Amazon Web Services ブログ
MXNet と Amazon Elastic Inference を使った Java ベースの深層学習の実行
Amazon Elastic Inference 向けの新しい MXNet 1.4 のリリースには、Java および Scala のサポートが含まれています。Apache MXNet は、ディープニューラルネットワークの構築、訓練、およびデプロイメントに使用されるオープンソースの深層学習フレームワークです。Amazon Elastic Inference (EI) は、Amazon EC2 および Amazon SageMaker インスタンスに低コストの GPU 駆動のアクセラレーションをアタッチできるようにするサービスです。Amazon EI は、深層学習推論の実行コストを最大 75% 削減します。この記事では、MXNet および Elastic Inference アクセラレーター (EIA) を使って Java で推論を実行する方法について説明します。
Amazon EC2 での Amazon Elastic Inference のセットアップ
Amazon EI アクセラレーターがアタッチされた EC2 インスタンスを開始するには、AWS アカウントのセットアップ時にいくつかの事前設定ステップが必要になります。必要なものはすべて、セットアップツールを使用して簡単に開始することができます。または、Amazon Elastic Inference ドキュメントにある手順に従って、アクセラレーターでインスタンスを起動することもできます。ここでは、基本的な Ubuntu Amazon Machine Image (AMI) で開始し、必要に基づいて設定を行います。SSH 経由でインスタンスに接続し、以下の依存関係をインストールすることから始めます。
Java プロジェクトのセットアップ
デモプロジェクトをダウンロードして解凍することから始めます。
アーカイブ内には、Amazon EI MXNet の依存関係でプロジェクトを構築する pom.xml があります。これは、Amazon EI MXNet パッケージが含まれる Amazon S3 に置かれた追加の Maven リポジトリを使用します。
そして、プロジェクトの pom.xml には Apache MXNet の Amazon EI ビルドへの依存性があります。
これらの変更により、Maven は適切なリポジトリにアクセスでき、自動的に Amazon EI MXNet jar をダウンロードして、プロジェクトからアクセスできるようにします。
ResNet-152 アプリケーションの作成
このセクションでは、以下にあるアーカイブのデモコードについて順を追って説明していきます。
ResNet-152 モデルを使ってシンプルなイメージ分類を実行するコードを記述しましょう。まず、このモデル、異なるイメージ分類ラベルの名前、およびテストイメージをダウンロードする必要があります。
次に、Predictor オブジェクトを作成してモデルを実行します。これは、イメージを、各イメージが 3 x 224 x 224 の NDArray フロートであるイメージの 1 要素のバッチとして取り込みます。イメージはこのモデルに対する唯一の入力であるため、その inputDescriptor を唯一の要素としてリストを作成します。また、ローカルファイルシステム上のモデルへのパスも提供します。この Predictor を Amazon EI で実行するために、Context.eia() をパスします。また、Context.cpu() を使って、推論を CPU のみでローカルに実行することもできます (これはデバッグに便利です)。
Predictor ができたので、予測を実行するためのイメージを取得する必要があります。ObjectDetector クラスには、このプロセスをシンプル化するために役立つユーティリティがあります。ファイルからイメージをロードし、それを 224 x 224 に再形成して、NDArray に変換しましょう。
最後に、Predictor を使ってイメージで推論を実行します。
イメージの予測されたクラスの上位 5 位を印刷しましょう。予測を実行した後は、信頼値が最も高い結果を見つけなければなりません。次に、synset.txt ファイルから、結果内の各要素に対応する名前を探す必要があります。
ResNet-152 アプリケーションの構築と実行
プロジェクトを構築するには、README と pom.xml が格納されているメインディレクトリに移動し、mvn package を実行します。構築後、mvn exec:java -Dexec.mainClass=mxnet.ImageClassificationDemo -Dexec.cleanupDaemonThreads=false を使ってこの例を実行できます。
