- AWS Builder Center›
- builders.flash
はじめに
こんにちは。AWS Community Hero の御田 稔 (みのるん) です。
普段は生成 AI を活用したクラウドアプリケーションの開発をしながら、テックエバンジェリストとして技術の楽しさを発信する活動をしています。AWS ユーザーグループの JAWS-UG では、東京支部の運営をしています。
先日、AWS re:Invent 2024 で多数の AWS サービスのアップデートが発表されました。
今日はその中でも開発者向けの生成 AI サービス、Amazon Bedrock の新機能である「マルチエージェントコラボレーション」を使って、今流行りのマルチエージェント型の生成 AI アプリケーションを作ってみましょう。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
そもそもマルチエージェントとは ?
LLM (大規模言語モデル) を中心とした生成AIブームが続いていますが、最近のトレンドは「AI エージェント」です。
エージェント (代理人) という語が示すように、人間の代わりに高度なタスクをこなせることが特徴です。
AI エージェントは、一問一答形式のチャットボットと比較すると理解しやすいです。ユーザーからの問いかけにそのまま返答するだけではなく、何か大きな目的を与えられたらAI自ら行動計画を立てて、必要あれば外部のツール等を使い、その結果をうけて次の行動を調整し、最終的な目的を達成してくれます。
特に最近人気なのが「マルチエージェントシステム」という、複数のエージェントを駆使して目的を達成するアプローチです。マルチエージェントのプログラムを開発するのは、コードも複雑になりハードルが高かったのですが、AWS 上で GUI からこれを簡単に作れてしまう新機能が Amazon Bedrock のマルチエージェントコラボレーションです。
サンプルアプリを作ってみよう !
アプリの概要
あなたが開発で困ったとき、このアプリケーションに質問すると裏で 3 体の AI エージェントが動作します。
-
1 体目は監督者エージェントで、残りの 2 体のサブエージェントへ専門的な仕事をルーティングします。
-
