- AWS Builder Center›
- builders.flash
はじめに
ゲームな皆さんこんにちは、Game Solutions Architect の Leng (@msian.in.japan) と Game Developer Relations の Taka (@takahiroishii_) です。
ゲームバックエンドに Amazon DynamoDB を活用するという冒険の中で、ゲームデザインが生み出す複雑な検索からは逃げられません。
この投稿では「ギルド検索機能」を取り上げ、DynamoDB のデータに対してスケーラブルでサーバーレスに検索する方法をご紹介します。DynamoDB で他のゲーム機能をサポートする上で、テーブル設計でお悩みの方は是非 インベントリ機能 や クエスト管理機能 の記事を参考にしてみてください !
このクラウドレシピ (ハンズオン記事) を無料でお試しいただけます »
AWS for Games
Amazon DynamoDB とゲーム
Amazon DynamoDB はハイパフォーマンスなアプリケーションを様々な規模で実行できる、フルマネージドかつサーバーレスの Key-Value 型 NoSQL データベースです。そんな DynamoDB とゲームの相性を考える上でまずは DynamoDB の代表的な特徴をあげます
-
Key-Value データベース : キーと値というシンプルな管理方法でデータを格納
-
高いスケーラビリティ : 一貫性のある高速パフォーマンスを自動でスケールしながら実現
-
低い管理負担 : バージョンアップやメンテナンスのような作業が不要
次にそれぞれの特徴とゲームの相性を見ていきましょう
-
Key-Value データベース : プレーヤー主体であるゲームのデータベースのキーはほとんどがプレーヤー ID
-
高いスケーラビリティ : 突然人気が出たり、時間帯で総プレーヤー数が著しい変化するのがゲーム
-
低い管理負担 : 管理負担を減らすことでゲーム本来の面白さを作ることに集中できる
どの DynamoDB の特徴もゲームと非常にマッチしていて高いシナジーがあることがわかります。
一方で、今回取り上げているギルド検索のような柔軟な検索が必要なゲーム内の機能には、DynamoDB が持っているパーティションキー (PK) やソートキー (SK)、そしてグローバルセカンダリインデックス (GSI) を駆使してもゲームデザインを全て満たすには難しい事があります。
そこで今回は DynamoDB の特徴を活かしゲームのデータのバックエンドとしては引き続き活用し、柔軟な検索のために Amazon OpenSearch Serverless を合わせて採用する事でゲームデザインを満たす例を紹介します。
サービス達のおさらい
Amazon OpenSearch Serverless
Amazon OpenSearch は、インタラクティブなログ分析、リアルタイムのアプリケーションモニタリング、ウェブサイト検索などを簡単に実行できるマネージドサービスです。APIを介して検索クエリを送信することで、高速な検索結果を得ることができます。今回使用する OpenSearch Serverless は、その名の通り、開発者はサーバー構築やスケール調整などを心配することなく、検索エンジンを簡単に構築・実装することができます。あるいは、杖を意識せずに呪文を覚えれば魔法を使える魔法使いのようです。DynamoDB と OpenSearch Serverless をよりシームレスに繋ぎこむためにも今回は Amazon Kinesis Data Firehose と re:Invent 2022 で発表された Amazon EventBridge Pipes を使って行きます。
Amazon Kinesis Data Firehose
Kinesis は「動き」または「動力」という意味があります。Amazon Kinesis は、「動く」データを、リアルタイムで収集・処理・分析を行うサービスです。その中の一つは Kinesis Data Firehose であり、リアルタイムのストリーミングデータをAmazon S3 や Amazon RedShift、OpenSearch などのデータレイク、ウェアハウス、分析ツールに配信してくれます。
Amazon EventBridge Pipes
