Amazon Web Services ブログ
AWS Data Exchange を使用してデータ製品を動的に公開し、更新する
あらゆるサイズの組織において、データがビジネスの方法を大変革しています。会社はますます、サードパーティのデータを、社内のデータを補完し、顧客に価値を提供できるようにするために使用するようになっています。サードパーティのデータは、様々なユースケースで使用されています。その中には、顧客のためのアプリケーションの構築、事業の運営とマーケティング活動を改善するためのワークロードの分析、機械学習(ML)のテクニックに基づく予測モデルの構築が含まれます。
しかし、データが会社の事業の中心になったにもかかわらず、データプロバイダーがサブスクライバーにデータを提供する方法は何年も変わっていません。データプロバイダーの側からすると、提供物としてのデータと、エンタイトルメントの管理機構を構築するために、代わり映えのしないヘビーリフティングに時間と労力を費やして、顧客にサービスを提供してきたわけです。多くのデータプロバイダーは、従来式の販売方法と配信チャネルに依存しており、多くの場合、自社のデータに関心を持っている多くの見込み客にアクセスすることはできないでいます。そのため、データ製品をニーズに適合させることは遅れています。
AWS Data Exchange の世界に入ってください。
AWS Data Exchange を使用すると、クラウド内のデータを簡単に交換できます。顧客は数分で、金融サービス、ヘルスケア、ライフサイエンス、消費者および小売などの業界の 80 を超える認定データプロバイダーからの数百のデータ製品を見つけて購読できます。購読の後、顧客はデータセットをダウンロードすること、またはAmazon S3 にコピーして、AWS の様々な分析と機械学習サービスを使用しての分析することができます。AWS Data Exchange を使えば、データプロバイダーは、セキュアで透明、そして信頼できるチャネルを通して幾百万の AWS の顧客に接触する機会が得られます。AWS Data Exchange はまた、データの配信、ライセンス、または課金のインフラストラクチャを構築する必要をなくすので、既存の顧客サブスクリプションをより効率的に、そしてより低コストで提供できるようにする点でも助けになります。
多くのデータプロバイダーは、定期的に更新されるデータ製品を公開しています。たとえば、株式価格のデータプロバイダーは毎日の終値を公開したいと思うでしょうし、天気予報のデータプロバイダーは、予報を毎週更新したいと思うでしょう。この記事では、AWS Data Exchange で製品の公開と更新を動的に行う方法について、手順を追って説明します。まず、新しい製品を公開して、サブスクライバーが利用できるようにします。これは AWS Data Exchange コンソールを使用して数分間で行えます。それから、Lambda 関数を使用して、基本となるデータセットに新しいリビジョンを公開することにより、製品を自動的に更新するワークフローも知ることができます。
前提条件
開始する前に、次の前提条件を満たしてください。
- AWS Data Exchange の登録プロバイダーとなる必要があります。資格があり、登録プロバイダーだけが、AWS Data Exchange でデータ製品を公開できます。資格があるプロバイダーは、米国または EU の成員国に本拠を置く有効な法人の下で AWS Marketplace の利用条件に合意し、有効な銀行および課税当局の身分証明書を提出し、AWS Data Exchange のビジネスオペレーションチームによって資格を認定される必要があります。詳細については、Providing Data Products on AWS Data Exchange(AWS Data Exchange でデータ製品を提供する)を参照してください。
- プロバイダーが公開するデータは、AWS Marketplace の使用条件と AWS Data Exchange Publishing Guidelines (AWS Data Exchange の公開ガイドライン) に従っている必要があります。
- プロバイダーは、AWS Data Exchange をプロバイダーとして使用するための適切な IAM アクセス許可を持っている必要があります。たとえば、
AWSDataExchangeProviderFullAccessマネージド IAM ポリシーを使用することができます。 - 公開の準備ができたデータファイルを格納する S3 バケットが必要です。詳細については、バケットの作成と Amazon S3 とはを参照してください。
AWS Data Exchange の概念
製品とは、AWS Data Exchange での交換対象の単位です。製品とは、プロバイダーが公開し、サブスクライブの対象となる、データセットのパッケージ です。AWS Data Exchange 製品カタログと AWS Marketplace ウェブサイトには、製品のリストが含まれています。製品には 1 つ以上のデータセット、そして製品の詳細を含めることができます。この詳細には製品の名前と説明、カテゴリー、そして連絡先の詳細が含まれます。製品にはまた、製品の提供条件に関連した情報を含めることもできます。製品にサブスクライブする場合にサブスクライバーが同意する必要のある条件です。これらの条件には、料金と期間の利用可能なオプション、データサブスクライバーとの契約、そして返金ポリシーが含まれます。
データセットとは、ファイルベースのデータコンテンツの動的なセットです。データセットは動的なものであり、リビジョンを基にバージョンを指定します。リビジョンとは、データセットの特定のバージョンです。それぞれのリビジョンには、アセットと呼ばれる複数のファイルを含めることができます。アセットは、ジョブと呼ばれる非同期ワークフローを使用してリビジョンにインポートできます。リビジョンを作成し、アセットをインポートしたら、公開の準備ができたというマークをそのリビジョンに付ける必要があります。それからそれをデータセットの製品として公開します。詳細についてはWorking with Data Sets(データセットの操作)を参照してください。
下の図は、上記で説明した概念と、異なるリソース間の階層構造を示しています。

新しい製品を AWS Data Exchange に公開する
既存の製品を自動的に更新する方法を確認する前に、新しい製品のセットアップと作成の方法から始めましょう。すでに公開済みの製品がある場合には、このセクションはスキップして、「新しいデータファイルを自動的に製品に公開する」に移動してください。
データセットの作成
製品を公開するためには、まずデータセットを作成する必要があります。以下の手順を完了してください。
- AWS Data Exchange コンソールの [Data sets] の下で、[Create data set] を選択します。

- データセットの [Name] と [Description] を入力して、[Create] をクリックします。
データセットの名前が、カタログの製品の詳細の一部として表示されます。簡潔で、顧客がデータセットの内容を容易に理解できるような名前にしてください。説明は、製品のアクティブなサブスクリプションを有しているサブスクライバーに見えるようになります。カバー対象の情報と、そのデータセットの特徴とメリットを含めるようにしてください。
次のスクリーンショットは、[Create data set] 画面、および名前と説明を示しています。この記事では、名前として [Exchange-A End of Day Prices]、説明として次のとおり入力しています。 [End-of-day pricing of all equities listed on Exchange-A.Covers all industries and all equities traded on the exchange (2,000+).This data set contains full history from 1985, and is updated daily with a new file every day around 5pm EST]

リビジョンの作成
データセットの作成後、製品に公開する前に、最初のリビジョンを作成する必要があります。以下の手順を完了してください。
- データセットのページで、[Revisions] を選択します。
- [Create revision] を選択します。
- [Revision settings] で、このリビジョンのデータについての短いコメントを入力します。
- [Create] を選択します。リビジョンのコメントは、サブスクライバーがこの製品にサブスクライブすると表示されます。次のスクリーンショットは、この記事で入力したコメントとして、[
Historical data from January 1st, 1985 to November 13th, 2019(1985 年 1 月 1 日から 2019 年 11 月 13 日までの履歴データ)] が表示されているところです。 ファイル(資産)は、 S3 バケットまたは自分のコンピュータのいずれかから、このリビジョンにインポートするように選択することができます。この記事では S3 バケットからインポートします。デフォルトでは、AWS Data Exchange は資産の名前として S3 オブジェクトのキーを使用することに注意しておくことは大切です。次のスクリーンショットは、この記事で使用するファイルの例です。
ファイル(資産)は、 S3 バケットまたは自分のコンピュータのいずれかから、このリビジョンにインポートするように選択することができます。この記事では S3 バケットからインポートします。デフォルトでは、AWS Data Exchange は資産の名前として S3 オブジェクトのキーを使用することに注意しておくことは大切です。次のスクリーンショットは、この記事で使用するファイルの例です。
- インポートステータスが「完了」になったら、[Finalize] を選択します。

あるバージョンがファイナライズされると、公開の段階に入ったことになります。サブスクライバーに公開できるのは、ファイナライズされたリビジョンだけです。リビジョンを公開後に変更することはできません。
新しい製品の公開
このデータセットを使って、新しい製品を公開する準備ができました。以下の手順を完了してください。
- AWS Data Exchange コンソールの [Publish data] の下で、[Products] を選択します。
- [Publish new product] を選択します。

- [Product overview] に、サブスクライバーが製品の特徴を知るのに役立つ製品の紹介を入力します。製品の詳細を入力する際のベストプラクティスについては、Publishing Products(製品の公開)を参照してください。特に、データのデューデリジェンスのアンケート(due diligence questionnaire、DDQ へのリンクを含めることを考慮しておくとよいでしょう。これはデータセットのファイルタイプとスキーマ、およびその他のファクトシートについての情報です。製品の説明についてのリンクを含め、形式を設定するには、マークダウンを使用できる点に注意してください。

- [Next] を選択して [Add data] に進みます。上で作成したデータを追加できます。

- [Next ] を選択して [Configure the public offer] ページに進みます。これは、製品の提供物の詳細を設定するページです。これには料金オプション、データのサブスクリプション契約、および返金ポリシーが含まれます。サブスクリプションの検証を有効にするかどうかも選択できます。サブスクリプションの検証を有効にすると、サブスクライバーとなる見込みのあるユーザーには、サブスクライブする前に、名前、会社名、メールアドレス、およびユースケースについて入力することが求められます。その後、サブスクリプションのリクエストがプロバイダーの [Product Dashboard] ページに表示されます。リクエストを受け入れるか拒否するかを決定するまで 45 日の猶予があります。サブスクリプションの検証については、[Subscription Verification for Providers] を参照してください。

- [Next] をクリックして、製品をレビューします。製品は、AWS Data Exchange の製品カタログに表示されるので、プレビューできます。製品と提供物の詳細に問題がなければ、[Publish the product] を選択します。重要: [ Publish the product ] を選択すると、製品は AWS Data Exchange カタログに公開され、サブスクライバーに公開されて利用できるようになります。
ここまでで新しいデータセットを作成し、このデータセットに最初のリビジョンを追加して履歴データが含まれるようにし、リビジョンをファイナライズして、ファイナライズしたリビジョンで製品を公開しました。この製品は、公開後数時間でサブスクライバーに利用可能になって、購入できるようになります。
新しいデータファイルを製品に自動的に公開する
これで、製品を顧客が利用できるようになりました。さらに必要なのは、製品を更新し、新しいリビジョンを継続的に製品に公開することです。この例では、毎日新しい株価を公開する必要があります。そのためには、S3 バケットにアップロードされたファイルを自動的に認識し、それらを新しいリビジョンの一部として製品のデータセットに公開するアーキテクチャをセットアップします。このワークフローは、S3 バケットにアップロードされたファイルごとに、新しいリビジョンを作成して公開します。

