Amazon Web Services ブログ
AWS Glue 5.0 の Apache Spark におけるオープンテーブルフォーマット機能の活用
本記事は 2024 年 12 月 4 日 に公開された「Use open table format libraries on AWS Glue 5.0 for Apache Spark」を翻訳したものです。
オープンテーブルフォーマットは、急速に進化するビッグデータ管理の領域で台頭しており、データストレージと分析の状況を根本的に変えています。Apache Iceberg、Apache Hudi、Delta Lake に代表されるこれらのフォーマットは、柔軟性、パフォーマンス、ガバナンス機能の高度な組み合わせを提供することで、従来のデータレイク構造における永続的な課題に対処しています。データ表現の標準化されたフレームワークを提供することで、オープンテーブルフォーマットはデータサイロを解消し、データ品質を向上させ、大規模な分析を加速します。
組織が指数関数的なデータ増加とますます複雑化する分析要件に取り組む中、これらのフォーマットはオプションの拡張機能から競争力のあるデータ戦略の必須コンポーネントへと移行しています。データの一貫性、クエリ効率、ガバナンスなどの重要な問題を解決する能力により、データ駆動型組織にとって不可欠なものとなっています。オープンテーブルフォーマットの採用は、データ管理プラクティスを最適化し、データから最大の価値を引き出そうとする組織にとって重要な検討事項です。
以前の投稿では、AWS Glue 5.0 for Apache Spark について説明しました。この投稿では、AWS Glue 5.0 における Iceberg、Hudi、Delta Lake の注目すべきアップデートを紹介します。
Apache Iceberg のハイライト
AWS Glue 5.0 は Iceberg 1.7.1 をサポートしています。このセクションでは、注目すべきアップデートを紹介します。詳細については、Iceberg Release 1.7.1 を参照してください。
ブランチ
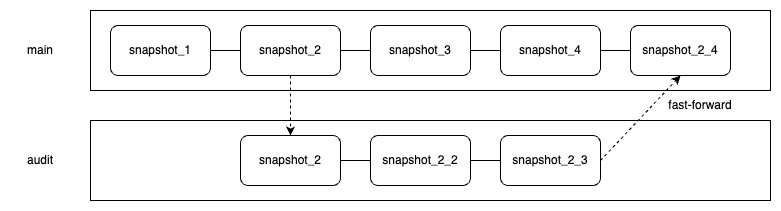
ブランチは、各系統のヘッドを指すスナップショット履歴の独立した系統です。これらは柔軟なデータライフサイクル管理に役立ちます。Iceberg テーブルのメタデータは、各トランザクションで更新されるスナップショットの履歴を保存します。Iceberg は、これらのスナップショットの系統を通じてテーブルのバージョン管理や同時実行制御などの機能を実装しています。Iceberg テーブルのライフサイクル管理を拡張するために、他のブランチから派生するブランチを定義できます。各ブランチには独立したスナップショットライフサイクルがあり、個別の参照と更新が可能です。
Iceberg テーブルが作成されると、暗黙的に作成される main ブランチのみが存在します。すべてのトランザクションは最初にこのブランチに書き込まれます。audit ブランチなどの追加ブランチを作成し、エンジンがそれらに書き込むように設定できます。あるブランチの変更は、Spark の fast_forward プロシージャを使用して別のブランチにファストフォワードできます。
次の図は、このセットアップを示しています。
新しいブランチを作成するには、次のクエリを使用します。
ブランチを作成した後、branch_<branch_name> を指定することで、ブランチ内のデータに対してクエリを実行できます。特定のブランチにデータを書き込むには、次のクエリを使用します。
特定のブランチをクエリするには、次のクエリを使用します。
次のクエリを使用して fast_forward プロシージャを実行し、サンプルテーブルデータを audit ブランチから main ブランチに公開できます。
タグ
タグは、特定のスナップショット ID への論理的なポインタであり、ビジネス目的で重要な履歴スナップショットを管理するのに役立ちます。Iceberg テーブルでは、各トランザクションで新しいスナップショットが作成され、スナップショット ID またはタイムスタンプを指定してタイムトラベルクエリを使用して履歴スナップショットをクエリできます。ただし、スナップショットはすべてのトランザクションで作成されるため、重要なものを区別することが困難な場合があります。タグは、任意の名前で特定のスナップショットを指すことができるため、この問題に対処するのに役立ちます。
例えば、次のコードでスナップショット 2 に event タグを設定できます。
次のコードを使用して、タグ付けされたスナップショットをクエリできます。
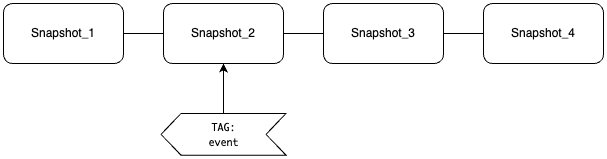
ブランチとタグによるライフサイクル管理
ブランチとタグは、独立したスナップショットライフサイクル管理設定による柔軟なテーブルメンテナンスに役立ちます。Iceberg テーブルでデータが変更されると、各変更は新しいスナップショットとして保存されます。時間の経過とともに、変更が蓄積されるにつれて、複数のデータファイルとメタデータファイルが作成されます。これらのファイルはタイムトラベルクエリなどの Iceberg 機能に不可欠ですが、スナップショットが多すぎるとストレージコストが増加する可能性があります。さらに、大量のメタデータを処理するオーバーヘッドにより、クエリパフォーマンスに影響を与える可能性があります。そのため、組織は不要になったスナップショットの定期的な削除を計画する必要があります。
AWS Glue Data Catalog は、マネージドストレージ最適化機能を通じてこれらの課題に対処します。その最適化ジョブは、保持するスナップショットの数とスナップショットを保持する最大日数という 2 つの設定可能なパラメータに基づいてスナップショットを自動的に削除します。重要なのは、ブランチとタグ付きスナップショットの両方に独立したライフサイクルポリシーを設定できることです。
ブランチについては、スナップショットを保持する最大日数と、最大保持期間を超えても保持する必要があるスナップショットの最小数を制御できます。この設定は各ブランチで独立しています。
例えば、スナップショットを 7 日間保持し、少なくとも 10 個のスナップショットを保持するには、次のクエリを実行します。
タグは、データの特定のスナップショットへの永続的な参照として機能します。有効期限を設定しないと、タグ付きスナップショットは無期限に保持され、最適化ジョブが関連するデータファイルをクリーンアップするのを防ぎます。参照を作成するときに、保持する期間の制限を設定できます。
例えば、event でタグ付けされたスナップショットを 360 日間保持するには、次のクエリを実行します。
このブランチとタグ機能の組み合わせにより、さまざまなビジネス要件とユースケースに対応できる柔軟なスナップショットライフサイクル管理が可能になります。Data Catalog の自動ストレージ最適化機能の詳細については、The AWS Glue Data Catalog now supports storage optimization of Apache Iceberg tables を参照してください。
変更ログビュー
create_changelog_view Spark プロシージャは、包括的な変更履歴ビューを生成することで、テーブルの変更を追跡するのに役立ちます。挿入から更新、削除まで、すべてのデータ変更をキャプチャします。これにより、データがどのように進化したかを分析し、時間の経過とともに変更を監査することが簡単になります。
create_changelog_view プロシージャによって作成された変更ログビューには、変更されたレコードの内容、実行された操作の種類、変更の順序、変更がコミットされたスナップショット ID など、変更に関するすべての情報が含まれています。さらに、指定されたキー列を渡すことで、レコードの元のバージョンと変更されたバージョンを表示できます。これらの選択された列は通常、各レコードを一意に識別する個別の識別子または主キーとして機能します。次のコードを参照してください。

プロシージャを実行すると、変更ログビュー test_changes が作成されます。SELECT * FROM test_changes を使用して変更ログビューをクエリすると、Iceberg テーブル内のレコード変更の履歴を含む次の出力を取得できます。

create_changelog_view プロシージャは、データの変更を監視し理解するのに役立ちます。この機能は、変更データキャプチャ (CDC)、監査レコードの監視、ライブ分析など、多くのユースケースで価値があります。
ストレージパーティション結合
ストレージパーティション結合は、Iceberg が提供する結合最適化技術であり、読み取りと書き込みの両方のパフォーマンスを向上させます。この機能は、既存のストレージレイアウトを使用してコストのかかるデータシャッフルを排除し、互換性のあるパーティショニングスキームを共有する大規模なデータセットを結合する際のクエリパフォーマンスを大幅に向上させます。ディスク上のデータの物理的な構成を活用して動作します。両方のデータセットが互換性のあるレイアウトを使用してパーティション化されている場合、Spark は一致するパーティションを直接読み取ることで結合操作をローカルで実行でき、データシャッフルの必要性を完全に回避できます。
ストレージパーティション結合を有効にして最適化するには、SparkConf または AWS Glue ジョブパラメータを通じて次の Spark 設定プロパティを設定する必要があります。次のコードは、Spark 設定のプロパティを示しています。
AWS Glue ジョブパラメータを使用するには、次のように設定します。
- キー:
--conf - 値:
spark.sql.sources.v2.bucketing.enabled=true --confspark.sql.sources.v2.bucketing.pushPartValues.enabled=true --confspark.sql.requireAllClusterKeysForCoPartition=false --confspark.sql.adaptive.enabled=false --confspark.sql.adaptive.autoBroadcastJoinThreshold=-1 --confspark.sql.iceberg.planning.preserve-data-grouping=true
次の例では、ストレージパーティション結合の有無による EXPLAIN クエリで取得したサンプル物理プランを比較しています。これらのプランでは、product_review と customer の両方のテーブルが review_year や product_id などの同じバケットパーティションキーを持っています。ストレージパーティション結合が有効な場合、Spark はシャッフル操作なしで 2 つのテーブルを結合します。
以下は、ストレージパーティション結合なしの物理プランです。
以下は、ストレージパーティション結合ありの物理プランです。
この物理プランでは、ストレージパーティション結合なしの物理プランに存在する Exchange 操作が見られません。これは、シャッフル操作が実行されないことを示しています。
Delta Lake のハイライト
AWS Glue 5.0 は Delta Lake 3.3.0 をサポートしています。このセクションでは、注目すべきアップデートを紹介します。詳細については、Delta Lake Release 3.3.0 を参照してください。
削除ベクトル
削除ベクトルは、Delta Lake の機能で、従来のコピーオンライト (CoW) アプローチの代替として、マージオンリード (MoR) パラダイムを実装しています。この機能は、Delta Lake テーブルでの DELETE、UPDATE、MERGE 操作の処理方法を根本的に変更します。CoW パラダイムでは、1 行を変更するだけでも Parquet ファイル全体を書き換える必要があります。削除ベクトルを使用すると、変更はソフト削除として記録され、論理的な一貫性を維持しながら元のデータファイルはそのまま残ります。このアプローチにより、書き込みパフォーマンスが向上します。
削除ベクトルが有効な場合、書き込み操作中に変更は圧縮されたビットマップ形式でソフト削除として記録されます。読み取り操作中に、これらの変更はベースデータとマージされます。さらに、削除ベクトルによって記録された変更は、REORG コマンドを使用してファイルを書き換えることで、ソフト削除されたデータを物理的に適用できます。
削除ベクトルを有効にするには、テーブルパラメータを delta.enableDeletionVectors = 'true' に設定します。
削除ベクトルが有効な場合、削除ベクトルファイルが作成されていることを確認できます。ファイルは次のスクリーンショットでハイライトされています。
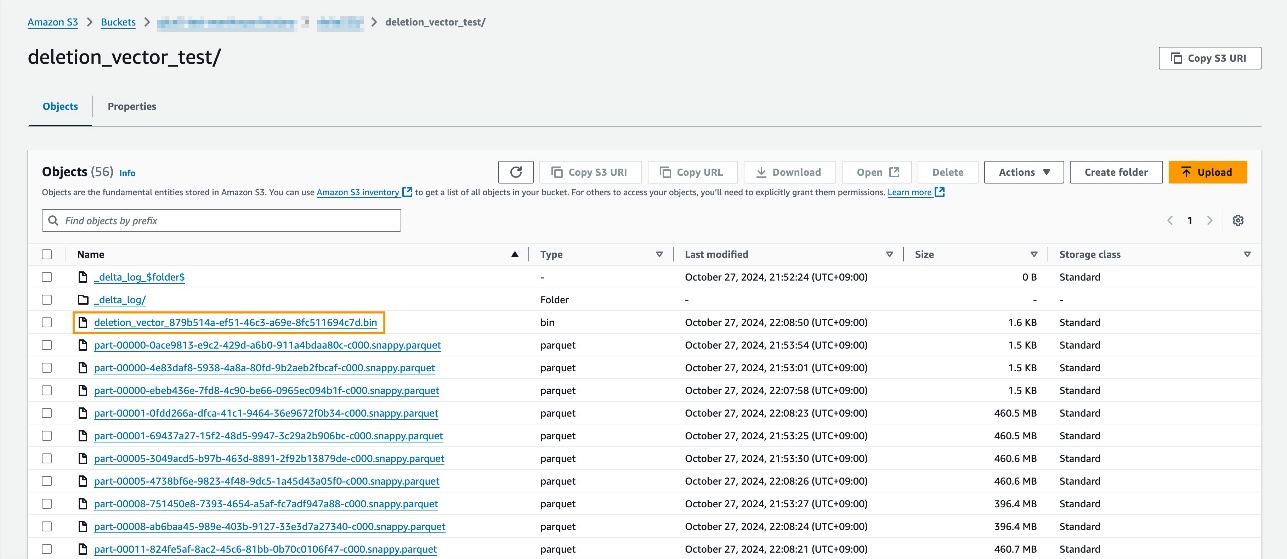
削除ベクトルを使用した MoR は、頻繁な更新があり、データが複数のファイルに分散しているテーブルへの効率的な書き込み操作が必要なシナリオで特に役立ちます。ただし、これらのファイルをマージするために必要な読み取りオーバーヘッドを考慮する必要があります。詳細については、What are deletion vectors? を参照してください。
最適化された書き込み
Delta Lake の最適化された書き込み機能は、データレイクでよくあるパフォーマンスの課題であるスモールファイル問題に対処します。この問題は通常、分散操作を通じて多数の小さなファイルが作成されるときに発生します。データを読み取る際、多くの小さなファイルを処理すると、広範なメタデータ管理とファイル処理により大きなオーバーヘッドが発生します。
最適化された書き込み機能は、複数の小さな書き込みをディスクに書き込む前に、より大きく効率的なファイルに結合することでこの問題を解決します。このプロセスは、書き込み前にエグゼキューター間でデータを再分散し、同じパーティション内に類似のデータを配置します。spark.databricks.delta.optimizeWrite.binSize パラメータを使用してターゲットファイルサイズを制御でき、デフォルトは 512 MB です。最適化された書き込みが有効な場合、出力ファイル数を制御するための従来の coalesce(n) や repartition(n) の使用は不要になります。ファイルサイズの最適化は自動的に処理されるためです。
最適化された書き込みを有効にするには、テーブルパラメータを delta.autoOptimize.optimizeWrite = 'true' に設定します。
最適化された書き込み機能はデフォルトでは有効になっておらず、ファイルがテーブルに書き込まれる前のデータシャッフルにより、書き込みレイテンシが高くなる可能性があることに注意してください。場合によっては、これを自動コンパクションと組み合わせることで、スモールファイルの問題に効果的に対処できます。詳細については、Optimizations を参照してください。
UniForm
Delta Lake Universal Format (UniForm) は、Iceberg と Hudi を通じて Delta Lake テーブルへのシームレスなアクセスを可能にすることで、データレイクの相互運用性へのアプローチを導入しています。これらのフォーマットは主にメタデータレイヤーで異なりますが、Delta Lake UniForm は、単一のデータコピーを参照しながら、Delta Lake と並行して各フォーマット用の互換性のあるメタデータを自動的に生成することでこのギャップを埋めます。UniForm が有効な Delta Lake テーブルに書き込むと、UniForm は他のフォーマット用のメタデータを自動的かつ非同期的に生成します。
Delta UniForm により、組織は単一の Delta Lake ベースのデータソースで操作しながら、各データワークロードに最適なツールを使用できます。UniForm は Iceberg と Hudi の観点からは読み取り専用であり、各フォーマットの一部の機能は利用できません。制限事項の詳細については、Limitations を参照してください。AWS での UniForm の使用方法については、Expand data access through Apache Iceberg using Delta Lake UniForm on AWS をご覧ください。
Apache Hudi のハイライト
AWS Glue 5.0 は Hudi 0.15.0 をサポートしています。このセクションでは、注目すべきアップデートを紹介します。詳細については、Hudi Release 0.15.0 を参照してください。
レコードレベルインデックス
Hudi は、レコードキーを対応するファイルの場所にマッピングするインデックスメカニズムを提供し、効率的なデータ操作を可能にします。これらのインデックスを使用するには、まずテーブルパラメータで hoodie.metadata.enable=true を設定して MoR を使用するメタデータテーブルを有効にする必要があります。Hudi のマルチモーダルインデックス機能により、さまざまな種類のインデックスを保存できます。これらのインデックスにより、ニーズの進化に応じてさまざまなインデックスタイプを追加する柔軟性が得られます。
レコードレベルインデックスは、レコードキーと対応するファイルの場所との間の正確なマッピングを維持することで、書き込みと読み取りの両方の操作を強化します。このマッピングにより、レコードの場所を迅速に特定でき、データ取得時にスキャンする必要があるファイルの数を削減できます。
書き込みワークフローでは、新しいレコードが到着すると、レコードレベルインデックスは、いずれかのファイルグループに存在する場合、各レコードに場所情報をタグ付けします。このタグ付けプロセスにより、書き込みレイテンシを直接削減して効率的な更新操作を実現します。読み取りワークフローでは、レコードレベルインデックスにより、ライターが特定のデータを含むファイルを迅速に見つけることができるため、すべてのファイルをスキャンする必要がなくなります。どのファイルにどのレコードが含まれているかを追跡することで、レコードレベルインデックスは、特にレコードキー列での完全一致を実行する際にクエリを高速化します。
レコードレベルインデックスを有効にするには、次のテーブルパラメータを設定します。
レコードレベルインデックスが有効な場合、次のスクリーンショットに示すように、インデックスを保存するメタデータテーブルに record_index パーティションが作成されます。
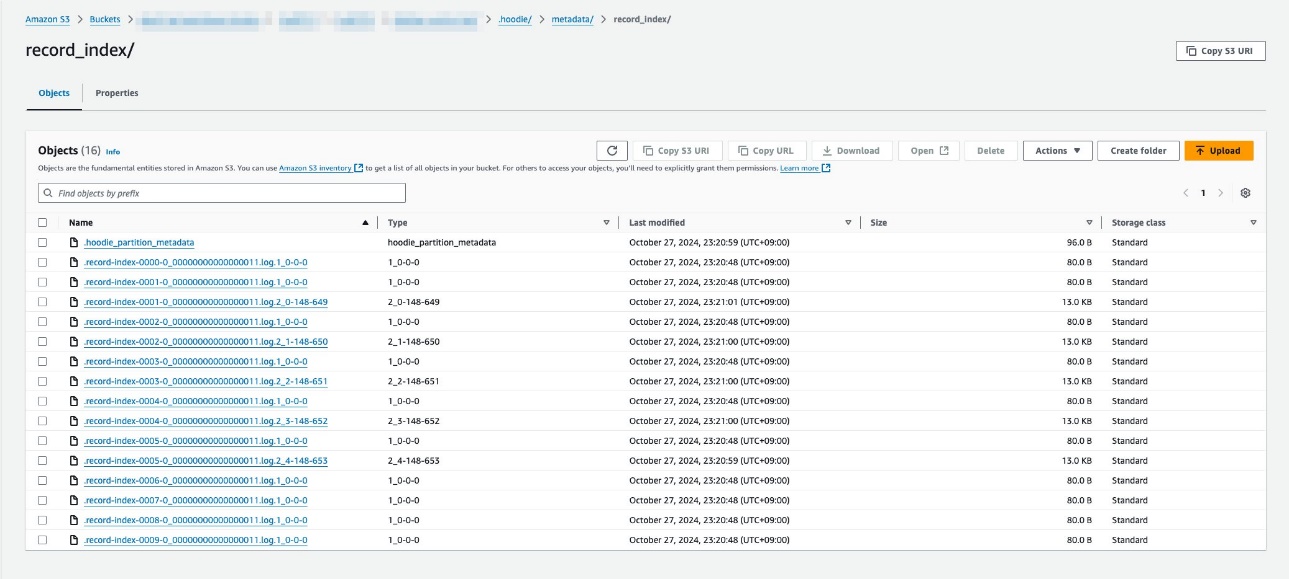
詳細については、Record Level Index: Hudi’s blazing fast indexing for large-scale datasets on Hudi’s blog を参照してください。
自動生成キー
従来、Hudi ではすべてのテーブルに主キーの明示的な設定が必要でした。ユーザーは hoodie.datasource.write.recordkey.field 設定を使用してレコードキーフィールドを指定する必要がありました。この要件は、ログ取り込みシナリオなど、自然な一意の識別子がないデータセットでは課題となることがありました。
自動生成主キーにより、Hudi は主キーを明示的に設定せずにテーブルを作成する柔軟性を提供するようになりました。hoodie.datasource.write.recordkey.field 設定を省略すると、Hudi は一意性要件を維持しながら、計算、ストレージ、読み取り操作を最適化する効率的な主キーを自動的に生成します。詳細については、Key Generation を参照してください。
CDC クエリ
ストリーミング取り込みなどの一部のユースケースでは、単一のコミットに属するレコードのすべての変更を追跡することが重要です。Hudi は、開始と終了のコミット時間の間に変更されたレコードのセットを取得できる増分クエリを提供していますが、レコードの変更前後のイメージは含まれていません。代わりに、Hudi の CDC クエリを使用すると、挿入、更新、削除を含むすべての変更操作をキャプチャして処理でき、時間の経過に伴うデータの完全な進化を追跡できます。
CDC クエリを有効にするには、テーブルパラメータを hoodie.table.cdc.enabled = 'true' に設定します。
CDC クエリを実行するには、次のクエリオプションを設定します。
次のスクリーンショットは、CDC クエリからのサンプル出力を示しています。op 列では、各レコードに対してどの操作が実行されたかを確認できます。出力には、変更されたレコードの変更前後のイメージも表示されます。

この機能は現在 CoW テーブルで利用可能です。MoR テーブルは執筆時点ではまだサポートされていません。詳細については、Change Data Capture Query を参照してください。
まとめ
この投稿では、AWS Glue 5.0 における Iceberg、Delta Lake、Hudi の主要なアップグレードについて説明しました。新しいジョブを作成し、現在のジョブを移行することで、強化された機能をすぐに活用できます。
著者について
 Sotaro Hikita アナリティクスソリューションアーキテクトです。幅広い業界のお客様が分析プラットフォームをより効果的に構築・運用できるよう支援しています。特にビッグデータ技術とオープンソースソフトウェアに情熱を持っています。
Sotaro Hikita アナリティクスソリューションアーキテクトです。幅広い業界のお客様が分析プラットフォームをより効果的に構築・運用できるよう支援しています。特にビッグデータ技術とオープンソースソフトウェアに情熱を持っています。
 Noritaka Sekiyama AWS Glue チームのプリンシパルビッグデータアーキテクトです。東京を拠点に活動しています。お客様を支援するためのソフトウェアアーティファクトの構築を担当しています。余暇にはロードバイクでサイクリングを楽しんでいます。
Noritaka Sekiyama AWS Glue チームのプリンシパルビッグデータアーキテクトです。東京を拠点に活動しています。お客様を支援するためのソフトウェアアーティファクトの構築を担当しています。余暇にはロードバイクでサイクリングを楽しんでいます。
この記事は Kiro が翻訳を担当し、Solutions Architect の Sotaro Hikita がレビューしました。