- AWS Builder Center
- builders.flash
サーバーレスアプリケーション開発におけるエラーハンドリング ~ マイクロバッチ・ストリーミングパターン
2023-09-01 | Author : 大磯 直人
はじめに
今回はマイクロバッチ・ストリーミング パターンにおけるエラーハンドリングを AWS で実現する際に抑えておくべきポイントについてご紹介します。マイクロバッチ・ストリーミングパターンのユースケースでは、イベントソースマッピングと、ポイズン・ピルメッセージのエラーハンドリングについてご説明します。
本シリーズの オープニング記事 でもサーバーレスエラーハンドリングの基礎と絡めてご説明していますので、またご覧になられていない方は、そちらからご覧いただけると理解が深まると思います !
builders.flash メールメンバー登録
ユースケース
マイクロバッチパターンとストリーミングパターンは、プロデューサーがメッセージを生成し、メッセージストアを介してコンシューマーがメッセージを処理するフローを持ちます。プロデューサーとコンシューマー間にメッセージストアが挟むことで、一定の数または時間の単位で複数のメッセージをまとめて処理することができます。
このように一定の単位でまとまったメッセージを処理する時のみ、動的にリソースプロビジョニングされ、それに応じたコストが発生をする点において、マイクロバッチやストリーミング形式のデータ処理も、サーバーレスと相性の良いユースケースになります。
メッセージストアをイベントソースとする サーバーレスパターン における代表的な適用シーン / ユースケース以下のケースがあります。
- 流入データの連続処理
- IoT バックエンド
- データ変更トリガー処理
- ログデータ収集処理
パターン特性
マイクロバッチ・ストリーミングパターンのサーバーレスアプリケーションの特性として、メッセージの Pull 形式による非同期呼び出しがあります。前提の用語の説明になりますが、メッセージストアをイベントソースとするパターンで登場する概念として、キューとストリームがあります。どちらもアプリケーションとアプリケーションがメッセージを介してやり取りをする際に、一時的にメッセージを格納するバッファ領域になります。
Pull 型のサーバーレスアプリケーションは、キューとストリームに保存されたメッセージを処理するために、コンシューマーからアプリケーションがキューに対してポーリングを行ってメッセージの有無を確認し、メッセージがあった場合にそのメッセージを取得して処理を行います。
Web API パターン の記事で触れましたが、Pull 形式の処理はメッセージを取得する責任がその際のエラーハンドリングを含めてサーバー側にあるため、Push 形式の処理と比較してコードの実装によってカバーする責任範囲が増える傾向にあります。後ほどご紹介しますが、メッセージを Pull する実装については、サーバーレスを利用すると大部分はサービス側にオフロードできることが可能です。
またマイクロバッチ・ストリーミングパターンのサーバーレスアプリケーションのもう一つ重要な特性として、一度に複数のメッセージを処理できる点も特性としてあげられます。マイクロバッチ・ストリーミングパターンでは、メッセージバッファに溜まったメッセージ数がしきい値を超えたら、トリガーを発火させるなどの手法が取られます。その際に効率的にメッセージを処理するために、キューから複数メッセージをまとめて取得することもあります。
このような複数メッセージをまとめて処理することをバッチ実行と呼びます。しかしながら、バッチという用語がマイクロバッチ、定期バッチ、コピーバッチのような一定間隔の定期処理と混同してしまうため、ここでは「一括処理」と表現します。
メッセージバッファとなる AWS サービス
メッセージバッファには、マイクロバッチ方式の際のメッセージキューの役割を果たす Amazon SQS と、ストリーム方式のパイプラインとなる Amazon Kinesis Data Streams などのサービスと大きく 2 種類あります。
SQS はサーバーレスのメッセージキューサービスです。 SQS を利用することで管理不要の信頼性の高いキューを利用することが可能です。 SQS にはベストエフォートでの順序保証を行う標準キューと、キュー側で FIFO (First-In-First-Out) の順序保証を行う FIFO キューの 2 種類のキューがあります。スループットが重視される場合においては標準キュー、メッセージの順序性をキューで担保する必要がある場合には FIFO キューという使い分けが出来ます。
Amazon Kinesis
Kinesis は、サーバーレスデータストリーミングサービスであり、あらゆる規模のデータストリームを簡単にキャプチャ、保存、処理します。Kinesis を利用することで、大量のデータをリアルタイムでスケーラブルに処理することが可能です。
Kinesis はプロデューサーから送信されたデータレコードを保持するデータストアであり、単一のデータストリームは複数のシャードから構成されています。データストリームに入力された、レコードはシャードごとに順序保証を行い、シーケンシャルにコンシューマーによって取得、処理されます。
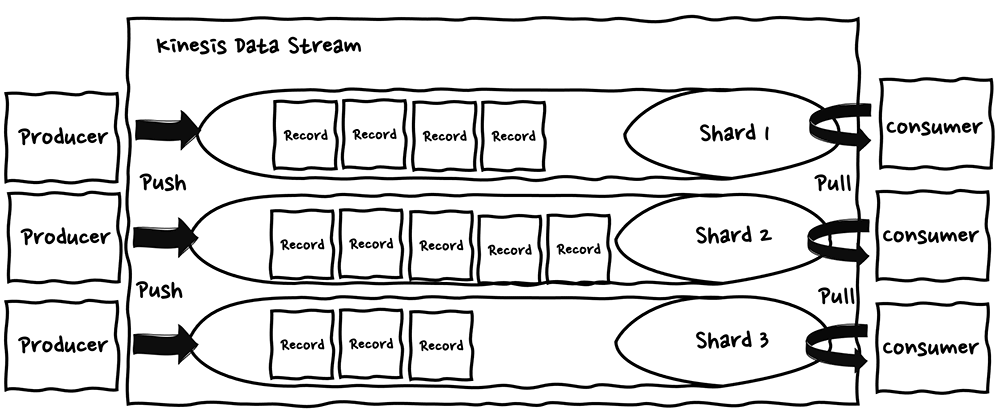
メッセージストアと サーバーレスコンシューマーとの中継処理
マイクロバッチ・ストリーミングパターンのサーバーレスアプリケーションの特性として、Pull 形式のメッセージ処理であることから、メッセージを取得する責任がその際のエラーハンドリングを含めてサーバー側にあることを説明しました。
このメッセージを取得する責任については、AWS Lambda ではイベントソースマッピング (ESM) を利用することで、サービス側に任せることが出来ます。イベントソースマッピングとは、イベントソースからメッセージを読み取り、Lambda 関数を呼び出す Poller と呼ばれる役割を果たす AWS 管理のリソースのことです。イベントソースマッピングを利用すると、Poller がストリームまたはキューのメッセージを取得し、Lambda 関数の呼び出しを行うため、サーバーレスアプリケーション側のユーザーコードでメッセージを取得する処理を記述せずとも、ストリームまたはキューのメッセージを処理できます。
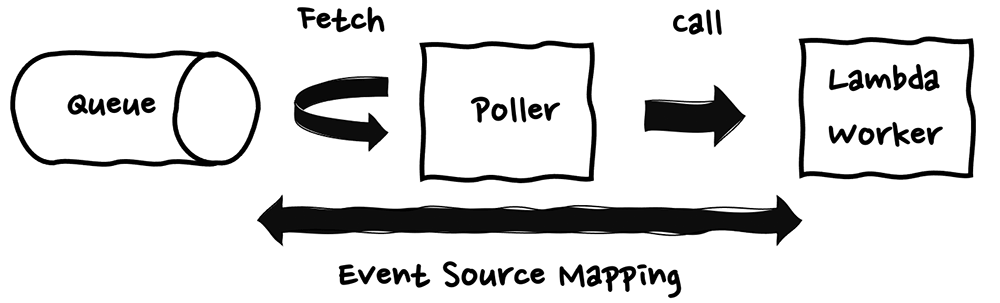
Amazon EventBridge Pipes
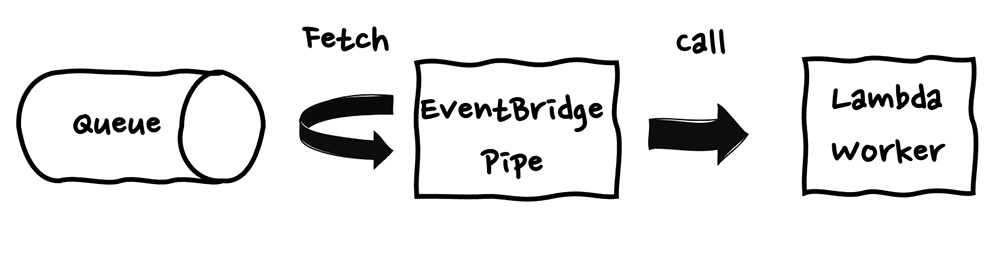
また、このようなメッセージ Pull 型のサーバーレスのアプリケーション実行環境にイベントソースマッピングのような Push 型の起動を実現するサービスとして Amazon EventBridge Pipes があります。
EventBridge Pipes はプロデューサーとコンシューマのインテグレーションを行うサーバーレスサービスです。EventBridge Pipes を用いることで、Lambda のイベントソースマッピング と同様の仕組みを実現することが出来ます。つまり、AWS Fargate や Amazon Step Functions での処理においても、メッセージを取得する処理をプログラムとして記述する必要がなくなります。
[Tips]
イベントソースマッピングや EvendBridge Pipes を利用する際に合わせて利用を推奨しているのが、イベントフィルタリングという予め決められたルールにマッチしないメッセージをフィルターする機能です。効率的なエラーハンドリングを行うためには必須の機能で、不正なメッセージの処理に伴う実行コストの削減を実現します。イベントフィルタのベストプラクティスについては こちらのドキュメント をご覧ください。
エラーハンドリング
マイクロバッチ・ストリーミングパターンのサーバーレスアプリケーションのエラーハンドリング
マイクロバッチ・ストリーミングパターンでも従来のパターンで紹介してきたエラーハンドリングである、リトライとデータの破棄・退避を行うための設定が必要となります。これら従来のエラーハンドリングについては、 イベントソースマッピングがその機能を担ってくれますが、リトライで検討すべき回数と間隔や、データの破棄と退避の判断は、AWS サーバーレスサービスの機能で設定します。
加えて、複数メッセージを一度に処理する際に、デフォルトでは Lambda 関数が複数メッセージの内の 1 つのメッセージを処理できなかった場合、一括処理対象の複数メッセージ全体がリトライとなります。そのため複数メッセージの一括処理のデフォルトの動作により、1 つの失敗メッセージ だけで Lambda 関数がすべてのバッチメッセージを複数回再試行する可能性があります。
このような複数のメッセージの中に含まれるエラーを引き起こすメッセージをポイズン・ピルメッセージと言います。特に順序性を保証するメッセージストアを利用している場合、こういったポイズン・ピルメッセージが、成功するまで同じレコードセットで Lambda 呼び出しを再試行し続けることによって、システムのボトルネックになる可能性があります。今回はこのポイズン・ピルメッセージへの対応にフォーカスを当ててご説明します。
[Tips]
ポイズン・ピルメッセージについては コンシューマーを停止させるために使用されるメッセージの意味で使われることもあります。
今回のポイズン・ピルメッセージについては、AWS の以下のドキュメントで利用されているコンテキストで利用しています。https://docs.aws.amazon.com/ja_jp/kinesisanalytics/latest/dev/how-it-works-output-lambda.html
AWS マネージドサービスの組み込みのエラーハンドリング機構
イベントソースマッピングを活用した、SQS 利用時のポイズン・ピルメッセージのエラーハンドリング
Web API パターン で紹介したように、リトライで検討すべきポイントは、回数と間隔です。イベントソースマッピングにおけるリトライの回数と間隔の制御は、キューの場合可視性タイムアウトと、メッセージの有効期限を利用します。キューをイベントソースとする Lambda 内で処理が完了とされない場合、メッセージが再度キューに現れますが、可視性タイムアウトを設定することで、その間隔を制御することが可能です。また、いつまでメッセージが再度キューに現れるかはメッセージ保持期間を設定することで制御可能です。
イベント駆動のデータ加工、連携処理パターン で紹介したように、データの破棄・退避を行うための設定は、キューにデッドレターキューを設定することで実現可能です。
イベントソースマッピングを活用した、ストリーム利用時のポイズン・ピルメッセージのエラーハンドリング
ストリーム利用時にもイベントソースマッピングを利用して、リトライや、データの破棄・退避によるエラーハンドリングを行うことができます。しかし、先程述べたように、ソースが Kinesis などのストリームのような順序性を保証するメッセージストアを利用している場合、複数メッセージを一括処理する際のポイズン・ピルメッセージによって、成功するまで同じレコードセットで Lambda 呼び出しを再試行し続ける問題が発生します。
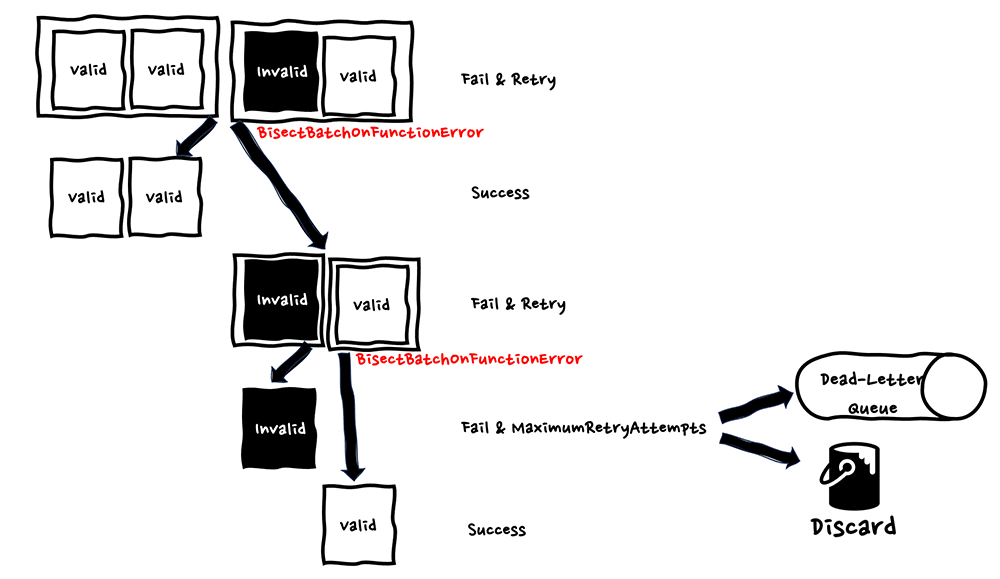
このポイズン・ピルメッセージに対応するための AWS の機能として、BisectBatchOnFunctionError があります。BisectBatchOnFunctionError は、二分探索法 (bisect) で一括処理対象の複数メッセージを 2 つの一括処理単位に分割した上でリトライを実行し、ポイズン・ピルを絞り込む手法になります。以下に図を用いて、BisectBatchOnFunctionError の挙動についてご説明します。
BisectBatchOnFunctionError の挙動
初回処理時は一括処理のメッセージ数の単位として4 つメッセージを一度に処理していますが、そのうちの 3 つ目のメッセージが、アプリケーションロジック上正常に処理できないポイズン・ピルメッセージとなっています。
エラーが発生すると BisectBatchOnFunctionError により、複数メッセージ全体が 2 分割され、それぞれが別々の処理としてリトライが行われます。
分割後の再試行の内、前 2 つの正常なメッセージのみの一括処理については正常に完了しますが、残りの 2 つの中にはポイズン・ピルメッセージが含まれているため、再度エラーが発生します。すると再び BisectBatchOnFunctionError により、複数メッセージ全体が 2 分割され、それぞれが別々の処理としてリトライが行われます。
残りは正常なメッセージが処理され、残ったポイズン・ピルメッセージについては、再試行回数上限に達したため、DLQ への退避またはデータ破棄の形で処理を行い、後続の処理を継続できるようにしています。
一括処理するメッセージ数であるバッチサイズで指定したメッセージが、BisectBatchOnFunctionError により 2 分割されていくため、最後 1 つになったタイミングでデータの破棄・退避を行えるように、再試行回数を設定する必要があります。今回の例では、バッチサイズが 4 なので、再試行回数を 2 としています。
BisectBatchOnFunctionError の設定方法
BisectBatchOnFunctionError のマネジメントコンソールでの設定方法としては、Lambda の イベントソースマッピングの場合、トリガーに Kinesis などのストリームサービスを選択し、「エラー時にバッチを分割」のチェックマークをつけるだけで設定ができます。

EventBridge Pipes の設定
EventBridge Pipes の場合、Source 設定の追加設定の「部分バッチアイテムの失敗時」で AUTOMATIC_BISECT を選択するだけで設定ができます。

アプリケーションで行うエラーハンドリング
上記のような BisectBatchOnFunctionError による二分探索法 (bisect) で一括処理対象の複数メッセージを分割した上でリトライを実行し、ポイズン・ピルメッセージを絞り込むリトライは、べき等性が担保されていることが必須です。
処理にべき等性がない場合は論理整合性の問題になりえますし、順序性が重要である場合には、失敗した時点で失敗したメッセージのデータを破棄、または退避するまでは、後続のメッセージの処理を行ってはいけないはずです。
仮にべき等性が担保されている場合においても、二分探索法 (bisect) でのリトライをすることで不要な実行が発生することによるリソースの無駄遣いが発生します。
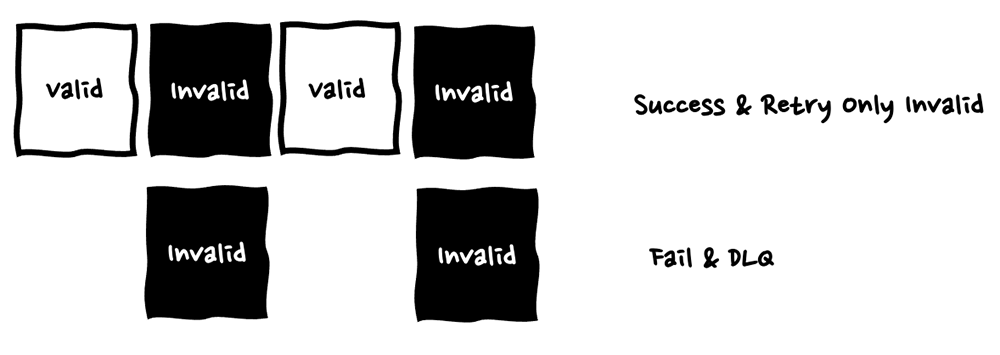
このような問題への対策として、アプリケーションの中でポイズン・ピルメッセージを特定し、レスポンスに定められた形式でポイズン・ピルメッセージの ID を含めることで、ポイズン・ピルメッセージのみをエラーハンドリングの対象とし、より効率的なエラーハンドリングを行うことが出来ます。
Amazon SQS の場合の対処手法 : Partial Batch Response
SQS の場合はpartial batch response を利用して、ポイズン・ピルメッセージのみエラーハンドリングを実現します。
繰り返しになりますが、デフォルトでは、Lambda 関数が SQS にある処理対象の 1 つ以上のメッセージの内、1 つのメッセージの処理に失敗した場合、処理対象のメッセージ全体がキューに戻されます。
しかし、partial batch response 利用することで、Lambda 関数が失敗したメッセージのみをリトライする機能を提供します。これにより、反復的なデータ転送の必要性を排除し、スループットを向上させることができます。
partial batch response を利用するには、itemIdentifier をキーとした値が失敗したメッセージ ID の配列を持つ batchItemFailures JSON レスポンスで返す必要があります。
Partial Batch Response のサンプルコード
以下が partial batch response のサンプルコードになります。このコードは、一括処理として渡ってきた複数メッセージに対して、それぞれにビジネスロジックとしての処理を行う関数です。
exports.handler = async (event) => {
const batchItemFailures = event.Records.reduce((batchItemFailures, record) => {
const { body, messageId } = record;
try {
bussinessLogic(body) // bussinessLogic 関数の中で、エラー時にはthrow new Error(messageId)をしている
} catch (e) { // エラーが発生したものは batchItemFailures に詰める
console.error({messageId}) // エラーになったレコードの messageId を参照している
batchItemFailures.push({
"itemIdentifier": messageId
})
}
return batchItemFailures
}, [])
return { batchItemFailures };
};レスポンスデータのサンプル
処理の中で、エラーになったメッセージをキャッチし、batchItemFailures の配列を生成し、オブジェクトとして返すことで、partial batch response を利用しています。 以下のオブジェクトがレスポンスデータのサンプルです。今回で言えば、id2 と id4 のメッセージが失敗として扱われます。
{
"batchItemFailures": [
{
"itemIdentifier": "id2"
},
{
"itemIdentifier": "id4"
}
]
}FIFO キューで利用する場合
この機能を FIFO キューで使用する場合、関数は最初の失敗の後にメッセージの処理を停止し、その後のメッセージ ID をすべて batchItemFailures に含めてレスポンスを行う必要があります。これによって、キュー内のメッセージの順序性を担保します。
以上が partial batch response のサンプルコードになりますが、partial batch response については こちら にベストプラクティスがまとまっていますので、ご覧ください。
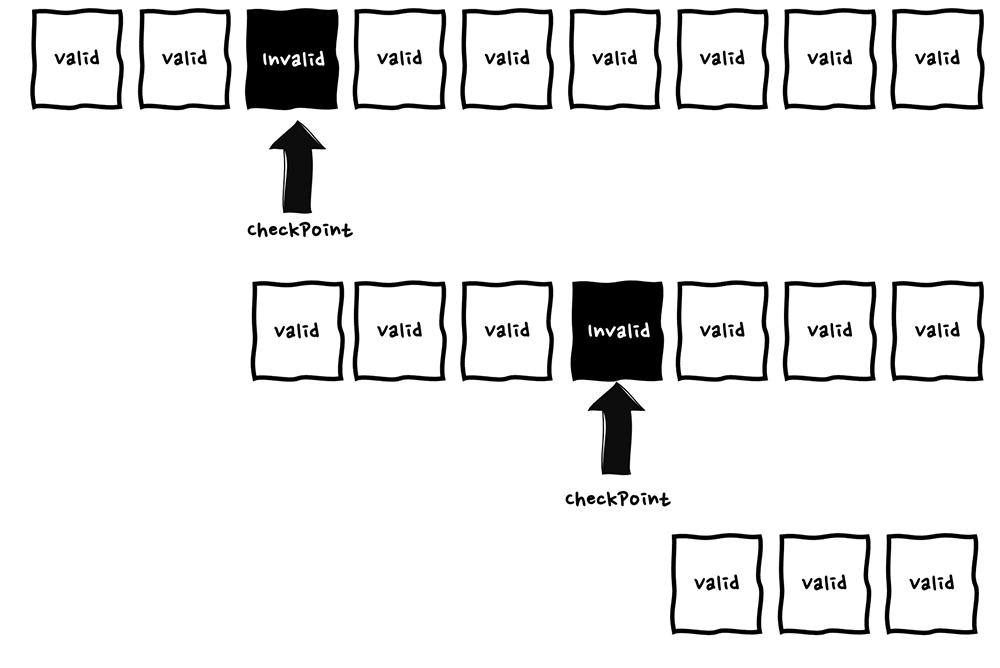
ストリーム の場合の対処手法 : カスタムチェックポイント
これが Kinesis などのストリームがイベントソースなった場合は、 partial batch response と同様の役割の機能としてカスタムチェックポイントがあります。
使い方は partial batch response と同じく、itemIdentifier をキーとした値が失敗したメッセージ ID の配列を持つ batchItemFailures JSON レスポンスで返す必要がありますが、batchitemFailures 配列に複数のアイテムが含まれている場合、最小のシーケンス番号がチェックポイントとして使用されます。
原則最初にエラーが発生した時点で、メッセージの処理を停止し、その時点のメッセージ ID を batchItemFailures に含めてレスポンスを行います。
以下が カスタムチェックポイント のサンプルコードになります。
カスタムチェックポイントのサンプルコード
このコードは一括処理として渡ってきた複数メッセージに対して、それぞれにビジネスロジックとしての処理を行う関数です。
exports.handler = async (event) => {
try { // エラー時にはループを抜けて、エラーになったレコードのsequenceNumberをcatchに渡している。
event.Records.forEach((record, index) => {
const { data, sequenceNumber } = record.kinesis;
bussinessLogic(data) // bussinessLogic 関数の中で、エラー時にはthrow new Error(sequenceNumber)をしている
console.log('Success: ', sequenceNumber)
})
} catch (err) {
console.error('Failure sequenceNumber: ', err.message) // エラーになったレコードのsequenceNumberを参照している
return { "batchItemFailures": [ {"itemIdentifier": err.message} ] }
}
}エラー時の挙動
エラー時の挙動は、ループを抜けてエラーになったレコードの sequenceNumber を catch 句に渡しています。catch 句では、渡ってきたエラーになったレコードの sequenceNumber を itemIdentifier をキーとするオブジェクトの配列に格納しています。Lambda 関数は、 batchItemFailures をキーとするオブジェクトに、その配列を渡した値を返すことで、カスタムチェックポイント を実現しています。
以上がカスタムチェックポイントのサンプルコードになりますが、カスタムチェックポイントについては こちらのブログ がわかりやすいため、ご参照ください。
まとめ
今回はマイクロバッチ・ストリーミングを行うユースケースのエラーハンドリングについてご紹介しました。
マイクロバッチ・ストリーミング パターンのサーバーレスアプリケーションの特性として、メッセージの Pull 形式による実行方式が挙げられます。Pull 形式の処理はメッセージを取得する責任がその際のエラーハンドリングを行う必要がありますが、Lambda の場合はイベントソースマッピングを利用することで、メッセージを取得する責任をサービス側にアウトソースすることが出来ます。
またもう一つの特性として、複数メッセージの一括処理による一度に複数のメッセージの処理とその際に発生するポイズン・ピルメッセージのエラーハンドリング手法についてご紹介しました。
AWS の機能のみで対応する場合には、イベントソースマッピングの機能を利用して、リトライとデータの退避・破棄を行います。SQS をソースとする場合、ソースとなるキューにリトライの制御は、可視性タイムアウトと、メッセージの有効期限を利用して行い、データの破棄と退避はキューにデッドレターキューを設定することで実現可能です。ストリームをソースとする場合は、BisectBatchOnFunctionError を用いて、2 分割を行いながら再試行とデッドレターキューへのデータの退避が可能です。
またアプリケーションの中でポイズン・ピルメッセージを特定することで、AWS に機構のみに頼った手法よりも、効率的なエラーハンドリングが行なうことができます。メッセージストアが SQS の場合は、partial batch response、メッセージバッファが Kinesis の場合はカスタムチェックポイントを利用することで、アプリケーションの中で特定したポイズン・ピルメッセージをサーバーレスサービスに通知し、エラーハンドリングを行うことが出来ます。
次回は複数の処理から成り立つマイクロサービスや、ワークフロー型の処理のユースケースにおけるサーバーレスアプリケーションのエラーハンドリングについてご紹介します。
サーバーレス学習のための関連資料
筆者プロフィール
大磯 直人
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
インターネット・Web サービスを提供されるお客様に対して技術支援を行っています。好きな食べ物は 肉・寿司・ラーメン です。空き時間は永遠に YouTube を見ています。好きな AWS サービスは AWS StepFunctions です。