Amazon EventBridge Pipes (以下 Pipes) は、データを処理するための入力と出力を柔軟に管理するサービスです。複数のデータソースから情報を収集し、特定のルールに基づいて処理し、最終的に出力先に適切なデータを送信してくれます。以下は Pipes の各要素の説明になります。
-
ソース : データソースを示します。これは、Amazon EventBridge からのイベントや他の AWS サービスからのイベントなどを収集するためのものです。
-
フィルタリング (任意) : 特定の条件に基づいてデータをフィルタリングするためのものです。例えば、新しくギルド情報が作成された時だけターゲットにデータを流す場合などに使用されます。
-
強化 (任意) : データを補完または拡張するためのものです。例えば、プレーヤーの情報などをギルドの情報に追加するなどの場合に使用されます。
-
ターゲット : データを送信する宛先です。例えば、分析結果を保存するためのデータベースにデータを送信する場合などにはその分析用データベースなどがターゲットに指定されます。
このように、EventBridge Pipes は、ソースからターゲットまでのデータ処理フローを管理することができます。フィルタリングと強化を使用することで、より高度なデータ処理が可能となり、最終的に ターゲット に適切なデータを送信することができます。
ギルド検索
それではここからはギルドで冒険の仲間を見つける準備をしたいと思います。

ギルド
ギルドはマルチプレーヤーゲームに欠かせない機能です。例えば、同じモンスターを討伐することが目標の魔法使い達がプレーヤーグループを結成し、ギルドになります。このようなプレーヤーグループは、仲間と協力してゲームの課題に挑戦したり、ギルドに所属する魔法使い同士で連携してより強力な魔法を使うことができるので、単純な 1+1 の足し算よりもより大きな力が発揮されるでしょう。

検索したいギルドの詳細
例として 3 つの内容についてギルドを検索したいと思います。
-
ギルド名
-
ギルド概要
-
創設時のメンバーのプレーヤー名
ゲームをある一定のレベルまで進めると、そろそろ誰かと一緒に終末世界を冒険し、新しい魔法を覚えたいと思いませんか ? そういう時は、ギルド名の「初心者魔法使いの集まり」でギルド検索をしたりするでしょう。またエンドコンテンツなどを沢山の猛者と共に攻略したい時は「終末世界の救世主」というギルド概要のキーワードで検索します。もちろん、知り合いがいる場合は直接プレーヤー名で検索して知り合いが所属しているギルドを探し出すこともあるでしょう。
今回は OpenSearch の細かい操作や機能の説明を省き、DynamoDB からデータを効率的に流し検索しやすくする事にフォーカスしているのでギルド創設時のデータに絞っています。変更時のデータ等がゲームデザインの条件として必要な方は後半の ”拡張性” のセクションまで読んでみてください。
ゲームスタート !
いよいよ作業を開始したいと思います 。まずはギルドとプレーヤーのテーブルを作成します。その後に OpenSearch へのつなぎ込みをやっていきます !
テーブル設計
まずはテーブルの名前を決めますが、ズバリ Guilds と Players にしましょう ! Guilds テーブルの各項目にはそのギルドに関連する情報、ギルド名、ギルド概要、所属しているプレーヤーの ID のリストが含まれたメンバーズという属性が含まれます。Players テーブルはギルドとは直接関係しておらず、各項目はプレーヤー ID とプレーヤー名という属性のみが保存されているとしましょう。この 2 つのテーブルを上手く組み合わせる事で、ギルド情報だけではなく、例えば所属しているプレーヤーの名前も検索する際のギルド情報に紐付けることができます。
今回はこの 2 つのテーブルの内の片方 Guilds テーブルに対して DynamoDB Streams を設定する事でギルド情報が OpenSearch へと流れ込み、その途中で Players テーブルからプレーヤーの名前だけ取得して情報を拡張していきます。


Pipes で繋ぎこみ
Streams で Guilds テーブルから情報を流したら Amazon EventBridge Pipes の出番です。まず、Pipes のソースを DynamoDB に設定し、Guilds テーブルから送信されたイベントを収集するように設定します。

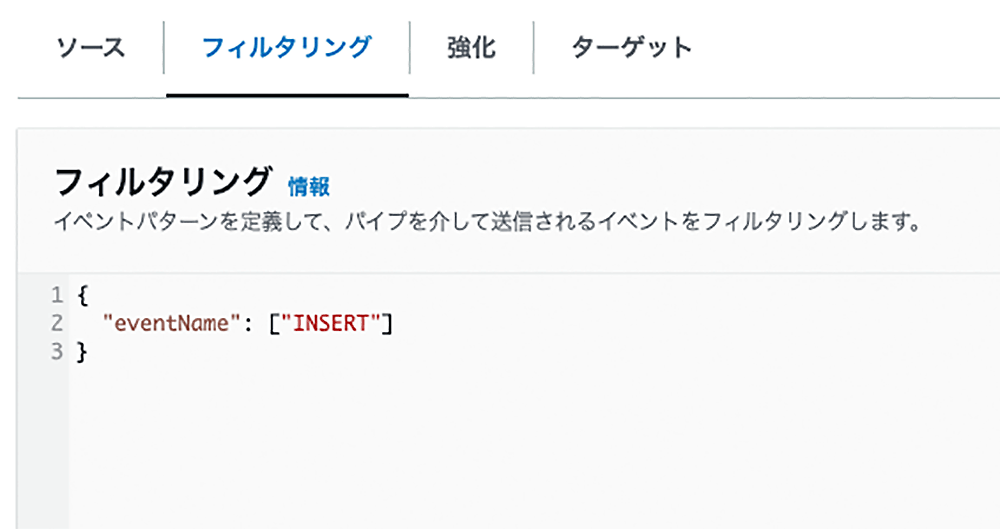
フィルタリングと強化 !
今回のサンプルでは冒頭におさらいした Pipes のフィルタリング機能を使い、データベースから送信された INSERT というイベント、つまりはとあるギルドの創設時のデータのみに絞っていきます。
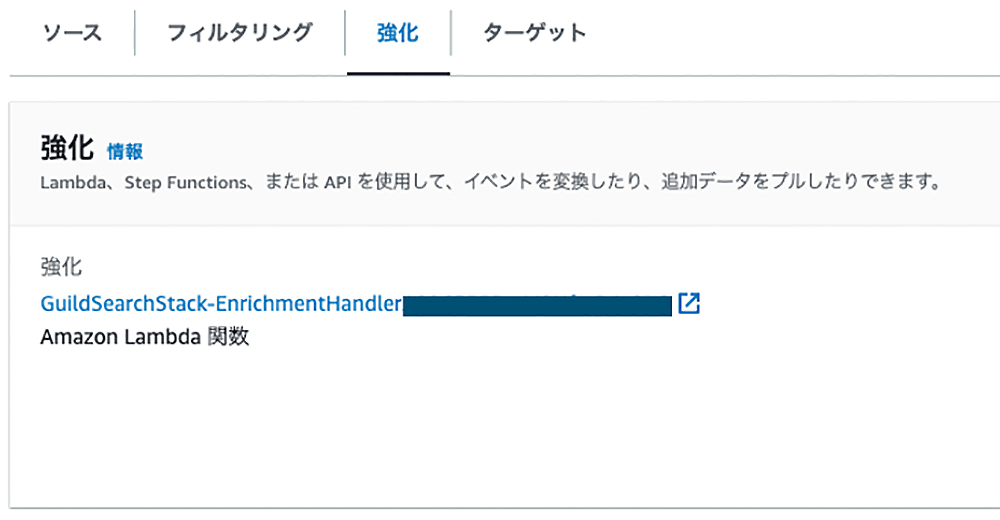
イベントの情報付加・変換
次は Pipes の強化でイベントの情報付加や変換を行います。
今回はギルドに所属するプレーヤーの名前で直接検索できるよう強化します。Guilds テーブルのメンバーズ属性はプレーヤー ID のみで構成されているので、このままではプレーヤーの名前では検索できません。ですので、 Players テーブルに対してプレーヤー ID で名前をクエリーし、メンバーズの ID と名前を交換し強化します !
今回は強化方法として Lambda 関数で行う方法を選びました、他にも AWS Step Functions などが対象になります。Pipes はこれらすべての処理を完了すると最終的にターゲットに指定された Firehose にデータを送信していきます。
やりたいことが Lambda の同期呼び出しだった場合、Amazon Kinesis Data Firehose だけでもできるのではないかと考える方もいるかもしれません。しかし、今後ゲームデザインに大きな変更があったとしてもインフラ側の変更を少なくするという点で Pipes の方がより柔軟であり、ゲーム開発で活躍する場も多いでしょう。
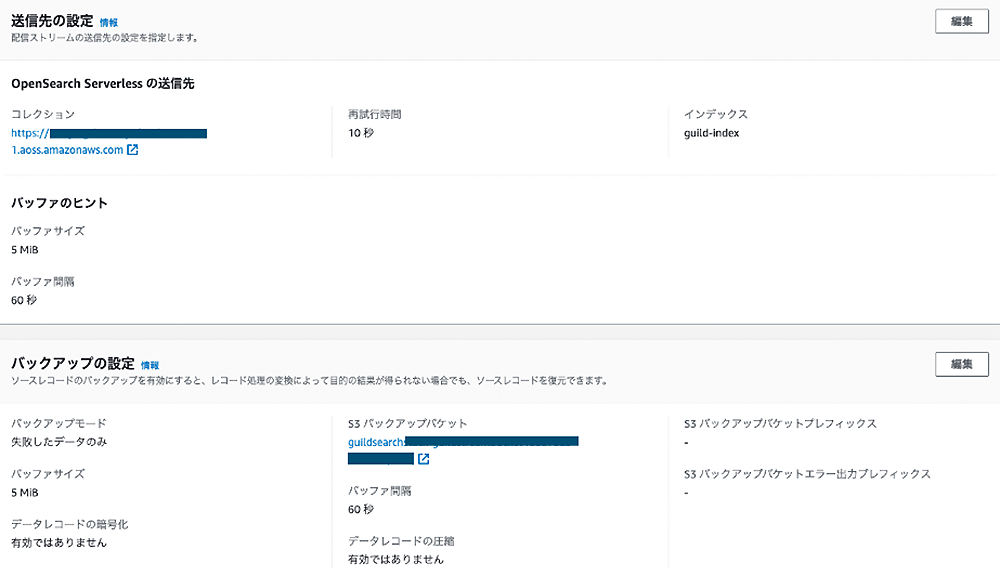
Firehose から OpenSearchへ
収集したデータは Firehose から OpenSearch Serverless へ送信します。まずは Firehose に OpenSearch のインデックスを指定する必要があります。次に OpenSearch 側で きめ細やかなアクセスコントロール を設定している場合は Firehose に必要なアクセス権限を全て与えます。さらにこのサンプルでは失敗した場合はデータを S3に転送するように設定しています。このように Pipes、Firehose そして OpenSearch Serverless を組み合わせることでより効率的に DynamoDB のデータを収集、処理、そして検索できるようになりました !
検索してみる !
OpenSearch の Node.js 向け Client を利用
さらに今回は OpenSearch の Node.js 向け Client を利用して Lambda からもアクセスしてみます。
サンプルコード
以下のサンプルコードは Amazon API Gateway に紐付いた Lambda 内で OpenSearch Client を使い、ギルド概要に対して ”初心者” というキーワードで検索を行っています。
export const handler: APIGatewayProxyHandler =
async (): Promise<APIGatewayProxyResult> => {
const query = {
query: {
match: {
description: {
query: "初心者",
},
},
},
};
const response = await osClient.search({
index: 'guild-index',
body: query,
});
return {
statusCode: 200,
body: JSON.stringify(response.body.hits),
};
};検索結果
この検索の結果は以下になります。
{
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.3092299,
"hits": [
{
"_index": "guild-index",
"_id": "jCU5WYYBDkx1jnNsA4z6",
"_score": 2.3092299,
"_source": {
"members": [
"オレンジ魔法使い",
"週末だけ戦士"
],
"description": "初心者大歓迎です!レベル・スキル不問です",
"guildId": "guild1",
"guildName": "初心者魔法使いの集まり"
}
}
]
}特定のギルドを探す
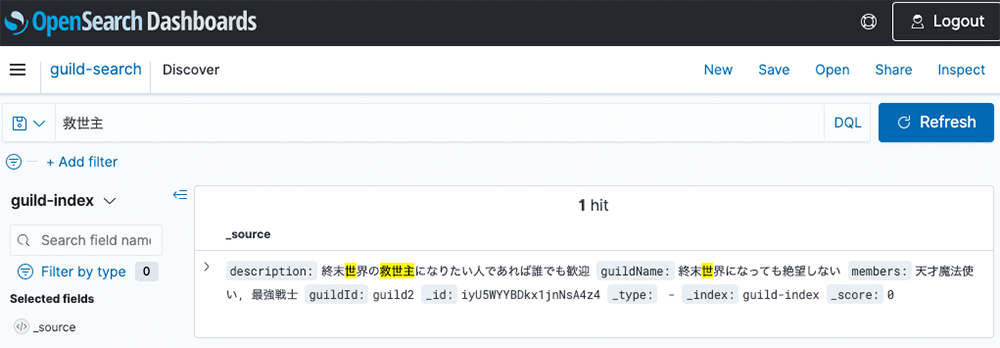
初心者のプレーヤーに優しそうなギルドが見つかりました ! 参加申請を送りたい所ですがもう少し検索を続けます。 次はかの有名な “天才魔法使い” さんがいるギルドを探してみましょう。
export const handler: APIGatewayProxyHandler = async (): Promise<APIGatewayProxyResult> => { const query = { query: { match: { members: { query: "天才魔法使い", }, }, }, }; const response = await osClient.search({ index: "guild-index", body: query, }); return { statusCode: 200, body: JSON.stringify(response.body.hits), }; };検索結果
結果は 2 件返ってきました。
{
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 2.157612,
"hits": [
{
"_index": "guild-index",
"_id": "iyU5WYYBDkx1jnNsA4z4",
"_score": 2.157612,
"_source": {
"members": [
"天才魔法使い",
"最強戦士"
],
"description": "終末世界の救世主になりたい人であれば誰でも歓迎",
"guildId": "guild2",
"guildName": "終末世界になっても絶望しない"
}
},
{
"_index": "guild-index",
"_id": "jCU5WYYBDkx1jnNsA4z6",
"_score": 0.71535087,
"_source": {
"members": [
"オレンジ魔法使い",
"週末だけ戦士"
],
"description": "初心者大歓迎です!レベル・スキル不問です",
"guildId": "guild1",
"guildName": "初心者魔法使いの集まり"
}
}
]
}ギルドの ID も含まれる
この例ではオプションは何も変更していない Full-Text Query になるので、“魔法使い” というキーワードが含まれるプレーヤーがいるギルドが2件返ってきました。しかし、 _score を見て頂くと”天才魔法使い”さんがいるギルドのほうが高い事が伺えます。
全ての検索結果にはキーワードだけでは無くギルドの ID も含まれています。ゲームクライアントに結果情報を返す際は、このギルド ID を使ってデータベースからより詳細な情報を追加できます。ギルドのレベルや設立時期などが分かり各地の戦士と情報交換ができ、プレーヤーは自分にピッタリなギルドを見つけやすくなるでしょう。
拡張性
今回は DynamoDB に保存されたゲームのデータをより自由に検索するために必要な AWS サービスの組み合わせにフォーカスした例になりました。ここからスタートする事で、より複雑なゲームデザインに合わせて様々な構成へと拡張していく事が可能です。例えば、今回のように作成時に一度だけ OpenSearch にデータを送信するのではなく、ギルド情報が変更される度にデータを送りドキュメント ID を使って上書き保存する事でギルド情報に変更がかかっても問題なく検索する事ができます。さらに、今回の例のようにプレーヤーの名前を検索用に OpenSearch に保存していても、同じようにドキュメント ID を活用して一部のデータを更新する事も可能です。
OpenSearch のドキュメント ID を使った操作の詳しい説明は こちら を参考にして下さい。
まとめ
気の合った友達と一緒にゲームプレイするのはなんて楽しいことでしょう。ゲームのバックエンドとして採用が増えている Amazon DynamoDB と Amazon OpenSearch Serverless の組み合わせで、シームレスなギルド検索をゼロからやってみました。
なお、今回ご紹介したようなゲーム向け DynamoDB の活用例やその他のデータベースサービスに関する情報は、 AWS for Games のゲーム向けデータベース でまとめて確認できます。是非皆さんのゲームにあったデータベースを選んで、楽しいゲーム開発にお役立てください !
筆者プロフィール
Sheng Hsia Leng
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
ゲーム業界に特化したソリューションアーキテクトとしてお客様を支援しております。
RPG とドット絵ゲームが好きです。オフモードの時はインスタでバイリンガル漫画を投稿しています。

石井 宇大
アマゾン ウェブ サービス ジャパン合同会社
ゲームデベロッパーリレーションズ
カナダ🇨🇦 で 10 年以上生活していたゲームで遊ぶのも作るのも好きな元ゲームエンジニア。趣味は奥さんと季節を感じながら美味しい物を食べ大好きな赤🍷 を嗜む事。
普段は楽しいゲーム作りに繋がるよう、様々なソリューションを提供するお仕事をしています。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages