たけのこの里が好きな G くんのために、きのこの山を分別する装置を作ってあげた。~ モデル作成編 ~
2022-03-02 | Author : 呉 和仁, 市川 純

はじめに
Builder の皆様、機械学習ソリューションアーキテクトの 呉和仁 です。単独名義だと 献立のレコメンド 以来ご無沙汰しておりました・・・。と思ったのですが、今回の記事は私一人ではどうにもならないところまで行き着いてしまったのでまた共同執筆者がいます。後ほど紹介します。
また、記事は 2 部で構成される予定で、この記事は第一部として機械学習のモデルを作成します。次回の記事でデバイスの作成からモデルのデプロイと実際に使ってみるところまでを行う予定です。
X ポスト » | Facebook シェア | はてブ »
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
AWS Builders Online Series は見ていただけましたか ?
1/20 に AWS Builders Online Series という基礎コンテンツのみで構成され、約 3.5 時間で集中的に学習できる、グローバルでも人気のイベントが開催されていました。(現在アーカイブ配信中)
その中で私も 、Amazon SageMaker JumpStart を用いた IT エンジニアによる機械学習 PoC のすゝめ というタイトルで 1 セッション担当しました。
簡単に内容を説明すると、Amazon SageMaker JumpStart を使えば機械学習の経験がなくてもコードの読み書きができれば簡単に機械学習 PoC を実施できます、という内容です。
その題材として具体的なプロジェクトっぽく仕立て上げ、たけのこの里好きの G くん (架空の存在です) と、きのこの山を混入してくるきのこの山好きの U さんがいて、G くんのお菓子に U さんがきのこの山を混入してくるのを G くんは機械学習を利用してどれくらい検出できるのか、という PoC を行いました。

機械学習の結果を物理的な空間へ適用する大変さ
解説
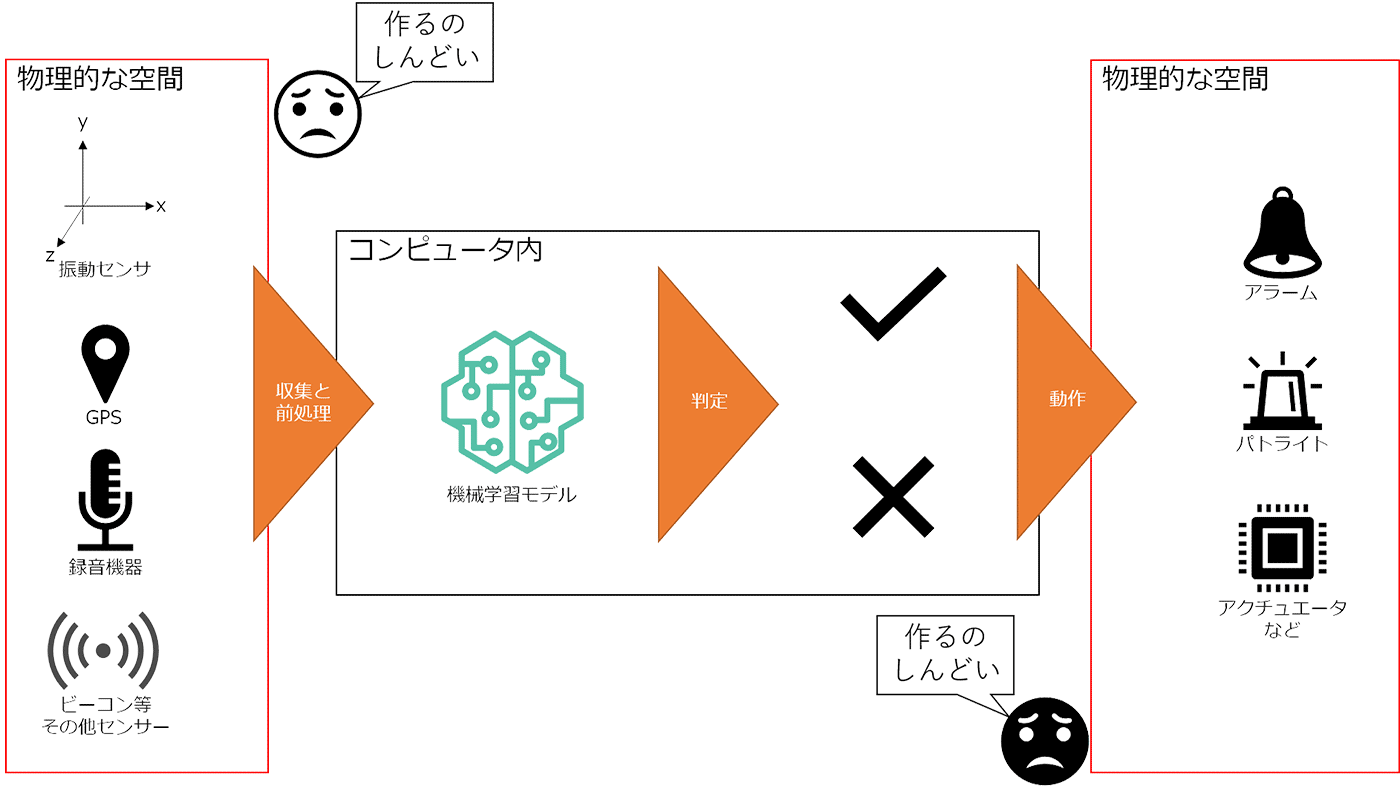
しかし、実社会で機械学習を用いるときには、デバイスなどのハードウェアと業務をセットで考えて開発する必要なケースが多いです。
最近のユースケースだと eKYC (electronic Know Your Customer、お客様確認) で、免許証などの本人確認書類を撮影して、申請してきた人が申請してきた人が本人かどうかのチェックなどがあります。その場合はインターネットに接続されたカメラとサーバサイドを連携させるためのアプリを開発し、本人かどうかをチェックさせる必要があるわけです。
工場の製造工程などになると、センサーで集めたデータを機械学習モデルに流した結果から異常があったら自動でパトライトを光らせたり、アラートを上げて人に気付かせる装置と連動したり、異常品を自動で仕分けするなどアクチュエータを動かす必要があり、工数を消費しがちです。
Builders Online Series の G くんはそこまで考える時間がなかったので、今回は皆様と一緒に物理デバイスに機械学習モデルを組み込んで動かして、どんなことを考えて作る必要があるのかを皆様と一緒に追体験しつつ、本記事では出来上がったものを架空の G くんにプレゼントしよう、という記事です。
また、実現にあたって AWS のサービスがあるとどんなところが楽になるのか、というところも併せて紹介いたします。
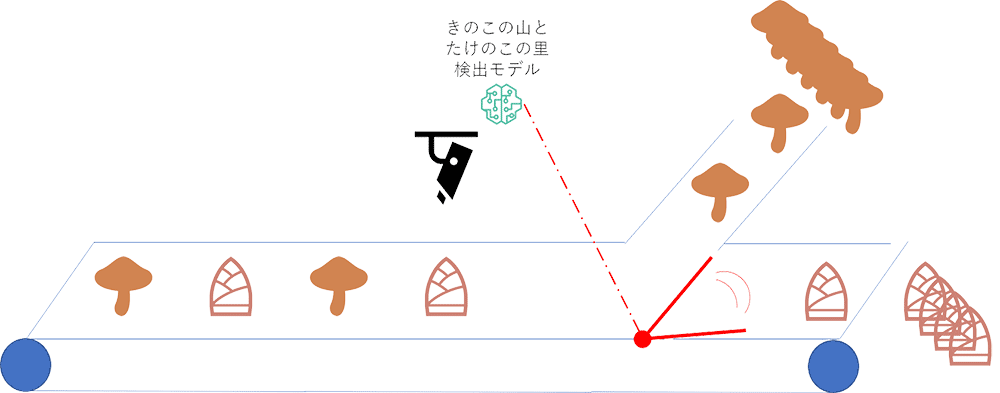
後述する完成予想図
3. G くんの行ったことの再現 (モデル作成と推論)
3-1. G くんの状況の復習
あらためて Builders Online Series をまだ見ていない、もしくは忘れてしまった方向けに G くんの置かれた状況を再確認しましょう。
むかしむかし、たけのこの里が大好きな G くんがいました。G くんはいつだってたけのこの里を食べられるよう、念願だった会社の福利厚生でたけのこの里が自動で支給される会社 AVVS 社 (架空の会社) に就職しました。
しかし困ったことが発生します。きのこの山が大好きな U さんが同僚で、同じくきのこの山が支給されており、布教活動と称して G くんのたけのこの里にきのこの山を混入するという G くんにとって、“いともたやすく行われるえげつない行為” をしてきます。
G くんは IT エンジニアで機械学習もちょっとかじっており、IT ですべてを解決してやる、というマッチョな思想の持ち主です。たけのこの里が支給されるベルトコンベアの上にカメラを取り付け、きのこの山を検出したらアラートを飛ばす装置を考え、まずは機械学習 PoC をとして、画像から機械学習でたけのこの里ときのこの山を検出できるのかを確認しました。
機械学習はデータ収集、学習、推論の順番で行うのでそれに沿って行いました。Gくんが行った再現から始めましょう。
3-2.データ収集
まずは調達
機械学習はデータがないと始まりません。G くんはまず。きのこの山やたけのこの里が映った画像を集めることからはじめました。インターネットの海にはきのこの山やたけのこの里の写真が溢れています。が、権利の問題が怖いので、 G くんは自分で写真を集めようと試みました。まずは、きのこの山とたけのこの里を買いに行きました。

ここで G くんはこんな言葉を残していました。
「機械学習のモデルを作るにあたって初手がお菓子の購入というのは初体験でしたね。今後もない気がします。」
私も、そんな経験をしたことがありません。また、こんな言葉も残しておりました。
「本当にきのこの山とたけのこの里はあるのか ? その謎を解明するため、我々調査隊はスーパーのお口へと向かった―。PoC 完了後、お菓子たちは調査隊のお口へと入った―。奥地とお口がかかっているのは笑うところです。」
正直どこを笑えばいいのかわかりませんが、買って来たそうです。
また、買ってきたきのこの山とたけのこの里を画角 (拡大縮小) や、背景、配置、お菓子の数を変えながら 23 枚写真を撮ったそうです。

幸い、撮った写真(だけでなく コードや手順も) をすべて残してくれておりました。私もこちらを使ってみましょう。
3-3. ラベリング
3-3-1. Amazon SageMaker Ground Truth
今回は写真のどこにきのこの山やたけのこの里が映っているのかを認識するタスクを解こうと考えました。いわゆる物体検出タスクですね。
物体検出タスクを解くには画像データだけでは不十分です。きのこの山やたけのこの里がどこに映っているのか、という座標データも必要です。もちろん座標データなど最初からあるわけがないので、自分で作らないといけません。こういったデータに対して正解を与える作業をラベリングといったりアノテーションといったりしますが、ラベリング作業は意外と大変です。
今回の場合は、XX.jpg の中で、(x1,y1) = (10,15) から (x2,y2) = (20,25) にきのこの山が映っているよ、(x1,y1) = (110,75) から (x2,y2) = (130,94) にたけのこの里が映っているよ、といった形で情報を与えていくわけです。
しかし、画像の座標を探っていくのも大変ですしその入力も大変な上、最終的には機械学習に入力できる形 (つまり数値) に整形しないといけません。
座標探しやその入力、アウトプットの整形などが大変なことに気づいた多忙な G くんはなんとか楽をできないか、と考えついた先に Amazon SageMaker Ground Truth というサービスを見つけました。
Amazon SageMaker Ground Truth はあらかじめ画像の分類やセマンティックセグメンテーション、テキストの分類などよく使われるラベリングを行うためのユーザーインターフェースが用意してあり (存在しないケースについてはカスタマイズすることで対応可能)、今回行おうとしている物体検出用の矩形ラベリングのためのユーザーインターフェースももちろん用意されているので、こちらを利用して楽をしようと考えました。
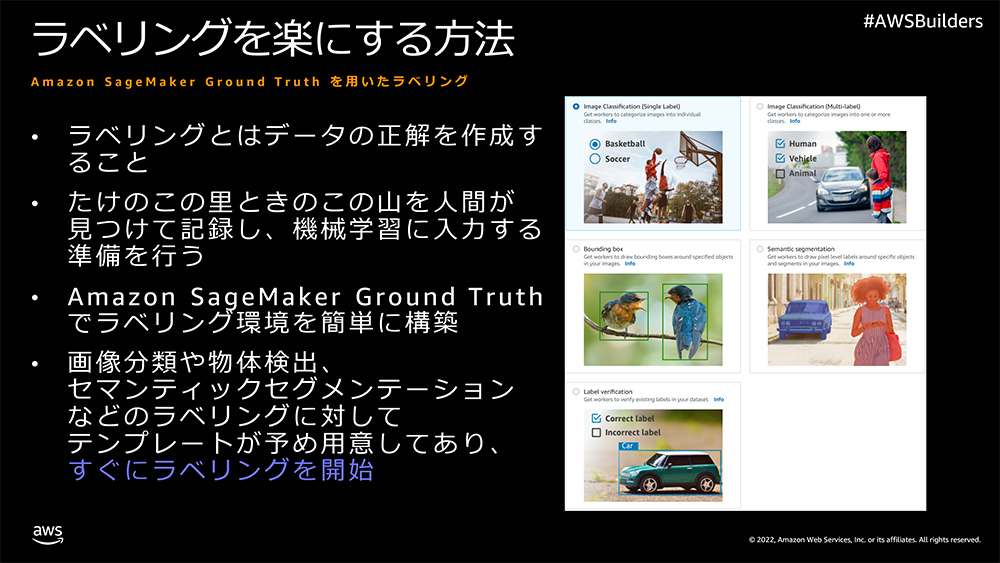
ラベリングを始めるまでの手続きはいたって簡単なので、マネジメントコンソールで実行した場合を (※AWS SDK を使って実行も可能です) スクリーンショットとともにご紹介します。
3-3-2. プライベートチームの作成
今回は私一人でアノテーションしていきます。Amazon SageMaker Ground Truth ではチームを作ってそのチームでラベリングを行うため、私一人だけの寂しいチームを作ります。
ラベリングフォースの画面 にアクセスして、プライベートタブから「プライベートチームを作成」をクリックします。

その次にチーム名を入力します。今回は kinoko-detect-team というチーム名を入力しました。
また、E メールアドレスの欄に、実際の作業者のメールアドレスを入力します。Eメールを送る際に組織の名前を入れて送信することができるので、組織名を入力します。今回は “茸探隊” としました。そのままですね。
最後に連絡先 E メールを入力します。ワーカーが困ったときの連絡先です。今回は一人で行ったので、ワーカーの E メールアドレスも連絡先 E メールも同じアドレスを入力しました。

最後に「プライベートチームを作成」をクリックします。

すると、プライベートチームが出来上がり、ワーカーにパスワードが記述されたメールが飛びますので、あとで使えるようにメモしておきます。

プライベートチームを作成すると、こちらの画面に遷移しますので、ラベリングポータルのサインイン URL をクリックします。

ラベリングポータルへのログイン画面が表示されますので、ワーカーのメールアドレスと入手したパスワードを入力して「Sign in」をクリックします。
初期パスワードの変更を求められるので、強固で素晴らしいパスワードを上下 2 つの欄に入力し、「Send」をクリックします。
するとラベリングポータルの画面に遷移します。ラベリングジョブが未作成のため空白です。これからラベリングジョブを作成しましょう。

3-3-3. 画像を Amazon S3 にアップロードする
ラベリングジョブの作成には予めラベリング対象のデータ (今回はきのこの山やたけのこの里が映った画像) を Amazon S3 に配置しておく必要があるので配置します。
ここからの作業はコード (Python) も必要です。
まずは実行環境の作成です。実行環境については Amazon SageMaker Studio を前提とします。Amazon SageMaker Studio の環境が未作成の場合は、セットアップ の 12.「Open Studio」をクリックし、初めて SageMaker Studio にアクセスする際には、ページの読み込みに 1~2 分かかることがあります。までを実行してください。
SageMaker Studio の画面が表示されたら、Launcher 画面から「System terminal」をクリックします。

Terminal が起動できましたら、以下のコマンドを入力して、撮影済の画像を含むリポジトリを clone します。
git clone https://github.com/aws-samples/aws-ml-jp
clone がおわりましたら、aws-ml-jp → sagemaker → sagemaker-jumpstart → builders-online-2022-demo とディレクトリをダブルクリックで開いていきます。

takenoko_to_kinoko.ipynb というノートブックがあるので、ダブルクリックして開きます。
このノートブックに実行するコードが記載されているので、以降ノートブック記載のコードを紹介していきます。皆様は日本語で記載されている内容をトレースし、コードが書かれている部分を実行 (Shift + Enter) していけば OK です。

開くと、もしかしたら Kernel や Image の選択画面が出るかもしれません。そのときはそれぞれ Data Science , Python3 を選択して、「Select」をクリックしてください。

同様にインスタンスを選択する画面が出た場合は、ml.t3.medium を選択の上、「Save and continue」をクリックしてください。

さて、少し前置きが長くなりましたが G くんが撮影した画像を S3 にアップロードします。学習用の画像は ./train_raw_images/ にあるので、以下のコードでディレクトリまるごと S3 にアップロードします。あわせてこの後にラベリングジョブの名前が必要になるので、予め uuid を使ってユニークな名前を生成します。
# 撮影した画像のディレクトリ指定
TRAIN_RAWIMAGE_DIR = './train_raw_images/'
# S3 にアップロードする先の Prefix の指定
BASE_PREFIX = 'takenoko_kinoko_gt'
# ユニークなラベリングジョブ名の生成
GT_JOB_NAME = f'{BASE_PREFIX}-{uuid.uuid4()}'.replace('_','-')
# 撮影した画像を S3 にアップロードし、その URI を取得する
rawimage_s3_uri = sagemaker.session.Session().upload_data(TRAIN_RAWIMAGE_DIR,key_prefix=BASE_PREFIX)
# ラベリングジョブ名とラベリング画像を配置した URI 、ラベリングに使う IAM ロールを取得
print(f'GroundTruth job name : {GT_JOB_NAME}')
print(f'GroundTruth Target : {rawimage_s3_uri}/')
print(f'GroundTruth Role : {sagemaker.get_execution_role()}')
結果
GroundTruth job name : takenoko-kinoko-gt-{UUID}
GroundTruth Target : s3://sagemaker-{REGION}-{ACCOUNTID}/takenoko_kinoko_gt/
GroundTruth Role : arn:aws:iam::{ACCOUNT_ID}:role/service-role/AmazonSageMaker-ExecutionRole-20211201T1413923-3-4. ラベリングジョブの作成
さて、ここで一旦ノートブックを離れて、マネジメントコンソールに戻ってラベリングジョブを作成します。
SageMaker Ground Truth のラベリングジョブ作成画面 にアクセスし、「ラベリングジョブの作成」をクリックします。

作成するジョブの詳細を入力していきます。
-
ジョブ名に先程のノートブックの出力結果の GroundTruth job name : 以降の文字列を記入します。
-
入力データセットの S3 の場所に先程のノートブックの出力結果の GroundTruth Target : 以降の文字列を記入します。
-
出力データセットの S3 の場所はデフォルトのまま入力データセットと同じ場所 を選択します。
-
データタイプは「画像」を選択します。
-
IAM ロールは今動かしている SageMaker Studio と同じロールを選択します(上のセルの GroundTruthe Role : 以降に表示されているロールを選択)します。
-
「完全なデータセットアップ」をクリックします。

タスクカテゴリで「画像」を選択し、タスクの選択で、「境界ボックス」を選択します。

「次へ」をクリックします。

ラベリングジョブを行うチームの設定をします。
-
ワーカータイプで「プライベートチーム」を選択します。
-
プライベートチームのプルダウンで先程作成したワーカーを選択します。

最後に、ラベリングジョブでワーカーにやってもらいたいことの設定をします。
他はデフォルトのまま境界ボックスラベリングツールの部分で、takenoko と kinoko というラベルを作成します。初期の空白ラベルは1つなので、take を入力後、「新しいラベルを追加」をクリックして、kino を入力して、最後に「作成」をクリックします。

これでラベリングジョブの作成が完了しました。
先程のラベリングジョブのポータルを見に行くと、ラベリングジョブが出来上がっていることが確認できます。今作成したラベリングジョブのラジオボタンを選択した上、「Start Working」をクリックします。

ラベリング画面に遷移するので、きのこの山は kinoko を選んで矩形で括り、たけのこの里は takenoko を選んで矩形で括ってSubmit していきます。とても使いやすいユーザーインターフェースですね。

3-4. 画像が少なくても良いモデルを作る
さて、G くんはここまでやったのに不安にかられたそうです。果たして 23 枚だけの学習でいけるのか・・・? と。確かに私も機械学習を依頼されてデータが 23 個だったら、回れ右して帰ってしまいそうです。ここで、G くんは画像が少なくてもなんとか成功させるべく 2 つの方法を考えました。
3-4-1. ランダムクロップ
1 つ目はデータオーグメンテーション手法の一つで有名なランダムクロップです。今回は比較的大きなサイズ (1477 x 1108) の画像を撮影し、ラベリングしました。ここからランダムに 512 x 512 の画像を切り出し (クロップ) を 20 回繰り返しました。
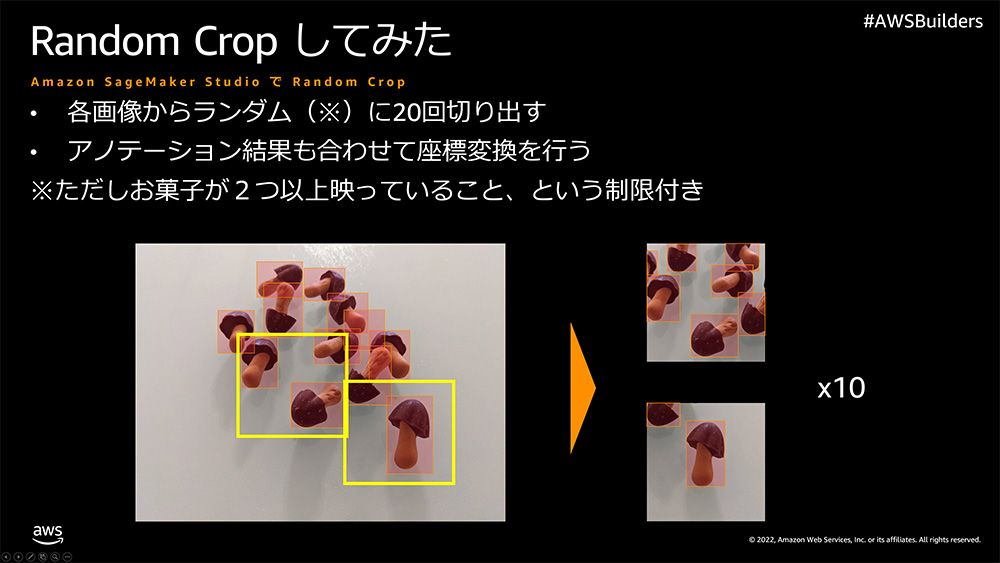
こうすることであら不思議、23 枚の学習画像が 460 枚に増幅されました。また、以下 2 点の工夫を入れています。
-
クロップする際にきのこの山やたけのこの里を 2 個以上含むこと
せっかく元のデータでラベリングしてあるので、写真のどこにきのこの山やたけのこの里が映っているかがわかっています。きのこの山やたけのこの里が全く映っていない画像を学習しても意味がないので、ラベリングの結果を使って、クロップした画像にきのこの山もしくはたけのこの里が 2 個以上含むように制限をかけています。 -
本来のきのこの山やたけのこの里の矩形面積の 1/4 以下だったら
クロップするときのこの山やたけのこの里が中途半端に映るようなこともありますが、ラベリングした際の矩形面積の 1/4 以下なら 1 個とカウントしない、というロジックを入れています。
コードは以下の通りです。
# クロップした画像にきのこの山やたけのこの里が映っている場合、
# クロップした後のきのこの山やたけのこの里が1/4以下かどうかを判定するヘルパー関数
def fix_bbox(l,t,r,b,w,h):
# 判定結果、NG なら False にする
judge = True
# ラベリング結果のクロップ補正後の値が負の値ならば 0 に、イメージサイズより大きければイメージサイズに補正する
fix_left = 0 if l < 0 else l
fix_top = 0 if t < 0 else t
fix_right = w if r > w else r
fix_bottom = h if b > h else b
# 領域外ならラベリング無しとする
if l > w or t > h or r < 0 or b <0:
judge=False
# 基の面積の1/4以下ならアノテーション無しとする
elif (r-l)*(b-t)/4 > (fix_right-fix_left)*(fix_bottom-fix_top):
judge=False
return judge,(fix_left,fix_top,fix_right,fix_bottom)
# ラベリング結果をテキストとして読み込む
with open('manifest/output.manifest','r') as f:
manifest_line_list = f.readlines()
# クロップした結果のきのこの山やたけのこの里の位置情報を格納する辞書
annotation_dict = {
'images':[],
'annotations':[]
}
# クロップサイズの定数
IMAGE_SIZE_TUPLE=(512,512)
# クロップした画像のファイル名に使う一意なシーケンス番号
IMAGE_ID = 0
# クロップした画像の保存先
OUTPUT_DIR = './train_random_crop_images/'
# (re-run用の削除コマンド)
!rm -rf {OUTPUT_DIR}*.png
# ラベリング結果の行数分ループする
# ラベリング結果は 1 行につき 1 画像格納される
for manifest_line in manifest_line_list:
# 画像のラベリング結果の読み込み
manifest_dict = json.loads(manifest_line)
# 画像のファイル名取得(ラベリング結果に格納されている)
filename = manifest_dict['source-ref'].split('/')[-1]
# 元画像のサイズを取得(ラベリング結果に格納されている)
image_size_tuple=(manifest_dict['kinoko-takenoko-aug']['image_size'][0]['width'],manifest_dict['kinoko-takenoko-aug']['image_size'][0]['height'])
# PIL で画像を開く
raw_img = Image.open(os.path.join(TRAIN_RAWIMAGE_DIR,filename))
# 20 回クロップする
for i in range(20):
# ループするかどうかのフラグ(画像にきのこの山やたけのこの里が 2 枚未満だったらクロップをやりなおし)
loop = True
while loop:
# クロップを行う左上の座標を設定
rand_x = np.random.randint(0,image_size_tuple[0]-IMAGE_SIZE_TUPLE[0])
rand_y = np.random.randint(0,image_size_tuple[1]-IMAGE_SIZE_TUPLE[1])
# クロップする
crop_img = raw_img.crop((
rand_x,
rand_y,
rand_x + IMAGE_SIZE_TUPLE[0],
rand_y + IMAGE_SIZE_TUPLE[1]
))
# クロップ後のきのこの山やたけのこの里の位置を格納するリスト
annotation_list = []
# 元画像のラベリング結果をループ
for annotation in manifest_dict['kinoko-takenoko-aug']['annotations']:
# クロップした後のきのこの山やたけのこの里の座標に補正
left = annotation['left'] - rand_x
top = annotation['top'] - rand_y
right = annotation['left'] + annotation['width'] - rand_x
bottom = annotation['top'] + annotation['height'] - rand_y
# きのこの山やたけのこの里があるかどうかを判定
judge,(left,top,right,bottom) = fix_bbox(left,top,right,bottom,IMAGE_SIZE_TUPLE[0],IMAGE_SIZE_TUPLE[1])
if judge:
# きのこの山やたけのこの里があったら位置とラベルを追加
annotation_list.append(
{
'bbox':[left,top,right,bottom],
'category_id':annotation['class_id']
}
)
# きのこの山やたけのこの里と数が2未満だったらクロップやり直し
if len(annotation_list) > 1:
loop = False
# クロップしたら画像を保存する
save_file_name = f'{str(IMAGE_ID).zfill(5)}_{str(i).zfill(5)}_{filename}'.replace('jpg','png')
crop_img.save(os.path.join(OUTPUT_DIR,save_file_name))
# 補正済ラベリング結果を出力用辞書に格納
annotation_dict['images'].append(
{
'file_name' : save_file_name,
'height' : IMAGE_SIZE_TUPLE[1],
'width' : IMAGE_SIZE_TUPLE[0],
'id' : IMAGE_ID
}
)
for annotation in annotation_list:
annotation_dict['annotations'].append(
{
'image_id': IMAGE_ID,
'bbox':annotation['bbox'],
'category_id':annotation['category_id']
}
)
IMAGE_ID += 1
# ランダムクロップ補正後のラベリング結果を出力
with open('annotations.json','wt') as f:
f.write(json.dumps(annotation_dict)) コピー
ランダムクロップ以外にもミラーやフリップ、拡大縮小といった手法もありますので皆様も色々試してみてください。
3-4-2. Amazon SageMaker JumpStart を用いた Fine-Tune
ランダムクロップを使ったデータオーグメンテーション (データ増幅) で 23 枚だった画像とラベリング結果が、 460 枚の画像とラベリング結果に化けました。
画像が揃ったので機械学習のトレーニングを始めていきたいところですが、G くんは多忙だったため、これ以上あまり時間をかけられなかったそうです(↑ のコードを書くのに半日を費やしてしまったそうです)。
一般的に機械学習でトレーニングを行うためには、データが揃った後も、モデルとトレーニングを定義したコードを用意して、実際に動かして上手くいくまで (デバッグと精度向上) 試行錯誤を繰り返すことになります。それに対して G くんは 3 つのアプローチで省力化を図りました。
-
既存のモデル構造を流用する
機械学習の物体検出タスクは一般的で、Yolo や Faster-RCNN など世にいろんなモデルが出ています。1 から新しく作って論文を出すレベルの物体検出モデルを作る方向に行くよりは、既存の良いとされているモデルを流用したほうが当然省力化できます。G くんは迷わず人のモデル構造を流用することを選びました。 -
Fine-Tune する
トレーニングも一般的には時間がかかります。機械学習のトレーニングは軽いモデルでも 1 日かかることはざらで、大きいモデルであれば数週間、とかかかることもよくあります。しかし既存のモデル構造を流用したように、既存のモデルの学習結果 (重みとバイアス) を流用することで、学習時間の短縮を図れます。具体的には既存のモデルの学習結果 (pre-trained model) に対して、きのこの山やたけのこの里の画像を学習させる (Fine-Tune) ことで、学習時間の短縮を図りました。 -
Amazon SageMaker JumpStart で Fine-Tune する
既存のモデル構造を流用し、さらにそれを Fine-Tune で考える時間と学習する時間の圧縮を行いました。しかし、まだ大変な作業があります。モデル構造と Fine-Tune をコードとして記述、つまりプログラミングする必要があります。G くんはそれすらめんどくさくなってます。そこで G くんは AWS を自由に使える環境であったことを利用して、Amazon SageMaker JumpStart で Fine-Tune を試みました。Amazon SageMaker JumpStart は様々な pre-trained model を用意しており、テキスト系であれば 100 以上、画像系であれば 200 以上ものモデルがあります。今回は Fine-Tune 可能な物体検出モデルである COCO2017 という 20 万枚以上の画像データセットで学習済の SSD MobileNet 1.0 を使うことにしました。

実際の学習の仕方ですが、Amazon SageMaker JumpStart で Fine-Tune するためには、学習データとラベリング結果を S3 にアップロードする必要があります。以下のコードで S3 にアップロードしつつ、アップロードした先の URI を出力しておきます。
# 出力したディレクトリを prefix として使う
prefix = OUTPUT_DIR[2:-1]
# re-run 用の削除コマンド
!aws s3 rm s3://{bucket}/{prefix} --recursive
# ランダムクロップした画像をアップロード
image_s3_uri = sagemaker.session.Session().upload_data(OUTPUT_DIR,key_prefix=f'{prefix}/images')
# ラベリング結果をアップロード
annotatione_s3_uri = sagemaker.session.Session().upload_data('./annotations.json',key_prefix=prefix)
# Fine-Tune で使う URI を出力
paste_str = image_s3_uri.replace('/images','')
print(f"paste string to S3 bucket address:{paste_str}")
コピー
ここから SageMaker JumpStart で Fine-Tune するための手順です。SageMaker Studio の左上にある「+」アイコンなどからLauncher (SageMaker Studio を開いた時の初期画面でもあります) タブを出します。

クリックすると拡大します
Get started の Explore one-click solutions, models, and tutorials SageMaker JumpStart の中にある「Go to SageMaker JumpStart」をクリックします。

クリックすると拡大します
Search と書かれた検索窓に SSD MobileNet と打ち込むと青い丸に m と書かれたアイコンで SSD MobileNet 1.0 と表示されるので、そちらをクリックします。

クリックすると拡大します
やや下にある Fine-tune Model の Data Source のラジオボタンから「Enter S3 bucket location」を選択し、S3 bucket address に先程出力した paste string to S3 bucket address:より後ろの値を貼り付けます。
「Deployment Configuration」をクリックして表示を展開し、SageMaker Training Instance で「ML.G4dn.xlarge」を選択します。これは GPU インスタンスですので、クオータ緩和をしないと使えないことがありますので、その場合は リンク の
AWS サポートセンターのページを開き、必要に応じてサインインし、[Create case] を選択します。Service Limit increase を選択します。フォームに入力して送信します。
から SageMaker Training instance の ml.g4dn.xlarge を 1 台使えるように申請してください 。
Model Name は任意の名前を入力します (デフォルトのままでも可ですが、わかりづらいので、検出したいモノなどを入れましょう。例:kinoko-detection-model など)
「Hyper-parameters」 をクリックし、下記を入力します。(デフォルトのままだとトレーニングが短く急なため変更します)
-
learning rate : 0.0001
-
batch-size : 4
-
epochs : 40
最後に「Train」をクリックして Fine-Tune をスタートさせます。

これだけの操作で Fine-Tune を開始できました。ノーコードでトレーニングできるので、多忙な G くんにはピッタリなサービスです。
3-5. クラウド推論
G くんはトレーニングが終わった後、出来上がったモデルを使って推論してモデルを試していました。確かにモデルが出来上がったら本当にまともに動くかどうかを確認しないと使えるモデルかわかりません。 Amazon SageMaker JumpStart はクラウドにすぐデプロイできるので、クラウドデプロイを試しました。
3-5-1. 推論エンドポイント立ち上げ
トレーニングは 20 分弱で終了し、 complete と表示されます。Deploy Model という画面が出るので、SageMaker Hostin Instance のプルダウンから、「ML.M5.Large」を選択します。
次に Endpoint Name に任意の名前を入力します。わかりやすく kinoko-detection-endpoint と入力します。最後に「Deploy」をクリックします。

数分待ち、In Service に変わると立ち上げが完了します。

3-5-2. 推論エンドポイントを使って画像からきのこの山とたけのこの里を検出する
推論エンドポイントが立ち上がったら画像をリクエストして試してみましょう。推論コードを書くのもめんどくさいですが、上の画像の「Open Notebook」をクリックすると、Fine-Tune 元となった COCO2017 の pre-trained model を用いた推論コードを見つけたので、それを改変して使うことにしました。お試し用の画像が test_raw_images/lattice.jpg にあったので、そちらを使いました。

lattice.jpg
推論コードは以下の通りです。
er-runtime クライアントの生成
smr_client = boto3.client('sagemaker-runtime')
# エンドポイントの名前
ENDPOINT_NAME='jumpstart-ftc-kinoko-detection-endpoint'
# 推論する画像の場所
TEST_IMAGE_FILE = 'test_raw_images/lattice.jpg'
# 推論対象の画像を開いて変数に格納
with open(TEST_IMAGE_FILE, 'rb') as f:
img_bin = f.read()
# 推論を実行
response = smr_client.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType='application/x-image', Body=img_bin)
# 推論結果を読み込む
model_predictions = json.loads(response['Body'].read())
# 結果を可視化
# テスト画像を PIL を通して numpy array として開く
image_np = np.array(Image.open(TEST_IMAGE_FILE))
# matplotlibで描画する
fig = plt.figure(figsize=(20,20))
ax = plt.axes()
ax.imshow(image_np)
# 推論結果を変数に展開
bboxes, classes, confidences = model_predictions['normalized_boxes'], model_predictions['classes'], model_predictions['scores']
# 物体検出結果を検出した分だけループする
for idx in range(len(bboxes)):
# 信頼度スコアが 0.5 以上のみ可視化する
if confidences[idx]>0.5:
# 検出した座標(左上を(0,0),右下を(1,1)とした相対座標)を取得
left, bot, right, top = bboxes[idx]
# 相対座標を絶対座標に変換する
x, w = [val * image_np.shape[1] for val in [left, right - left]]
y, h = [val * image_np.shape[0] for val in [bot, top - bot]]
# 検出した物体の ID を take/kino に読み替える
class_name = 'take' if int(classes[idx])==0 else 'kino'
# take/kinoに対して矩形で描画するための色を設定する
color = 'blue' if class_name == 'take' else 'red'
# matplotlib に検出した物体に矩形を描画する
rect = patches.Rectangle((x, y), w, h, linewidth=3, edgecolor=color, facecolor='none')
ax.add_patch(rect)
# 左上に検出結果と信頼度スコアを描画する
ax.text(x, y, "{} {:.0f}%".format(class_name, confidences[idx]*100), bbox=dict(facecolor='white', alpha=0.5))
格子状にきのこの山やたけのこの里が並んで配置されているのを見事に検出できてますね !
と思ったのですが、左から 2 列目、一番下はきのこの山なのにたけのこの里と検出されてしまっています。
きのこの山の軸部分が映っていないので、たけのこの里と誤認識してしまったようです。今回このように軸が映っていないきのこの山をトレーニングしていないため発生したと考えられます。PoC でわかった重要な知見ですね。

3-5-3. 本番運用を模した推論
さらに G くんは実際の本番運用を模した推論もしていました。忙しいんだか暇なんだかわからないですね。
G くんはたけのこの里を横一列に並べた上、1 つだけきのこの山を混ぜた状態で、画角が広いカメラで撮影した画像を用意していました。

ここから 512 px x 512 px の画像を左端から切り出し、1 px ずつストライドして合計 3520 枚の画像を切り出しました。これをベルトコンベアを写した動画の各フレームと見立てて、それを一枚ずつ推論しようと考えたのでした。
# 画像を切り出すためのコード
# 開始地点設定
x ,y = 0,512
# 切り出すサイズ設定
CROP_SIZE=(512,512)
# 切り出す対象の画像を PIL で開く
img = Image.open('./test_raw_images/takenoko.jpg')
# 切り出した画像を保存するディレクトリ
CROP_DIR = './test_crop_images/'
# re-run 用の削除コマンド
!rm -rf {CROP_DIR}/*.png
# 1pxずらしてループ
for i in range(img.size[0]-CROP_SIZE[0]):
# 画像の切り出し
crop_img = img.crop((i,y,i+CROP_SIZE[0],y+CROP_SIZE[1]))
# 切り出した画像を保存
file_name = f'{CROP_DIR}{str(i).zfill(5)}.png'
crop_img.save(file_name)
切り出した画像の例


推論コードをループさせて 3520 枚全部推論します。また、それらをつなぎ合わせて動画にしました。
# 検出結果を保存するディレクトリを設定
DETECT_DIR='./test_detect_images/'
# re-run 用の削除コマンド
!rm -rf {DETECT_DIR}/*.png
# 切り出した画像分だけループ
for img_file_path in sorted(glob(f'{CROP_DIR}*.png')):
# 切り出した画像を開く
with open(img_file_path,'rb') as f:
img_bin = f.read()
# 推論エンドポイントに画像を投げる
response = smr_client.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType='application/x-image', Body=img_bin)
# 推論結果を読み込む
pred=json.loads(response['Body'].read())
# 推論結果を展開
bboxes, classes, confidences = pred['normalized_boxes'], pred['classes'], pred['scores']
# 切り出した画像を PIL で開く
img = Image.open(img_file_path)
# 矩形やテキストを描くために draw インスタンスを生成
draw = ImageDraw.Draw(img)
# 検出したkino/take分ループ
for i in range(len(bboxes)):
# 信頼度スコアが0.8以上のみ描画する
if confidences[i]>0.8:
# 矩形の相対座標を取得
left, top, right, bottom = bboxes[i]
# 矩形の相対座標を絶対座標に変換
left = img.size[0] * left
top = img.size[1] * top
right = img.size[0] * right
bottom = img.size[1] * bottom
# 検出した物体の ID を take/kino に読み替える
text = 'take' if int(classes[i])==0 else 'kino'
# take/kinoに対して矩形で描画するための色を設定する
color = 'blue' if text == 'take' else 'red'
# 矩形の左上に表示する文字の大きさを設定、きのこの山なら大きくする
TEXTSIZE=14 if classes[i]=='0' else 18
# 矩形の先の太さを設定、きのこの山なら太くする
LINEWIDTH=4 if classes[i]=='0' else 6
# 矩形を描画する
draw.rectangle([(left,top),(right,bottom)], outline=color, width=LINEWIDTH)
# 矩形の左上に描画する信頼度スコアの取得
text += f' {str(round(confidences[i],3))}'
# テキストを描画する場所を取得
txpos = (left, top-TEXTSIZE-LINEWIDTH//2)
# フォントの設定
font = ImageFont.truetype("/usr/share/fonts/truetype/noto/NotoMono-Regular.ttf", size=TEXTSIZE)
# 描画するテキストのサイズを取得
txw, txh = draw.textsize(text, font=font)
# テキストの背景用の矩形を描画
draw.rectangle([txpos, (left+txw, top)], outline=color, fill=color, width=LINEWIDTH)
# テキストを描画
draw.text(txpos, text, fill='white',font=font)
# 画像をファイルに書き出す
img.save(img_file_path.replace(CROP_DIR,DETECT_DIR))
# 書き出した画像を連結して動画にする
fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v')
video = cv2.VideoWriter('./video.mp4',fourcc, 120.0, CROP_SIZE)
for img_file_path in sorted(glob(f'{DETECT_DIR}*.png')):
img = cv2.imread(img_file_path)
video.write(img)
video.release()実施した結果
推論時間も動画連結を除いて 3520 枚で、13 分 20 秒 = 1 枚あたり 0.2 秒強で推論できることがわかりました。クラウド推論なので画像のネットワーク転送時間を入れても 0.2 秒であれば、エッジの弱めのリソースを差し引いても速度的に問題ないのではないでしょうか。また、きのこの山が画面に出始めた頃は、たけのこの里と誤認識する場合もありましたが、ほぼ正確に取れていることもわかりました。
だいぶ (記事が) 長くなりましたが、ここまでで G くんがやっていたことの追体験が完了です。

4. Amazon SageMaker JumpStart のモデルを用いたローカル推論 (追加)
4-1. モデルのダウンロード
モデルはどこにあるのか ?
まずモデルはどこにあるのか ? です。クラウド推論用のエンドポイントからできたモデルを辿れるので見てみましょう。
ここからノートブックを変えて (option) local_predict.ipynb を実行します。 Kernel について理由は後述しますが、「Python 3 (MXNet 1.8 Python 3.7 CPU Optimized)」を選択します。インスタンスは ml.t3.medium を利用します。
まず、AWS SDK for Python(boto3) で Endpoint の詳細を取得し、そこで入手できる EndpointConfigName から SageMaker に登録された Model の詳細を取得します。そこに S3 の URI が格納されています。なんのこっちゃかと思いますので、コードで見てみましょう。
import boto3
sm_client = boto3.client('sagemaker')
# Endpoint の詳細から EndpointConfigName を取得
endpoint_config_name = sm_client.describe_endpoint(EndpointName='jumpstart-ftc-kinoko-detection-endpoint')['EndpointConfigName']
# EndpointConfig の詳細から ModelName を取得
model_name = sm_client.describe_endpoint_config(EndpointConfigName=endpoint_config_name)['ProductionVariants'][0]['ModelName']
# Model の詳細を取得
model_detail = sm_client.describe_model(ModelName=model_name)
# Model の詳細からクラウド推論に使っているコンテナイメージを取得
model_container_image = model_detail['PrimaryContainer']['Image']
# Model の詳細からクラウド推論に使っているモデルの URI を取得
model_s3_uri = model_detail['PrimaryContainer']['ModelDataUrl']
# コンテナイメージと URI を取得
print(model_container_image)
print(model_s3_uri)
出力結果
763104351884.dkr.ecr.{REGION}.amazonaws.com/mxnet-inference:1.7.0-cpu-py3
s3://sagemaker-{REGION}-{ACCOUNT_ID}/mxnet-od-ssd-512-mobilenet1-0-coco-YYYYMMDD-HHMISS/model.tar.gz
コンテナは SageMaker のマネジメント推論コンテナを使っていることがわかりました。・・・MXNet !? M,M,M,MXNet !? 使ったことないぞ !?
4-2. 推論コード作成
モデルの URI もわかったので早速手元 (SageMaker Studio) にダウンロードしましょう。
# re-run 用の削除コマンド
!rm -rf model/
# modelダウンロードディレクトリ作成
!mkdir -p model/
# モデルを S3 からダウンロード
!aws s3 cp {model_s3_uri} ./model/
# モデルディレクトリへ移動
%cd model/
# 解凍
!tar zxvf model.tar.gzmodel.tar.gz
model.tar.gz を除くと巨大 (92 MB, 46 MB) なファイルが 2 つあります。coco と finetunedと書かれているので、COCO2017 の pre-trained model と、Fine-Tune 後のパラメータ (Deep Learning の重みとバイアス) でしょう。また、code ディレクトリがあるので、この中に推論コードがあるに違いません。code ディレクトリも見てみましょう。
%cd code
!ls -l
total 2124
-rw-rw-r-- 1 root root 0 Jan 22 01:04 init.py
drwxr-xr-x 2 root root 6144 Jan 22 02:18 constants/
-rw-rw-r-- 1 root root 9240 Jan 22 01:04 inference.py
drwxr-xr-x 3 root root 6144 Jan 22 02:18 lib/
-rw-rw-r-- 1 root root 0 Jan 22 01:04 requirements.txt
-rw-rw-r-- 1 root root 5 Jan 22 01:04 versioninference.py
ありました、ありましたよ ! inference.py が !
詳細は割愛しますがこれが推論コードですね。あと、constants ディレクトリ下には定数が定義されていました。lib ディレクトリには OpenCV (画像処理のライブラリ) が格納されていました。
というわけでこの code ディレクトリ配下にあるリソースで推論してみましょう。出来上がったコードは以下からダウンロードできます。先程と同じ lattice.jpg を使ってみます。
表示された画像

これで、ライブラリさえ揃っていればどこでも推論できることが確認できました。
5. IoT プロトタイプエンジニア召喚
装置の作成
作ったモデルが動作したことを確認したので、いよよい次は、きのこの山を山に返す装置の作成です。
しかし、私はハードウェアやエッジデバイスの扱いがサッパリで、次の投稿が 10 年先になってしまうことが容易に想像できました。社内で誰か協力してくれる人いないかな~と、思っていたところたけのこの里 1 箱で協力してくれそうな IoT プロトタイプエンジニアがいたので、たけのこの里を生贄にして召喚しました。
呉
「IoT プロトタイピングエンジニアの市川さん、きのこの山 1 箱で今回のデバイス作成をやってくださるとか、本当にありがとうございます。」
たけのこの里派の市川
「たけのこの里です。絶対に間違えないでください。」
呉
「た、大変失礼しました。市川さんは AWS をいじってたらいつの間にか第二種電気工事士になっていた とか 子供の教育をプログラミングで自動化した とか伺っています。」
市川
「そうなんです。AWS を学ぶと電気の勉強にもなっていて子供も勝手に育つように・・・って全然違います。」
呉
「(ノリツッコミしてくれた)」
市川
「で、どんなのを作ればいいんですか ?」
呉
「かくかくしかじかこんなものを・・・」
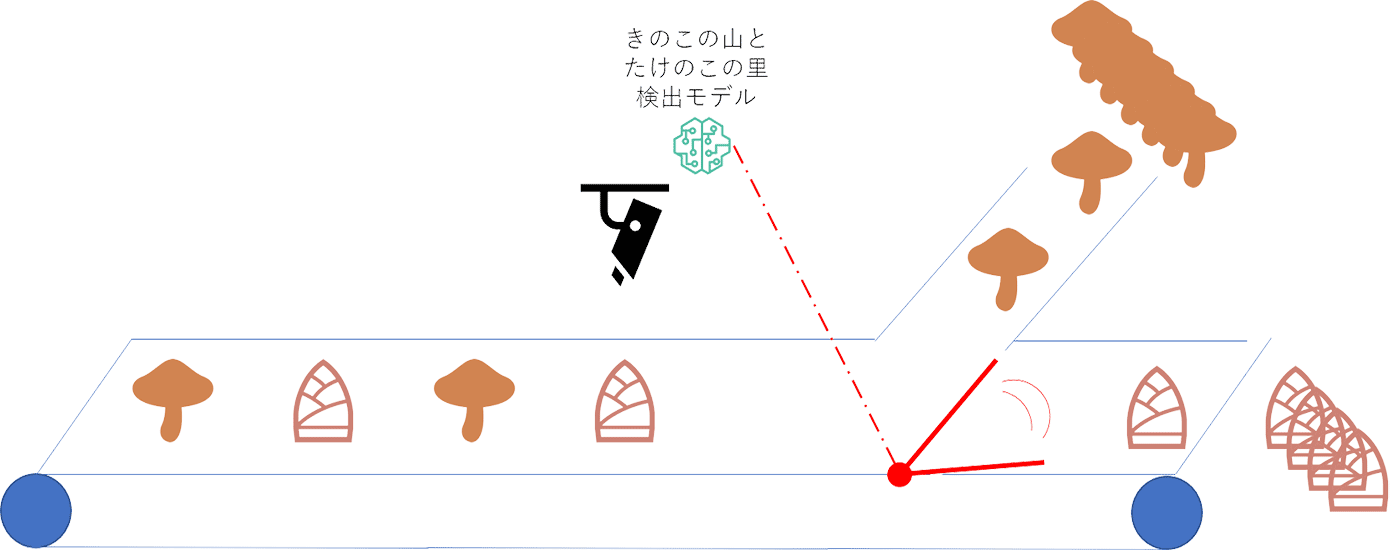
実際に市川と呉でリモート会議した時のポンチ絵
呉
「こんな感じにきのこの山とかたけのこの里がベルトコンベア的に流れてきたら、自動で仕分けてくれる装置がほしいです。機械学習モデルは私のほうで作りました。あと、きのこの山派の人もいるので、きのこの山が好きな人、つまりはダイバーシティへの配慮も忘れないよう、ユニバーサルなデザインで。さらに読者の皆様が実際に作れるよう安価なパーツだけで、AI でなんかすごくてマーベラスでファビュラスにお願いします。あ、大事なことを忘れてました。食品を扱うんで、最後にスタッフがおいしくいただきましたと書いてなくても炎上しないですむようn・・・」
市川
「あ、もういいです。」
呉
「(あと 500 字くらい早口で喋りたかった顔をしている)」
市川
「とりあえず検討します。」
6. G くんにプレゼントしたいデバイスの構成検討
さて、市川が実際に作るのは次回の記事なのですが、皆様でも再現できるような部品を使うことにしました。
Jetson nano を使用することとしました。ベルトコンベアの流れる速度や撮影頻度によりますが、GPU が使えたほうがいいだろうということで Jetson Nano を用いることとしました。ついでにベルトコンベアやお菓子をルーティングするアクチュエータへの命令も担います。
USB 接続できるカメラを Jetson Nano に接続することとしました。
業務用のコンベアは高いので、夏休みの工作ぐらいの予算感で自作します。
安価なサーボモーターを利用します。
7. 次回予告
の三本立てです。(まだ1文字も書いていない妄想のため、実際にお送りする内容とは大幅に異なる可能性があります) お楽しみに !
筆者プロフィール
呉 和仁
 アマゾン ウェブ サービス ジャパン合同会社機械学習ソリューションアーキテクト。IoT の DWH 開発、データサイエンティスト兼業務コンサルタントを経て現職。プログラマの三大美徳である怠惰だけを極めてしまい、モデル構築を怠けられる AWS の AI サービスをこよなく愛す。
アマゾン ウェブ サービス ジャパン合同会社機械学習ソリューションアーキテクト。IoT の DWH 開発、データサイエンティスト兼業務コンサルタントを経て現職。プログラマの三大美徳である怠惰だけを極めてしまい、モデル構築を怠けられる AWS の AI サービスをこよなく愛す。
市川 純
 アマゾン ウェブ サービス ジャパン合同会社技術統括本部 プロトタイピング ソリューションアーキテクト2018年 に AWS へ入社した、Web サービスから家のデッキ作りまで、モノを作るという事であれば何でも好きな DIY おじさんです。最近は週末にバイクをイジるのにハマっています。
アマゾン ウェブ サービス ジャパン合同会社技術統括本部 プロトタイピング ソリューションアーキテクト2018年 に AWS へ入社した、Web サービスから家のデッキ作りまで、モノを作るという事であれば何でも好きな DIY おじさんです。最近は週末にバイクをイジるのにハマっています。
今日お探しの情報は見つかりましたか?
ページコンテンツの品質向上のため、皆さまのご意見をお寄せください