多くの企業や業界にとって、予測という側面はとても重要です。明確に定義された目標がないまま前進すると深刻な結果をもたらす可能性があります。製品計画、財務予測、および天気予報は、ハードデータと重要な分析に基づいて科学的な見積もりを作成します。時系列予測は、ベースライン、トレンド、および季節性があれば履歴データを分解できます。
Amazon SageMaker DeepAR 予測アルゴリズムは、時系列を予測するための教師あり機械学習アルゴリズムです。このアルゴリズムは、リカレントニューラルネットワーク (RNN) を使用して、ポイント予測と確率論的予測を生成します。DeepAR アルゴリズムを使用して、スカラー (1 次元) 時系列の単一の値を予測するか、モデルを作成することにより、関連する数百の時系列で同時に動作させることができます。また、モデルがトレーニングされる系列に関連する新しい時系列を予測することもできます。
時系列予測を説明するために、DeepAR アルゴリズムを使用してシカゴの速度違反カメラデータセットを分析します。データセットは Data.gov によってホストされ、米国総務局、テクノロジートランスフォーメーションサービスによって管理されています。これらの違反はカメラシステムによってキャプチャされ、シカゴデータポータルで利用できます。データセットを使用して、データのパターンを識別し、有意義な洞察を得ることができます。
データセットには、複数のカメラの位置と毎日の違反件数が含まれています。カメラがとらえた毎日の違反を 1 つの時系列として想像すると、DeepAR アルゴリズムを使用して、複数の道路のモデルを同時にトレーニングし、複数の道路のカメラ違反を予測できます。
この分析により、ドライバーが 1 年間さまざまな時間帯に制限速度を超過して運転する可能性が最も高い道路と、データの季節性を特定することができます。これにより、都市では、運転速度を下げ、代替経路を作成し、安全性を高めるための事前対策を実施することができます。
このノートブックのコードは、GitHub リポジトリで入手できます。
Jupyter ノートブックの作成
始める前に、Amazon SageMaker Jupyter ノートブックインスタンスを作成します。この投稿では、ml.m4.xlarge ノートブックインスタンスと組み込みの python3 カーネルを使用します。
必要なライブラリのインポート、データのダウンロードと視覚化
データを Jupyter ノートブックインスタンスにダウンロードし、Amazon Simple Storage Service (Amazon S3) バケットにアップロードします。データをトレーニングするには、住所、違反日、違反回数を使用します。以下のコードと出力は、データセットをダウンロードし、数行と 4 列を表示する方法を示しています。
url = 'https://data.cityofchicago.org/api/views/hhkd-xvj4/rows.csv?accessType=DOWNLOAD'
# シカゴ市のサイトからデータを取得
r = requests.get(url, allow_redirects=True)
open(datafile, 'wb').write(r.content)
# 入力ファイルを読み取り、サンプルの行/列を表示する
pd.set_option('display.max_columns', 500)
pd.set_option('display.max_rows', 50)
df = pd.read_csv(open(datafile, 'rb'), encoding='utf-8')
df[df.columns[0:3]]

matplotlib を使用したデータの視覚化
この手順では、違反日を文字列形式からデータフレームの日付に変換し、不足している違反値をカメラごとに 0 として追加し、matplotlib を使用して、さまざまな道路による違反を時系列として視覚化します。これは、各カメラと道路データを時系列として視覚化するのに役立ちます。次のコードを参照してください。
df['VIOLATION_DT'] = pd.to_datetime(df['VIOLATION DATE'])
df[['ADDRESS', 'VIOLATION_DT', 'VIOLATIONS']]
unique_addresses = df.ADDRESS.unique()
idx = pd.date_range(df.VIOLATION_DT.min(), df.VIOLATION_DT.max())
number_of_addresses = len(unique_addresses)
print('Unique Addresses {}'.format(number_of_addresses))
print('Minimum violation date is {}, maximum violation date is {}'.format(df.VIOLATION_DT.min(),df.VIOLATION_DT.max()))
violation_list = []
for key in unique_addresses:
temp_df = df[['VIOLATION_DT', 'VIOLATIONS']][df.ADDRESS == key]
temp_df.set_index(['VIOLATION_DT'], inplace=True)
temp_df.index = pd.DatetimeIndex(temp_df.index)
temp_df = temp_df.reindex(idx, fill_value=0)
violation_list.append(temp_df['VIOLATIONS'])
plt.figure(figsize=(12,6), dpi=100, facecolor='w')
for key, address in enumerate(unique_addresses):
plt.plot(violation_list[key], label=address)
plt.ylabel('Violations')
plt.xlabel('Date')
plt.title('Chicago Speed Camera Violations')
plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.05), shadow=False, ncol=4)
plt.show()
以下のグラフは、データセットで利用可能なすべてのデータを、X 軸の日付に対してプロットされた Y 軸の日別の速度違反件数を含む時系列として示しています。

トレーニングと評価用のデータセット分割
これで、データをトレーニングセットとテストセットに分割できます。モデルの予測を評価するために、直近 30 日間のデータからテストデータセットを作成します。トレーニングジョブでは、直近 30 日間のテストデータは表示されません。データセットをパンダシリーズから JSON シリーズオブジェクトに変換し、テストデータセットを使用して、トレーニング済みモデルの予測機能の品質を確認します。以下のコードは、データ分割とトレーニングおよびテストデータセットの作成を示しています。
prediction_length = 30
# トレーニングと検証のためにデータを分割する/差し控える
violation_list_training = []
for i in violation_list:
violation_list_training.append((i[:-prediction_length]))
def series_to_obj(ts, cat=None):
obj = {'start': str(ts.index[0]), 'target': list(ts)}
if cat:
obj['cat'] = cat
return obj
def series_to_jsonline(ts, cat=None):
return json.dumps(series_to_obj(ts, cat))
encoding = 'utf-8'
s3filesystem = s3fs.S3FileSystem()
with s3filesystem.open(train_data_path, 'wb') as fp:
for ts in violation_list_training:
fp.write(series_to_jsonline(ts).encode(encoding))
fp.write('\n'.encode(encoding))
with s3filesystem.open(test_data_path, 'wb') as fp:
for ts in violation_list:
fp.write(series_to_jsonline(ts).encode(encoding))
fp.write('\n'.encode(encoding))
管理型スポットインスタンスと自動モデルチューニングをトレーニングに使用する
Amazon SageMaker Python SDK は、自動モデル調整ジョブを作成するためのシンプルな API を提供します。この使用例では、管理型スポットインスタンスを使用してトレーニングのコストを削減します。テストデータセットの二乗平均平方根誤差 (RMSE) を目的として使用して、モデルのトレーニング値を最小限に抑えることができます。Amazon SageMaker チューニングパッケージの HyperparameterTuner クラスは、最適なハイパーパラメータを見つけるために実行するトレーニングジョブ数の並列処理を制御する簡単なインターフェイスを提供します。実行する最大ジョブ数を 10 に設定して、10 個の並列ジョブを使用しています。数値をより高い値に設定して、より多くのハイパーパラメータ調整を可能にし、より良い結果を生み出すことができます。fit メソッドは、最大トレーニング時間を 1 時間に設定して、ハイパーパラメータ調整ジョブを開始します。次のコードを参照してください。
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner
deepar = sagemaker.estimator.Estimator(image_name,
role,
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
train_use_spot_instances=True, # use spot instances
train_max_run=3600, # max training time in seconds
train_max_wait=3600, # seconds to wait for spot instance
output_path='s3://{}/{}'.format(bucket, s3_output_path),
sagemaker_session=sess)
freq = 'D'
context_length = 30
deepar.set_hyperparameters(time_freq=freq,
context_length=str(context_length),
prediction_length=str(prediction_length))
hyperparameter_ranges = {'mini_batch_size': IntegerParameter(100, 400),
'epochs': IntegerParameter(200, 400),
'num_cells': IntegerParameter(30,100),
'likelihood': CategoricalParameter(['negative-binomial', 'student-T']),
'learning_rate': ContinuousParameter(0.0001, 0.1)}
objective_metric_name = 'test:RMSE'
tuner = HyperparameterTuner(deepar,
objective_metric_name,
hyperparameter_ranges,
max_jobs=10,
strategy='Bayesian',
objective_type='Minimize',
max_parallel_jobs=10,
early_stopping_type='Auto')
s3_input_train = sagemaker.s3_input(s3_data='s3://{}/{}/train/'.format(bucket, prefix),
content_type='json')
s3_input_test = sagemaker.s3_input(s3_data='s3://{}/{}/test/'.format(bucket, prefix),
content_type='json')
tuner.fit({'train': s3_input_train, 'test': s3_input_test},
include_cls_metadata=False)
tuner.wait()
ベストモデルのデプロイ
Amazon SageMaker Python SDK tuner.best_tuning_job API は、最適なチューニングジョブを識別できます。これを使用して、ハイパーパラメータトレーニングの目的メトリックを最小化したモデルをデプロイできます。1 回のデプロイ API 呼び出しで、自動ハイパーパラメータ最適化ジョブによって識別された最適モデルが ml.m4.xlarge インスタンスにデプロイされます。
best_tuning_job_name = tuner.best_training_job()
endpoint_name = tuner.deploy(initial_instance_count=1,
endpoint_name=best_tuning_job_name,
instance_type='ml.m4.xlarge',
wait=True)
以下の出力の一部は、最適モデルのトレーニングと請求対象のトレーニング時間を示しています。
…
トレーニング秒数: 674
請求可能秒数: 242
管理型スポットトレーニングの節約: 64.1%
Amazon SageMaker が管理するスポットトレーニングは、10 個のトレーニングジョブすべてのコストを削減します。上記の出力は、オンデマンドトレーニングインスタンスと比較して、10 個のトレーニングジョブのうち最もトレーニングされたモデルがトレーニングコストの 64% 以上を節約したことを示しています。
推論を行う
次に、sagemaker.predictor.RealTimePredictor クラスと関連するヘルパー関数を拡張して、パンダシリーズをオブジェクトにエンコードし、デコード関数を拡張してオブジェクトをパンダシリーズに逆シリアル化する DeepARPredictor クラスを定義します。このメソッドを使用すれば、テストデータセットの予測メソッドを実装できます。次のコードを参照してください。
class DeepARPredictor(sagemaker.predictor.RealTimePredictor):
def set_prediction_parameters(self, freq, prediction_length):
""" 時間頻度と予測長のパラメータを設定します。このメソッドは、
`predict` を使用する前に呼び出す **必要があります**。
パラメータ:
freq -- 時間頻度を示す文字列
prediction_length -- 整数、予測時点の数
戻り値: なし。
"""
self.freq = freq
self.prediction_length = prediction_length
def predict(self, ts, cat=None, encoding='utf-8', num_samples=100, quantiles=['0.1', '0.5', '0.9']):
""" `ts` にリストされた時系列の予測をリクエストします。それぞれに
(オプション) 対応するカテゴリが `cat` にリストされています。
パラメータ:
ts -- `pandas.Series` オブジェクトのリスト、予測する時系列
cat -- 整数のリスト (デフォルト: なし)
encoding -- 文字列、リクエストに使用するエンコーディング (デフォルト: 'utf-8')
num_samples -- 整数、予測時に計算するサンプル数 (デフォルト: 100)
quantiles -- 計算する分位数を指定する文字列のリスト (デフォルト: ['0.1', '0.5', '0.9'])
戻り値: それぞれが予測を含む `pandas.DataFrame` オブジェクトのリスト
"""
prediction_times = [x.index[-1]+1 for x in ts]
req = self.__encode_request(ts, cat, encoding, num_samples, quantiles)
res = super(DeepARPredictor, self).predict(req)
return self.__decode_response(res, prediction_times, encoding)
def __encode_request(self, ts, cat, encoding, num_samples, quantiles):
instances = [series_to_obj(ts[k], cat[k] if cat else None) for k in range(len(ts))]
configuration = {'num_samples': num_samples, 'output_types': ['quantiles'], 'quantiles': quantiles}
http_request_data = {'instances': instances, 'configuration': configuration}
return json.dumps(http_request_data).encode(encoding)
def __decode_response(self, response, prediction_times, encoding):
response_data = json.loads(response.decode(encoding))
list_of_df = []
for k in range(len(prediction_times)):
prediction_index = pd.DatetimeIndex(start=prediction_times[k], freq=self.freq, periods=self.prediction_length)
list_of_df.append(pd.DataFrame(data=response_data['predictions'][k]['quantiles'], index=prediction_index))
return list_of_df
predictor = DeepARPredictor(endpoint=best_tuning_job_name,
sagemaker_session=sagemaker_session,
content_type="application/json")
予測の視覚化
最後のステップでは、予測オブジェクトを使用して、テストデータセットから 5 つの道路サンプルの予測を行い、テストデータと予測データのグラフィカルな結果を提供します。80% の信頼区間でテストデータに対する予測をグラフ化して、モデルのパフォーマンスを確認できます。以下のコードとグラフを参照してください。
predictor.set_prediction_parameters(freq, prediction_length)
list_of_df = predictor.predict(violation_list_training[:5])
actual_data = violation_list[:5]
for k in range(len(list_of_df)):
plt.figure(figsize=(12,6), dpi=75, facecolor='w')
plt.ylabel('Violations')
plt.xlabel('Date')
plt.title('Chicago Speed Camera Violations:' + unique_addresses[k])
actual_data[k][-prediction_length-context_length:].plot(label='target')
p10 = list_of_df[k]['0.1']
p90 = list_of_df[k]['0.9']
plt.fill_between(p10.index, p10, p90, color='y', alpha=0.5,label='80% confidence interval')
list_of_df[k]['0.5'].plot(label='prediction median')
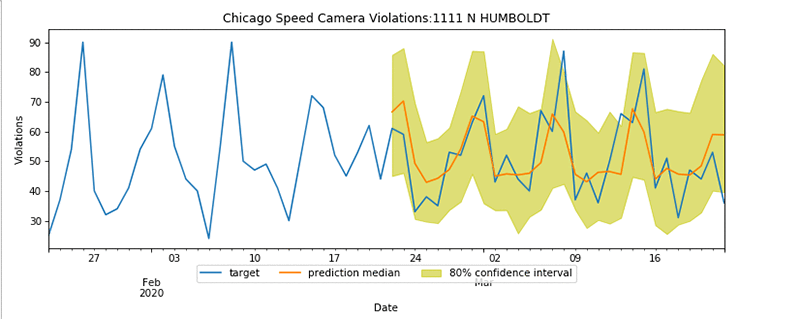
上に表示されたパターンは、予測が 80% の信頼度内でターゲットとテストデータ通りであることを示しています。また、1111 N HUMBOLDT 通りの場所が、週末 2020 年 1 月 31 日、2020 年 2 月 8 日、2020 年 2 月 15 日 (すべて土曜日) に急上昇していることも示しています。
すべてのデータポイントを連続して使用してこのデータをグラフ化すれば、年の半ばと夏に速度違反が急上昇することを示す季節パターンを確認できます。
クリーンアップ
このチュートリアルを完了した後に、AWS アカウントで料金が発生しないように、予測エンドポイントを必ず削除してください。次のコードを参照してください。
predictor.delete_endpoint(endpoint_name)
Amazon SageMaker ノートブックインスタンスも削除する必要があります。手順については、ステップ 9: クリーンアップを参照してください。
まとめ
この投稿では、Amazon SageMaker の DeepAR アルゴリズムを使用してモデルをトレーニングし、さまざまなカメラ位置での複数の住所を予測して、時間の経過による速度違反を観察し、季節性を特定しました。このデータを使用して、モデルは、週末および夏の間に、その後の期間に発生する違反パターンおよび違反の急増を予測できます。このような分析は、運転者が 1 年間のさまざまな時間帯に制限速度を超過して運転する可能性が高い通りを予測するのに役立ちます。都市は、運転速度を下げ、安全性を高め、混雑を減らすための代替経路を作成するための事前対策を実施できます。
ビジネスで複数の関連時系列を予測する必要がある場合は、この投稿の DeepAR アルゴリズムとソリューションを使用できます。DeepAR アルゴリズムの詳細については、DeepAR アルゴリズムの仕組みを参照してください。アルゴリズムの設計方法については、DeepAR: 自己回帰リカレントネットワークを使用した確率的予測を参照してください。
著者について
 Viral Desai は、AWS のソリューションアーキテクトです。 顧客がクラウドで成功できるように、アーキテクチャの指針を提供します。余暇には、テニスをし、家族と過ごす時間を楽しんでいます。
Viral Desai は、AWS のソリューションアーキテクトです。 顧客がクラウドで成功できるように、アーキテクチャの指針を提供します。余暇には、テニスをし、家族と過ごす時間を楽しんでいます。