2 体目は RAG (Retrieval-Augmented Generation、検索によって強化された生成) 担当のサブエージェントで、Amazon Bedrock のドキュメントを検索して情報提供を行います。
-
3 体目は Web 検索担当のサブエージェントで、Tavily という検索エンジンの API を使って最新情報を取得します。
実際のアプリケーション操作画面はこちらです。
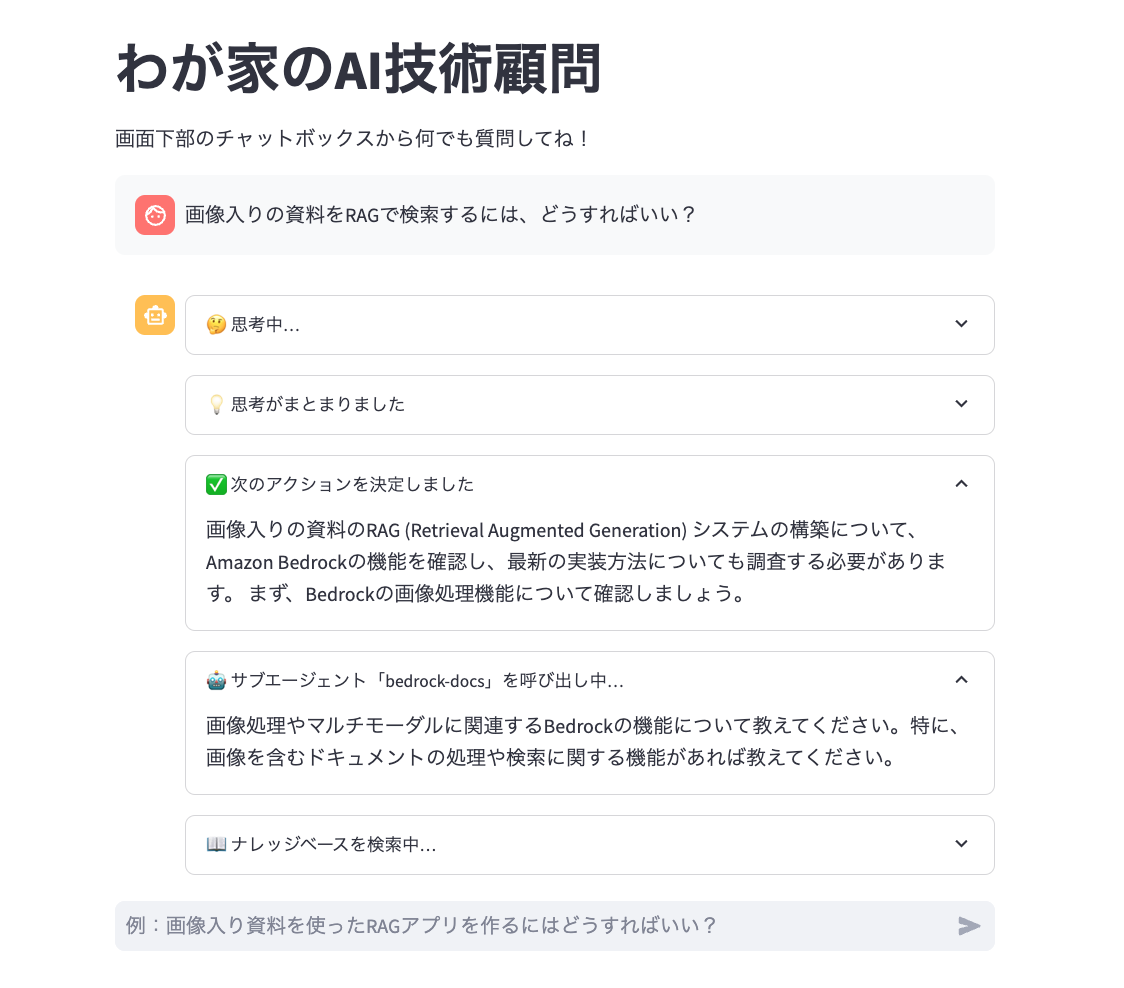
アーキテクチャ図
環境準備
筆者は以下の環境で本ハンズオンを実施しています。
-
デバイス : MacBook Air M2 モデル
-
Webブラウザ : Google Chrome
-
コードエディタ : VS Code
-
インストール済みの主なソフトウェア
-
Python 3.12.7
-
AWS CLI 2.22.28
-
AWS アカウントをお持ちでない方は、以下を参考に作成してください。
作業用の IAM ユーザーを作成の上、AWS マネジメントコンソールにサインインして作業を実施してください。(ルートユーザーのままだと実施できない作業が一部あります)
また、今回の作業はすべてバージニア北部 (us-east-1) リージョンで実施します。
【手順 1】 サブエージェント 1 (RAG 担当) の作成
モデルの有効化
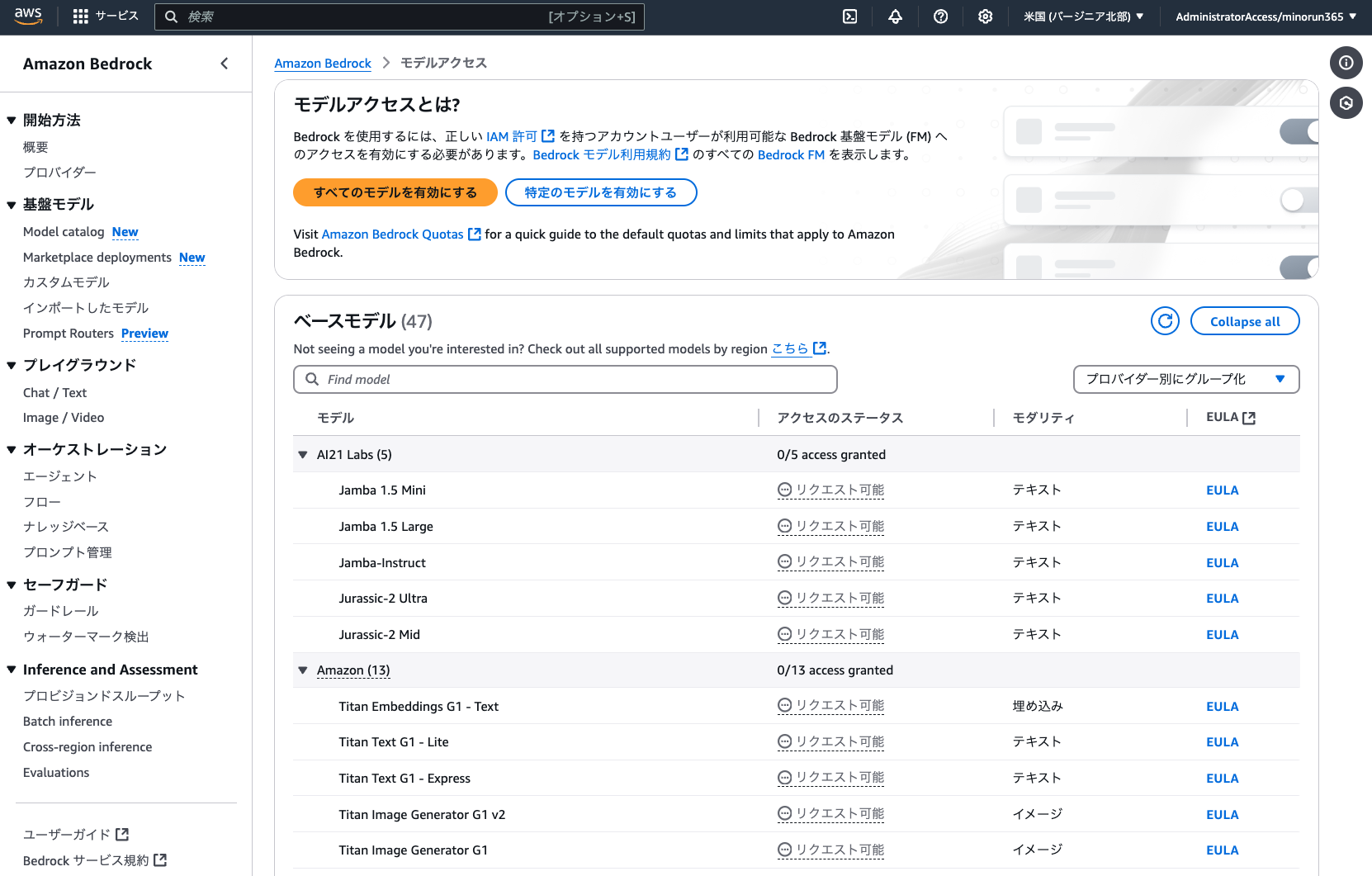
Amazon Bedrock で生成 AI のモデルを利用するためには、最初にモデルアクセスの有効化が必要です。
マネジメントコンソールから Amazon Bedrock を検索し、バージニア北部リージョンで「モデルアクセス」から以下のモデルを有効化しましょう。
-
Amazon
-
Titan Text Embeddings V2
-
-
Anthropic
-
Claude 3.5 Haiku
-
Claude 3.5 Sonnet v2
-
Claude 3.5 Sonnet
-
※今回は Amazon Bedrock Agents 用に最適化済みのモデルを選定しています。先日リリースされたばかりの「Claude 3.7 Sonnet」も、Agents への本格対応が楽しみですね !
Amazon S3 バケットの作成
RAG のデータソースとなるドキュメントを取得します。今回は Amazon Bedrock のユーザーガイドを利用しましょう。以下のリンクから PDF 版をダウンロードします。
これを Amazon S3 バケットにアップロードします。マネジメントコンソールから Amazon S3 を検索し、bedrock-docs-(あなたのニックネーム)-(YYYYMMDD) という名前の新規バケットを作成しましょう。名前以外の設定はデフォルトで大丈夫です。そこに前述の PDF をアップロードしておきます。
ナレッジベースの作成
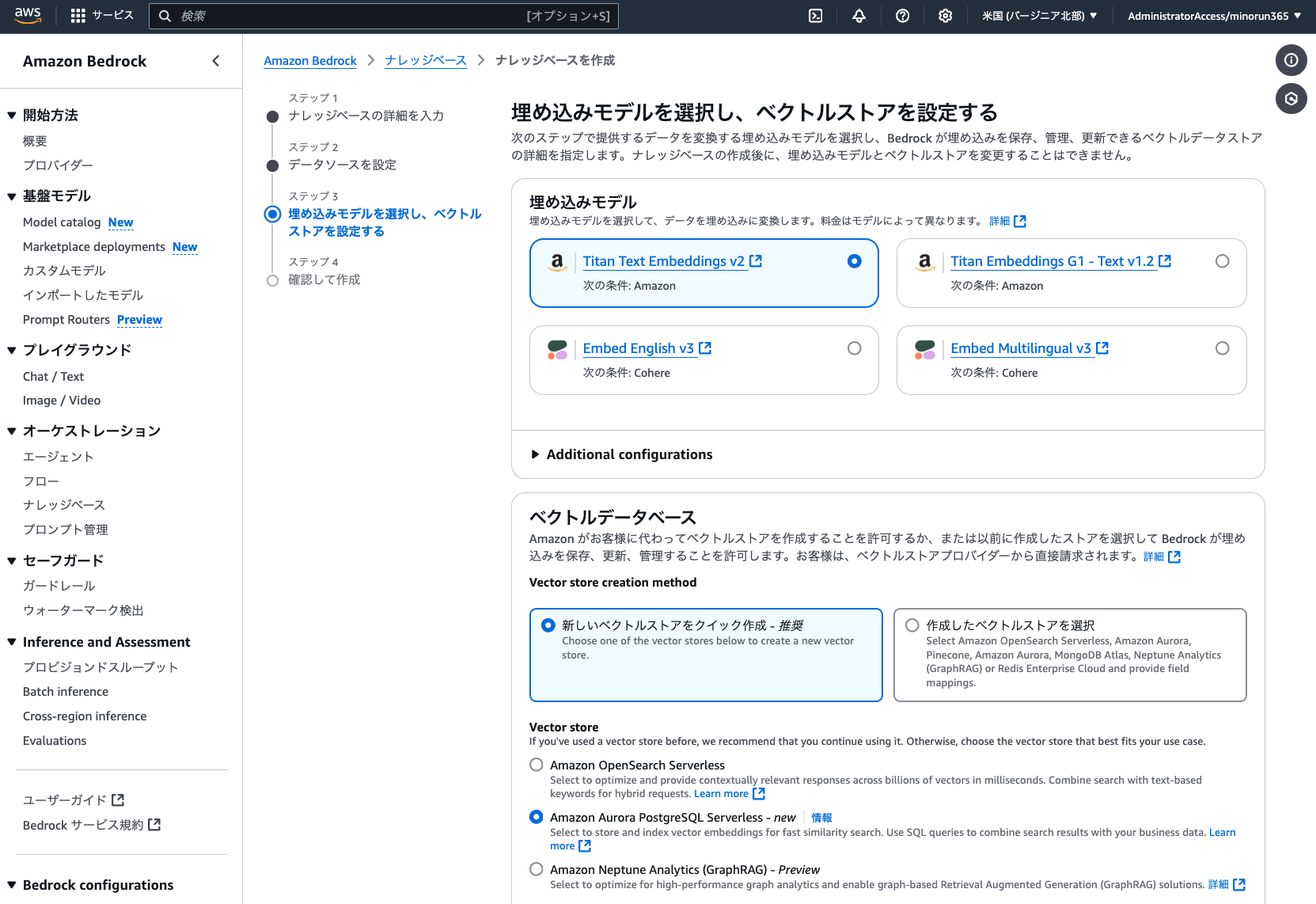
その後、Amazon Bedrock のコンソールに移動し、「オーケストレーション > ナレッジベース」から新規ナレッジベース (Knowledge Base with vector store) を作成します。この機能を使えば、簡単に RAG API を作ることができます。設定は以下のとおりです。(記載のない項目は変更不要)
ステップ 1
-
ナレッジベース名 : bedrock-docs
ステップ 2
-
データソース名 : bedrock-docs
-
S3 URI : s3://bedrock-docs-(あなたのニックネーム)-(YYYYMMDD)
ステップ 3
-
埋め込みモデル : Titan Text Embeddings v2
-
Vector store : Amazon Aurora PostgreSQL Serverless
ナレッジベースの作成には最大 13 分かかります。作成完了したら、詳細画面を開いてデータソース bedrock-docs の「同期」を実行しておきましょう。(ボタンを押してから同期開始まで少し時間がかかります)
なお、Amazon Aurora Serverless は最近、アイドル状態のときに自動で一時停止してくれるようになりました。このおかげで、このアプリケーションを使用していないときは Aurora クラスターが自動停止し、ベクトル DB のランニングコストを節約することができます。
エージェントの作成
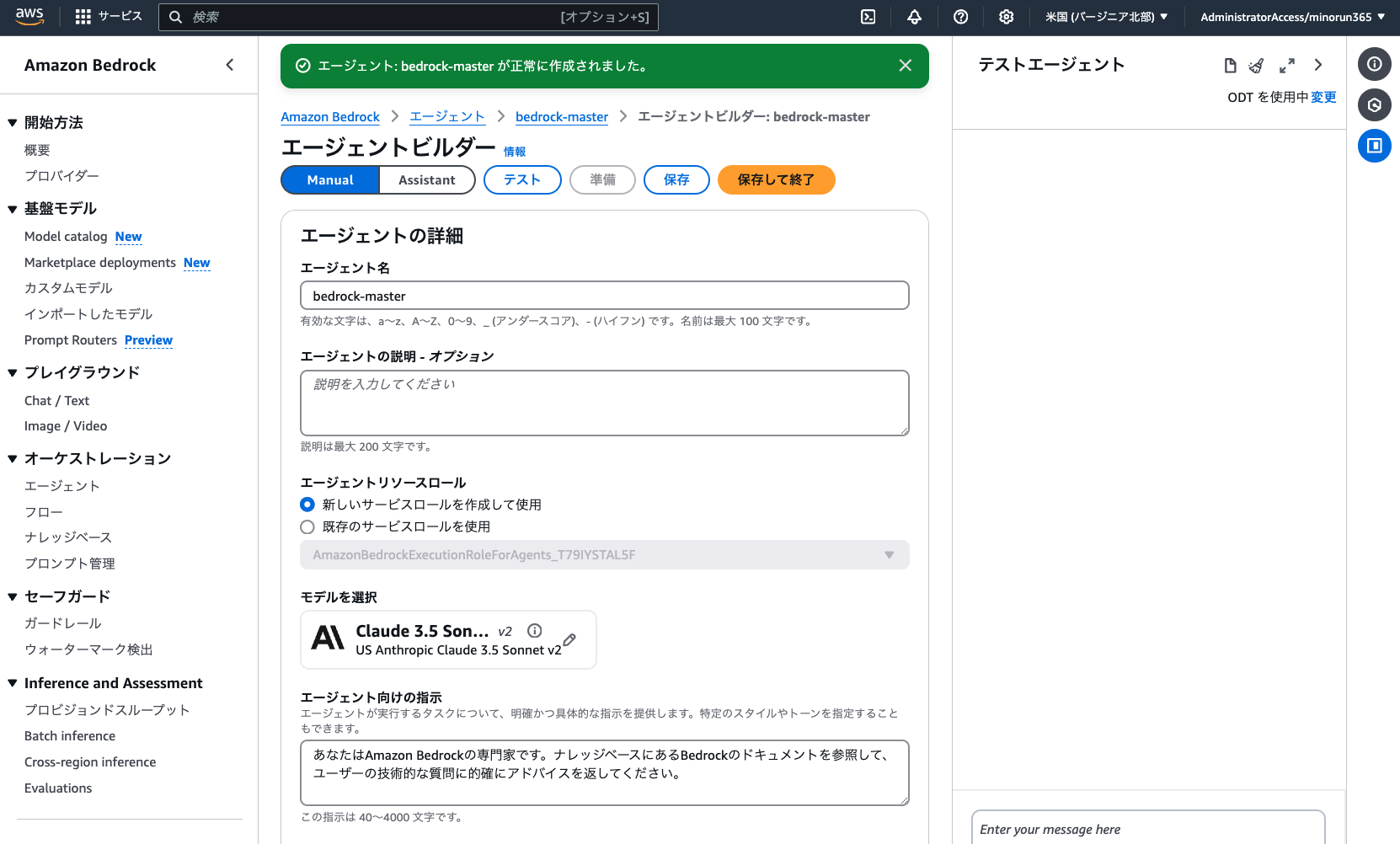
Amazon Bedrockコンソール の「オーケストレーション > エージェント」より、RAG 担当のサブエージェントを作成します。「エージェントを作成」より、以下のとおり設定しましょう。(記載のない項目は変更不要)
-
名前 : bedrock-master
エージェントビルダー
-
モデルを選択 : Anthropic > Claude 3.5 Haiku > US Anthropic Claude 3.5 Haiku (推論プロファイル)
-
エージェント向けの指示 : あなたは Amazon Bedrock の専門家です。ナレッジベースにある Bedrock のドキュメントを参照して、ユーザーの技術的な質問に的確なアドバイスを返してください。
ここで一度「保存」ボタンをクリックしておきます。
-
ナレッジベース : 「Add」ボタンから追加
-
ナレッジベースを選択 : bedrock-docs
-
エージェント向けのナレッジベースの指示 : Amazon Bedrock に関する情報が必要なときは、この公式ドキュメントから検索してください。
-
設定後は「保存して終了」し、画面右側のテスト用サイドバーにある「準備」ボタンを押したのち、「エイリアスを作成」を実施しましょう。
-
エイリアス名 : v1
【手順2】 サブエージェント2(Web検索担当)の作成
Tavily APIキーの取得
今回、Web 検索には Tavily という外部サービスを利用します。LLM での利用に最適化された検索エンジンで、無料でも月間 1,000 回までの API 呼び出しを使うことができます。
上記の公式サイトよりサインアップし、API キーの文字列を取得しておいてください。
エージェントの作成
Amazon Bedrock コンソールの「オーケストレーション > エージェント」より、Web 検索担当のサブエージェントを作成します。「エージェントを作成」より、以下のとおり設定しましょう。(記載のない項目は変更不要)
-
名前 : web-search-master
エージェントビルダー
-
モデルを選択 : Anthropic > Claude 3.5 Sonnet v2 > US Anthropic Claude 3.5 Sonnet v2 (推論プロファイル)
