス間を移動する手間を減らしました。
問題、イベント、アラートはこの新しいコンソールに操作項目 (OpsItem) として表示され、コンテキスト情報、履歴のガイダンス、迅速な解決手順を提供します。この機能では、主要な調査データを 1 か所で入手できるようにすることで、ソリューションに到達するまでの平均時間を短縮し、エンジニアの生産性を向上させることを目的としています。
OpsItem 担当エンジニアは、次のような情報にアクセスできます。
- イベント、リソース、アカウントの詳細
- 類似の特性を持つ過去の OpsItem
- 関連する AWS Config の変更と関係性
- AWS CloudTrail ログ
- Amazon CloudWatch アラーム
- AWS CloudFormation スタック情報
- ログやメトリクスにアクセスするためのその他のクイックリンク
- Runbook と 推奨 Runbook の一覧
- AWS サービスを通じて OpsCenter に渡される追加情報
この情報はエンジニアが運用上の問題をより迅速に調査し、修正するのに役立ちます。エンジニアは OpsCenter を使うと、Systems Manager コンソールを介してまたは Systems Manager OpsCenter API を使用して問題を表示し、対処することができるようになります。
このブログの残りの部分では、この新機能について解説します。まず最初に Systems Manager コンソールを開き、ご自分が関連するリージョンにいることを確認し、画面の左端にある [Operations Management] メニュー内の [OpsCenter] をクリックします。
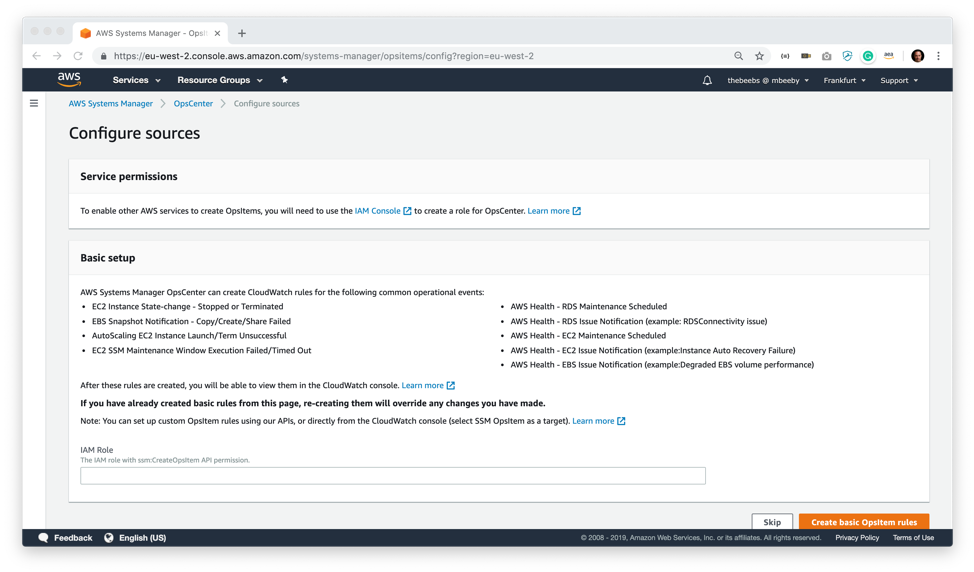
初めて OpsCenter の画面にアクセスし [Getting Started] をクリックすると、ソースの構成画面が表示されます。この画面では、特定のルールをトリガーするときに OpsItem を作成する CloudWatch ルールの例をいくつか使用して、システムを設定します。たとえばある CloudWatch ルールでは、AutoScaling EC2 インスタンスが停止または終了した場合にアラートします。この画面で、OpsItem を作成するアクセス許可を持つ IAM ロールの ARN を構成し、追加する必要があります。CloudWatch ルールがこのセキュリティロールを使って、OpsItem を作成します。もちろん、API を通じて、あるいはカスタム CloudWatch ルールを作成することでも OpsItem を作成できます。
これでシステムが CloudWatch のルールをいくつか設定しました。アラートをトリガーしてテストします。EC2 コンソールで、この AutoScaling グループに関連付けられている Amazon マシンイメージを意図的に登録解除 (削除) します。次に、AutoScaling グループの Desired Capacity を 2 から 4 に増やします。AutoScaling グループは後で新しいインスタンスを作成しようとしますが、AMI を削除したので失敗します。

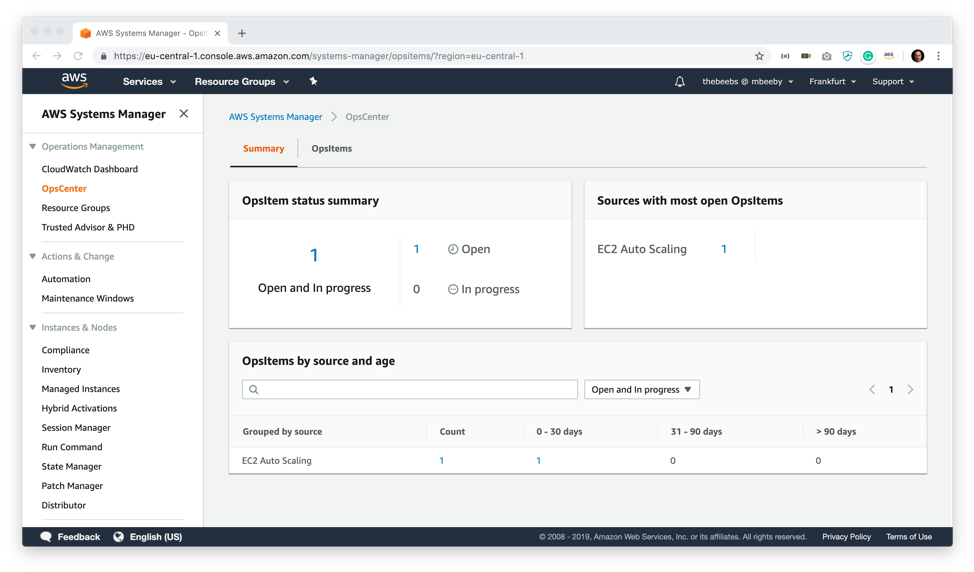
期待どおり、アラートが CloudWatch ルールをトリガーし、OpsCenter コンソールに OpsItem を作成しました。OpsItem ステータス概要ダッシュボードに、項目が 1 つ開いています。これをクリックして、開いている OpsItem の詳細を表示します。
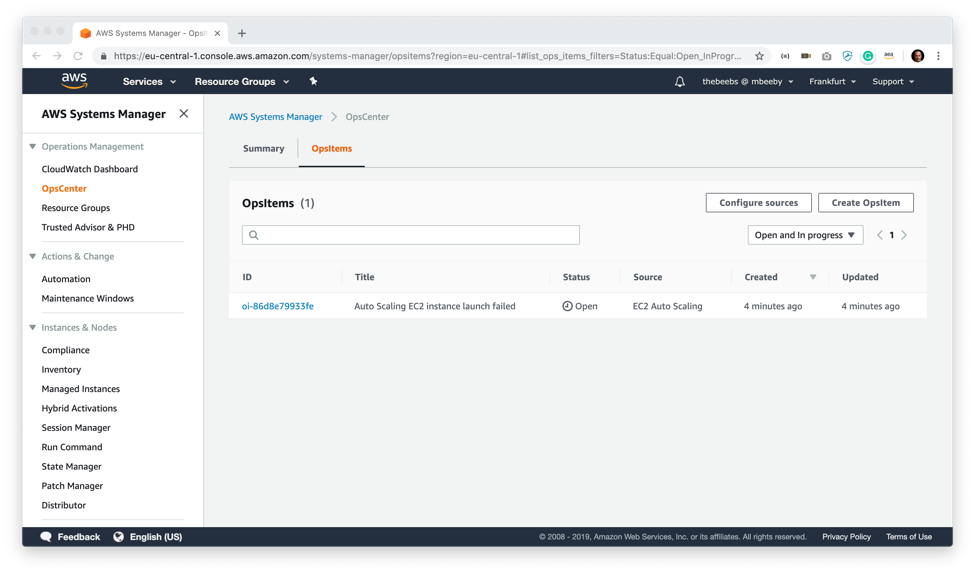
開いているすべての OpsItem のリストが表示されます。そこで、AutoScaling グループに関連付けられている AMI を削除したために CloudWatch ルールによって作成されたタイトル「Auto Scaling EC2 インスタンスの起動に失敗しました」が示されています。その OpsItems をクリックすると、OpsItem の詳細を見ることができます。
この概要画面から、項目を調べることができます。この画面から OpsItem についてさらなる情報が得ることができますが、この情報は多数のサービスからデータを収集して 1 か所に表示していることが分かります。
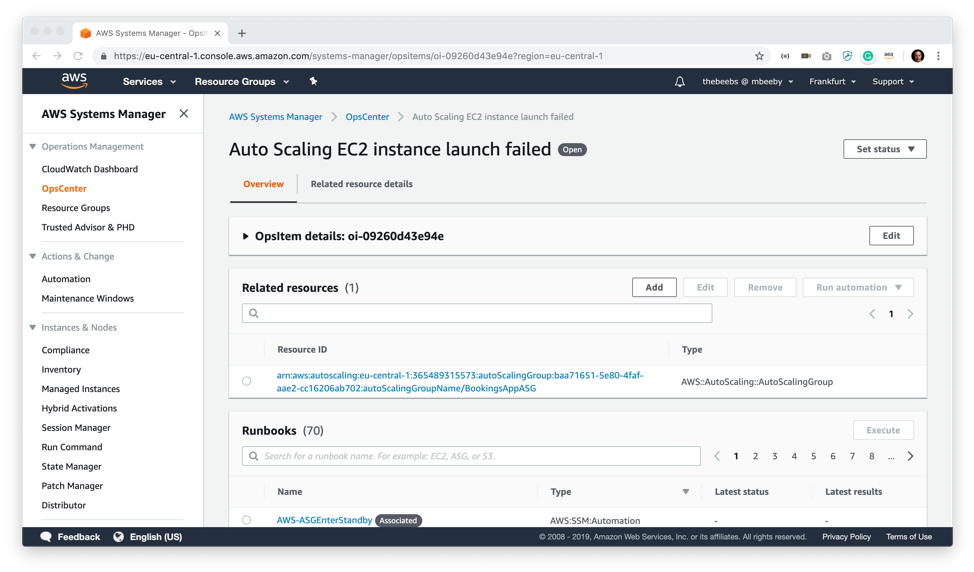
画面の下方に他にも [Similar OpsItems] があり、これらを掘り下げることができます。実際にこれで、過去に同様の問題がどのように解決されたかについてのコンテキスト情報が得られるため、オペレーションチームはこれまでの集められた経験から確実に学習できます。OpsItem に接続している場合は、OpsItem 間に手動で関係を追加することもできます。Operational data セクションに、原因に関する情報があることに注目してください。ステータスメッセージが AMI が存在しないという問題を指摘している場合、特に便利です。
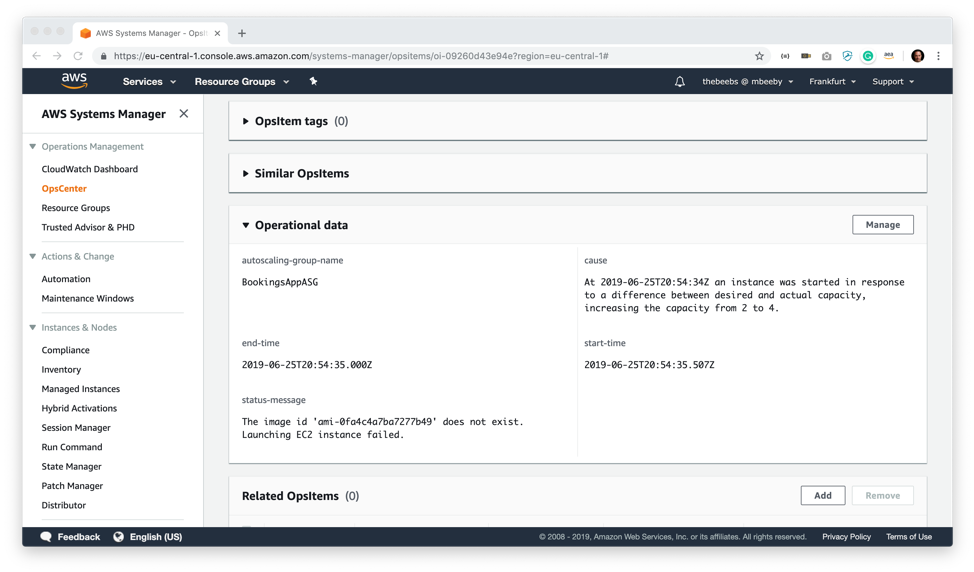
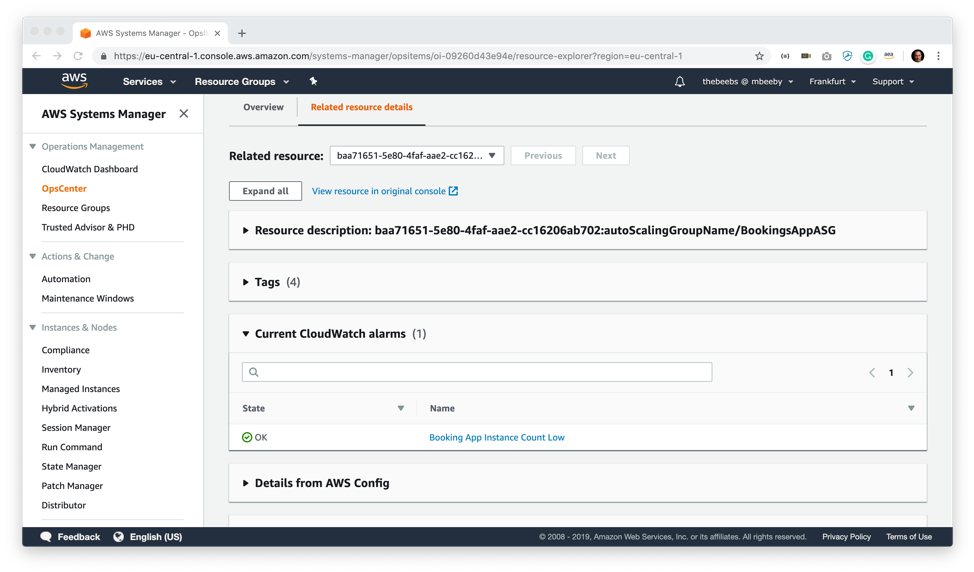
関連リソースの詳細画面で、この OpsItem に関する詳細情報を表示することができます。たとえば、関連する CloudWatch アラームとともに、リソースに関するタグ情報も見ることができます。AWS Config から詳細を調べたり、CloudTrail ログを掘り下げることも可能です。リソースが CloudFormation スタックに関連付けられているかどうかも確認できます。
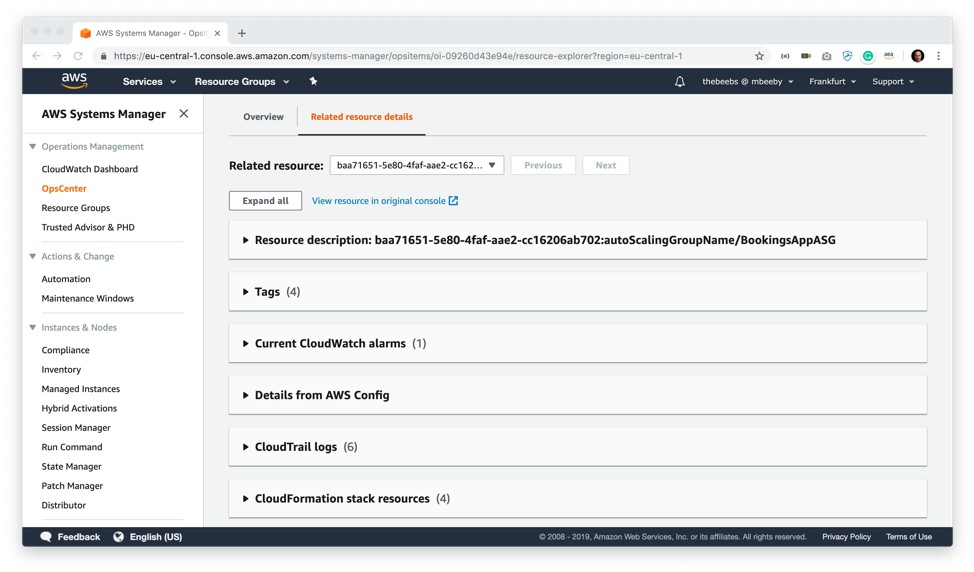
先に、AutoScaling グループのインスタンス数が目的のインスタンスしきい値 (4 つのインスタンス) を下回ったときにアラートする CloudWatch アラームを作成しました。ご覧のとおり、これを表示するのに CloudWatch コンソールにアクセスする必要はありません。この画面では [Booking App Instance Count Low] のアラーム状態を表示しています。
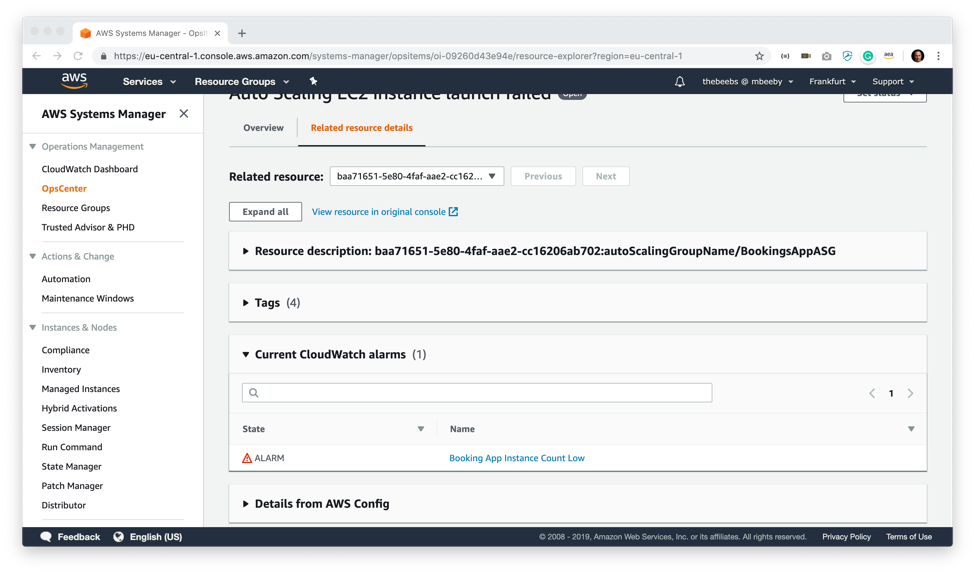
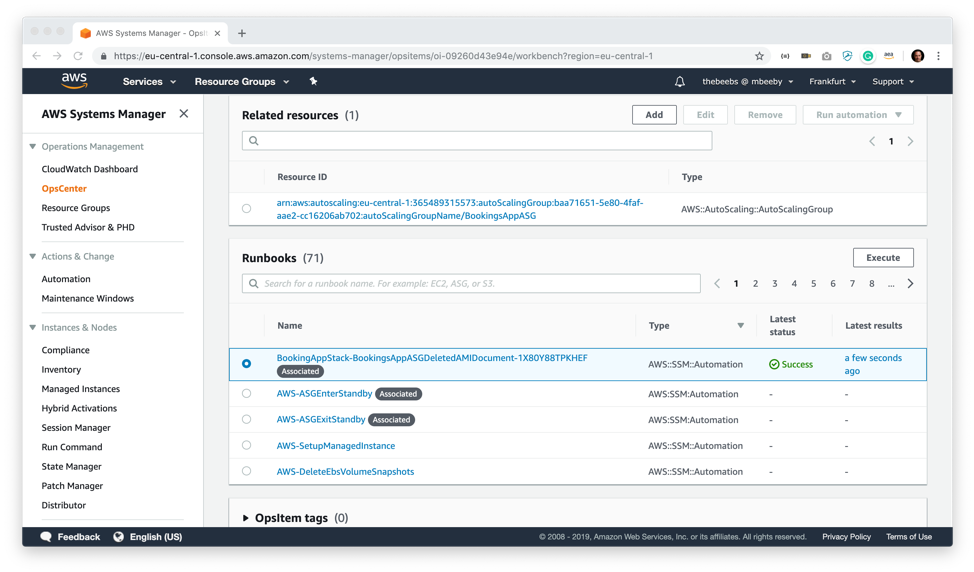
自動化した方法でこの問題を解決する Runbooks セクションも、興味をそそられるところです。ビルトインの Runbook がいくつか組み込まれていますが、幸運にも、この特定の問題に対する修正を自動化できるカスタムの Runbook がありました。AutoScaling グループ内の正常なインスタンスの 1 つに基づいて新しい AMI を作成し、インスタンスを作成するときにその新しい AMI を使用するように設定を更新します。このオートメーションを実行するには、Runbook を選択して [Execute] をクリックします。

自動化ジョブのためのパラメータをいくつか提供するように指示されます。AutoScaling グループ名 (BookingsAppASG) を唯一の必須パラメータとして貼り付けて、[Execute] をクリックします。
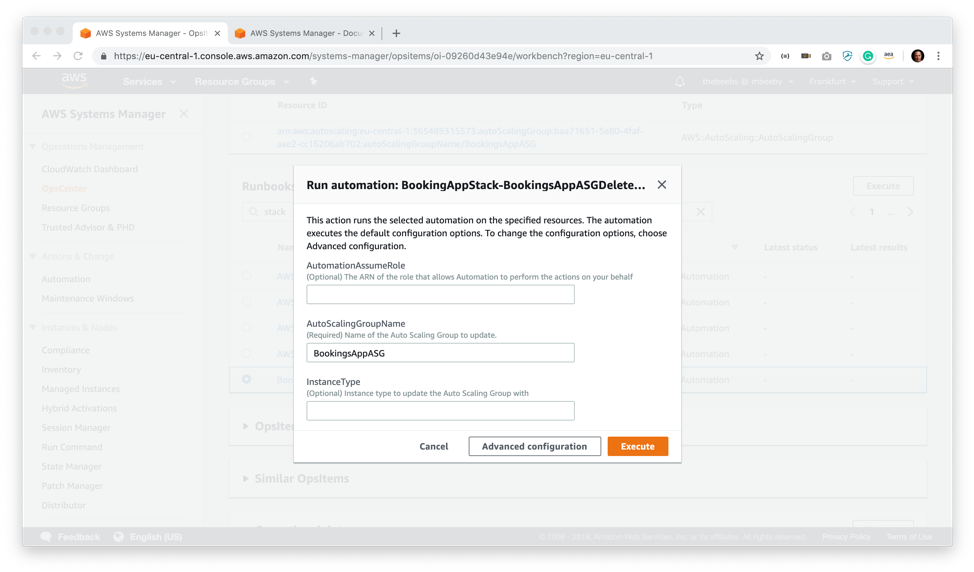
1 分ほどした後、Runbook の [Latest Status] 列に緑色の成功を示すマークが表示されます。これで、ログを表示したり、出力を OpsItem の運用データに保存したりできるようになり、他のエンジニアが自身の作業をきちんと確認できます。
OpsCenter の OpsItem 関連のリソース詳細画面に戻ると、CloudWatch アラームが緑色で OK の状態になっていることが分かります。これは、AutoScalling グループで現在 4 つのインスタンスを実行していることを示しています。
このサービスは本日よりご利用可能となりました。今日からすべてのパブリック AWS リージョンでご利用いただけます。今すぐコンソールを開いていろんな方法を探索し、ご自身とチームの貴重な時間を節約しましょう。