Amazon Web Services ブログ
Amazon Elastic Inference を使用して ONNX モデルを実行する
re:Invent 2018 で、AWS は Amazon Elastic Inference (EI) を発表しました。これは、すべての Amazon EC2 インスタンスに適切な量の GPU による推論アクセラレーションを追加できる新しいサービスです。これは、 Amazon SageMaker のノートブックインスタンスとエンドポイントにも利用可能で、ビルトインアルゴリズムや深層学習環境にアクセラレーションをもたらします。
このブログ記事では、GitHub で ONNX Model Zoo のモデルを使用して、MXNet と Elastic Inference Accelerator (EIA) をバックエンドとして推論を実行する方法を示します。
Amazon Elastic Inference のメリット
Amazon Elastic Inference を使用すると、低コストの GPU によるアクセラレーションを Amazon EC2 および Amazon SageMaker インスタンスに適用して、深層学習推論の実行コストを最大 75% 削減できます。
Amazon Elastic Inference は、Apache MXNet、TensorFlow、および ONNX モデルをサポートしています。ONNX は、Apache MXNet、Caffe2、Microsoft Cognitive Toolkit (CNTK)、PyTorch などの深層学習フレームワーク間の相互運用を可能にする深層学習モデルのオープンな標準形式です。つまり、これらのフレームワークのいずれかを使用してモデルをトレーニングし、そのモデルを ONNX 形式でエクスポートしてから、推論のために Apache MXNet にインポートすることができます。
GitHub の ONNX Model Zoo で、事前にトレーニングされた最先端のモデルのコレクションを ONNX 形式で見ることができます。
Resnet 152v1 モデルを使用して推論を開始する
チュートリアルを始めるために、すでに Apache MXNet、EIA、ONNX、およびその他の必要なライブラリをサポートしている AWS Deep Learning AMI (DLAMI) を使用します。Elastic Inference に関連する手順については、Elastic Inference の前提条件で確認できます。Elastic Inference Accelerator を使用して DLAMI を起動する方法の詳細については、Elastic Inference のドキュメントを参照してください。MXNet での推論には、モデル zoo の標準 ResNet-152v1 ONNX モデルを使用します。
ステップ 1: MXNet EI 環境を有効にする
チュートリアルを開始するには、Conda コンソールで Deep Learning AMI にログインします。Python 3 MXNet EI 環境を有効にします。
ステップ 2: 依存関係をインポートしてダウンロードする
ONNX モデル zoo から、Resnet-152v1 モデルとクラスラベルを含む synset.txt ファイルの両方をダウンロードします。
ステップ 3: MXNet に ONNX モデルをインポートして、推論を実行する
ONNX-MXNet API を使用して、ONNX モデルを MXN にインポートします。
CPU コンテキストを使用した推論のために resnet152v1 ネットワークをロードします。
入力画像のパスをたどり、上位 5 つの予測を出力する予測関数を定義します。
推論のために入力画像をプロットします。

ステップ 4: 入力画像で予測を生成する
表示されている画像に対して生成された確率と共に、上位 5 のクラスは、順に、以下のとおりです。
出力を評価してパフォーマンスを向上させる
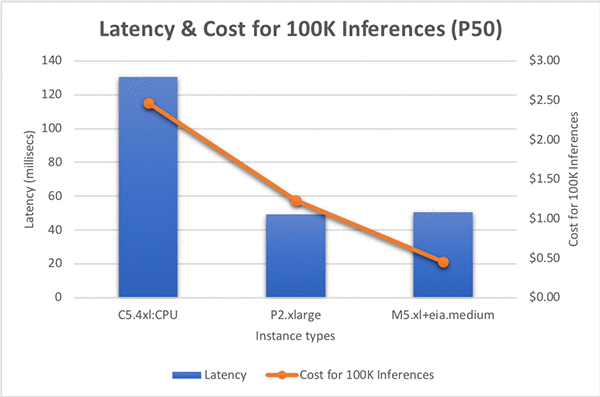
このモデルの推論は、C5.4xlarge で約 131 ミリ秒かかります。したがって、100,000 件の推論要求の場合、これには 2.46 USD の費用がかかります。これは、本稼働のユースケースでは高価である可能性があります。それでは、Amazon Elastic Inference がどのように役立つかを見てみましょう。
Amazon Elastic Inference には以下の 3 つのサイズがあり、画像処理や自然言語処理、音声認識などの様々な種類の推論モデルに対して効率的に使い分けることができます。
- eia1.medium: 8 TFLOPS の混合精度演算
- eia1.large: 16 TFLOPS の混合精度演算
- eia1.xlarge: 32 TFLOPS の混合精度演算
これにより、アプリケーションに最適な価格/性能比を選択できます。コストとパフォーマンスの違いを見るために、GPU と EIA のコンテキストを使用して同じモデルで推論を実行しました。
モデルを mx.eia() コンテキストで実行するには、コードを少し変更するだけです。
- EIA コンテキストで、Symbol API または Module API を使用するときは、必ず
for_training=Falseと設定してください。 - コンテキストを設定して、モデルを
ctx=mx.eia()とバインドします。
EI は通常、EI アクセラレータにオフロードすることでホストインスタンスの CPU メモリ要件を最小限に抑えようとしていますが、それでもホストでの前処理と後処理の実行が必要になる場合があります。アプリケーションのコンピューティング要件とメモリ要件に応じて、最も適切なインスタンスタイプを選択できます。
このモデルのパフォーマンスを C5 および M5 インスタンスで評価しましたが、このモデルではより多くの CPU メモリが必要であることがわかりました。より多くの RAM を備えた M5 インスタンスが最も費用対効果の高いソリューションでした。EIA1.Medium アクセラレータを使用して、サイズの異なるいくつかの M5 インスタンスでテストを実行しましたが、M5.xlarge よりも大きいインスタンスサイズではレイテンシパフォーマンスが大幅に向上するわけではないことを確認しました。次に、異なるサイズの EI アクセラレータで M5.xlarge をテストしました。EIA1.large アクセラレータを使用した推論呼び出しは EIA1.Medium よりもかなり高速でしたが、推論要求に対して 50 ミリ秒での EIA1.Medium が要件を満たしていたので、それ以上の処理能力は必要ありませんでした。
要件に基づいて、ワークロードに適したインフラストラクチャの組み合わせとして EIA1.Medium を使用する M5.xlarge を選択しました。インスタンスの時間あたりのコストを比較すると、P2.xlarge は 1 時間あたり 0.90 USD、M5.xlarge + EIA1.Medium は 1 時間あたり 0.32 USD、最後に C5.4xlarge は 1 時間あたり 0.68 USD です。ただし、100,000 回の推論を実行する場合のコストも比較してみましょう。これには、1 時間ごとのコストとパフォーマンスが組み込まれ、意味のある比較ができます。P2.xlarge は 100,000 回の推論を実行するのに 1.23 USD かかりますが、この新しい EI ベースの組み合わせのコストは 0.45 USD であり、なんと 74% のコスト削減で、速度の犠牲はわずか 2% で済みます。C5.4xlarge を使うと、コストは 2.47 USD となり、M5.xlarge + EIA1.Medium より 2.5 倍も遅くなります! 詳しくは下のグラフをご覧ください。
結論
このチュートリアルから分かるように、Amazon Elastic Inference は、アプリケーションに最適な価格対パフォーマンスの比率を選択する機会を与えてくれます。ONNX ResNet152 モデルによる推論では、EIA1.medium は C5.4xlarge より 2.5 倍速く、81% も安価です! また、ONNX サポートにより、さまざまな深層学習フレームワークでトレーニングされたモデルをエクスポートして、バックエンドとして Apache MXNet を使用して EIA で推論を実行することができます。
EI の使用方法に関する一般的な情報については、EC2 ユーザーガイドの Amazon EI の操作を参照してください。また、MXNet での ONNX サポートに関する詳細情報は、MXNet ウェブサイトにある ONNX API ドキュメントにもあります。
著者について

Roshani Nagmote は、AWS Deep Learning のソフトウェア開発者です。 彼女は、すべての人が深層学習を簡単に利用できるようにするための分散型深層学習システムおよび革新的なツールの構築に焦点を当てています。余暇には、彼女はハイキングを楽しんだり、新しい場所を探検したり、大変な愛犬家でもあります。
 Vandana Kannan は、AWS Deep Learning のソフトウェア開発者であり、スケーラブルな深層学習システムの構築に焦点を当てています。余暇には、彼女は絵を描くこと、インドの古典舞踊を学ぶこと、そして家族や友人と過ごすことを楽しんでいます。
Vandana Kannan は、AWS Deep Learning のソフトウェア開発者であり、スケーラブルな深層学習システムの構築に焦点を当てています。余暇には、彼女は絵を描くこと、インドの古典舞踊を学ぶこと、そして家族や友人と過ごすことを楽しんでいます。
 Hagay Lupesko は、AWS Deep Learning のエンジニアリングマネージャーです。開発者や科学者がインテリジェントなアプリケーションを実現できるような深層学習ツールの構築に注力しています。余暇には、彼は読書、ハイキング、家族との時間を楽しんでいます。
Hagay Lupesko は、AWS Deep Learning のエンジニアリングマネージャーです。開発者や科学者がインテリジェントなアプリケーションを実現できるような深層学習ツールの構築に注力しています。余暇には、彼は読書、ハイキング、家族との時間を楽しんでいます。