-
エージェント向けの指示 : あなたは生成 AI アプリ開発の専門家です。ユーザーの質問に対し、「tavily_search」ツールを用いて Web 検索のうえ、回答してください。
※Bedrock のモデル呼び出しクォータ上限に抵触しないよう、エージェントごとにモデルを少し変えています。ご注意ください。
ここで一度「保存」ボタンをクリックしておきます。
-
アクショングループ : 「追加」ボタンから以下設定
-
アクショングループ名を入力 : tavily_search
-
アクショングループ関数 1
-
名前 : tavily_search
-
パラメータ : 以下のとおり
-
-
|
名前 |
説明 |
タイプ |
必須 |
|---|---|---|---|
|
query |
Web 検索クエリー |
String |
True |
設定後は「保存して終了」し、画面右側のテスト用サイドバーにある「準備」ボタンを押したのち、「エイリアスを作成」を実施しましょう。
-
エイリアス名 : v1
AWS Lambda の設定
先ほど Bedrock エージェントでアクショングループを作成したことにより、Lambda 関数が自動で作成されています。マネジメントコンソールから「Lambda」に移動し、追加の設定を実施しましょう。
最初に画面右上の [>_] アイコンをクリックして を起動し、Lambdaレイヤー用の ZIP ファイルを作成します。
コマンドの実行
下記コマンドを実行しましょう。
mkdir python
pip install tavily-python --target python #エラーは無視してOK
zip -r layer.zip pythonレイヤーの作成
実行後、「アクション > ファイルのダウンロード」から layer.zip と入力し、ZIP ファイルをダウンロードしておきます。その後、Lambda コンソールの「その他のリソース > レイヤー」より、「レイヤーの作成」を実施します。
-
レイヤー名: Tavily
-
「.zip ファイルをアップロード」より、上記の ZIP ファイルをアップロード
-
互換性のあるアーキテクチャ : x86_64
-
互換性のあるランタイム : Python 3.9
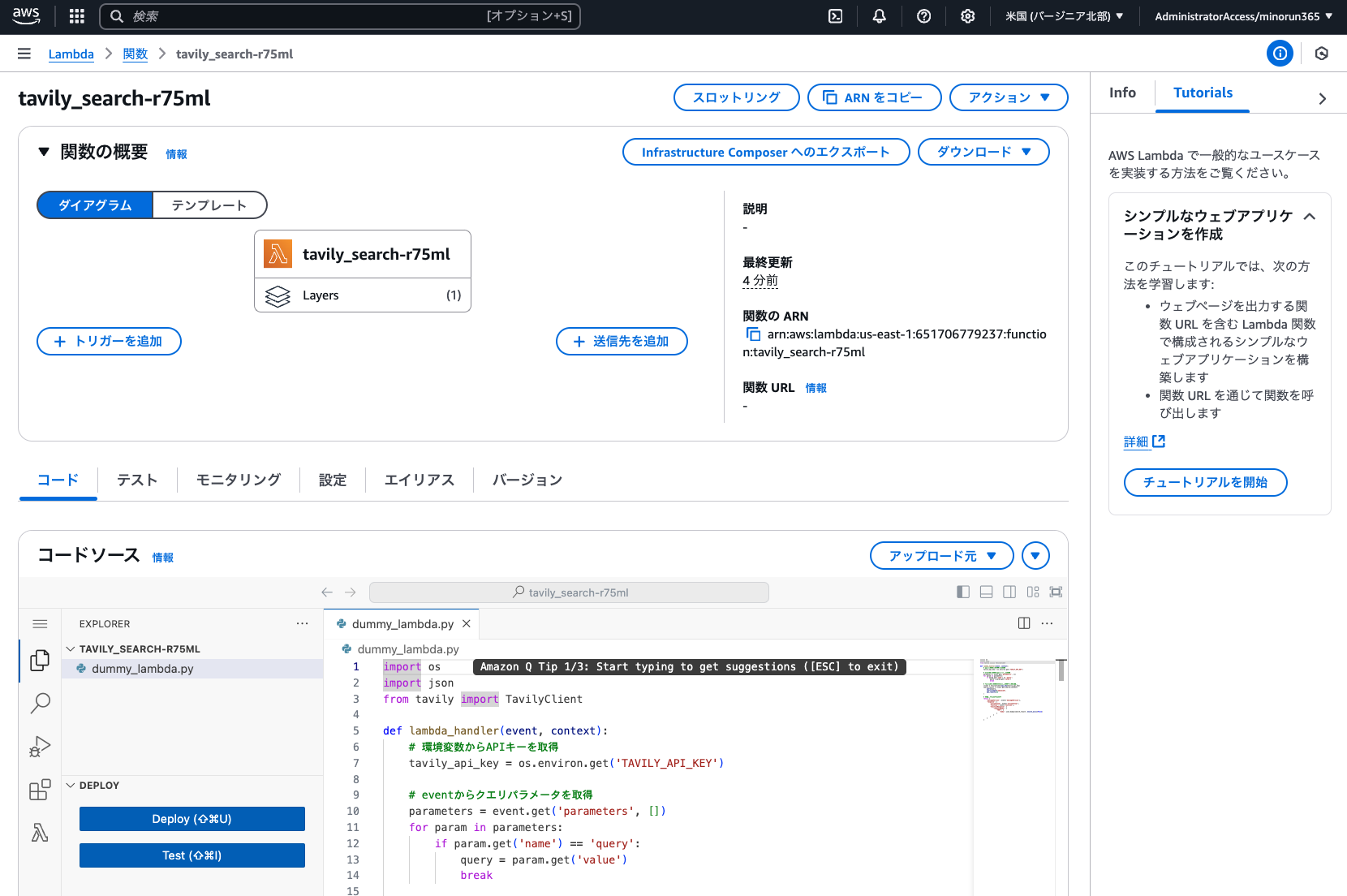
設定したら「作成」を実行します。その後、Lambda 関数「tavily_search-xxxxx」に移動し、以下のとおり設定します。(記載のない項目は変更不要)
dummy_lambda.py を編集
コードソース : dummy_lambda.py を以下コードで上書きし「Deploy」を実行
import os
import json
from tavily import TavilyClient
def lambda_handler(event, context):
# 環境変数からAPIキーを取得
tavily_api_key = os.environ.get('TAVILY_API_KEY')
# eventからクエリパラメータを取得
parameters = event.get('parameters', [])
for param in parameters:
if param.get('name') == 'query':
query = param.get('value')
break
# Tavilyクライアントを初期化して検索を実行
client = TavilyClient(api_key=tavily_api_key)
search_result = client.get_search_context(
query=query,
search_depth="advanced",
max_results=10
)
# 成功レスポンスを返す
return {
'messageVersion': event['messageVersion'],
'response': {
'actionGroup': event['actionGroup'],
'function': event['function'],
'functionResponse': {
'responseBody': {
'TEXT': {
'body': json.dumps(search_result, ensure_ascii=False)
}
}
}
}
}Lambda 関数の設定
-
ランタイム設定
-
ランタイム : Python 3.9(CloudShell と合わせる)
-
-
レイヤー:「追加」より以下を設定
-
レイヤーソース : カスタムレイヤー
-
カスタムレイヤー : Tabily
-
バージョン : 1
-
「設定」タブ
-
一般設定
-
タイムアウト : 0 分 30 秒
-
-
環境変数 : 以下を設定
|
キー |
設定 |
|---|---|
|
TAVILY_API_KEY |
先ほどコピーした Tavily の API キーを入力 |
※今回は簡易検証のため環境変数を利用していますが、本格利用の際は API キーを AWS Secret Manager 等を用いてセキュアに保存しましょう。
【手順 3】 監督者エージェントの作成
Amazon Bedrock コンソールの「オーケストレーション > エージェント」より、監督者エージェントを作成します。「エージェントを作成」より、以下のとおり設定しましょう。(記載のない項目は変更不要)
-
名前 : your-tech-advisor
-
Enable multi-agent collaboration : チェックを入れる
エージェントビルダー
-
モデルを選択 : Anthropic > Claude 3.5 Sonnet v1 > US Anthropic Claude 3.5 Sonnet v1 (推論プロファイル)
-
エージェント向けの指示 : あなたは生成 AI アプリ開発の専門家です。ユーザーからの質問にアドバイスを返してあげてください。その際、Amazon Bedrock が活用できそうな場合は、bedrock-master エージェントから情報を取得してください。また、フレームワークやツール等に関する最新情報が必要な場合は、web-search-master エージェントから情報を取得してください。
-
その他の設定
-
ユーザー入力 : 有効
-
ここで一度「保存」ボタンをクリックしておきます。
-
Multi-agent collaboration : 「編集」ボタンから以下設定
-
Agent collaborator (1 件目)
-
Collaborator agent : bedrock-master
-
Agent alias : v1
-
Collaborator name : bedrock-master
-
Collaborator instruction : Amazon Bedrock に関する情報を的確に収集し回答します。
-
-
Agent collaborator (2 件目)
-
Collaborator agent : web-search-master
-
Agent alias : v1
-
Collaborator name : web-search-master
-
Collaborator instruction : Web 検索を行って最新のツールやフレームワーク、その他開発手法に関する情報を回答します。
-
-
設定したら「Save and exit」を実行します (エラーが発生するときは、Agent collaborator を 1 件ずつ登録して保存してみてください)。その後、エージェントビルダー画面も「保存して終了」し、画面右側のテスト用サイドバーにある「準備」ボタンを押したのち、「エイリアスを作成」を実施しましょう。
-
エイリアス名:v1
この監督者エージェントのIDと、「エイリアスID」の2つをメモしておきましょう。このあと使います。
【手順 4】 Python フロントエンドから動作確認
ここまでで AWS 上の設定はすべて完了です。3 体のエージェントを作成できたので、以下のコードを frontend.py という名前で作業 PC のローカルに作成しましょう。
import os
import json
import uuid
import boto3
import streamlit as st
from dotenv import load_dotenv
from botocore.exceptions import ClientError
from botocore.eventstream import EventStreamError
def initialize_session():
"""セッションの初期設定を行う"""
if "client" not in st.session_state:
st.session_state.client = boto3.client("bedrock-agent-runtime", region_name="us-east-1")
if "session_id" not in st.session_state:
st.session_state.session_id = str(uuid.uuid4())
if "messages" not in st.session_state:
st.session_state.messages = []
if "last_prompt" not in st.session_state:
st.session_state.last_prompt = None
return st.session_state.client, st.session_state.session_id, st.session_state.messages
def display_chat_history(messages):
"""チャット履歴を表示する"""
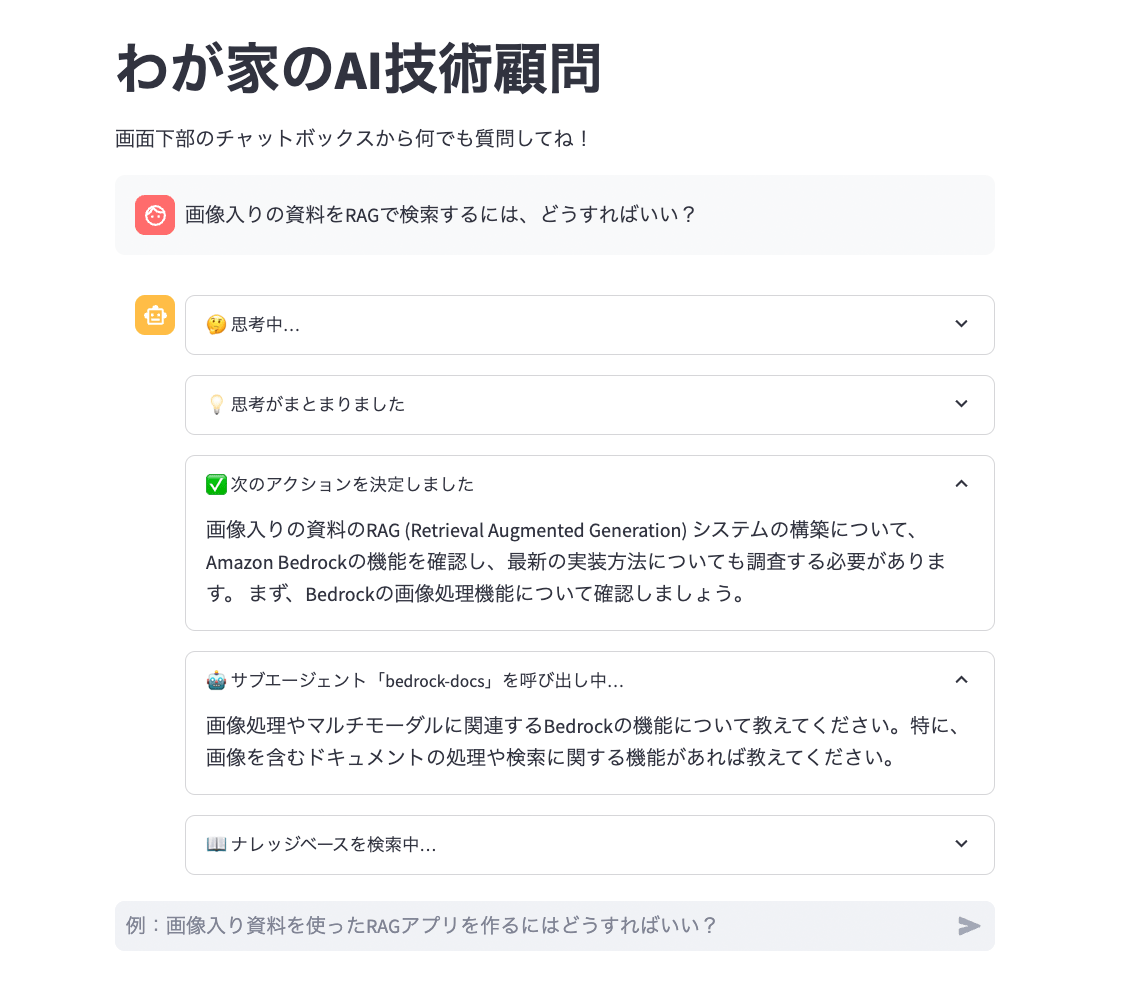
st.title("わが家のAI技術顧問")
st.text("画面下部のチャットボックスから何でも質問してね!")
for message in messages:
with st.chat_message(message['role']):
st.markdown(message['text'])
def handle_trace_event(event):
"""トレースイベントの処理を行う"""
if "orchestrationTrace" not in event["trace"]["trace"]:
return
trace = event["trace"]["trace"]["orchestrationTrace"]
# 「モデル入力」トレースの表示
if "modelInvocationInput" in trace:
with st.expander("🤔 思考中…", expanded=False):
input_trace = trace["modelInvocationInput"]["text"]
try:
st.json(json.loads(input_trace))
except:
st.write(input_trace)
# 「モデル出力」トレースの表示
if "modelInvocationOutput" in trace:
output_trace = trace["modelInvocationOutput"]["rawResponse"]["content"]
with st.expander("💡 思考がまとまりました", expanded=False):
try:
thinking = json.loads(output_trace)["content"][0]["text"]
if thinking:
st.write(thinking)
else:
st.write(json.loads(output_trace)["content"][0])
except:
st.write(output_trace)
# 「根拠」トレースの表示
if "rationale" in trace:
with st.expander("✅ 次のアクションを決定しました", expanded=True):
st.write(trace["rationale"]["text"])
# 「ツール呼び出し」トレースの表示
if "invocationInput" in trace:
invocation_type = trace["invocationInput"]["invocationType"]
if invocation_type == "AGENT_COLLABORATOR":
agent_name = trace["invocationInput"]["agentCollaboratorInvocationInput"]["agentCollaboratorName"]
with st.expander(f"🤖 サブエージェント「{agent_name}」を呼び出し中…", expanded=True):
st.write(trace["invocationInput"]["agentCollaboratorInvocationInput"]["input"]["text"])
elif invocation_type == "KNOWLEDGE_BASE":
with st.expander("📖 ナレッジベースを検索中…", expanded=False):
st.write(trace["invocationInput"]["knowledgeBaseLookupInput"]["text"])
elif invocation_type == "ACTION_GROUP":
with st.expander("💻 Lambdaを実行中…", expanded=False):
st.write(trace['invocationInput']['actionGroupInvocationInput'])
# 「観察」トレースの表示
if "observation" in trace:
obs_type = trace["observation"]["type"]
if obs_type == "KNOWLEDGE_BASE":
with st.expander("🔍 ナレッジベースから検索結果を取得しました", expanded=False):
st.write(trace["observation"]["knowledgeBaseLookupOutput"]["retrievedReferences"])
elif obs_type == "AGENT_COLLABORATOR":
agent_name = trace["observation"]["agentCollaboratorInvocationOutput"]["agentCollaboratorName"]
with st.expander(f"🤖 サブエージェント「{agent_name}」から回答を取得しました", expanded=True):
st.write(trace["observation"]["agentCollaboratorInvocationOutput"]["output"]["text"])
def invoke_bedrock_agent(client, session_id, prompt):
"""Bedrockエージェントを呼び出す"""
load_dotenv()
return client.invoke_agent(
agentId=os.getenv("AGENT_ID"),
agentAliasId=os.getenv("AGENT_ALIAS_ID"),
sessionId=session_id,
enableTrace=True,
inputText=prompt,
)
def handle_agent_response(response, messages):
"""エージェントのレスポンスを処理する"""
with st.chat_message("assistant"):
for event in response.get("completion"):
if "trace" in event:
handle_trace_event(event)
if "chunk" in event:
answer = event["chunk"]["bytes"].decode()
st.write(answer)
messages.append({"role": "assistant", "text": answer})
def show_error_popup(exeption):
"""エラーポップアップを表示する"""
if exeption == "dependencyFailedException":
error_message = "【エラー】ナレッジベースのAurora DBがスリープしていたようです。数秒おいてから、ブラウザをリロードして再度お試しください🙏"
elif exeption == "throttlingException":
error_message = "【エラー】Bedrockのモデル負荷が高いようです。1分待ってから、ブラウザをリロードして再度お試しください🙏(改善しない場合は、モデルを変更するか[サービスクォータの引き上げ申請](https://aws.amazon.com/jp/blogs/news/generative-ai-amazon-bedrock-handling-quota-problems/)を実施ください)"
st.error(error_message)
def main():
"""メインのアプリケーション処理"""
client, session_id, messages = initialize_session()
display_chat_history(messages)
if prompt := st.chat_input("例:画像入り資料を使ったRAGアプリを作るにはどうすればいい?"):
messages.append({"role": "human", "text": prompt})
with st.chat_message("user"):
st.markdown(prompt)
try:
response = invoke_bedrock_agent(client, session_id, prompt)
handle_agent_response(response, messages)
except (EventStreamError, ClientError) as e:
if "dependencyFailedException" in str(e):
show_error_popup("dependencyFailedException")
elif "throttlingException" in str(e):
show_error_popup("throttlingException")
else:
raise e
if __name__ == "__main__":
main().env ファイルを保存
また、上記と同じ階層に .env ファイルを保存しておきます。ここに先ほどコピーした値を記載しましょう。
AGENT_ID = "XXXXXXXXXX"
AGENT_ALIAS_ID = "XXXXXXXXXX"IAM ユーザーの認証設定
ターミナルの実行環境に IAM ユーザーの認証設定を実施していない方は、以下を実施しておきます。
Python コードを実行
以下のコマンドで Python コードを実行してみましょう。
# 必要なライブラリをインストール
pip install boto3 streamlit
# Streamlitでコードを実行
streamlit run frontend.pyWeb ブラウザでアクセス
PC の Web ブラウザで http://localhost:8501/ へアクセスすると、アプリを試すことができます。
※初回実行時は Amazon Aurora Serverless がゼロキャパシティへ縮退しており、エラーとなる可能性があります。その際はブラウザを更新し、再度お試しください。
おかたづけ
今回のアーキテクチャでは、サーバーレス対応の AWS サービスが中心のため利用していないときのコストがあまりかからない構成となっています。作成した主なリソースは以下となりますので、検証が終わったら不要なものは削除しておきましょう。
Amazon Bedrock
- エージェント : bedrock-master, web-search-master, your-tech-advisor
- ナレッジベース : bedrock-docs
Amazon S3
- 汎用バケット : s3://bedrock-docs-(あなたのニックネーム)-(YYYYMMDD)
Amazon RDS
- データベース : knowledgebasequickcreateaurora-XXX-auroradbcluster-xxxxxxxxxx
AWS Lambda
- 関数 : tavily_search-xxxxx
- レイヤー : Tavily
まとめ
いかがでしたでしょうか。実際に触ってみると、マルチエージェントの動作イメージや意義がより分かりやすかったのではないかと思います。
なお、新規作成したばかりの AWS アカウントでは Amazon Bedrock のサービスクォータが低めに設定されており、マルチエージェントを稼働させると「1 分あたりのモデル呼び出し数上限」に抵触してスロットリングエラーが発生することがあります。本ハンズオンでは、対策としてエージェントごとにモデルを変えていますが、それでも上手くいかない場合は以下の記事を参考にクォータの緩和申請を実施してみてください。
今回のサンプルアプリケーションのコードは、以下の GitHub でも公開しています。不具合が見つかった際や、仕様変更により動作しなくなった場合は随時更新予定です。
なお、Amazon Bedrock のマルチエージェントコラボレーション機能は、本稿執筆時点 (2025 年 1 月) でまだプレビューである点にご注意ください。協働可能なエージェント数や、構築可能なデザインパターンに制限があります。GA されるのが楽しみですね !
筆者プロフィール
御田 稔(みのるん @minorun365)
KDDIアジャイル開発センター株式会社 テックエバンジェリスト。クラウドや生成AIを用いた内製開発に携わりつつ、技術の楽しさを広める活動をしています。
AWS Community Hero、AWS Samurai 2023、2024 Japan AWS Top Engineer & All Certs認定。著書「Amazon Bedrock 生成AIアプリ開発入門」(SBクリエイティブ刊)
