Amazon Web Services ブログ
Aurora PostgreSQL ストレージの I/O コストを削減
多くの企業における IT 部門では、オンプレミスのワークロードをクラウドに移行することの最大の理由の 1 つがコスト削減となっています。今回の記事では、コスト管理についての実例を、Amazon Aurora PostgreSQL のチューニングに着目しながらご紹介していきます。
ヒストリー
私は最近、当社の自動車向けテレマティクスアプリケーションの、AWS への実装作業を指揮するという機会に恵まれました。少し説明しますと、テレマティクスアプリケーションとは、データ提供者から運転データをストリーミングで受信するものです。このデータは、検証、修正、および正規化されます。そして、処理に合わせた変換が行われた後、専用のスコアリングアルゴリズムを用いて、ドライバーの点数付け計算に使われます。このプロジェクトには、次に示す主要な目的がありました。
- 高い可用性 (HA) の実現 (99.999%) 。
- レスポンスタイプは、数ミリ秒台という高いパフォーマンスの実現。
- 現状の TCO をその何割かまでに削減する。これには、人的および設備的なリソースの削減も含まれます。
- 実際の使用量を反映した、従量課金制の支払に移行する。
- 国や地域を問わず、デプロイと新規顧客の受け入れを容易にする。
- 規模の拡大と需要変動に適応できる、スケーラビリティと伸縮性の獲得。
コストと HA での目標を達成するため、アプリケーションはサーバーレス/マネージド型のアーキテクチャを用いて、ゼロから再設計と再コーディングが行われました。これにより、保守に必要なリソースの最小化と従量課金制の利用がはかられましたこの再設計は、ほとんどの目的を達成し大きな成功となりましたが、コストだけに問題が残りました。オンプレミスに比べればコスト削減ができたものの、依然として想定した金額の 3 倍の金額になってしまったのです。
概要
他のどの変更作業と同様に、オンプレミスから AWS への移行要素には、次の 3 つが含まれます。
- 人材
- 処理
- テクノロジー
個人的には、人材の要素がキーになると思います。オンプレミス環境とは違い、AWS でのインフラストラクチャーのコストは、いわゆる埋没費用ではありません。AWS での運用コストは、サービス利用量をベースに変化するからです。この利用量には、サービスの実行/経過時間だけでなく、メモリー、ストレージ、I/O といった、サービス毎に違いがうまれるものの利用も含まれます。AWS での課金手法になじむには、少し時間がかかることもあります。作業の工程の見直しやサービスの自動化は、AWS の環境が提供するメリットを活用するための重要なポイントです。
AWS を利用する上でのコスト削減の取り組みは、次のようなステップにグループ分けされます。
- AWS のコストを理解する: まず始めに、請求管理ダッシュボードの使用になれることです。それぞれのサービスが、AWS のコストにどの程度影響しているかを理解します。タスクを優先付けするために、まず上位 3 つの高コスト要件に取り組みます。また最終的には、これらの検証がコスト面での重要性だけでなく、セキュリティーの抜け道を洗い出す目的にも重要となります。
- ハウスキーピング: サーバーレスでマネージド型のサービスに移行するからといって、データのクリーニングやアプリケーションの保守のためにオンプレミスで行ったベストプラクティスが完全に不要になるわけではありません。むしろ、そういった作業はより厳格に行う必要が生まれます。
- アプリケーションとサービスの低い機能を特定し調整します。
詳細情報
私のケースでの、コスト増要因およびコストにおける割合のトップ 3 は次のようなものでした。
- Aurora PostgreSQL データベース: 75%
- Amazon CloudWatch Logs: 5%
- Amazon Kinesis: 5%
Aurora PostgreSQL データベースでコストがかかる主要コンポーネントと、関連する中でコストの割合いが高い要素は、次の 3 つでした。
- Database I/O: 65%
- インスタンスサイズ: 30%
- ストレージ: 5%
I/O
トランザクションがとても多いアプリケーションでは、一般的に I/O コストがデータベースコストの中で最大のコスト要因となります。しかし、データベース I/O についてであれば、納得がいく部分でもあります。経験から得た感覚では、インスタンスコストと I/O コストの割合は、おおむね 1.2 を超えるべきではありません。
Performance Insights や CloudWatch のメトリクスを使うと、問題のデバッグや分離に役立つヒントが得られます。Performance Insights が有効化されていない場合は、次に示すスクリーンショットを参考に有効化しておいてください。

次に示すいくつかのヒントも、チューニング作業の役に立つでしょう。
- Performance Insights のメトリクスを確認します。次のスクリーンショットのように、IO: DataFileRead が高い場合は、IO の使用率が高くなっています。IO:DataFilePrefetch が高い場合は、シーケンシャルスキャンが発生しています。

- CloudWatch で Billed IOPS を確認します。同時に、この Billed IOPS の値を想定していたワークロードと比較します。これには、アプリケーションへの知識が必要となります。たとえば、データ取り込み、変換処理、クエリワークロードなどの量が影響するデータベース I/O は、想定した数値と比較して桁違いに大きくなり得ます。ここで注意していただきたいのは、Aurora の Billed メトリクスのラベル付けが、誤っていることです。このメトリクスでは、 I/O 処理数を 5 分ごとのインターバルで表示しています。つまり、このインターバルの間に毎秒何回の I/O 処理が行われたかを知るには、このグラフから読み取れる数値はすべて、300 秒 (つまり 5 分) で割り算する必要があります。
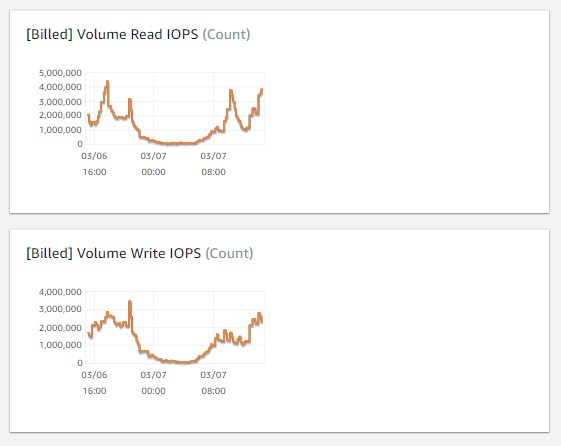
- バッファーキャッシュのヒット率は、I/O 処理を増やす要因の 1 つです。CloudWatch メトリクスで Buffer Cache Hit Ratio を確認します。99% に近い値が適切です。これが低いと、I/O 処理が多くなります。

- バッファーキャッシュ率は、
shared_buffersに割り当てらるメモリを多くすると改善できます。しかし、使用可能なメモリの総量は、データベースインスタンスのサイズに依存します。インスタンスサイズを大きくすれば、shared_buffersで使えるメモリも多くなりますが、同時にサービスにかかるコストも増大します。インスタンスのサイズもコストに関する大きな要因の 1 つだからです。コスト削減のメリットを得るためには、適切なバランス点を見つける必要があります。つまり、インスタンスサイズを大きくする前に、ワークロードとクエリについて、詳細に分析する必要があるわけです。 - SQL タブでは、各 SQL が IO に与える影響を表示できます。上位 3 つのクエリへの対応から始めましょう。表示上でクエリが途中で切られている場合は、データベースパラメータの
track_activity_query_sizeに 4096 以上の値を設定して、実際のクエリのサイズに合わせる必要があります。この処理には、インスタンスの再起動が必要です。 - 次に、これらのクエリに対して、
EXPLAINプランを実行します。ANALYZEオプションを使っている場合なら、EXPLAINがクエリを実行し、実際の行数と実行時間を表示してくれます。加えて、BUFFERSオプションも使うようにすると、実行時の統計情報をより詳しく表示できます。これにより、I/O 処理へのクエリの影響に関する情報が得られます。
EXPLAIN プランを見て、インデックスとパーティションが適切であることを確認します。
- パーティション列の関数を使用しているときは、パーティションの切り取りはできません。このことは、I/O 処理とインスタンスサイズの需要に対し、とても大きな影響を与えます。最良の対処法は、テーブルの設計を適切に行い、パーティションされた列にある関数を利用しなくてもよくすることです。しかしながら、関数ベースの列を使うパーティションをすでに実装済みで実稼働の環境下では、それを修正することは現実的ではないとう場合もあります。そのような場合は、アプリケーションのロジック側で適切なパーティションが見つけられるように修正するという対処法で、同様の結果を得ることができます。例:
この test_table では、パーティションの列には日付が付いています。しかし、テーブルのデータは月ごとにパーティショニングされています。仮に、start_date が January なら、そのデータはパーティション test_table_01 の中に収められています。February のデータは、パーティション test_table_02 にあり、以下同様に続きます。完全な解決策としては、テーブル内に月の列を作成し、それをパーティショニングキーとして使うことです。しかし、環境上の制約があるために、テーブルの形状を変更するのは容易ではありません。そこで、代替策を用意しました。クエリを実行する前に月のパーティションを計算し、start_date フィールドにある月を基に、適切なパーティションを選択するというものです。
QUERY EXPLAINプランが適切なインデックスを使用していない場合は、それらを作成します。同じように、使っていないインデックスを破棄することも、不要なメンテナンスコストとストレージを削減する上で重要です。全インデックスを確認します。次にしめすクエリがスタート地点として使えます。実稼働に移る前に、全体を通したテストを必ず行います。
- データベース内に作成する必要のないテーブルを見つけます。一般的なユースケースとしては、ログテーブル、ステータステーブル、あるいはその他のテーブルとして、更新されてない、またはレコードレベルでのアクセス頻度が低いテーブルが挙げられます。これらは、データベースにではなく Amazon S3 に保存先を移す場合の主要な候補となります。そうすれば、料金が高いデータベース I/O とストレージを削減できます。これらのテーブルを S3 に保存しようとする際は、書き込みの前に Parquet に変換することも検討してください。この目的には、Amazon Kinesis Data Firehose が、低料金で直接的な手段を提供してくれます。同時に、パーティショニングを適切に行うこと、そして AWS Glue によりカタログ化をすることも忘れないようにしましょう。これで、データをデータベーステーブルと同じように扱えます。
私は、I/O のチューニングを行ったところ、月ごとの請求を 50% 以上削減できました。
データベースインスタンスのサイズ
データベースインスタンスのサイズは、コストの中で顕著な割合を占めます。
- ワークロードのチューニングを行い、処理負荷の変化について理解した後は、リザーブドインスタンスを購入します。AWS では、同じインスタンスファミリーでリザーブドインスタンスを柔軟に適用できます。たとえば、r5.large と r5.xlarge のどちらが必要か最初の段階では分からない場合、最小限の規模で開始しつつ、リザーブドインスタンスを購入しておき、必要になった際に r5.large から r5.xlarge に増やすようにします。リザーブドインスタンスが、r5.xlarge の部分をカバーし、その他の部分にはオンデマンド料金がかかります。いつでもリザーブドインスタンスの追加購入を行い、ギャップをカバーさせることが可能です。
- インスタンスサイズを大きくし、先に述べた通りに I/O コストが削減するかをテストします。リザーブドインスタンスの購入によりインスタンスのコストは減ります。ただし、リザーブドインスタンスは I/O を考慮しては作られていません。
- まったく同じく定義されたデータベースと可用性が実稼働と試験段階のアカウントで本当に必要かを検討します。 試験段階のアカウントでは、インスタンスサイズを小さくすると容易にコスト削減が行えます。加えて、試験段階のアカウントでは、Multi-AZ を有効化する必要もないと言えるでしょう。
データベースストレージ
ストレージは、コストの残り 5% を占めます。
- Aurora PostgreSQL のストレージコストは、使用量の最高水準値を基に決まります。データベースからデータを削除してもストレージコストは削減されません。つまり、古いパーティションを定期的に S3 に移動することでアーカイブし、パーティションを小さく保つことがベストプラクティスになります。また、インデックスサイズが小さくなるために、I/O にとっても有利です。
- 注意すべきなのは、データ移行処理の最中は、データの一時ストレージで使用料がピークとなることです。このため、データは定期的にクリーニングしておくことが最良策となります。
- バックアップストレージを管理します。各 Aurora DB クラスターでは、Aurora データベースストレージのバックアップは、最大で 100% までの容量なら追加料金はかかりません。 追加で行った手動バックアップで不要なものは、定期的に削除されます。
追加コスト
コストを簡単に増加するための他の一般的サービスには、次のようなものがあります。
- CloudWatch ロギング: API ゲートウェイのログ作成の一例を次に示します。
- 通常は、開発者モードでのログレベルは
INFOに設定されています。この設定は、次に示すスクリーンショットを参考に、ERRORに忘れずに戻しておきます。 - また、Log full requests/responses data も忘れずにオフにしておきます。
- 通常は、開発者モードでのログレベルは

- Kinesis ストリーム: 通常これは、シャードがプロビジョニングされた場合を除き、使用量に対し課金されます。つまり、使っているかいないかに関わらず、固定の料金が発生します。試験段階の環境では、Kinesis のシャードを削減することも検討します。
- S3: S3 でのコストを低く抑えるには次のようにします。
- すべての一時的および冗長的なオブジェクトを減らします。
- ライフサイクルポリシーを設定することで、データの削除や低コストストレージへの移動などを実行できます。
- Amazon EC2: EC2 でのコストを低く抑えるには次のようにします。
- 冗長的な EC2 インスタンスを減らします。
- EC2 インスタンスのサイズを適切に設定します。
- バッチやユーティリティのジョブは、削減もしくは統合、および時間差処理にして、EC2 インスタンスを完全に活用します。
- リザーブドインスタンスの購入を利用して基礎的容量を確保します。
- 使っていない EBS ボリュームはすべて削除します。
- AWS CloudTrail: CloudTrail のコストは簡単に増加します。特に、数百万規模の Lambda 関数を実行するサーバーレスアーキテクチャがある場合などは顕著です。
- トレイルは 1 つなら無料です。仮に複数のトレイルを使用しているのなら、本当に必要か考慮するようにします。
結論
要約すると以下のとおりです。
- 使用している環境を理解する
- 疑問を投げかける
- 調査を行う
どのサービスについても、その使用期間や使うリソースの妥当性を見直しましょう。私は、先にあげた手順を行ったところ、数週間の内にコストを初期の推定額より削減することができました。
ご不明な点がございましたら、お気軽にコメントをお寄せください。
この記事の内容および意見は第三者の作者によるものであり、AWS はこの記事の内容または正確性について責任を負いません。
著者について
 Sundeep Sardana は、 Verisk 社の副社長であり、IoT 部門のチーフアーキテクトです。Sundeep は、テレマティクス用のオンプレミスアプリケーションをクラウドネイティブなサーバーレスアプリケーションに設計しなおし、AWS 上で実装するプロジェクトを指揮しました。Verisk に参加する以前の Sundeep は、HBO のデータ統合部門において、高速大容量データ処理アプリケーションの開発責任者として 10 年間勤務していました。Sundeep は変化を生み出す人であり AWS のエバンジェリストで、組織によるクラウドへの移行を支援する専門家でもあります。彼は、大学で機械工学を専攻しました。Sundeep はニューヨーク市に住んでおり、そこで働いています。
Sundeep Sardana は、 Verisk 社の副社長であり、IoT 部門のチーフアーキテクトです。Sundeep は、テレマティクス用のオンプレミスアプリケーションをクラウドネイティブなサーバーレスアプリケーションに設計しなおし、AWS 上で実装するプロジェクトを指揮しました。Verisk に参加する以前の Sundeep は、HBO のデータ統合部門において、高速大容量データ処理アプリケーションの開発責任者として 10 年間勤務していました。Sundeep は変化を生み出す人であり AWS のエバンジェリストで、組織によるクラウドへの移行を支援する専門家でもあります。彼は、大学で機械工学を専攻しました。Sundeep はニューヨーク市に住んでおり、そこで働いています。