- AWS Builder Center
- builders.flash
Amazon Bedrock で手軽に絵芝居を作れるシステムを開発してみた
Author : 大前 遼
Introduction
こんにちは、ソリューションアーキテクトの大前です。子供の頃、漫画やアニメを好きでよく見ていた方は多いと思います。その中で、「漫画を好きなだけ読めれば良いのに」「物語の続きが読みたい」「もし主人公が違う行動をしたらどうなるのだろう」など思ったことはないでしょうか。そこで、本記事では生成 AI の力を使って、物語生成に挑戦しました。
生成 AI はテキストや画像を自動的に生成するような AI を指します。生成 AI は、基盤モデルと呼ばれる大規模なデータを学習した機械学習モデルを用いて実現されます。AWS では、生成 AI を使ったアプリケーション開発を支援するサービスとして、Amazon Bedrock を提供しています。Amazon Bedrock では Amazon および先進的な AI スタートアップの開発した基盤モデルを使うことができ、テキスト生成や画像生成、埋め込み表現生成といったタスクを行うことができます。
今回は物語作成のために、Anthropic 社が提供する Claude 2.1 というテキスト生成モデルを、挿絵生成のために、Stability AI 社が提供する Stable Diffusion XL 1.0 (SDXL 1.0) という画像生成モデルを使います。また、ナレーションは Amazon Polly という テキスト読み上げのための AWS サービスを使って作成します。これらの AI モデルを組み合わせて絵物語を作っていきたいと思います。
アップデート情報
2024/03/04 より、Claude モデルの最新版である Claude3 Sonnet が Amazon Bedrock 上で利用可能となりました。より精度の高い文章生成が可能となっていますので、ぜひ合わせてお使いいただければと思います。
完成品のイメージ
ご注意
本記事で紹介する AWS サービスを起動する際には、AWS アカウントのサインアップ が必要です。また、料金がかかるため、builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
1. 環境構築
今回は、Amazon Bedrock と Amazon SageMaker Notebook を活用してシステムを開発していきます。本記事の手順は全て us-east-1 (北部バージニア)リージョンにて実施します。他のリージョンで実施される場合、Amazon Bedrock における基盤モデルの対応状況 をご確認ください。
1-1. Amazon Bedrock の有効化
Amazon Bedrock 上で Claude 2.1 モデルと Stable Diffusion XL 1.0 モデルの有効化を行います。ドキュメントの「モデルアクセスを追加する」の手順 に従って、有効化設定を行います。すでに設定済みの方は、「1-3. SageMaker Notebook インスタンスの起動」まで読み飛ばしてください。
なお、課金について、モデルを有効化した段階では発生せず、API を利用したとき (つまり画像や文字を生成したとき) のみ費用が発生するためご安心ください。
-
AWS Management Console にログインし、Amazon Bedrock サービスを開き、「Getting Started」を押します。
-
左のナビゲーションペインから「Model access」を選択します。
-
モデル一覧の中から、Anthropic の右側にある 「Submit use caes details」をクリックし、表示されるアンケートフォームを記入してください。Company name については所属の会社の情報を入れていただき、社内検証用であれば、 Internal employees を選択し、ユースケースについては検証したい内容を記載ください。
-
アンケート提出後、しばらく待つとモデル一覧画面から Anthropic モデルを選択することができるようになります。使いたいモデル (今回の場合、少なくとも Anthropic, Stability を選択してください) を選択し、「Save Changes」をクリックしてください
以上で基盤モデルを有効化することができました。
1-2. Amazon Bedrock Playgrounds での動作確認
では、試しにモデルを呼び出します。Amazon Bedrock では Playgrounds 機能があり、モデルの実行、動作確認を行うことができます。
1. 左のナビゲーションペインから Playgrounds セクションを開き、「Text」をクリックします。
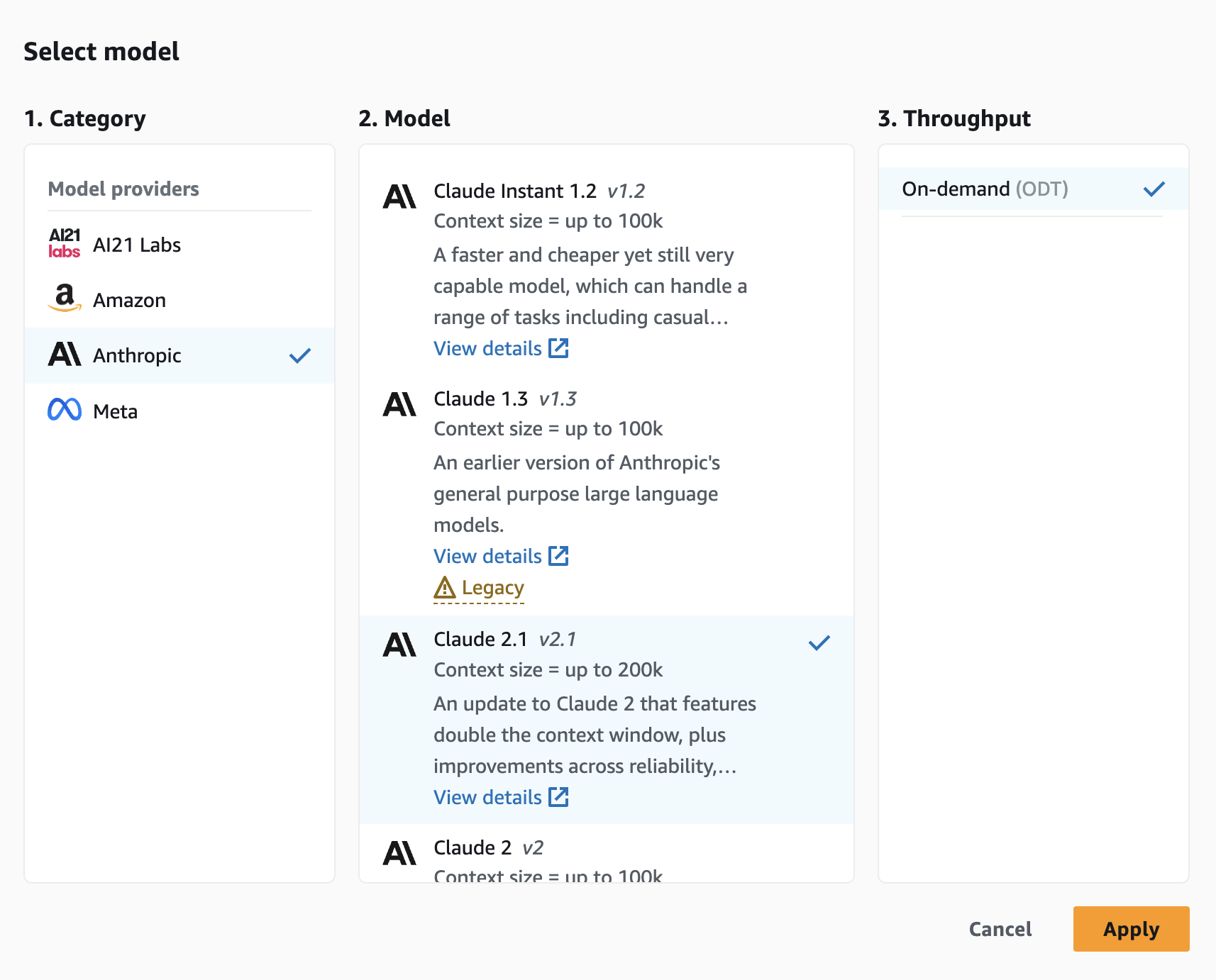
2.「Select model」をクリックし、
-
Categoryで「Anthropic」
-
Model で「Claude 2.1」
-
Throughputで「On-demand (ODT)」を選択して 「Save」をクリックします。
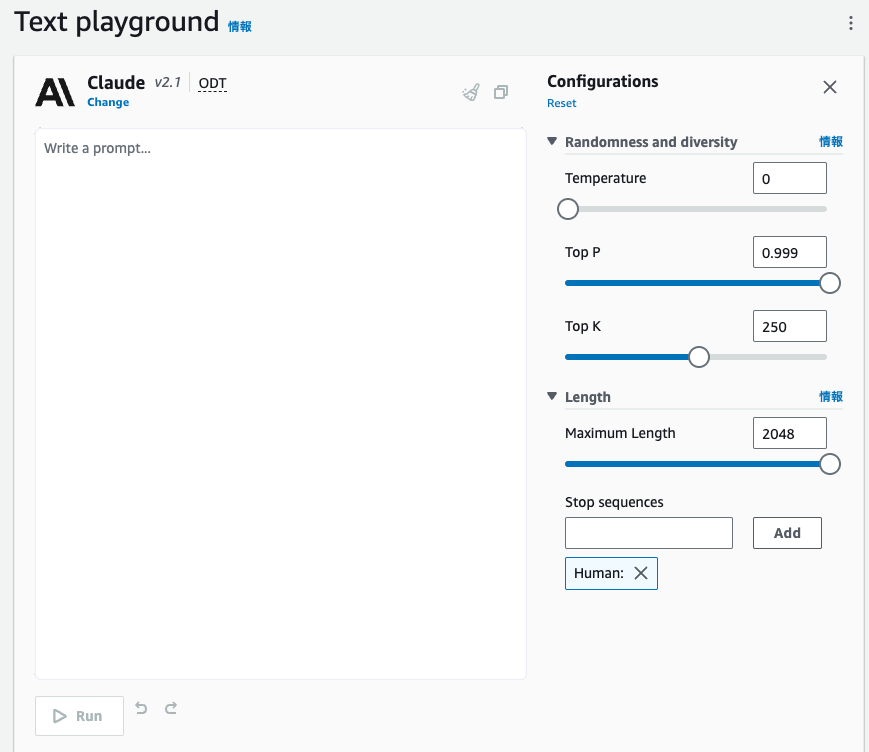
3. 左側がプロンプトの入力欄で右側が各種パラメータの調整欄となります。各パラメータの詳細については、Amazon Bedorck ドキュメント をご確認ください。
今回は生成結果を安定させるため、結果のランダムさを表す Temperature を 0 にします。また、生成文が長くなることが考えられるため、最大生成長を表す Maximum Length を 2048 へと設定します。
プロンプトの探索はこちらの Playground 上で行います。
1-3. SageMaker Notebook インスタンスの起動
基盤モデルでの出力をもとに絵芝居を作るための環境として、 JupyterLab を使います。SageMaker Notebook を使うと JupyterLab 環境を簡単に構築することができます。Notebook 上では、セル単位でPython プログラムを実行することができるため、試行錯誤しながら開発するのに適しています。今回は Amazon Bedrock の呼び出しや出力の加工などの処理を Notebook のセル上に実装します。
SageMaker Notebook インスタンスの起動方法

1. AWS Management Console から、SageMaker サービスを開きます。左のナビゲーションペインから「ノートブック」 → 「Notebookインスタンス」を選択します。
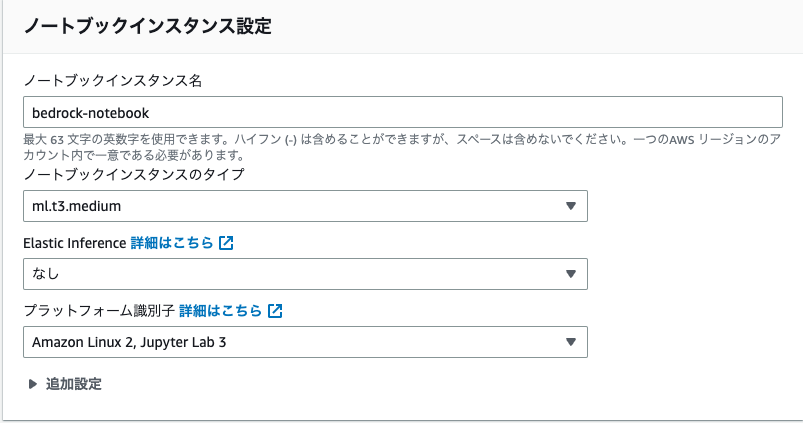
2. 画面右上「ノートブックインスタンスの作成」をクリックします。
以下のようにNotebookインスタンスの設定を行います。インスタンス名を除いてデフォルト値を用います。
-
ノートブックインスタンス名: お好きな名前を設定します。
-
インスタンスタイプ: 「ml.t3.medium」 を選択します
-
Elastic Inference: 「なし」
-
プラットフォーム識別子: 「Amazon Linux 2, Jupyter Lab 3」
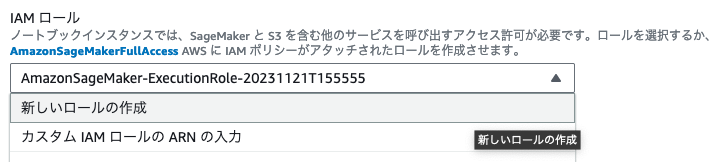
3. IAM ロールを設定します。下にスクロールし、「IAM ロール」→ 「新しいロールの作成」をクリックします。
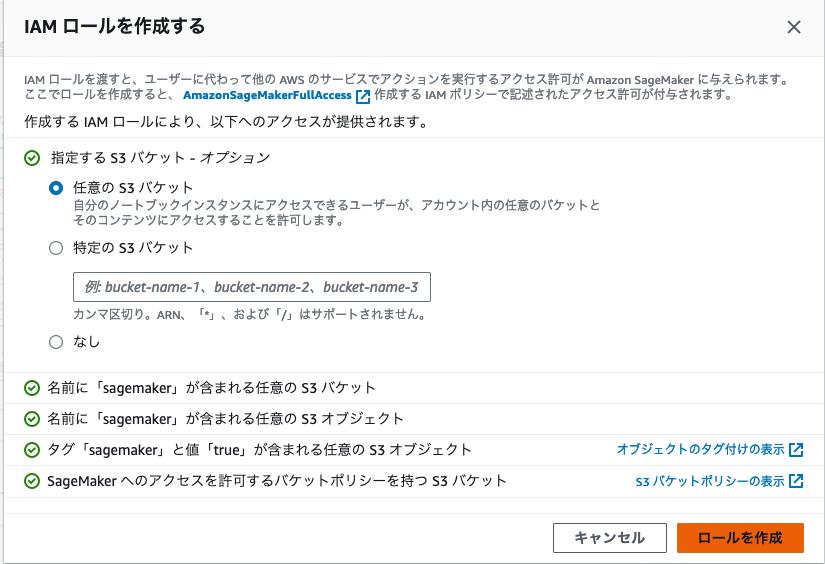
4. 今回は検証のため、「任意の S3 バケット」 を指定し、ロールを作成します。実運用される際は、特定の S3 バケットを指定するなど適切な権限を設定ください。

5. 「ノートブックインスタンスの作成」をクリックしてインスタンスを立ち上げます。
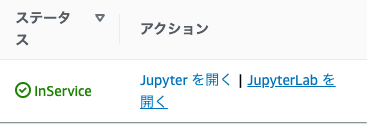
6. ステータスが「InService」になったら、「JupyterLab を開く」をクリックして JupyterLab にアクセスできます。
これで Notebook Instance が使えるようになりました。JupyterLab 上で機械学習モデル開発等を行えます。
2. プロンプトエンジニアリング
生成 AI モデルは、入力された文章を元に、次に登場する確率が最も高い文章を予測するように学習されています。入力文章での指示内容(プロンプト)を工夫することにより、意図した文章を生成する確率も高くなります。このように、意図した出力を得るために入力文章を工夫するテクニックは、一般にプロンプトエンジニアリングと呼ばれます。
Claude モデルにおける プロンプトエンジニアリング手法のガイドとして、Anthropic 社より Prompt Engineering Guide が提供されています。今回はガイドの内容を踏まえてプロンプトを構築します。ガイド内では、生成 AI で一般的な手法とモデル特有の手法の両方が解説されていることから、それぞれ分けて説明します。
2-1. 一般的な手法
生成 AI モデルは、指示が直接的で明快であるほど、より高い精度で回答することができます。例えば、同じ指示を入社初日のインターンに与えたとしても、完全に意図通りの結果が得られるかといった基準で考えると良いでしょう。
タスクを分割する
複雑なタスクは、分解して一つずつ解いていくことによって、最終的な出力の質を高めることができます。
Role Prompting
プロンプトの中で役割を設定することで、AI の振る舞い方を調整することができます。例えば、単に「パズルを解いてください」と指示するよりも、「あなたは論理学者で、複雑な論理を解くのが得意です。パズルを解いてください」と指示を出す方が、意図通りの結果を得られる確率が上がります。
Few-shot Learning
単に指示を出すだけでなく、いくつか回答の例を提示することで、意図通りの結果を得られる確率が上がります。
2-2. Claude 2.1 モデル特有の手法
Claude 3 モデルでは Completions API が廃止され、Messages API を用いた方式 に移行しております。そのため、Claude 3 を利用される際は、「Human: / Assistant: フォーマット」項目をお読み飛ばしください。
Human: / Assist: フォーマット
Cluade モデルは人間と AI アシスタントの会話を成立させるように学習されています。そのため、入力するプロンプトは Human: / Assistant: の構造である必要があり、それ以外の形式を入力した場合はエラーとなります。チャット形式の構造をとることで、Claude モデルはタスクの種類や生成を終えるタイミングを決定することができます。
System プロンプト
System プロンプトは Claude モデルに意図や指示を伝えるために使うことができるプロンプトです。バージョン 2.1 より実装された機能になります。これによって、会話のロールプレイにより集中させたり、ルールや指示に従った回答をする能力を高めたりすることができます。System プロンプトは、Human: タグの前に指示を記載することで使うことができます。
例えば、ファッションに関するアドバイスを行うエージェントを作る場合は以下のようなプロンプトを使うことができます。
例
You are a fashion industry expert. Your task is to help users by answering questions related to the fashion industry or by excuting tasks requested of you. If the task is unrelated to the fashion industry, then say "I cannot help with anything not related to fashion."
Human: Provide three potential names for a handbag startup targeting luxury consumers and explain your choices.
Assistant:XML タグによる強調
Claude モデルは <tag></tag> のような XML タグで囲まれた部分の記述を重視するようにチューニングされています。そのため、ルール、例、処理する入力テキストなど、重視してほしい部分をタグの中に記述することで、出力の精度を高めることができます。
出力を json 形式に強制する
Assistant: 以降に、文字列を指定することで、出力される最初の文字列を強制することができます。
この特性を利用し、Assistant: { のように中かっこ開きを指定しておくことで、以降の出力で json 形式の出力を取る確率を高めることができます。
2-3. プロンプトチェーンのための仕組み
以上のようにしてプロンプトを作成することができますが、システムとして基盤モデルを活用する上では、複数のプロンプトを連携して動かすことが重要です。プロンプトの入力と出力を接続して活用することは Prompt chaining と呼ばれます。Prompt chaining を実現するためには AWS Step Functions や Agents for Amazon Bedrock といった AWS サービスや LangChain などのライブラリが利用できますが、今回は仕組みの理解を深めるためになるべく標準機能のみを用いて実装します。
入力を生成する
Prompt を生成する仕組みとして、Python 文字列の format 関数を用います。以下に示すように、文字列内に、{name} のようにキーワード引数を設定することで、テキストを動的に変更できます。{} がフォーマット先として参照されてしまうため、プロンプトでテキストとして中かっこ {} を使う際は {{}} のように2重で記述します。
prompt_template = \
'''
あなたの名前は{name}です。自己紹介をしてください。
'''
prompt = prompt_template.format(name='山田太郎')
print(prompt)
> あなたの名前は山田太郎です。自己紹介をしてください。出力をプログラム内で扱えるように変換する
プロンプトエンジニアリングの項で述べたように、プロンプトの末尾を Assistant: { とすることで、出力を json 形式に強制し、json をパースすることで後段の処理に活用できるようにします。
処理は以下のようになります。
import json
prompt = '''
...
Assistant: {
'''
# invoke_resultは次のような出力になります
# "example_key": "example_value"}
invoke_result = invoke_claude(prompt)
# 文頭に{を付与することで、json文字列として辞書型にパースできます
result = json.loads('{'+invoke_result)
print(result['example_key'])
> example_value3. プロンプトの探索
「絵芝居を作成する」というタスクは、そのままでは複雑すぎるため単一のプロンプトで達成することは困難です。そこで、タスクを「あらすじの生成」「物語文の生成」「挿絵の生成」の 3 段階に分割し、それぞれのタスクに合わせたプロンプトを構築していきたいと思います。
プロンプトを構築するにあたっては、最適なプロンプトを試行錯誤して探索していくことが重要です。探索には Amazon Bedrock Playgrounds が利用可能です。
3-1. 与えられたテーマから物語のあらすじを生成する
まずは、物語の展開の大まかなあらすじを生成させます。
具体的な指示として、物語には起承転結を含める必要がある点や、各起承転結でどういった要素を含むべきかを記述していきます。また、ある程度あらすじの分量を確保するため、シーンの数を指定します。
また、出力結果をプログラム的に活用する上で、「はい、出力します」などの枕詞が出力されることを防ぐ必要があります。そこで、json 形式で出力するようにシステムプロンプト内で指定し、「Assistant: {」のように、生成がjsonのキーから始まるように指定することで、所望の出力結果のみを取り出せるようにします。
さらに、より出力の精度を高めるために、Few-shot Learning を用います。example タグの中で、出力結果を例示することで、より意図通りの結果が出力される確率を高めます。
以上のような考え方のもとで、Playground 上で試行錯誤を繰り返した結果、下記のようなプロンプトを採用することにしました。
あらすじ生成用システムプロンプト
あなたはセンスに溢れた気鋭に溢れる情熱的な作家です。Humanがテーマを与えるので、膨らませて、物語のあらすじを考えてください。
あらすじは物語を起承転結のシーンごとに分け、情景や描写を詳しく書くようにしてください。
起の部分では、登場人物の人となりを説明し、読者が主人公たちに親近感を抱くような情景を描写してください。
承の部分では、主人公は誤ちを犯しますが、途中でそのことに気づき、新たな視点で物事に取り組むようになります。
転の部分では、承で培った経験をもとに、困難を乗り越えます。
結の部分では、主人公がテーマを達成した様子を描写します。
以上のような形であらすじを考案してください。シーンは最低でも8個以上生成してください。
また、出来上がったあらすじはjson形式でexampleタグに示すような形式で、plot要素の中で各シーンをリスト形式で出力してください。また、json以外の文字列は出力しないでください。
<example>
{{
'plot': [
'森の中でクマさんにであう',
'クマさんが追いかけてくる',
'実はクマさんは落とし物を拾っていた',
'笑顔で一緒に踊る'
]
}}
</example>3-2. あらすじをもとに物語の各場面を生成する
次に、あらすじをもとにして、場面をより明瞭に描写していきたいと思います。
あらすじを生成した際と同様、指示を具体的に示し、出力形式もプロンプトで示します。また、Few-shot Learning のために物語の文章を例示します。今回は物語の例として、青空文庫より赤ずきん (Grimm作 矢崎源九郎訳) の一部を引用しました。
場面生成用プロンプト
あなたはセンスに溢れた気鋭に溢れる情熱的な作家です。子ども向けに読み聞かせできるような物語を描いてください。
Humanが物語のテーマを<Theme>タグの中で、物語の流れを端的に示したあらすじを<Plot>タグの中で与えます。全体あらすじの情報を踏まえつつ、<Scene>タグで示すシーンのあらすじをもとに、情景や背景、登場人物の心情やセリフを記述することで、読み手に伝わりやすいような臨場感のある文章を考えてください。ただし、物語の文章のみを出力し、その他の文字列は出力しないでください。また、指定されたシーンの部分のみ描画してください。文章はですます調で出力してください。
また、出来上がった文章はjson形式で、Scene要素の中にダブルクォーテーションで囲んで出力してください。
<Example>タグに生成したい文章の例を示します。
<Example>
{{
"Scene": "むかしむかし、あるところにちっちゃな、かわいい女の子がおりました。その子は、ちょっと見ただけで、どんな人でもかわいくなってしまうような子でしたが、だれよりもいちばんかわいがっていたのは、この子のおばあさんでした。おばあさんは、この子の顔を見ると、なんでもやりたくなってしまって、いったいなにをやったらいいのか、わからなくなってしまうほどでした。
あるとき、おばあさんはこの子に、赤いビロードでかわいいずきんをこしらえてやりました。すると、それがまたこの子にとってもよくにあいましたので、それからは、もうほかのものはちっともかぶらなくなってしまいました。それで、この子は、みんなに「赤ずきんちゃん」「赤ずきんちゃん」とよばれるようになりました。"
}}
</Example>
<Example>
{{
"Scene": "そこで、寝床のところへいって、カーテンをあけてみました。すると、そこにはおばあさんが横になっていましたが、ずきんをすっぽりと顔までかぶっていて、いつもとちがった、へんなかっこうをしています。
「ああら、おばあさん、おばあさんのお耳は大きいのねえ。」
「おまえのいうことが、よくきこえるようにさ。」
「ああら、おばあさん、おばあさんのお目めは大きいのねえ。」
「おまえがよく見えるようにさ。」
「ああら、おばあさん、おばあさんのお手ては大きいのねえ。」
「おまえがよくつかめるようにさ。」
「でも、おばあさん、おばあさんのお口はこわいほど大きいのねえ。」
「おまえがよく食べられるようにさ。」
オオカミはこういいおわるかおわらないうちに、いきなり寝床からとびだして、かわいそうな赤ずきんちゃんを、ぱっくりとひとのみにしてしまいました。"
}}
</Example>
Human: 3-3. イラストを生成させるプロンプト
Claude 2.1 で情景を表すようなプロンプトを生成し、SDXL で実際のイラストを生成させていきます。
Stability AI 社の Prompt Engineering Guide によると以下の点が重要であると述べられています。
- プロンプトの中心となる主題を明確にする (例えばパンダ、戦士、スケルトン)
- 写真のようにリアル、油絵、鉛筆画など、イメージのスタイルを指定する。
- 「高解像度」「ドラマティックな照明」などのフィニッシング・タッチを加えることでイメージを洗練させられる。
- ネガティブプロンプトを用いると望ましくない要素を排除できる。
また、Amazon Bedrock には 乱用検知機能 があり、コンプライアンス上望ましくない画像を生成しようとした場合、エラーとなります。意図せずエラーが出力されることを防ぐため、コンプライアンスを守ったプロンプトを出すようにも指示を出します。
以上の点を踏まえて、Claude 向けには以下のようなプロンプトを使います。
絵本の挿絵を作りたいです。そのために画像生成モデル向けのプロンプトを考える必要があります。
挿絵として、色鉛筆を使った絵を採用したいと思います。
Humanが物語全体のあらすじを<Plot>タグで、該当のシーンを<Scene>タグで明示します。与えられたシーンでの情景を表すような文章を簡潔に英語で1文程度で生成してください。プロンプトを作る上で、以下の点に注意してください。
* 写っている物体や人物を明確に指示する。
* 各物体がどのような形なのか明確に提示する。
* 人物はどのような服を着ていて何をしようとしているのか提示する。
* 以下の中から、関連しそうな Finishing Touch をピックアップして追加する。Highly-detailed, surrealism, trending on artstation, triadic color scheme, smooth, sharp focus, matte, elegant, illustration, digital paint, dark, gloomy, octane render, 8k, 4k, washed-out colors, sharp, dramatic lighting, beautiful, post-processing, picture of the day, ambient lighting, epic composition
* コンプライアンスに注意する
また、出力するプロンプトはjson形式で、prompt要素内に書き出すようにしてください。
Exampleタグで適切な出力の例を示します。
<Example>
{{
"prompt": "a panda by Leonardo da Vinci and Frederic Edwin Church, highly-detailed, dramatic lighting"
}}
</Example>
<Example>
{{
"prompt": "A professional color photograph of a bearded man on the sidewalk"
}}
</Example>
Human:
<Plot>
{plot}
</Plot>
<Scene>
{scene}
</Scene>
Assistant: {{4. 生成 AI システムの構築
ここまでで、プロンプトを作ることができました。では実際に一連の流れを JupyterLab 上に実装します。
JupyterLab 環境にアクセス

1. まずは、環境構築の際に立ち上げた JupyterLab 環境にアクセスします。
2. Notebook リストの中から、「Conda_python3」環境を選択し、新規のノートブックを開きます。
プログラムを記述

3. ノートブック上にプログラムを記述していきます。
4-1. ライブラリのインストール
動画を生成するためのライブラリとして、Moviepy をインストールします。
以下のセルを作り、実行します。
Moviepy をインストール
コマンド
!pip install ffmpeg moviepy4-2. Amazon Bedrock を呼び出す処理の実装
Claude 2.1 モデルや SDXL モデルを何度も呼び出すので、関数として実装します。 Notebook 上で次のようなセルを作り実行します。
import json
import io
import base64
import boto3
from PIL import Image
bedrock_runtime = boto3.client(service_name='bedrock-runtime')
# Claude 2.1 モデルを呼び出す関数
def invoke_claude(prompt: str, max_tokens_to_sample:int=3000) -> str:
# モデルに渡すパラメータを設定する
body = json.dumps({
"prompt": prompt,
"max_tokens_to_sample": max_tokens_to_sample,
"temperature": 0,
"top_k": 250,
"top_p": 1,
})
modelId = 'anthropic.claude-v2:1'
accept = 'application/json'
contentType = 'application/json'
# Bedrock で Claude v2.1 モデルを呼び出す
response = bedrock_runtime.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
# Bedrock で生成されたテキストを返す
response_body = json.loads(response.get('body').read())
text = response_body.get('completion')
return text
# StableDiffusion を呼び出す関数
def invoke_sdxl(prompt: str, seed:int=0) -> Image:
# モデルに渡すパラメータを設定する
body = json.dumps({
"text_prompts": [{"text": prompt}],
"cfg_scale": 10,
"seed": seed,
"steps": 50
})
modelId = "stability.stable-diffusion-xl-v1"
accept = "application/json"
contentType = "application/json"
# Bedrock で Stable Diffusion モデルを呼び出す
response = bedrock_runtime.invoke_model(body=body, modelId=modelId, accept=accept, contentType=contentType)
# Bedrock で生成された画像を PIL.Image 形式で返す
response_body = json.loads(response.get("body").read())
base_64_img_str = response_body.get("artifacts")[0].get("base64")
image = Image.open(io.BytesIO(base64.decodebytes(bytes(base_64_img_str, "utf-8"))))
return image4-3. 物語のあらすじを作成する処理の実装
以下のようにして、物語のあらすじを作成する処理をセル上に実装し、実行します。
プロンプトを定義する箇所
実行コード
prompt_make_plot = '''
あなたはセンスに溢れた気鋭に溢れる情熱的な作家です。Humanがテーマを与えるので、膨らませて、物語のあらすじを考えてください。
あらすじは物語を起承転結のシーンごとに分け、情景や描写を詳しく書くようにしてください。
起の部分では、登場人物の人となりを説明し、読者が主人公たちに親近感を抱くような情景を描写してください。
承の部分では、主人公は誤ちを犯しますが、途中でそのことに気づき、新たな視点で物事に取り組むようになります。
転の部分では、承で培った経験をもとに、困難を乗り越えます。
結の部分では、主人公がテーマを達成した様子を描写します。
以上のような形であらすじを考案してください。シーンは最低でも8個以上生成してください。
また、出来上がったあらすじはjson形式でexampleタグに示すような形式で、plot要素の中で各シーンをリスト形式で出力してください。また、json以外の文字列は出力しないでください。
<example>
{{
'plot': [
'森の中でクマさんにであう',
'クマさんが追いかけてくる',
'実はクマさんは落とし物を拾っていた',
'笑顔で一緒に踊る'
]
}}
</example>
Human: {instruction}
Assistant: {{
'''
instruction = '昔話の桃太郎を題材に、鬼と人間が種族を超えて手を取り合うことの大切さを描写してください。'プロンプトを実行するセル
コード
invoke_result = invoke_claude(prompt_make_plot.format(instruction=instruction))
plot = json.loads('{' + invoke_result)
# 動作確認用に出力する
print(plot)
> {'plot': ['桃太郎は鬼ヶ島に向かう途中、仲間たちと出会う', '鬼ヶ島に着くと大きな鬼が現れる', '桃太郎は鬼と戦おうとするが、鬼は人間を攻撃しようとしない', '桃太郎は鬼が人間を食べない理由を尋ねる', '鬼は以前人間と戦争をしていたが、戦争の惨さを知り、人間と仲良くしたいと思うようになったと言う', '桃太郎は鬼の気持ちを理解し、手を取って踊り始める', '鬼と人間は笑顔で踊り、種族の壁を超えて仲良くなる', '桃太郎は鬼ヶ島からの帰り道、人間と鬼が仲良く暮らせる方法を考え始める']}4-4. 物語の各場面を記述する処理の実装
あらすじをもとに、各場面ごとの物語を生成していきます。前後の表現の一貫性を保つために、チャットのように、前の出力結果を再度入力として使いつつ次の出力を生成させていきます。入力プロンプトはこの図のように、前段の出力が積み重なるような形になります。
実装として、最初のシステムプロンプトと、毎回の更新部分のプロンプトを別で定義し、ループの中で更新部分を追加していくという形で行います。
動作イメージ
物語を作成してくださいHuman: 桃太郎は鬼ヶ島に向かう途中、仲間たちと出会うAssistant: ある日のこと、桃太郎は鬼ヶ島に向かう旅に出かけました...Human: 鬼ヶ島に着くと大きな鬼が現れるAssistant: 物語を生成
物語を記述させる処理は以下のようになります。セルにコピーペーストし、実行します。
# システムプロンプトの定義
prompt_make_story = '''
あなたはセンスに溢れた気鋭に溢れる情熱的な作家です。子ども向けに読み聞かせできるような物語を描いてください。
Humanが物語のテーマを<Theme></Theme>タグの中で、物語の流れを端的に示したあらすじを<Plot></Plot>タグの中で与えます。全体あらすじの情報を踏まえつつ、<Scene></Scene>タグで示すシーンのあらすじをもとに、情景や背景、登場人物の心情やセリフを記述することで、読み手に伝わりやすいような臨場感のある文章を考えてください。ただし、物語の文章のみを出力し、その他の文字列は出力しないでください。また、指定されたシーンの部分のみ描画してください。文章はですます調で出力してください。
また、出来上がった文章はjson形式で、Scene要素の中にダブルクォーテーションで囲んで出力してください。
<Example>タグに生成したい文章の例を示します。
<Example>
{{
"Scene": "むかしむかし、あるところにちっちゃな、かわいい女の子がおりました。その子は、ちょっと見ただけで、どんな人でもかわいくなってしまうような子でしたが、だれよりもいちばんかわいがっていたのは、この子のおばあさんでした。おばあさんは、この子の顔を見ると、なんでもやりたくなってしまって、いったいなにをやったらいいのか、わからなくなってしまうほどでした。
あるとき、おばあさんはこの子に、赤いビロードでかわいいずきんをこしらえてやりました。すると、それがまたこの子にとってもよくにあいましたので、それからは、もうほかのものはちっともかぶらなくなってしまいました。それで、この子は、みんなに「赤ずきんちゃん」「赤ずきんちゃん」とよばれるようになりました。"
}}
</Example>
<Example>
{{
"Scene": "そこで、寝床のところへいって、カーテンをあけてみました。すると、そこにはおばあさんが横になっていましたが、ずきんをすっぽりと顔までかぶっていて、いつもとちがった、へんなかっこうをしています。
「ああら、おばあさん、おばあさんのお耳は大きいのねえ。」
「おまえのいうことが、よくきこえるようにさ。」
「ああら、おばあさん、おばあさんのお目めは大きいのねえ。」
「おまえがよく見えるようにさ。」
「ああら、おばあさん、おばあさんのお手ては大きいのねえ。」
「おまえがよくつかめるようにさ。」
「でも、おばあさん、おばあさんのお口はこわいほど大きいのねえ。」
「おまえがよく食べられるようにさ。」
オオカミはこういいおわるかおわらないうちに、いきなり寝床からとびだして、かわいそうな赤ずきんちゃんを、ぱっくりとひとのみにしてしまいました。"
}}
</Example>
Human:
<Theme>
{instruction}
</Theme>
<Plot>
{plot}
</Plot>
<Scene>
{scene}
</Scene>
Assistant: {{
'''
# 更新部分のプロンプト定義
prompt_update = '''
{prev_output}
Human:
<Scene>
{scene}
</Scene>
Assistant: {{
'''
# 各あらすじごとにプロンプトを更新して場面を生成させる
scenes = []
prompt_next = ''
invoke_result = ''
for scene in plot['plot']:
# 1つ目のあらすじの際はシステムプロンプトのみを入力する
if prompt_next == '':
prompt_next = prompt_make_story.format(instruction=instruction, plot=str(plot), scene=scene)
# 2つ目以降は前回の出力を使ってプロンプトを更新する
else:
prompt_next += prompt_update.format(prev_output=invoke_result, scene=scene)
# Claude モデルを呼び出す
invoke_result = invoke_claude(prompt_next)
# 呼び出し結果をscenesリストに保存
result = json.loads('{' + invoke_result.replace('\n', ''))
scenes.append(result['Scene'])
print(scenes)実行中エラーが出た場合
実行中、乱用検知機能などでエラーが出る場合があります。その場合は再度実行してください。
4-5. イラストを生成する処理の実装
各シーンごとに SDXL モデルを使って挿絵を生成します。雰囲気を統一するため、スタイルを色鉛筆画風として指定します。そのために、‘a color pencil painting' という記述をプロンプトの前に挿入するようにします。また、後ほど生成した画像を使いたいため、連番画像で保存します。
イラストの生成
処理としては以下のようになります。新しいセルを作成し、実行します。
# StableDiffusion に指示を出すためのプロンプト
prompt_draw_image = '''
絵本の挿絵を作りたいです。そのために画像生成モデル向けのプロンプトを考える必要があります。
挿絵として、色鉛筆を使った絵を採用したいと思います。
Humanが物語全体のあらすじを<Plot>タグで、該当のシーンを<Scene>タグで明示します。与えられたシーンでの情景を表すような文章を簡潔に英語で1文程度で生成してください。プロンプトを作る上で、以下の点に注意してください。
* 写っている物体や人物を明確に指示する。
* 各物体がどのような形なのか明確に提示する。
* 人物はどのような服を着ていて何をしようとしているのか提示する。
* 以下の中から、関連しそうな Finishing Touch をピックアップして追加する。Highly-detailed, surrealism, trending on artstation, triadic color scheme, smooth, sharp focus, matte, elegant, illustration, digital paint, dark, gloomy, octane render, 8k, 4k, washed-out colors, sharp, dramatic lighting, beautiful, post-processing, picture of the day, ambient lighting, epic composition
* コンプライアンスに注意する
また、出力するプロンプトはjson形式で、prompt要素内に書き出すようにしてください。
Exampleタグで適切な出力の例を示します。
<Example>
{{
"prompt": "a panda by Leonardo da Vinci and Frederic Edwin Church, highly-detailed, dramatic lighting"
}}
</Example>
<Example>
{{
"prompt": "A professional color photograph of a bearded man on the sidewalk"
}}
</Example>
Human:
<Plot>
{plot}
</Plot>
<Scene>
{scene}
</Scene>
Assistant: {{
'''
# イラストのスタイルを指定するプロンプト
style_image = 'a color pencil painting'
for index, scene in enumerate(scenes):
prompt = prompt_draw_image.format(plot=str(plot), scene=scene)
# StableDiffusion 向けのプロンプトを生成する
claude_result = invoke_claude(prompt)
# 鉛筆画を生成するため、プロンプトを追加した上で SDXL を呼び出す
prompt_for_sdxl = json.loads('{' + claude_result.replace('\n', ''))['prompt']
image = invoke_sdxl(f'{style_image}, {prompt_for_sdxl}')
# 生成した画像を表示し、保存する。
image.show()
print(scene)
image.save(f'{index}.png')4-6. ナレーションを生成して動画として保存する
最後に、作った物語と挿絵を組み合わせて、読み聞かせ動画を作成します。
テキストから音声を生成するためには、Amazon Polly という AI サービスを使います。Polly ではテキストを API で受け渡し、AI で読み上げ、音声ファイルを生成することができます。
動画の作成には、Moviepy という Python ライブラリを使います。各シーンごとに音声を作成し、Moviepy を使って画像と組み合わせて、読み聞かせ動画を作成します。
ナレーションを生成
まずはナレーションを生成します。以下のコードをコピーして実行してください。
# polly の boto3クライアントを作成します
polly_client = boto3.client('polly')
# 連番で音声ナレーションを生成します
for index, scene in enumerate(scenes):
result = polly_client.synthesize_speech(
Engine="neural",
VoiceId='Kazuha',
OutputFormat='mp3',
Text = scene)
with open(f'{index}.mp3', 'wb') as f:
f.write(result['AudioStream'].read())動画を生成
次に、動画を生成します。各シーンごとのイラストとナレーションファイルを統合します。以下のコードをセルにコピーして実行してください。
from moviepy.editor import *
video_clips = []
for index in range(len(scenes)):
image = ImageClip(f'{index}.png')
audio = AudioFileClip(f'{index}.mp3')
video = image.set_duration(audio.duration+1)
video = video.set_audio(audio)
video_clips.append(video)
final_video = concatenate_videoclips(video_clips)
# output.mp4 へ出力する
final_video.write_videofile("output.mp4", fps=24)ファイルをダウンロード
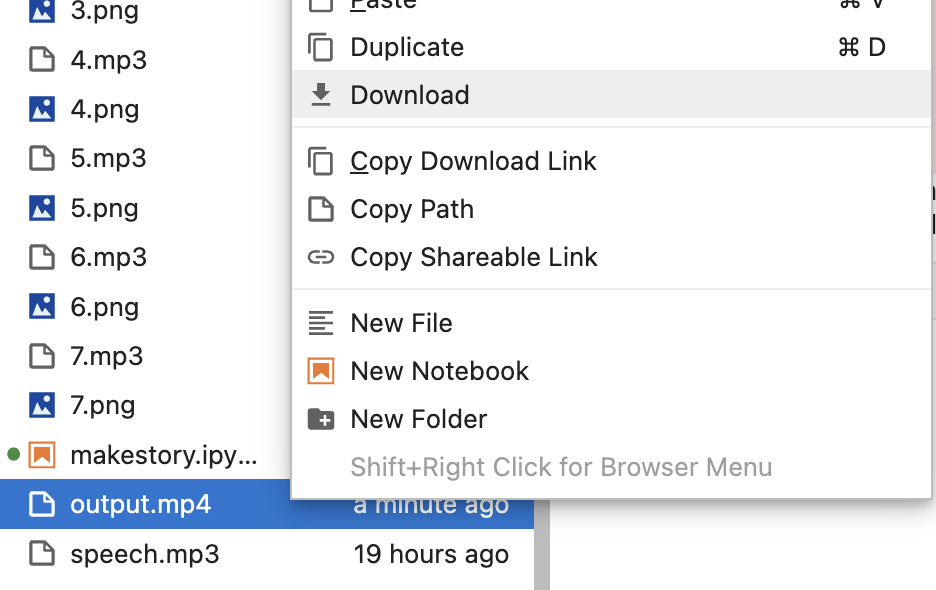
上記のセルを実行すると output.mp4 ファイルに生成結果が出力されます。再生のためにはファイルをダウンロードする必要があります。
左側のファイル一覧ペーンから「output.mp4」を右クリックし、「Download」を選択します。
VLC Media Player などの mp4 ファイルを再生できるプレイヤーを使い、動画を再生します。
※プレイヤーによっては音声が再生されない場合があります。その際は、他のプレイヤーでの再生をお試しください。
このようにしてナレーション付きの絵芝居を作ることができました。
5. 環境の削除
意図しない課金を防ぐため、Notebook インスタンス を削除します。
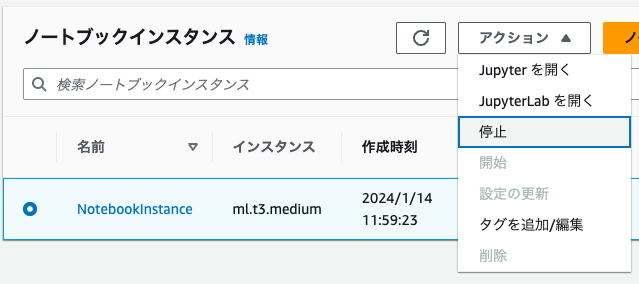
1. 作成したインスタンスを選択し、「アクション」から「停止」を選択します。
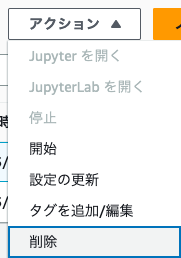
2. インスタンスが停止した後、インスタンス名を再度選択し、「アクション」から「削除」を選択します。これによってノートブックインスタンスを削除することができます。
6. まとめ
本記事では、Amazon Bedrock の各種モデルと Amazon Polly を組み合わせて、絵芝居を自動生成させるような生成 AI アプリケーションを構築する方法をご紹介しました。生成される画像はやや荒削りな部分もございますが、プロンプトを工夫したり画像生成モデルをファインチューニングしたりすることで、より良い結果を出力するように工夫することもできます (ファインチューニングで猫の画像を生成するモデルを構築するサンプル)。 ぜひさまざまな方式をお試しください。また、冒頭でご紹介した Claude 3 など、異なる文章生成モデルを使うことで、より良い文章が生成できる可能性もございます。ぜひお試しください。
このように、各種 AWS サービスを組み合わせることにより、本格的な生成 AI アプリケーションを簡単に構築することができます。今回は Prompt chaining のために Jupyter Notebook を使いましたが、実運用の際には、AWS Lambda や Amazon Step Functions、Agent for Amazon Bedrock といったサービスを活用いただくのが便利です。構成の支援をいたしますので、アイデアを思いついた方は、ぜひ AWS のソリューションアーキテクトにご相談ください。
筆者プロフィール
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト
主に製造業のお客様に対して技術支援を行なっています。趣味はバイクで、好きな AWS サービスはAmazon SageMaker, Amazon Bedrock です。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages