Amazon Web Services ブログ
Amazon SageMaker アルゴリズムのパイプ入力モードを使用する
本日は Amazon SageMaker の内蔵型アルゴリズムのためのパイプ入力モードについて紹介します。パイプ入力モードを使い、データセットが最初にダウンロードされるのではなく、トレーニングインスタンスに直接ストリーミングされます。これは、トレーニングジョブが直ぐに始まり、早く完了し、必要なディスク容量も少なくて済むという意味です。Amazon SageMakerのアルゴリズムは、高速で拡張性が高くなるように設計されています。このブログ記事では、パイプ入力モード、それがもたらす利点、トレーニングジョブにおいてそれをどのように活用できるかについて説明しています。
パイプ入力モードでは、データはディスク I/O なしで実行中にアルゴリズムコンテナに送られます。このアプローチは、長くかかるダウンロードの処理を短縮し、起動時間を大きく短縮します。それによって通常ならファイル入力モードより読込スループットも良くなります。これは、高度に最適化されたマルチスレッドバックグラウンドプロセスによって、データが Amazon S3 から取得されるからです。また、16 TB の Amazon Elastic Block Store (EBS) のボリュームサイズ制限よりもずっと大きいデータセットをトレーニングできます。
パイプモードによって以下のことが可能になります。
- データがトレーニングインスタンスにダウンロードされるのではなく、ストリーミングされるため、起動時間がより短くなります。
- より高性能なストリーミングエージェントによる I/O スループットの向上
- 実質的に無制限のデータ処理能力。
内蔵型 Amazon SageMaker アルゴリズムでファイル入力モードまたはパイプ入力モードを活用できます。大きなデータセットにはパイプモードが推奨されているとはいえ、メモリ内に収まる小さなファイルやアルゴリズムのエポック数が多い場合であっても、ファイルモードは有効です。現在、どちらのモードでもトレーニングジョブの小さい実験から、ペタバイト規模の分散型のトレーニングジョブに至るまでさまざまな使用範囲をカバーしています。
Amazon SageMakerのアルゴリズム
大半のファーストパーティのAmazon SageMakerアルゴリズムは、最適化された Protocol Buffers (プロトコルバッファー) のrecordIO フォーマットを使えば最適に動作します。このため、本リリースでは、protobuf の recordIO フォーマット用のパイプモードのみがサポートされています。以下に一覧するアルゴリズムは、Protocol Buffers (プロトコルバッファー) の recordIO にエンコードされたデータセットで使用した場合に、パイプ入力モードをサポートします。
- 主成分分析法 (PCA)
- K 平均法クラスタリング
- 因数分解法
- 潜在的ディリクレ配分法 (LDA)
- 線形の学習者 (分類と回帰)
- ニューラルトピックモデリング
- Random Cut Forest (RCF)
ベンチマーク
パイプモードのメリットを示すために、ニューヨーク市のタクシートリップレコードのデータセットで、ファーストパーティの PCA および K-Means アルゴリズムを使用してジョブを実行しました。このデータセットは、AWS Open Data Registry にて誰でも入手できます。
次のベンチマークでは、SageMaker Python SDK を使用して、元のデータセットをプロトコルバッファーrecordIO形式に変換しました。換の結果は1674ファイルで、合計サイズは78.1 GiBでした。次にこの新しいデータセットをAmazon S3パスにアップロードし、トレーニングインスタンスにアクセスできるようにしました。
以下に続く最初のベンチマークは、PCAアルゴリズムを使ってパイプモードとファイルモードを比較します。両方のジョブは、全く同一のハイパーパラメータのセットで実行されます。
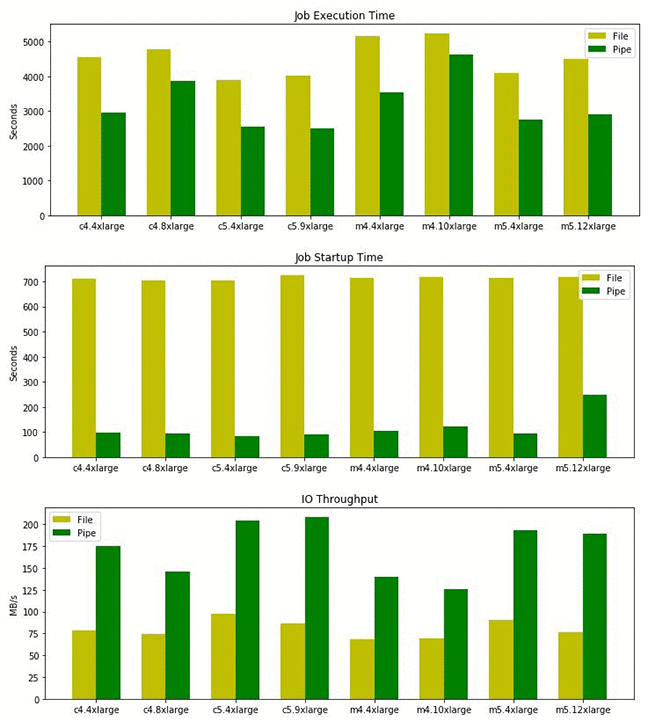
パイプモードでは、ほとんどの実験で起動時間が11.5分から1.5分に大幅に短縮されています。また、I/O スループット全体では、ファイルモードのスループットの少なくとも2倍です。これらの改善によって、トレーニングの合計時間がが最大で35%削減されました。
次に、K-Means アルゴリズムで同じデータセットを使用しましたが、PCA より計算量はずっと多く、パラメータサーバー通信に高いネットワーク帯域幅が必要です。私たちは、3 台のクラスター上で 3 つのエポックのトレーニングジョブを実行しました。
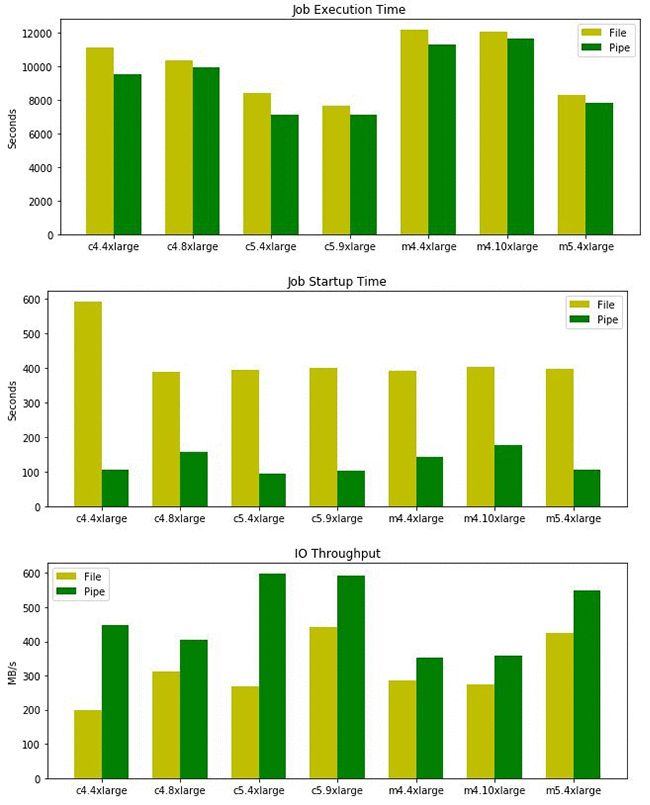
この場合も予想通り、パイプモードの起動時間はファイルモードの起動時間よりもずっと早い結果になりました。ファイルモードは2次エポックのためにファイルシステムのキャッシュを活用できますが、パイプモード全体での I/O スループットはファイルモードよりまだ高速です。K-Means は、ほとんど計算限界に達しているので、総トレーニング時間に対するパイプモードの影響は PCA に比べて劇的とまでいきませんが、それでも重要です。全体的に、パイプモードのジョブは、ファイルモードのジョブよりも10〜25分早く終了し、10GB の EBS ボリュームしか使用しませんでした。 PCAとK-Meansモデルはこの10GBよりかなり小さいですが、場合によってはより複雑なモデル(特にチェックポイントを持つモデル)を上回る可能性があります。
パイプモードの使い方
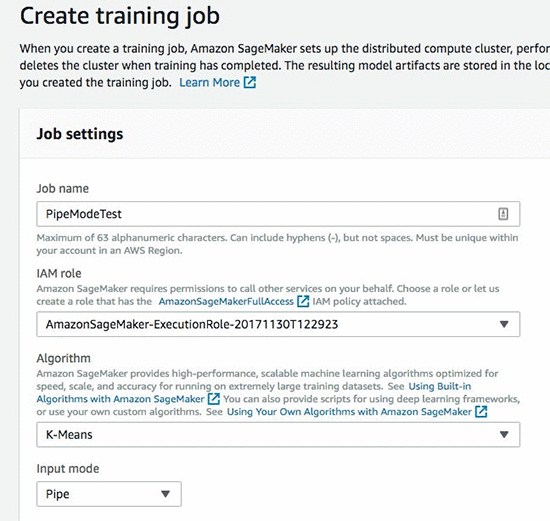
Amazon SageMaker コンソール
トレーニングジョブにおいてパイプモードのメリットを生かすのはとても簡単です。Amazon SageMaker コンソールを使用している場合は、ジョブの入力モードとして Pipe を指定するだけです。
Amazon SageMaker Python SDK
Amazon SageMaker Python SDK を使用すると、トレーニングや推論のジョブをプログラムで簡単に実行できます。Dkは 技術的詳細を隠し、Amazon SageMaker に明確な API を提供します。次のコードでは、SageMaker Python SDK を使用して新しい PCA トレーニングジョブを送信します。パイプモードを使うには、input_mode パラメータの値を変更するだけであることに注意しましょう。
AWS SDK for Python (Boto3)
低レベルのプログラムによるアクセスを希望する場合は、AWS SDK for Python (Boto3) を使用して、パイプモードでトレーニングジョブを開始できます。次のコードでは、Boto3 Python クライアントを使用して新しい PCA ジョブを送信する方法を理解できます。ここでも、input_modeを 「Pipe」に設定するだけで変更できます。
まとめ
新しく導入したパイプ入力モードのサポートにより、内蔵型 Amazon SageMaker アルゴリズムを使用してトレーニングジョブをかつてないほど高速で実行できるようになりました。既存のアルゴリズムと途切れなく統合され、データセットの格納方法を変更する必要はありません。 トレーニングジョブのための入力モードとして「Pipe」を指定するだけで、現在のパイプモードの利用を開始できます。
今回のブログ投稿者について
 Can Balioglu は AWS AI アルゴリズムチームのソフトウェア開発エンジニアで、高性能コンピューターの活用を専門にしています。休みの時は、彼は自作のGPUクラスターで遊ぶのが大好きです。
Can Balioglu は AWS AI アルゴリズムチームのソフトウェア開発エンジニアで、高性能コンピューターの活用を専門にしています。休みの時は、彼は自作のGPUクラスターで遊ぶのが大好きです。
 Ishaaq Chandy は Amazon AI の上級エンジニアで、Amazon Sagemaker のためイノベーティブで大いに拡張的なトレーニングプラットフォームを構築する作業が大好きです。以前の彼は、AWB ELB に携わり、NLB と同じく ALB 両方のチームの立ち上げチームの一員でした。
Ishaaq Chandy は Amazon AI の上級エンジニアで、Amazon Sagemaker のためイノベーティブで大いに拡張的なトレーニングプラットフォームを構築する作業が大好きです。以前の彼は、AWB ELB に携わり、NLB と同じく ALB 両方のチームの立ち上げチームの一員でした。
 David Arpin は AWS の AI Platforms Selection Leader で、データサイエンスチームと製品管理を統率してきた経歴があります。
David Arpin は AWS の AI Platforms Selection Leader で、データサイエンスチームと製品管理を統率してきた経歴があります。