ワークフローは次のとおりです。
- 公開の準備ができたデータファイルを S3 バケットにアップロードして、データセットを更新します。
- S3 は、AWS Lambda 関数を呼び出して、オブジェクトについての詳細を含んでいる S3 API イベントを起こします。詳細については、AWS Lambda を Amazon S3 に使用するを参照してください。
- AWS Lambda 関数は、以前から存在していたデータセットの下に新しいリビジョンを作成し、ファイルをインポートするジョブを開始します。
- AWS Lambda 関数は、以前から存在していた製品を変更して、新しいデータセットのリビジョンが含まれるようにします。
- サブスクライバーは新しいリビジョンを使用できるようになります。これはエンタイトルされたデータセットの一部として表示されます。
Lambda 関数の構築
ここで、製品をデータセットとともに公開しますが、S3 にアップロードされたデータファイルを認識して、それを製品の一部として公開する Lambda 関数を構築するための基本的な要素はすでに学んでいます。
Lambda 関数を正しく設定するには、まず前に作成したデータセット ID と製品 ID を記録しておく必要があります。それらは AWS Data Exchange コンソールから取得できます。製品 ID は製品のページで確認できます。このページには製品ダッシュボードからアクセスできます。データセット ID はデータセットのページから確認できます。[Data sets] ページからアクセスします。
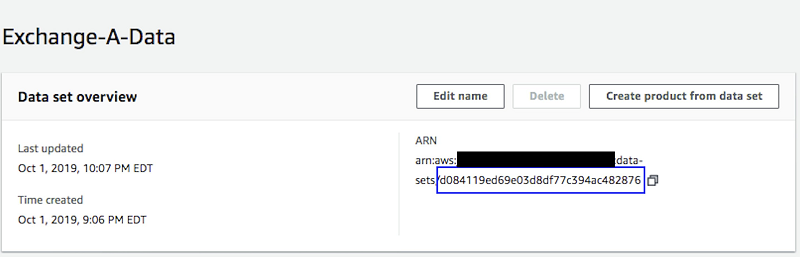
データセットのページ
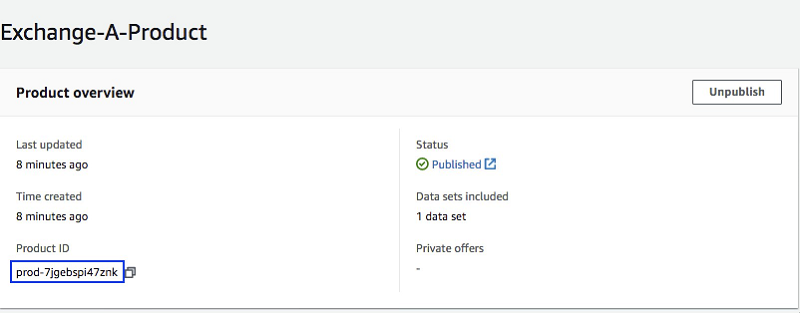
製品のページ
IAM ロールを作成する
Lambda 関数にソースの S3 バケットを読み取るアクセス許可を与える、リビジョンを作成する、ファイルをそのリビジョンにアップロードする、リビジョンを製品に公開するといった手順では、適切なアクセス許可を持つ IAM ロールを作成する必要があります。
そのためには、IAM ロールを作成して、以下のポリシーをそれにアタッチします。{INSERT-BUCKET-NAME} と {INSERT-ACCOUNTID} は、それぞれ S3 バケットの名前と自分のアカウント ID に置き換えるよう注意してください。
詳細については、IAM ロールの作成を参照してください。
Lambda レイヤーをデプロイする
この記事では、AWS Data Exchange および 2019 年 11 月 13 日の時点の AWS Marketplace Catalog API SDK を追加して、Lambda Python ランタイムに組み込まれている AWS Python SDK (boto3) を拡張する Lambda レイヤーを使用しています。この記事で公開されたサンプルレイヤーをデプロイすることもできますが、自分のニーズに適した AWS SDK のバージョンを使用するようにしてください。
Lambda 関数の作成
ここまでで IAM ロールを作成し、最新の SDK で Lambda レイヤーをデプロイしました。Lambda 関数は以下の手順で作成できます。
- Lambda コンソールで、[Create a function] を選択します。
- [Create function] ステップで、[Author from scratch] を選択します。
- [Basic information] セクションで、以下の情報を入力して Lambda 関数を設定します。
- [Function name] に、選択した名前を入力します。
- [Runtime] で [Python 3.7] を選択します。
- [Permissions] で、[Use an existing role] を選択します。
- [Existing role ] ドロップダウンで、それ以前に作成していた Lambda ロールを選択します。
- [Create function] を選択します。
Lambda 関数の設定
次に、Lambda 関数を設定します。まず、S3 バケットに新しいファイルがアップロードされたときにトリガーされるように設定する必要があります。以下の手順を完了してください。
- Lambda コンソールで、[Functions] を選択します。
- 新たに作成した関数を選択します。
- 関数の設定ページで、[Add trigger] を選択します。
- [Trigger Configuration] で、S3 を選択します。
- ドロップダウンから、前提条件を満たすために作成したバケットを先駆します。
- [Event type] で、[All Object Create Events] を選択します。
- AWS Data Exchange 製品に特定のファイルだけを公開する場合には、オプションとして、[Prefix] または [Suffix] を選択します。
- [Add] を選択します。
コードが適切な SDK で動作していることを確認するために、前にデプロイした Lambda レイヤーを Lambda 関数に関連付けます。前に注意したように、この記事ではサンプルレイヤーを公開しますが、自分のニーズに適した AWS SDK のバージョンを使用するようにしてください。
- Lambda コンソールで、[Functions] を選択します。
- 新たに作成した関数を選択します。
- 関数の設定ページの関数名の下で、[Layers] を選択します。
- [Add a layer] を選択します。
- [Layer Selection] で、[Select from list of runtime compatible layers] をオフにします。
- ドロップダウンから、前にデプロイしたレイヤーを選択します。
- [Add] を選択します。
次に、Lambda 関数のコードを設定する必要があります。次のコードを、Lambda 関数にコピーします。このコードはプログラムによって以下の API を呼び出します。これらは前にコンソールを使用して実行したのと同じ API です。
CreateRevisionは新しいリビジョンを作成します。CreateJobとStartJobはリビジョンへのファイルのインポートを開始します。GetJobはインポートのステータスをチェックします。UpdateRevisionはリビジョンをファイナライズしたものとしてマークします。
製品に更新を公開するために、Lambda 関数は、AWS Marketplace Catalog API サービスを以下の API で使用します。詳細については、AWS Marketplace Catalog API Reference(AWS Marketplace カタログ API リファレンス)を参照してください。
DescribeEntityは製品の詳細を取得します。StartChangeSet更新を開始します。DescribeChangeSetは製品の更新のステータスをチェックします。
以下の手順を完了してください。
- Lambda コンソールで、[Functions] を選択します。
- 新たに作成した関数を選択します。
- [Function code] までスクロールします
- 以下のコードを入力します。
- [Environment Variables] まで下方にスクロールします
- DATA_SET_ID および PRODUCT_ID 変数に、コンソールから取得した値を設定します。
- さらに [Basic Settings] までスクロールして、[Timeout] 変数を 1 分に設定します。
- [Save] を選択します。
ファイルを S3 バケットにアップロードすると、S3 イベントが Lambda 関数をトリガーして、次にそれがデータセットを自動的に更新し、新しいファイルをサブスクライバーに公開します。サブスクライバーはまた、AWS Data Exchange からAmazon CloudWatch イベントを受け取ります。サブスクライバーの S3 バケットにデータを自動的にエクスポートするためです。
まとめ
AWS Data Exchange は、データプロバイダーが顧客との間でクラウドネイティブでセキュア、そして効率的な方法でデータを交換するための、容易で便利な方法を提供します。この記事では、AWS Data Exchange コンソールを使用して、新しく作成したデータセットとリビジョンを基に新しい製品を公開する方法について説明しました。また、S3 バケットにアップロードされたファイルを新しいリビジョンとして自動的に公開する方法についても学びました。さらに詳しい点については、AWS Data Exchange にアクセスしてください。
著者について
 Akram Chetibi は AWS Data Exchange のシニアプロダクトマネージャーです。Akram は 2 年以上前に AWS に入社し、AWS Data Exchange や AWS Fargate などの複数のサービスを手がけました。
Akram Chetibi は AWS Data Exchange のシニアプロダクトマネージャーです。Akram は 2 年以上前に AWS に入社し、AWS Data Exchange や AWS Fargate などの複数のサービスを手がけました。
 Keerti Shah はアマゾン ウェブ サービスのソリューションアーキテクトです。 彼女は財務サービスの顧客と協力して、従来なプリケーションのイノベーション、デジタル化、そして近代化を推し進めるために働くことを楽しんでいます。
Keerti Shah はアマゾン ウェブ サービスのソリューションアーキテクトです。 彼女は財務サービスの顧客と協力して、従来なプリケーションのイノベーション、デジタル化、そして近代化を推し進めるために働くことを楽しんでいます。
 Harsha W. Sharma は AWS ニューヨークで働く、グローバルアカウントソリューションアーキテクトです。Harsha は 3 年以上前に AWS に入社し、グローバルファイナンシャルサービスの顧客とともに働いて、AWS 上のアーキテクチャのデザインと開発に携わり、クラウドへの移行をサポートしています。
Harsha W. Sharma は AWS ニューヨークで働く、グローバルアカウントソリューションアーキテクトです。Harsha は 3 年以上前に AWS に入社し、グローバルファイナンシャルサービスの顧客とともに働いて、AWS 上のアーキテクチャのデザインと開発に携わり、クラウドへの移行をサポートしています。