テストの実行により、以下の結果が生成されます。
これに関する詳細については、「Elastic Inference with MXNet Java API Documentation」をお読みください。
コストとパフォーマンスの向上
1 つの推論コールを完了するために必要なレイテンシーまたは時間を使って、各種設定のパフォーマンスを分析しましょう。Amazon EI アクセラレーターは現在、eia1.medium、eia1.large、および eia1.xlarge の 3 つのサイズで利用でき、それぞれに 1~4 GB のメモリと、8~32 TFLOPS のコンピューティング能力があります。 この例では、resnet-152 モデルを、P2、P3、C5.4xlarge、および C5.large の EC2 インスタンスタイプで、すべての EIA オプションを使って実行します。
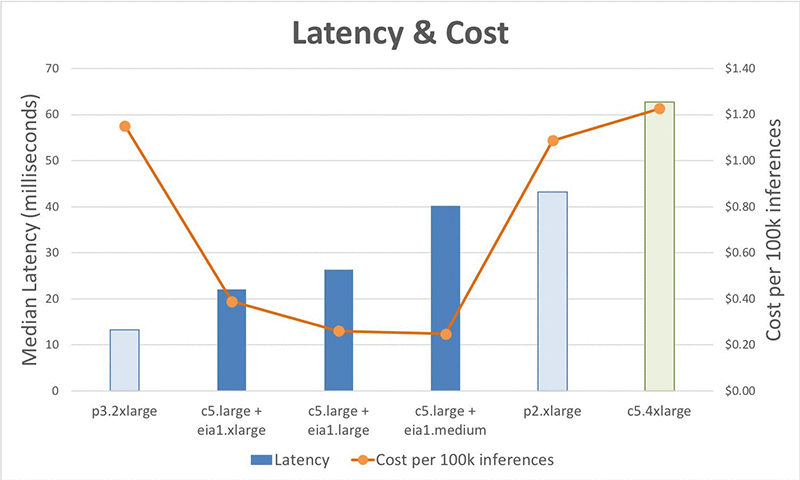
結果を見ると、標準インスタンスのレイテンシーは、最良のインスタンスから順に、P3 で 13.26ms、P2 で 43.52ms、および C5.4xlarge で 64.91ms であることが分かります。EIA インスタンスのレイテンシーは、最高レベルの P3 と、中レベルの P2 の範囲内に収まります (c5.large + eia1.xlarge で 22.11ms、c5.large + eia1.large で 26.28ms、および c5.large + eia1.medium で 41.7ms)。しかし、標準 EC2 インスタンスのコスト効率性は、10 万推論あたり 1.08~1.19 USD の範囲である一方、Amazon EI アクセラレーターインスタンスのコスト効率性は 0.24~0.37 USD であり、最大 78% の節約となります。
c5.4xlarge などの CPU インスタンスでの推論の実行と比較して、Amazon EI オプションは最大 56% 高速で、コストも低くなります。これらは、P2 よりもコストが最大 76% 低い上に、パフォーマンスも高くなっています。P3 インスタンスではレイテンシーがより低くなっていますが、同じ価格で最大 13 個の Amazon EI インスタンスを入手でき、これは 93% 安い価格です。
要するに、アプリケーションが最小のレイテンシーを必要とする場合は、P3 インスタンスタイプを使用し続ける必要があるでしょう。しかし、わずかに高いレイテンシーをアプリケーションが許容できる場合は、Amazon EI を利用し、P2 および P3 インスタンスのコストと比較して 78% のコスト節約を実現することができます。EIA インスタンスの結果は、EIA が P2 インスタンスと P3 インスタンスの間のレベルでの raw パフォーマンスという点でもうひとつのオプションを提供しながら、どのインスタンスタイプでも最も優れたコスト効率性を提供することを示しています。CPU、GPU、および EIA フレーバー間の詳しいパフォーマンス比較については、付録 1 を参照してください。
結論
Amazon EI における MXNet に対する Java/Scala サポートは、Java アプリケーションがコスト効率性に優れた深層学習アクセラレーションを既存の本番システムに追加することを可能にします。Amazon EI アクセラレーターを使用することにより、CPU のみを使用する場合と比較して、推論コストを最大 78% 削減しながら、レイテンシーを 56% 低減することができます。
Amazon EI と Java API の使用の開始
Amazon EI の使用開始、必要なインフラストラクチャのセットアップ、およびモデルの本番へのデプロイメントを行う方法に関する詳細については、Model serving with Amazon Elastic inference および Amazon Elastic Inference – GPU powered deep learning inference acceleration のブログ記事を参照してください。MXNet の詳細については、Java MXNet API Reference および Apache MXNet ウェブサイトをご覧ください。
付録 1 – ResNet-152 の raw パフォーマンスとコストの結果
この表は、Amazon Elastic Inference の使用時および未使用時の両方で、多数のインスタンスタイプ全体から収集されたデータを示すものです。これには、単一予測を実行する時間 (レイテンシー)、1 秒あたりの予測数 (スループット)、インスタンスのコスト、およびコスト効率性 (USD/10万推論) が提供されています。例えば、主な目標がコストを制御しながら最小のレイテンシーを実現することである場合 (例: 高額な GPU ホストを使いたくない)、最良の選択のひとつは eia1.xlarge アクセラレーターと共に c5.2xlarge インスタンスを使用することです。主な目標がコストの最小限化であり、レイテンシー要件はそれほど厳しくないという場合、eia1.large アクセラレーターと共に c5.large インスタンスを使用できます。レイテンシー最適化ケースと比較して推論時間は最大 28% 増加しますが、対応するコスト削減は最大 50% になります。
これらのメトリクスは Resnet-152 モデルのみのものであることに留意してください。最良のオプションを見つけるには、お使いのアプリケーションのモデルでデータを収集する必要があります。
| インスタンスタイプ | p50 レイテンシー | p90 レイテンシー | スループット/秒 | インタンスコスト/時間 | USD/10 万インスタンス | 注意 |
| c5.4xlarge | 62.73 | 64.91 | 15.94 | 0.68 USD | 1.19 USD | |
| c5.9xlarge | 39.61 | 39.81 | 25.25 | 1.53 USD | 1.68 USD | |
| c5.large + eia1.medium | 40.19 | 41.37 | 24.88 | 0.22 USD | 0.24 USD | |
| c5.large + eia1.large | 26.28 | 27.15 | 38.05 | 0.35 USD | 0.25 USD | EI を使用したコスト効率性に最適 |
| c5.large + eia1.xlarge | 22.11 | 23.13 | 45.23 | 0.61 USD | 0.37 USD | |
| c5.xlarge + eia1.medium | 39.62 | 41.35 | 25.24 | 0.30 USD | 0.33 USD | |
| c5.xlarge + eia1.large | 26.24 | 26.92 | 38.11 | 0.43 USD | 0.31 USD | |
| c5.xlarge + eia1.xlarge | 21.04 | 21.61 | 47.52 | 0.69 USD | 0.40 USD | |
| c5.2xlarge + eia1.medium | 38.8 | 43.24 | 25.78 | 0.47 USD | 0.50 USD | |
| c5.2xlarge + eia1.large | 26.27 | 27.03 | 38.07 | 0.60 USD | 0.44 USD | |
| c5.2xlarge + eia1.xlarge | 20.89 | 21.26 | 47.88 | 0.86 USD | 0.50 USD | EI を使ったレイテンシーに最適 |
| p2.xlarge | 43.23 | 43.52 | 23.13 | 0.90 USD | 1.08 USD | |
| p3.2xlarge | 13.26 | 13.54 | 75.44 | 3.06 USD | 1.13 USD |
著者について
 Zach Kimberg は、主に Java および Scala 向けの Apache MXNet に取り組む AWS 深層学習のソフトウェアエンジニアです。仕事以外では、特にファンタジーの本を読むことが好きです。
Zach Kimberg は、主に Java および Scala 向けの Apache MXNet に取り組む AWS 深層学習のソフトウェアエンジニアです。仕事以外では、特にファンタジーの本を読むことが好きです。
 Sam Skalicky は、高機能の異種コンピューティングシステムの構築を楽しむ AWS 深層学習のソフトウェアエンジニアです。Sam は熱烈なコーヒー愛好家ですが、ハイキングだけは何としてでも行きたくありません。
Sam Skalicky は、高機能の異種コンピューティングシステムの構築を楽しむ AWS 深層学習のソフトウェアエンジニアです。Sam は熱烈なコーヒー愛好家ですが、ハイキングだけは何としてでも行きたくありません。
 Denis Davydenko は AWS 深層学習のエンジニアリングマネージャーです。開発者や科学者がインテリジェントなアプリケーションを実現できるような深層学習ツールの構築に注力しています。余暇には、ポーカー、ビデオゲーム、家族との時間を楽しんでいます。
Denis Davydenko は AWS 深層学習のエンジニアリングマネージャーです。開発者や科学者がインテリジェントなアプリケーションを実現できるような深層学習ツールの構築に注力しています。余暇には、ポーカー、ビデオゲーム、家族との時間を楽しんでいます。