- AWS Builder Center
- builders.flash
AWS Amplify Gen 2 と AWS CDK で爆速アプリ開発 & 拡張 ! 第 2 回 AWS Amplify AI Kit で簡単 ! RAG アプリケーション開発
2025-03-03 | Author : 菊地 晏南
はじめに
こんにちは ! ソリューションアーキテクトの菊地です。
前回の記事「第 1 回 AWS Amplify Gen 2 から始める AWS CDK 入門」では、AWS Amplify Gen 2 のバックエンド開発で役立つ AWS Cloud Development Kit (AWS CDK) の基礎知識をご紹介しました。今回は第二弾として、AWS Amplify Gen 2 で生成 AI アプリケーションを構築する際に便利な Amplify AI Kit をご紹介します。
近年生成 AI に注目が集まっており、社内ツールとして RAG (Retrieval Augmented Generation) を構築したいという方も多いのではないでしょうか。本ブログでは AWS Amplify Gen 2 と AWS CDK を使って、Amplify AI Samples というチャットアプリケーションに RAG 機能を追加していきます。Amplify AI Kit でサクッと RAG アプリを構築してみましょう !
本連載では今後も AWS Amplify と AWS CDK を活用した情報をお届けする予定です。乞うご期待 !
builders.flash メールメンバー登録
はじめに
CDK 好きの菊地「稲田さん、最近 RAG アプリケーションの話をよく聞くんですが、サクッと作れる方法はないでしょうか?社内で使うものを作りたいんです。」
Amplify 好きの稲田「そういえば、Amplify に Amplify AI Kit というツールキットがあるんです。生成 AI アプリの開発に便利ですよ。」
菊地「Amplify AI Kit ? 初めて聞きました。」
稲田「Amplify AI Kit を使えば、RAG アプリの基本的な部分を簡単に構築できるんですよ。もちろん、CDK を使って他の AWS サービスと組み合わせたカスタマイズも可能です。」
菊地「それは素晴らしいですね ! ぜひ詳しく知りたいです。」
稲田「では、Amplify AI Kit の基本的な使い方から、カスタマイズのポイントまで、順を追って見ていきましょう。」
本ブログでは、Amplify AI Kit を使った RAG アプリケーションの開発方法をステップバイステップで解説していきます。生成 AI アプリケーション開発の効率化に興味がある方、ぜひ一緒に学んでいきましょう !
Amplify AI Kit
Amplify AI Kit は、AWS Amplify を使用して生成 AI 機能を簡単に実装することができるツールキットで、主に 2 種類のルートを提供しています。
-
Conversation : Conversation ルートは複数ターンの会話を実現する API です。会話とメッセージは自動的に Amazon DynamoDB に保存されます。チャットベースの AI 体験や会話型 UI に適しています。
-
Generation : Generation ルートはシンプルな同期リクエスト-レスポンス API です。AWS AppSync Query を使用して、ルート定義に従って構造化データを生成します。非構造化入力からの構造化データの生成や要約などに使用されます。
この Amplify AI Kit を使ったサンプルアプリケーションとして、Amplify AI Samples が提供されています。このアプリケーションでは、Amplify AI Kit の実際の使用例を見ることができます。Claude AI と Story Teller With Claude and Amazon Bedrock Knowledge Base の 2 つのサンプルが含まれていますが、今回はシンプルな Claude AI を例に見ていきましょう。
このアプリケーションでは、シンプルなチャットインターフェースで生成 AI とチャットすることができ、チャットの内容を簡潔にまとめたタイトルをつけて履歴を管理することできます。メインとなるチャット機能には Conversation ルート が使用され、チャット履歴のタイトル付けには Generation ルート が使用されています。
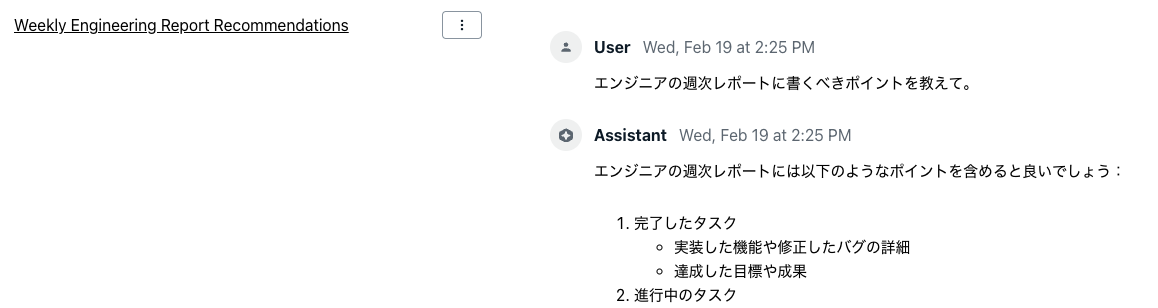
シンプルなチャット機能だけでも生成 AI を活用できますが、社内用途では社内のドキュメントに基づいた回答を生成させたい場合もあります。そこで便利なのが RAG 機能です。
RAG 機能を実装するために、Amplify AI Kit の Tools 機能 (「function calling」とも呼ばれます) を使用します。Tools 機能は、生成 AI モデルに特定のタスクを実行させるための機能です。例えば、データベースの検索や外部 API の呼び出しなどを生成 AI に行わせることができます。通常、このような機能を独自に実装しようとすると、以下のような手間がかかります。
-
ユーザー入力に応じたツール選択のための複雑なプロンプト設計
-
関数呼び出しのための複雑なロジックの実装
-
エラーハンドリングの実装
Amplify AI Kit の Tools 機能を使用することで、これらの手間を大幅に削減し、簡単に RAG 機能を実装できます。
ここからは、実際に Amplify AI Kit を使って RAG 機能を実装する方法を詳しく解説していきます。
全体アーキテクチャ
本ブログでは、AWS Amplify Gen 2 を使って RAG アプリケーションを構築します。Amazon Cognito でユーザー認証を行い、AWS AppSync の GraphQL API から AWS Lambda を介して Amazon Bedrock が提供する生成 AI の機能を利用します。Amazon Bedrock では基盤モデルだけでなく、RAG 機能として Amazon Bedrock Knowledge Base も利用します。チャットの履歴は Amazon DynamoDB に保存します。
アーキテクチャ図
Step 1. Amazon Bedrock Knowledge Bases を作成する
まずは Amazon Bedrock Knowledge Base を作成します。執筆時点では公式の Amazon Bedrock の L2 コンストラクトがないため、AWS Generative AI CDK Constructs の L2 コンストラクトを使用します。AWS Generative AI CDK Constructs は 2023 年の AWS re:Invent の Keynote でも紹介されている AWS CDK のオープンソース拡張で、生成 AI アプリケーションの構築に便利なコンストラクトが実装されています。
L2 コンストラクトって何 ? という方は、前回の記事 をご覧ください。また、Amazon Bedrock Knowledge Base って何 ? という方は、Black Belt オンラインセミナーの資料、および動画をご参照ください。
依存パッケージをインストール
まずは GitHub から サンプル をクローンして、Claude AI のディレクトリに移動し、依存パッケージをインストールします。
$ git clone https://github.com/aws-samples/amplify-ai-examples.git
$ cd amplify-ai-examples/claude-ai
$ npm ciaws-cdk と aws-cdk-lib のバージョンを確認
ここで、aws-cdk と aws-cdk-lib のバージョンについて確認します。"aws-cdk のリリース日が aws-cdk-lib のリリース日以降となる" ようにする必要があります。詳細はリンクを参照してください。
{
...中略
"devDependencies": {
...中略
"aws-cdk": "^2.164.2",
"aws-cdk-lib": "^2.178.1",
...中略
}
}aws-cdk のマイナーバージョンをアップデート
以下のコマンドで aws-cdk のメジャーバージョンを固定した上で最新のマイナーバージョンを確認し、アップデートします。
$ ncu --target minor aws-cdk
$ ncu --target minor aws-cdk -uclaude-ai/amplify/storage/resource.ts
次に、Knowledge Base のデータソースとなる Amazon Simple Storage Service (Amazon S3) バケットを作成します。Amazon S3 バケットは AWS Amplify の defineStorage を使って作成できます。claude-ai/amplify/storage/resource.ts ファイルを新規に作成し、 defineStorage で Amazon S3 バケットを定義します。
import { defineStorage } from "@aws-amplify/backend";
export const storage = defineStorage({
name: "<バケット名>",
});claude-ai/amplify/backend.ts
定義した storage を defineBackend に追加します。
import { defineBackend } from "@aws-amplify/backend";
import { auth } from "./auth/resource";
import { data } from "./data/resource";
import { storage } from "./storage/resource";
...中略
const backend = defineBackend({
auth,
data,
storage,
});
...以下略AWS Generative AI CDK Constructs をインストール
次に、AWS Generative AI CDK Constructs をインストールして、Knowledge Base を定義していきます。
$ npm install -D @cdklabs/generative-ai-cdk-constructsclaude-ai/amplify/backend.ts
Knowledge Base のデータソースとして Amazon S3 バケットを指定する際、defineStorage で作成した Amazon S3 バケットは backend.storage.resources.bucket で取得することができます。
import { defineBackend } from "@aws-amplify/backend";
import { bedrock } from "@cdklabs/generative-ai-cdk-constructs";
import { auth } from "./auth/resource";
import { data } from "./data/resource";
import { storage } from "./storage/resource";
const backend = defineBackend({
auth,
data,
storage,
});
const knowledgeBaseStack = backend.createStack("KnowledgeBase");
const kb = new bedrock.VectorKnowledgeBase(
knowledgeBaseStack,
"KnowledgeBase",
{
embeddingsModel: bedrock.BedrockFoundationModel.TITAN_EMBED_TEXT_V2_1024,
}
);
const kbS3DataSource = new bedrock.S3DataSource(knowledgeBaseStack, "KnowledgeBaseDataSource", {
bucket: backend.storage.resources.bucket,
knowledgeBase: kb,
});Knowledge Base の定義完了
これで Knowledge Base が定義できました。今回、Knowledge Base のベクトルデータベースとして Amazon OpenSearch Serverless を利用していますが、AWS Generative AI CDK Constructs のコンストラクト VectorKnowledgeBase ではベクトルデータベースの設定も行ってくれていて、とてもすっきりと書くことができます。
バックエンドリソースをデプロイ
ここで、Amplify のバックエンドリソースをデプロイしてみましょう。npx ampx sandbox で sandbox と呼ばれる開発環境をデプロイすることができます。
$ npx ampx sandboxドキュメントのアップロード
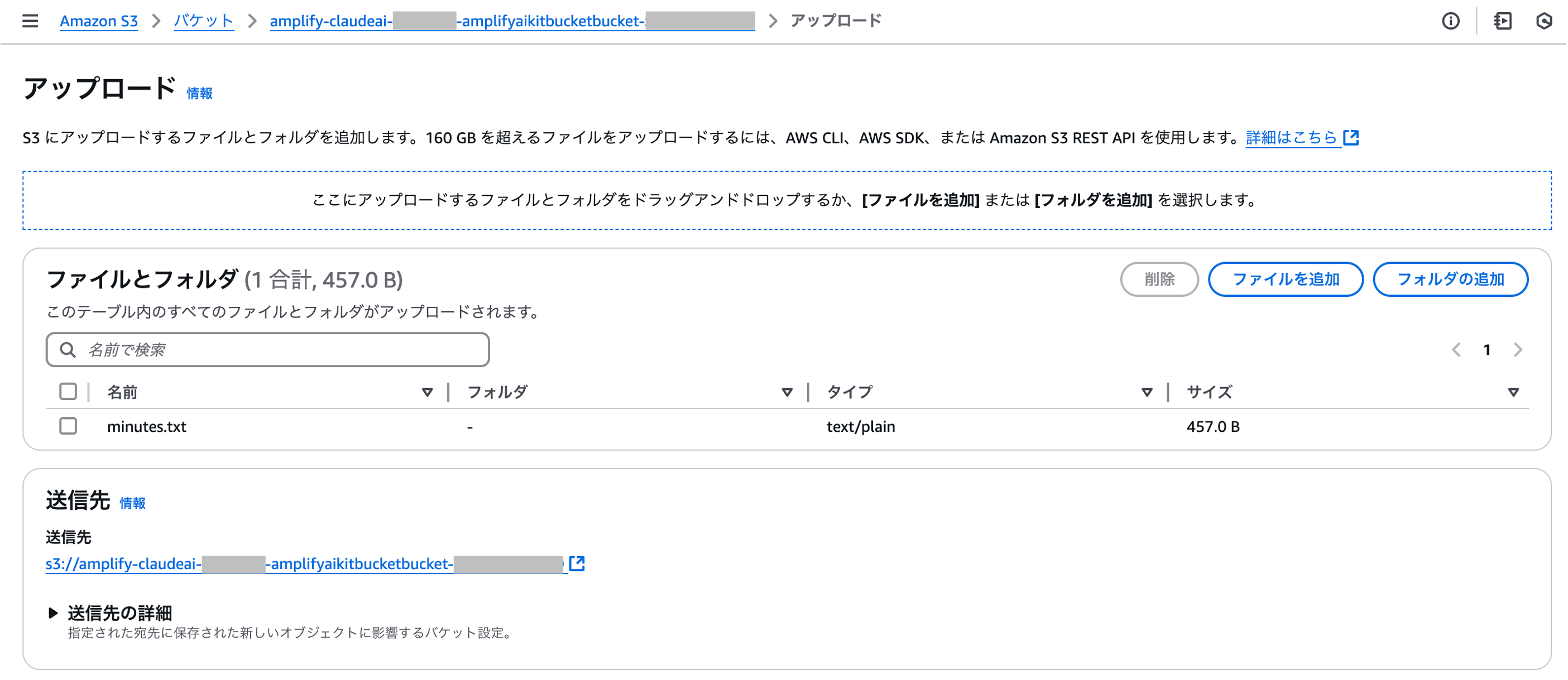
データソースに指定した Amazon S3 バケットに、RAG で参照したいドキュメントをアップロードします。
マネジメントコンソールにログインし、作成した Amazon S3 バケットにファイルをアップロードします。
バケット名は、npx ampx sandbox コマンドの出力の buckets か、claude-ai/amplify_outputs.json の storage.bucket_name から確認できます。
今回は例として、ある製品 A、X についての社内会議の議事録 (minutes.txt) をアップロードします。
- Q2業績
- 売上高:50億円(前年比+10%)
- 営業利益:8億円(前年比+15%)
- 主力製品A好調、コスト削減効果あり
- 新製品X開発
- プロトタイプ性能良好
- 部品調達遅れで量産1ヶ月遅延の可能性
- 対策案:1週間以内に提出
- アジア市場進出計画
- 目標:3年以内シェア10%
- 現地パートナー提携交渉中、来月基本合意見込み
Knowledge Base のデプロイ確認
データソースの同期
Step 2. Knowledge Base をツールとして呼び出す
Step 2-1. クエリツールの定義
まず、ツールを定義します。ツールは、claude-ai/amplify/data/resource.ts で定義されている schema の中に追加します。schema は Amplify Data の重要な要素の一つで、ここで定義したスキーマが AWS AppSync のスキーマに変換されます。
Amplify AI Kit では、conversation ルートに tools を指定することで、ツールを定義できます。ツールにはモデルツール、クエリツール、Lambda ツールの 3 種類があります。今回はクエリツールを使います。
-
モデルツール : Amplify のデータスキーマで定義したデータモデルの情報を LLM に渡すことができます。
-
クエリツール : Amplify のデータスキーマで定義したカスタムクエリを呼び出すことができます。今回はこちらを使用します。
-
Lambda ツール : Lambda 関数を呼び出すことができます。データスキーマの情報を使わない場合や、簡単な処理を実行したいときに便利です。
claude-ai/amplify/data/resource.ts
まず、claude-ai/amplify/data/resource.ts で定義しているスキーマの chat ルートに tools の設定を追加し、knowledgeBase クエリを呼び出すようにします。次に、knowledgeBase クエリを定義します。knowledgeBase クエリでは、次のステップで実装するデータソース (datasource) とリゾルバー (entry) を指定しています。 ツールの description にはツールでできることの説明を記載します。この description の内容から、LLM がユーザーのプロンプトに応じた適切なツールを選択します。
import { type ClientSchema, a, defineData } from "@aws-amplify/backend";
const schema = a.schema({
chat: a
.conversation({
aiModel: a.ai.model("Claude 3 Haiku"),
systemPrompt: `You are a helpful assistant`,
tools: [
a.ai.dataTool({
name: "searchDocumentation",
description: "製品 A に関する社内会議の議事録を取得する",
query: a.ref("knowledgeBase"),
}),
],
})
.authorization((allow) => allow.owner()),
knowledgeBase: a
.query()
.arguments({ input: a.string() })
.handler(
a.handler.custom({
dataSource: "KnowledgeBaseDataSource",
entry: "./resolvers/kbResolver.js",
})
)
.returns(a.string())
.authorization((allow) => allow.authenticated()),
...中略
});Step 2-2. AWS AppSync リゾルバー の定義
AWS AppSync のリゾルバーを定義します。AWS AppSync ではスキーマは 1 つ以上のデータソースに接続されており、リゾルバーはデータソースへのリクエストやデータソースからのレスポンスに対する処理を定義します。AWS AppSync のリゾルバーやデータソースについてはドキュメントをご参照ください。今回は、ユーザーからのプロンプトを使って、指定した Knowledge Base の Retrieve API を呼び出すよう request 関数を定義しています。
claude-ai/amplify/data/resolvers/kbResolver.js
リゾルバーを定義するファイル claude-ai/amplify/data/resolvers/kbResolver.js を作成します。<Knowledge Base ID> には、Knowledge Base を作成した際にメモした ID を記載してください。
export function request(ctx) {
const { input } = ctx.args;
return {
resourcePath: "/knowledgebases/<Knowledge Base ID>/retrieve",
method: "POST",
params: {
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
retrievalQuery: {
text: input,
},
}),
},
};
}
export function response(ctx) {
return JSON.stringify(ctx.result.body);
}Step 2-3. AWS AppSync データソースの作成
最後に、AWS AppSync のデータソースを作成します。今回は、backend.data.resources.graphqlApi で AWS AppSync の GraphQL API の L2 コンストラクトを取得し、addHttpDataSource で Knowledge Base をデータソースとして追加します。
また、Knowledge Base の Retrieve API を呼び出すために必要な IAM 権限も付与します。
claude-ai/amplify/backend.ts
AWS Amplify のバックエンドで Knowledge Baseと統合
import { defineBackend } from "@aws-amplify/backend";
import { bedrock } from "@cdklabs/generative-ai-cdk-constructs";
import { Stack } from "aws-cdk-lib";
import { PolicyStatement } from "aws-cdk-lib/aws-iam";
import { auth } from "./auth/resource";
import { data } from "./data/resource";
import { storage } from "./storage/resource";
...中略
const knowledgeBaseDataSource =
backend.data.resources.graphqlApi.addHttpDataSource(
"KnowledgeBaseDataSource",
`https://bedrock-agent-runtime.${
cdk.Stack.of(backend.data).region
}.amazonaws.com`,
{
authorizationConfig: {
signingRegion: cdk.Stack.of(backend.data).region,
signingServiceName: "bedrock",
},
}
);
knowledgeBaseDataSource.grantPrincipal.addToPrincipalPolicy(
new PolicyStatement({
resources: [kb.knowledgeBaseArn],
actions: ["bedrock:Retrieve"],
})
);Step 3. デプロイと動作確認
最後に、アプリケーションの動作確認をしてみましょう。「Step 1. Amazon Bedrock Knowledge Bases を作成する」で実行した npx ampx sandbox を中断していなければ、コードの変更が検知され、自動的にバックエンドがデプロイされます。また、npm run dev でフロントエンドをローカル PC 上でホストします。フロントエンドは AWS Amplify を利用してホスティングすることもできますが、今回は動作確認なのでローカル PC 上で実行します。
$ npm run devアカウント作成
ローカル PC でホストされたエンドポイント (例 : http://localhost:3000/) にブラウザからアクセスし、まずは「Create Account」からアカウント作成を行います。
入力したメールアドレス宛に送信された Confirmation Code を入力します。
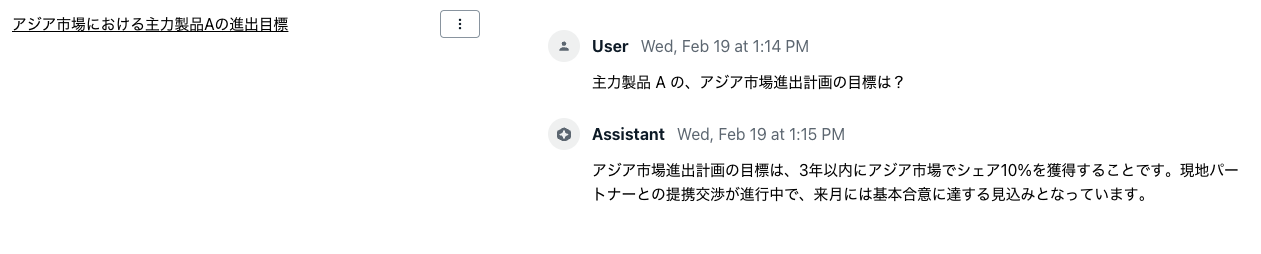
チャットで質問
ログインできたら、チャット欄で質問してみましょう。ある製品 A、X についての社内会議の議事録 (minutes.txt) の内容に基づいた回答が得られています。
おめでとうございます!これでシンプルなチャットアプリケーションに RAG 機能を追加できました!
(オプション) Knowledge Base のデータソースを定期的に同期する
まず、Amazon EventBridge Scheduler の L2 コンストラクトを使うために、 @aws-cdk/aws-scheduler-alpha と @aws-cdk/aws-scheduler-targets-alpha をインストールします。これらの alpha パッケージは安定版の前の developer preview 状態であるということにご留意ください。
@aws-cdk/aws-scheduler-alpha と @aws-cdk/aws-scheduler-targets-alpha をインストール
コマンド
$ npm install -D @aws-cdk/aws-scheduler-alpha @aws-cdk/aws-scheduler-targets-alphaclaude-ai/amplify/backend.ts
次に、IAM Role startIngestionJobSchedulerRole を定義し、Knowledge Base のデータソース同期ジョブの実行権限を付与します。次に、Amazon EventBridge Scheduler の Schedule を定義し、作成した IAM Role を指定します。Schedule の設定の引数 input で Knowledge Base ID やデータソース ID を渡すことで、同期するデータソースを指定します。
import { defineBackend } from "@aws-amplify/backend";
import {
Schedule,
ScheduleExpression,
ScheduleTargetInput,
} from "@aws-cdk/aws-scheduler-alpha";
import { Universal } from "@aws-cdk/aws-scheduler-targets-alpha";
import { bedrock } from "@cdklabs/generative-ai-cdk-constructs";
import { Stack, TimeZone } from "aws-cdk-lib";
import { PolicyStatement, Role, ServicePrincipal } from "aws-cdk-lib/aws-iam";
import { auth } from "./auth/resource";
import { data } from "./data/resource";
import { storage } from "./storage/resource";
...中略
// 追加
const startIngestionJobSchedulerRole = new Role(
knowledgeBaseStack,
"StartIngestionJobSchedulerRole",
{
assumedBy: new ServicePrincipal("scheduler.amazonaws.com"),
}
);
startIngestionJobSchedulerRole.addToPolicy(
new PolicyStatement({
resources: [kb.knowledgeBaseArn],
actions: ["bedrock:StartIngestionJob"],
})
);
new Schedule(knowledgeBaseStack, "StartIngestionJobSchedule", {
schedule: ScheduleExpression.cron({
minute: "0",
hour: "22",
timeZone: TimeZone.ASIA_TOKYO,
}),
target: new Universal({
service: "bedrockagent",
action: "startIngestionJob",
input: ScheduleTargetInput.fromObject({
KnowledgeBaseId: kb.knowledgeBaseId,
DataSourceId: kbS3DataSource.dataSourceId,
}),
role: startIngestionJobSchedulerRole,
}),
});同期履歴を確認
おわりに
Amplify 好きの稲田「菊地さん、いかがでしたか ? Amplify AI Kit を使った RAG アプリケーションの開発、思ったより簡単だったのではないでしょうか ?」
CDK 好きの菊地「そうですね ! Knowledge Base で簡単に RAG の仕組みを構築して、Amplify AI Kit でそれを簡単に呼び出せるというのが印象的でした。」
稲田「そうなんです。Amplify AI Kit を使うことで、生成 AI の機能を既存のアプリケーションに簡単に追加できるんですよ。今回は RAG 機能を実装しましたが、他にも様々な使い方ができるので、ぜひ ドキュメント もチェックしてみてください !」
菊地「確かに。今回学んだことを活かして、社内の他のプロジェクトにも応用できそうです。」
稲田「素晴らしいですね ! Amplify AI Kit の柔軟性を活かして、ぜひ様々なアイデアを試してみてください。」
みなさま、いかがだったでしょうか ?
本記事では AWS Amplify Gen 2 の AI Kit を利用して RAG アプリケーションを作成する方法をご紹介しました。
最近は多くの場面で生成 AI が活用されてきているので、AWS Amplify AI Kit で素早く構築し、AWS CDK でご自身のユースケースに合わせてカスタマイズしてみてください !
筆者プロフィール
菊地 晏南 (きくち あなん)
アマゾン ウェブ サービス ジャパン合同会社
技術統括本部 ソリューションアーキテクト
ソリューションアーキテクトとして、クラウドを活用されているお客様の技術支援を行っています。
バスケと旅行とカフェ巡りが趣味です。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages