サーバーレスアプリケーション開発におけるエラーハンドリング
2023-06-01 | Author : 大磯 直人

はじめに
皆さん、こんにちは。AWS ソリューションアーキテクトの大磯です。
本シリーズではサーバーレスアプリケーション開発におけるエラーハンドリングについてお伝えしていきます。
builders.flash メールメンバー登録
エラーハンドリングとは
みなさん ! サーバーレスアプリケーションの開発楽しんでますか ?
サーバーレスアプリケーションの開発は、インフラ面での非機能要件の責任を AWS のマネージド型サービスに委譲できることから、アプリケーションの本質 である ”ロジック開発" に注⼒できる点が私は大好きです ! 機能を実装していくプロセスは、明確にやりたいことに向かって進んでいくこともあり、成果がわかりやすく非常に楽しいですよね。
しかしサーバーレスアプリケーション開発は実現したいロジックの実装に集中できるからといって、正常系の実装の検討しか行わずに、サービスをリリースしていませんでしょうか ? サーバーレス環境でアプリケーションを動かせば、無条件に品質の高いアプリケーション実現できるかと言うとそうではありません。インフラ面での非機能要件はクラウドサービスに任せられても、アプリケーション面でのエラーを含む例外的な処理に対しては、皆様で責任を負う必要があります。
つまり我々開発者は、正常に処理ができないあらゆるケースに対しての挙動を制御する必要があります。そのような処理のことをエラーハンドリングと呼びます。
エラーハンドリングは重要
エラーハンドリングが不十分なアプリケーションは様々な問題を抱えています。具体的には挙動が不安定であったり、バグ発生時に原因を特定しづらかったり、論理不整合を許容してしまったりします。こういった理由より、システムをリリースする際にエラーハンドリングの実装は必須です。
それにもかかわらず、エラーハンドリングの実装は、本来実現したいこととは直接的には関係のない処理であることから、そもそも検討がなされなかったり、また想定されるエラーケースのモレが見落とされたりして、エラーハンドリングが不十分な状態でアプリケーションがリリースされてしまうシーンも多いように思われます。
エラーハンドリングすべきエラーのパターン
エラーハンドリングを検討する上で、網羅的なケースをカバーをするにはどのような検討を行うべきでしょうか。エラーのパターンはエラーの発生箇所の観点で、アプリケーション内で発生するエラーとアプリケーション外で発生するエラーに分けられます。
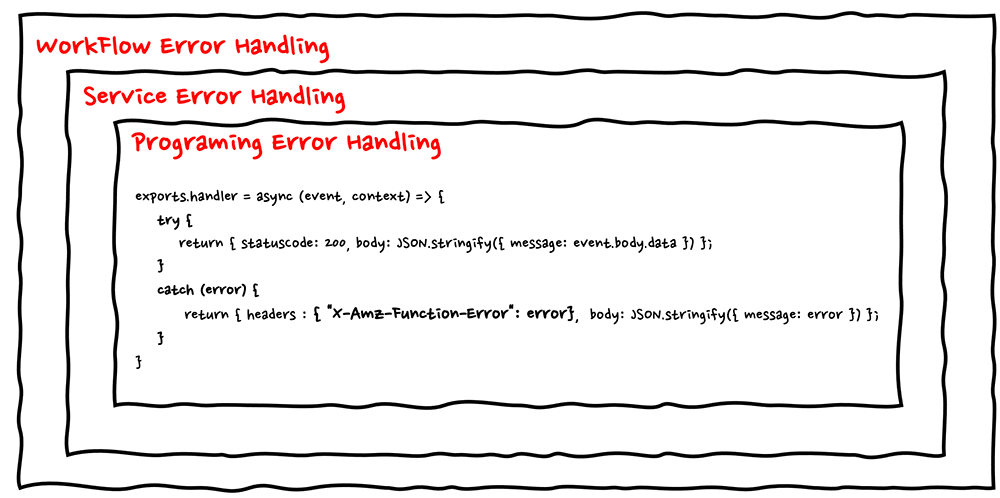
アプリケーション内で発生するエラーの例としては、コード起因によるRuntimeErrorや、ロジック起因による論理不整合によるエラーが挙げられます。このようなエラーは、実行されるプログラムのロジックにエラーの処理を含むことで、エラーハンドリングを行います。
一方アプリケーション外で発生するエラーの例としては、環境起因によるインフラ障害やNW障害や、設定起因によるスロットリングなどもあります。このようなエラーはアプリケーションを起動している側でエラーハンドリングを行います。
また例外的に、ワークフローやマイクロサービスのような複数のアプリケーションによって整合性を担保する必要がある場合においては、アプリケーションをまたがったエラーハンドリングも検討する必要があります。そのようなエラーは、複数のアプリケーションに対して、アプリケーション内のエラーとアプリケーション外のエラーの両方をハンドリングする必要があります。
このようにエラーには様々なパターンが存在し、それぞれエラーハンドリングの方法も異なってきます。
エラーハンドリングの手法
様々なエラーのパターンに対して検討すべきことはいくつもありますが、サーバーレスにおいては主にイベントによって生成されるメッセージの受け渡しや、メッセージのごとの処理の制御を行うための検討が重要です。言い換えると、メッセージを確実に受け渡しを行うためにどういった手法や機構を利用するのか、受け渡したメッセージが正常ではなかった場合にどの様なハンドリングを行うべきなのかについての検討が必要となってきます。
こういったエラーハンドリングを行うための手法について、全体観を以下のようにまとめました。これら 1 つ 1 つについて説明していきます。
1. リトライ (Retry)
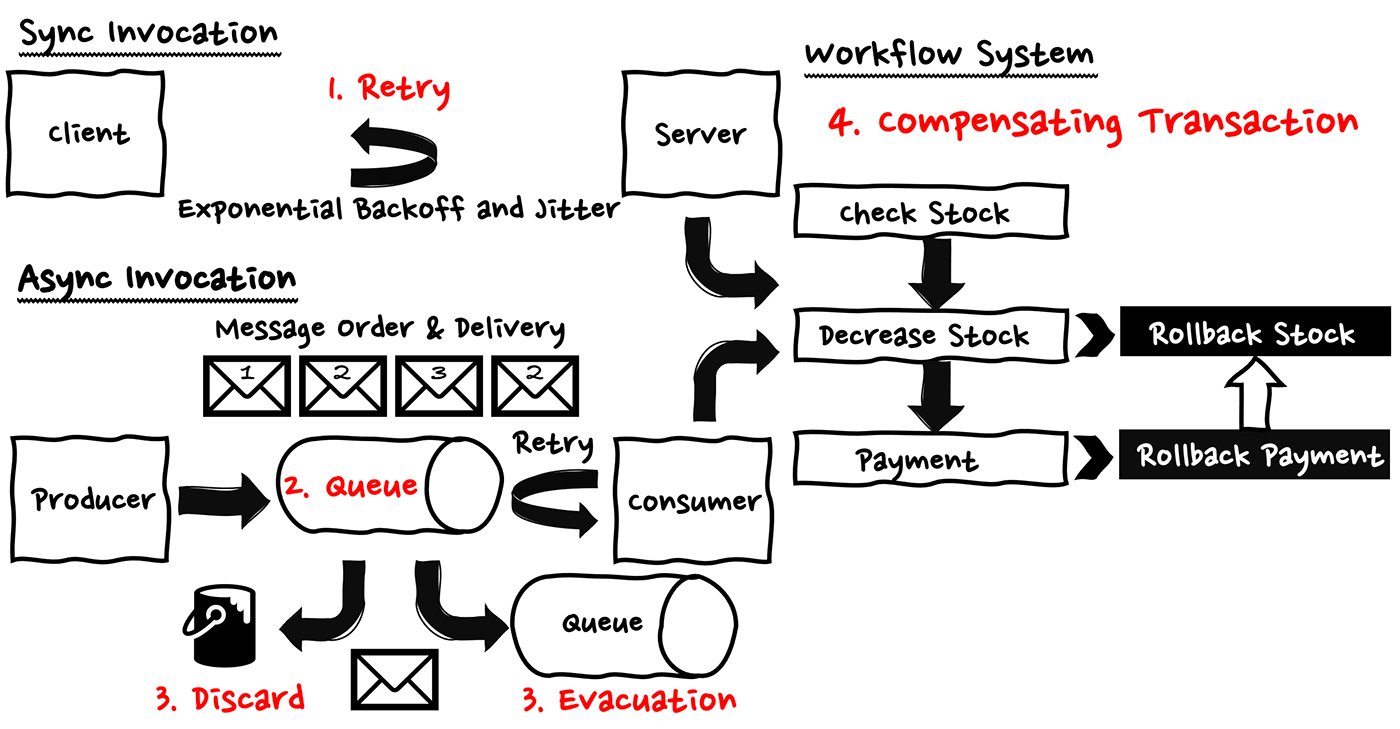
メッセージの受け渡しの精度を高めるためのエラーハンドリングとしてリトライがあります。リトライについて検討するポイントとしては「何回またはどの期間リトライするか」、そして「どれくらい実行間隔をあけるか」になります。
リトライの工夫として重要な点が 2 つあります。1 つは指数バックオフ (= エクスポネンシャルバックオフ) です。これはリトライの回数が増えるごとにリトライ間隔を 2 倍していく手法になります。等間隔でリトライを実行すると、ダウン中のサービスにトラフィックがどんどん集中していき、復帰に影響を与えてしまう可能性があります。そのため、エラーが返ってくるごとに、前回待っただけでの時間では不十分だったので、次回はそれ以上待機することで、リトライの集中を防ぐことができます。
もう一つはジッターです。これはエクスポネンシャルバックオフと合わせて使われるリトライのタイミングにランダムな微調整を行う手法です。単純な指数バックオフではリクエスト回数の増加を防ぐことはできますが、同時に多くのリクエストが発生してしまうリスクは防げません。ジッターを取り入れることで、リトライの間隔にランダムなズレを持たせ、同時に発生するリトライを分散させるイメージになります。
これらの 2 つによりリトライリクエストの増加、集中を防ぎ、一時的なエラーやランダムなエラーに対する効率的なハンドリングを実現できます。

2. メッセージキューイング (Queue)
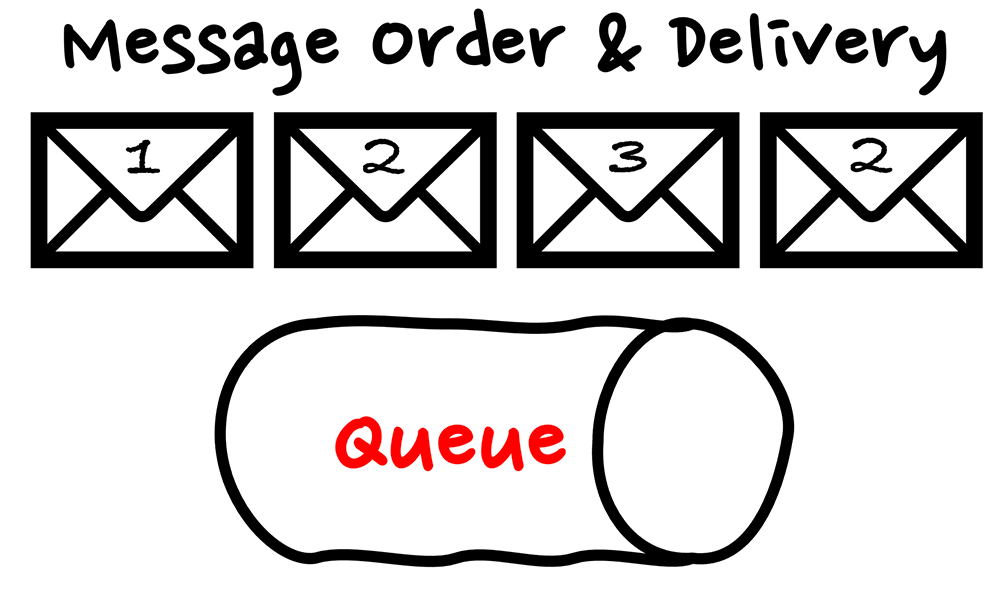
配信セマンティクス
配信セマンティクスは重複の管理を示す属性です。「At-Least-Once Delivery」と「Exactly-Once Delivery」 の 2 つの概念を紹介します。
At-Least-Once Delivery (少なくとも 1 回) は、「メッセージは欠損しないが重複しうる」という意味で、場合によっては 1 回以上のメッセージのコピーが配信されることがあります。SQS 標準キューや SNS 標準トピックのはこの属性を持ちます。この場合後続処理のべき等性について考慮し、同じ処理を複数回処理することによる論理的不整合が発生しないか検討すべきでしょう。
一方 Exactly-Once Delivery は (正確に 1 回)、「メッセージは欠損しないし重複もしない」という意味で、メッセージ配信における重複排除を提供します。FIFO キュー、FIFO トピックやストリーミングを扱うメッセージストレージはこの属性を持ちます。この場合、スケーラビリティについて考慮し、十分なスループットが担保出来ているのか検討すべきでしょう。
順序セマンティクス
順序セマンティクスは順序の管理を示す属性です。「ベストエフォートな順序づけ」と「FIFO」の 2 つの概念を紹介します。
ベストエフォートな順序は、後続のワーカーにて処理される順番が担保されない代わりに、高いスループットを実現します。SQS 標準キューや SNS 標準トピックのはこの属性を持ちます。この場合処理の順序が担保されなくとも、データとしてはその後順序が必要になってくることも考慮し、各々のメッセージで後からソートできる情報を付与させるをこと検討すべきでしょう。
一方 FIFO 配信は順序性の担保を実現します。FIFO キュー、FIFO トピックやストリーミングを扱うメッセージストレージはこの属性を持ちます。FIFO 配信を採用する主なユースケースとしては、注文処理やチケット予約システム、金融取引などが挙げられるでしょう。この場合 FIFO 配信になることでどこかのメッセージで処理がストップしてしまうと、処理全体に影響が出てしまうので、データの破棄や退避や、FIFO である必要性の有無の検討などが必要になります。
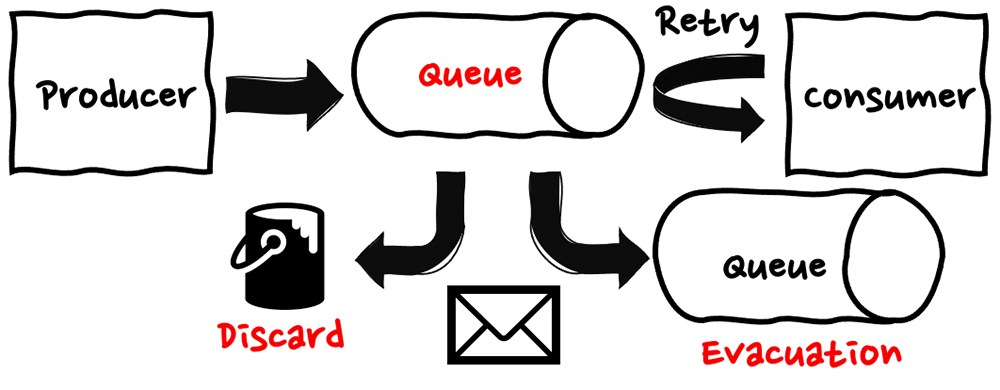
3. メッセージの破棄/退避 (Discard & Evacuation)
メッセージの受け渡しにおいて、リトライは一時的なエラーやランダムなエラーに対しては効果がありますが、同様のリクエストを行っていたところで、何度もエラーを繰り返すだけとなるような、再現性のあるエラーも存在します。こういったエラーに対してはメッセージの破棄、または退避を行います。
メッセージの破棄をするケースは、対象のデータが失われても、システム全体の論理的は整合性に影響がなく、むしろ不整合なメッセージを破棄すべきケースにおいて利用されます。具体的にはフロントエンドアプリケーションの UX モニタリングのアプリケーションなど数件記録できなかったり、数件重複しても大きな影響が出ないケースが挙げられます。メッセージの破棄を行うにあたっての検討ポイントは、再試行回数や再試行期限を定める点になります。
一方、メッセージの退避をするケースは、対象のデータが失われることで、システム全体の論理的は整合性が取れなくなるケースにおいて利用されます。具体的には課金データや注文データなどの 1 つ 1 つのイベントが重要だったり、集計情報が重要なアプリケーション等が挙げられます。メッセージの退避を行うにあたっての検討ポイントは、メッセージの破棄同様、再試行回数や再試行期限を定める点に加え、一定の条件下で繰り返し失敗したメッセージ用のキュー (= デッドレターキュー) や、 処理結果に応じた処理を行う割り振り先の用意などがあります。
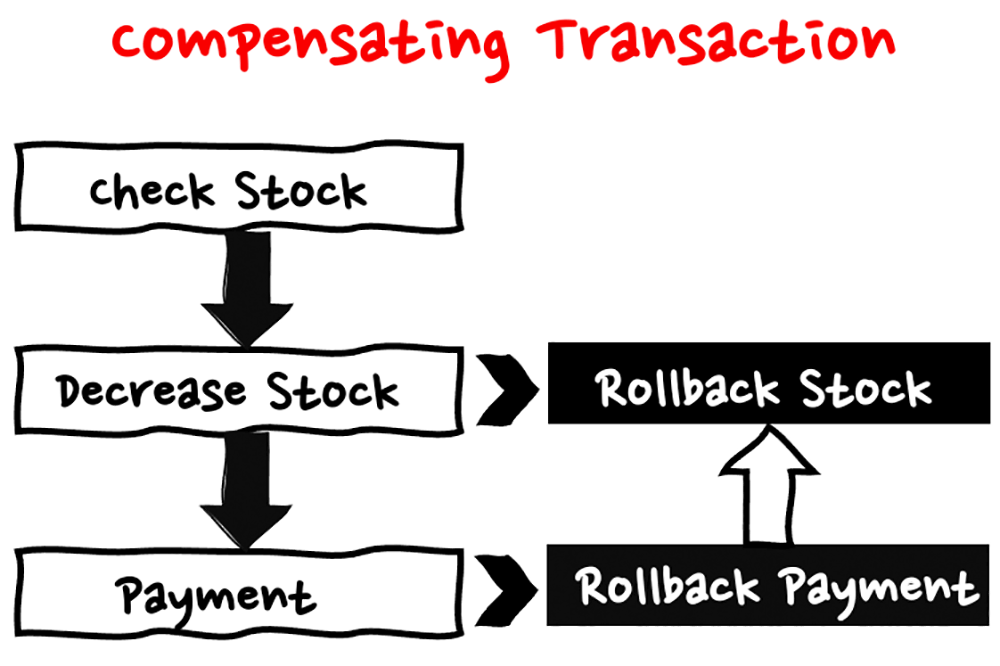
4. 補償トランザクション (Compensating Transaction)
マイクロサービスやワークフロー系のシステムにおいて受け渡したメッセージが正常でなかった場合、フローの途中でエラーが発生すると、複数のデータストアが全て正常に更新を完了しているか、またはすべてのデータストアが更新前の状態にロールバックされているかのどちらかの状態にする必要があります。従来のモノリシックなアプリケーションであれば、RDB のロールバックを利用することで、このような問題の発生を防ぐことが出来ますが、マイクロサービスにおいては、サービスごとに固有のデータベースを持つため、複数のデータベースにまたがってビジネス的な状態が更新前と整合する状態に戻すため専用の処理を行う必要があります。これが補償トランザクションと言われる処理になります。
例えば、注文のリクエストに対する、注文の受付処理、支払い処理、在庫の引き当て処理、注文確定のメッセージ送信処理などが個別のサービスとして連携して処理するようなアーキテクチャの場合、注文がキャンセルされた際に RDB の機能に依存したロールバックを行うことは出来ません。そのため、サービス間で連携する処理の途中でエラーが発生した場合、それまでにコミットした状態から、ビジネス的な状態が更新前と整合する状態に戻す必要があります。
こういった処理を実現するためには、複数のサービスにまたがってエラーの発生を補足し、エラーの内容や発生箇所に応じて整合性が担保されるような制御を行うための調整を行うロジックの用意をエラーハンドリングとして設ける必要があり、これが補償トランザクションで行うべき処理になります。
サーバーレス環境上でのエラーハンドリング
このようにエラーにも様々な発生パターンがあり、そのハンドリング手法も様々な種類があります。エラーハンドリングについて考えると、今までサーバーレスなアプリケーション開発の本質であるロジックの実装に集中できていたメリットがなくなってしまったかのように思われたかも知れませんが、安心してください。
サーバーレスサービスを利用すると、エラーハンドリングについても、ベストプラクティスとしてのエラーハンドリング機構はサービス側に備わっており、アプリケーション外で発生するエラーはそれらの機能によってハンドリングできます。
また、アプリケーション内で発生するエラーにおいても、AWS の様々なサーバーレスサービスを利用することでより高度なハンドリングを実現することができます。
シリーズでご紹介するユースケース
今回のシリーズでは、AWS のサーバーレスサービスを利用して、簡単にかつ高度なエラーハンドリングを実現するためのベストプラクティスをご紹介します。次回以降で全 4 回のシリーズとして、先程挙げたエラーハンドリングの手法について、具体的なユースケースごとに、実際の AWS のサーバーレスサービスを活用して実現する方法についてご紹介する記事をお届けします。
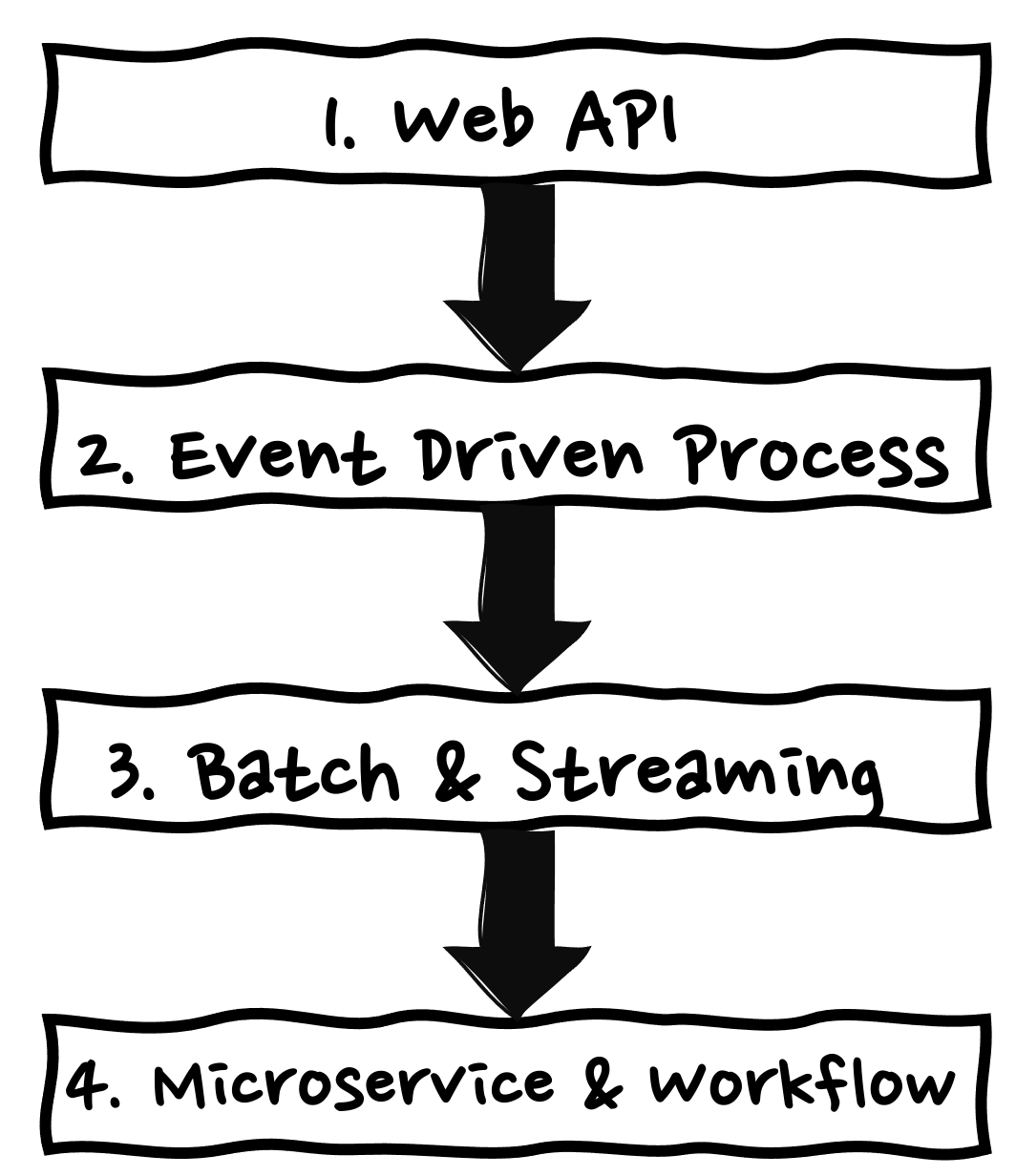
ご紹介するユースケースとしては、次のようになっております。
シリーズの流れとして、最初は最もよく使われている Web 3 層型の Web API におけるユースケースから学習します。
次にサーバーレスならではの特性を活かした、イベント駆動のデータ加工、連携処理としてのユースケースを取り扱います。
そして ETL の文脈で使われる、バッチ処理、ストリーミング処理 (リアルタイム処理) のユースケースを取り扱います。
最後に複数の処理から成り立つマイクロサービスや、ワークフロー型の処理のユースケースを取り扱います。
これらのユースケースを実現するアーキテクチャ例として、公式サイトの サーバーレスパターン や、AWS Black Belt Online Seminar の 形で考えるサーバーレス設計 サーバーレス ユースケースパターン解説 があります。こちらについても合わせてご覧いただけると理解が深まるかと思います。
まとめ
本記事においては、全体を通してエラーハンドリングとはなにか、またその重要性についてご説明したのちに、サーバーレスを利用することでエラーハンドリングについても、サービス側にオフロードできる旨ご説明しました。
サーバーレスによって、ユーザーによるエラーハンドリングの責任領域は小さくなっているものの、サービス側にオフロードできたエラーハンドリング機構がなにかを把握する必要あり、システム全体として行うべきエラーハンドリングが網羅できているのかは、ユーザー側で管理する必要があります。
シリーズとして後に続く記事では、サーバーレスのパターンごとにエラーハンドリングについてどういったポイントについて検討すべきか、ユーザ側でどこまでエラーハンドリングすべきかを、実際のユースケースに応じてご紹介していきます。
このシリーズを経て、ご自身のサーバーレスアプリケーションに照らし合わせて、網羅的なエラーハンドリングの理解にお役立て頂ければ幸いです。
筆者プロフィール
大磯 直人
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
インターネット・Web サービスを提供されるお客様に対して技術支援を行っています。好きな食べ物は 肉・寿司・ラーメン です。空き時間は永遠に Youtube 見てます。好きな AWS サービスは AWS StepFunctions です。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages