- AWS Builder Center
- builders.flash
Amazon EKS Auto Mode のノード自動更新を Deep Dive する ~ 長期実行ワークロードを正しく取り扱う
2025-04-02 | Author : 林 政利
はじめに
Amazon EKS Auto Mode は、AWS re:Invent 2024 で発表された Amazon EKS の新しい実行モードです。Auto Mode は、Kubernetes クラスターのノード管理を大幅に自動化し、運用の負荷を軽減することを目的としています。「Amazon EKS Auto Mode を始めよう」では、Auto Mode が持つ機能やアーキテクチャ、具体的に運用をどのように効率化できるかについて記載されていますのでぜひご参照ください。
Auto Mode では、Amazon EKS が皆さんに代わって自律的にノードを管理します。そのため、 Auto Mode が管理している Kubernetes のノードには以下のような動的な性質があります。
-
AMI の自動更新 : Auto Mode 用の新しい Amazon Machine Image (AMI) がリリースされると、ノードが自動的に新しい AMI で再作成されます
-
ノードの有効期限 : セキュリティを強化するため、ノードには最大 21 日の有効期限が設定されています。期限が来ると自動的にノードが終了し、最新の状態に更新されます
-
自動的なノード管理 : 詳しくは後述しますが、Auto Mode がノードのライフサイクルを自動化しており、様々な条件でノードが終了・削除され、必要に応じて新しいノードが作成されます。
Auto Mode は、このような動的な性質により、Kubernetes クラスターのセキュリティを強化し、常に最新の環境が使えるようにしています。同時に、手動で運用する手間を最小限に抑えることができるようになっています。
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
1. 長期実行ワークロードの課題
Auto Mode の動的な性質は、多くの利点をもたらす一方で、特定のタイプのワークロードに対しては懸念されることもあります。特に多くのお問い合わせを受けるのは、プロセスが長期間起動している以下のようなワークロードについてです。
-
ステートフルなアプリケーション
-
長時間のバッチ処理
-
長期間の常時接続を必要とするサービス (WebSocket など)
これらのワークロードは、一般的にノードの終了や再作成によって大きな影響を受けます。主な課題として以下が挙げられます。
-
データの永続性 : ノードが終了する際、そのノード上のメモリやファイルシステムなど、ノードローカルに保存されたデータが失われる
-
処理の中断 : 長時間実行中のタスクが、ノードの終了によって中断される
-
接続の維持 : 常時接続が必要なサービスが、ノードの入れ替えによって接続が切断されクライアントにエラーが返る
このようなワークロードも、適切な対策を行えば Auto Mode で実行できます。本記事では、Auto Mode がノードを終了させるメカニズムを解説し、各種ワークロードに対する具体的な対応策を紹介します。これにより、長期実行ワークロードを含む様々なアプリケーションを、Auto Mode 環境で安全かつ効率的に運用する方法を明らかにしていきます。
2. Auto Mode におけるノードの自動終了
Auto Mode では、ノードの自動管理を実現するために、AWS が オープンソースで開発している Karpenter を利用しています。
この Karpenter の持つ Disruption という仕組みにより、 Auto Mode では、様々な理由でノードが自動的に終了し、新しいノードに置換されます。この自動的なノードの更新により、Auto Mode は Kubernetes 環境をセキュアで可用性の高い状態に維持しています。
どのように終了されるかは、 Karpenter の NodePool という Kubernetes リソースで設定できますが、大きく Graceful な終了と Forceful な終了の 2 つに分類できます。それぞれの特徴と発生する状況について詳しく見ていきましょう。
2-1. Graceful な終了
Graceful な終了は、事前に計画された、比較的緩やかなプロセスで行われる終了方法です。ワークロードの中断が発生するタイミングを設定で制御できます。
-
NodePool Disruption Budgets を設定可能
-
終了のタイミングと、どの程度アグレッシブに終了させるか制御できる
-
例: 金曜の朝に 20% ずつノードを終了する
-
-
新しいノードの起動を確認してから Pod の再スケジューリングを開始
Graceful な終了は、以下のケースで発生します。
ノードの統合や安価なノードへの置き換えが発生した時 (Consolidation)
Auto Mode では、ノードの利用状況を常に監視しており、ノードを統合したり置き換えたりすることによりコンピュートを最適化し続けます。これを、ノードの Consolidation と呼びます。利用率が低いノードはこのメカニズムにより終了される可能性があります。
ノードが希望される状態からズレた時 (Drift)
ノードを管理している NodePool の定義と、実際に起動しているノードの仕様にズレが発生したときは、Auto Mode は NodePool の定義に合わせるためノードを終了させます。例えば、r系インスタンスを含めた NodePool があり、その NodePool から起動している r5.xlarge のノードがあったとします。このとき、NodePool を編集し、r 系インスタンスを外すと、Drift が発生したとしてノードの終了がトリガーされます。
ノードに新しい AMI が適用できる時
Drift に含まれるケースで、ノードに適用されるべき AMI が外部要因で変わることがあります。
-
セキュリティパッチが適用された新しい AMI が Auto Mode により公開された
-
Kubernetes のバージョンを更新したためにノードに適用されるべき AMI が新しい Kubernetes バージョンのものに変更された
この場合、Auto Mode は自動的に新しい AMI から新しいノードを起動し、古い AMI のノードを終了します。
2-2. Forceful な終了
Forceful な終了は、予期せぬ外部要因やノードに設定された期限により、即座に実行される終了方法です。この方法では、ワークロードの中断が突然トリガーされる可能性があります。
-
NodePool Disruption Budgets を設定できない
-
終了のタイミングを制御できない
-
-
ノードのドレインを即座に開始
-
新しいノードの起動を待たずに Pod の再スケジュールが開始される
-
外部イベントによるノードの中断 (Interuption)
Amazon EC2 のメンテナンスイベント、Spot の中断通知など、EC2 の中断イベントが発生すると、ノードの終了がトリガーされます。なお、Spot の中断通知の場合、挙動が少し異なり、Auto Mode は新しい EC2 をすぐに起動することでワークロードの中断を最小限に抑えるようにします。
ノードの期限が切れた時 (Expiration)
Auto Mode で起動されたノードには、期限が設定されています。デフォルトでは 14 日ですが、変更可能です。起動してからの時間がこの期限を過ぎると、ノードの終了がトリガーされます。
これらの自動終了メカニズムにより、Auto Mode は常に最新かつ最適な状態のノードを維持しようとします。しかし、ワークロードの特性によっては、これらの終了プロセスに対応するための追加の設定や対策が必要になる場合があります。
3. ノード終了のプロセス
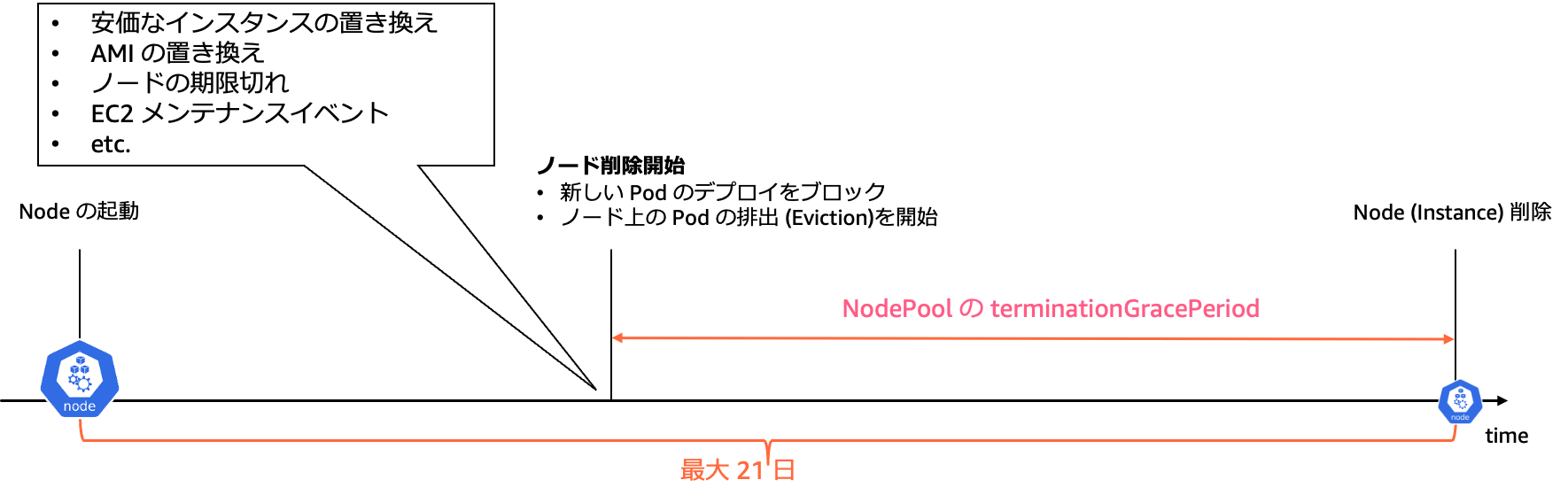
Auto Mode におけるノード終了のプロセスは、ワークロードの安全性と可用性を確保しつつ、システムの健全性を維持するように設計されています。このセクションでは、ノード終了の具体的なステップと、それに関連する時間的な制約について説明します。
Forceful、Graceful にかかわらず、Auto Mode でノードの終了がトリガーされると、ワークロードを安全にノードから退避させるために以下のステップが実行されます。
-
新しい Pod のデプロイをブロック : ノードにスケジュール不能な Taints が付与されます。これにより、新しい Pod がこのノードにスケジュールされることを防ぎます。
-
Pod の排出 : Eviction API を使用して、ノード上の Pod の排出プロセスが開始されます。
-
ノードの削除 : すべての Pod が正常に排出された場合、ノードが削除されます。一定時間 (NodePool の terminationGracePeriod) が経過しても Pod が排出されない場合、ノードは強制的に削除されます。
プロセス図
NodePool の設定
Auto Mode におけるノード終了プロセスでは、NodePool の以下の設定が重要です。
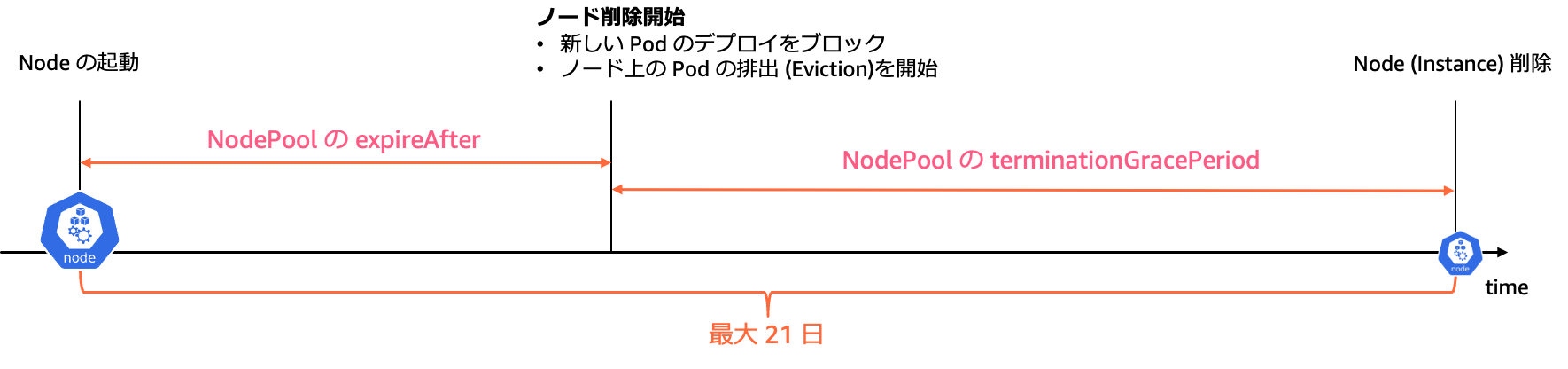
3-1. terminationGracePeriod
デフォルトでは 24 時間に設定されています。この期間内に Pod の排出が完了しない場合、ノードは強制的に削除されます。NodePoolの設定で変更可能ですが、最大値には以下の制限があります。
3-2. expireAfter
ノードの自動終了をトリガーする期間を指定します。デフォルトでは 2 週間に設定されています。 Auto Mode では、ノードの最大生存期間は 21 日間です。つまり、expireAfter と NodePool の terminationGracePeriod の合計値は 21 日を超えることはできません。
4. ワークロードの安全な終了方法
前提として、Kubernetes において、ワークロードは、Pod に設定された終了時間のうちに安全に終了する必要があります。具体的には、Pod の終了処理が開始されてから terminationGracePeriodSeconds に設定された時間が経過する前にワークロードが安全に処理を完了させて終了する必要があります。このベストプラクティスについては こちらのドキュメント も合わせてご参照ください。
上記は Pod レベルの話ですが、前述の通り Auto Mode ではノードの管理が自動化されており、ワークロードが稼働しているノードが Auto Mode によりシャットダウンされる可能性があります。その状況下で、ワークロードを安全に運用するにはどのようにするべきでしょうか。
大きく分けて、「Pod の安全な終了処理」と「可用性」から考えることができます。
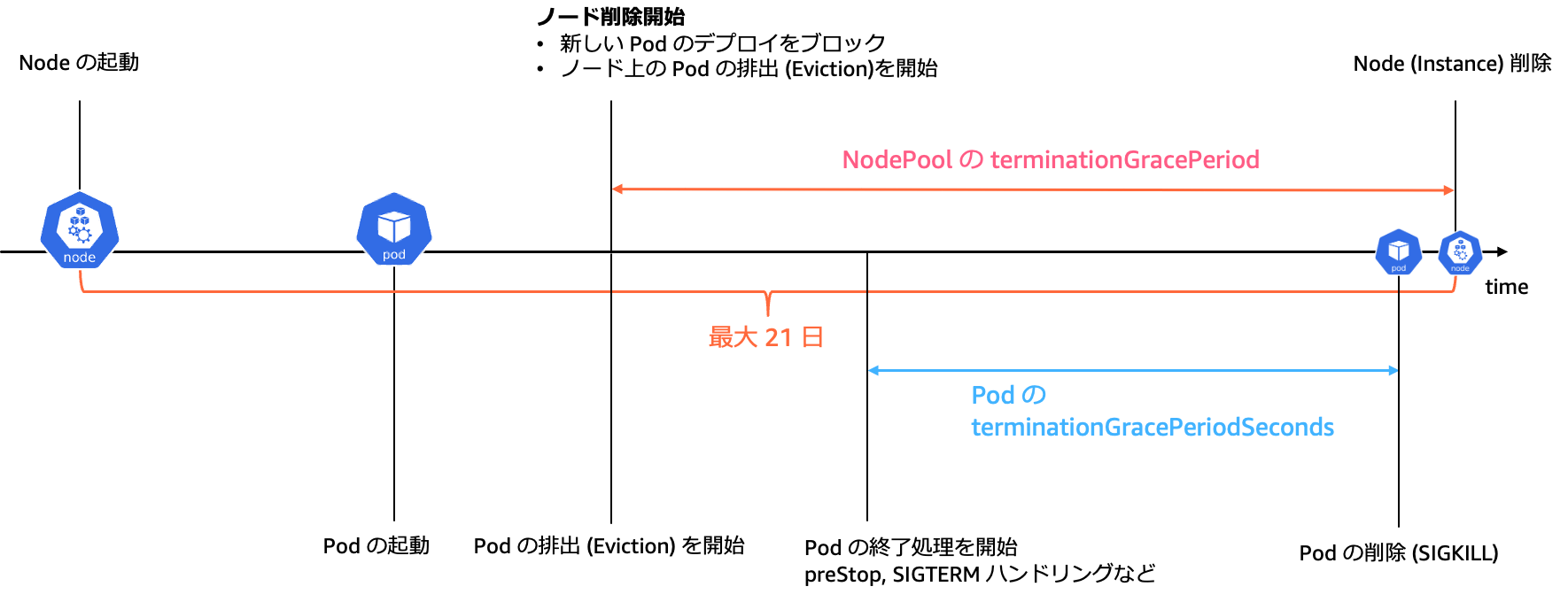
4-1. Pod の安全な終了処理
まず、「Pod の安全な終了処理」です。Auto Mode におけるノードの終了で重要な点は、
-
ノードの終了がトリガーされてから、NodePool の terminationGracePeriod に設定された時間が経過したら強制的に削除される
-
ノードに設定された expireAfter が経過したらノードの終了がトリガーされる
-
ノードの最大生存時間は 21 日間。つまり、expireAfter と terminationGracePeriod の合計値を 21 日より長く設定することはできない
という点です。
これはすなわち、Pod の terminationGracePeriodSeconds 期間内に安全に Pod が終了するという前提において、NodePool の terminationGracePeriod はノードで稼働する全ての Pod の terminationGracePeriodSeconds よりも長く設定されている必要がある、ということです。
NodePool の terminationGracePeriod が過ぎ、Auto Mode によってノードの強制終了が実行されると、Pod の設定にかかわらず Pod は強制終了されます。
Pod の安全な終了処理のプロセス図
4-2. 可用性の確保
Kubernetes においてワークロードの可用性を確保するには、Pod Disruption Budget (PDB) を活用することが重要です。PDB は、ノードの終了時にワークロードの可用性を維持するために重要な Kubernetes の仕組みです。
PDB の例
PDB を使用すると、同時に中断可能な Pod の数を制限できます。例えば、以下のような PDB を定義できます。 この設定により、app: sample-app ラベルを持つ Pod のうち、最大 1 つのみが同時に利用不可能になることを保証します。 Auto Mode は PDB の設定を尊重しながらノードを終了します。つまり、PDB 制約のもとで Pod が全て排出されてからノードを削除します。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: sample-pdb
spec:
maxUnavailable: 1
selector:
matchLabels:
app: sample-app4-3. 可用性と性能のトレードオフ
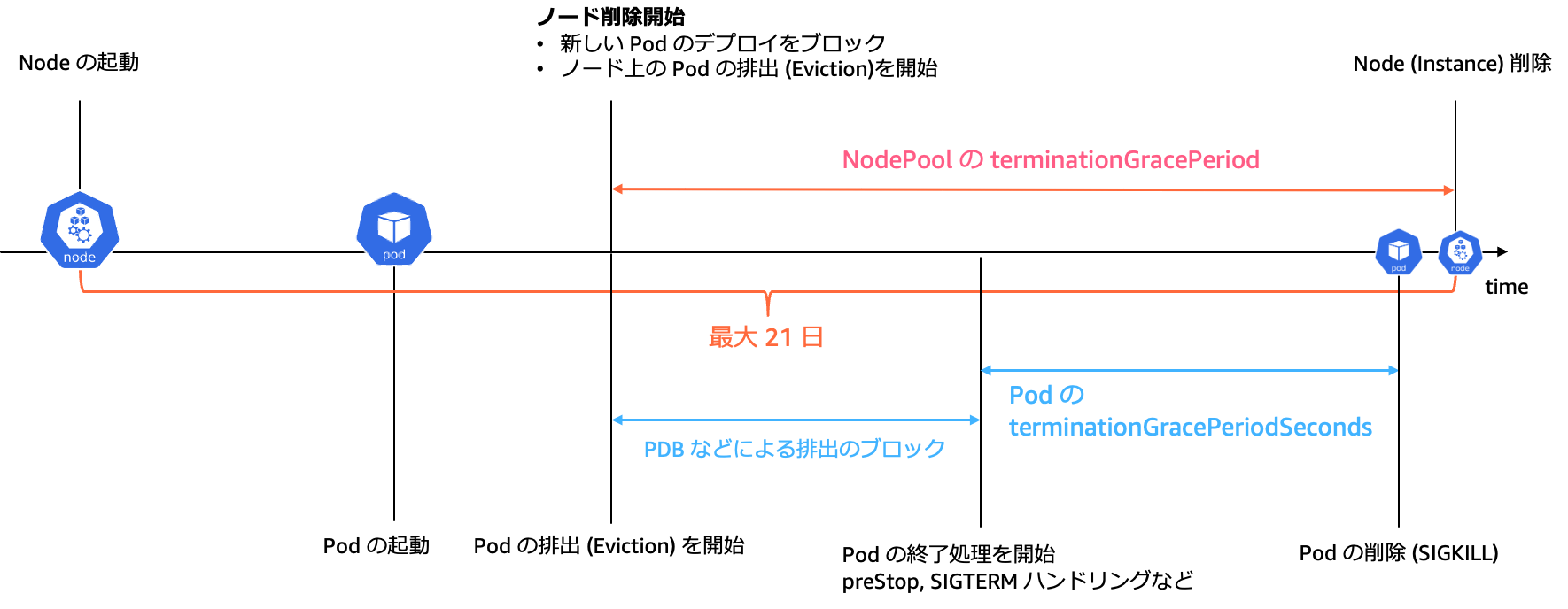
PDB を厳格に設定すると高い可用性が確保できますが、同時に Pod の終了処理の開始が遅くなります。Auto Mode においては、ワークロードの強制的な削除につながることもあります。
PDB により、Pod の終了がブロックされている間に NodePool の terminationGracePeriod が過ぎた場合、ノードとそこで稼働するPodも強制的に削除されます。特に、Pod の終了に時間がかかるワークロードでは、Pod Disruption Budget により Pod の終了にかかる時間がさらに大きくなるでしょう。NodePool のterminationGracePeriod には、PDB を考慮した値を設定する必要があります。
可用性と性能のトレードオフのプロセス図
5. ワークロードタイプ別の対応策
これまでの内容を踏まえて、いくつかの代表的な種類のワークロードで Auto Mode における中断を適切に取り扱う方法を考えてみましょう。
5-1. ステートレスな Web ワークロード
ステートレスな Web アプリケーションは、Auto Mode でもっとも容易に動かすことができるワークロードです。デフォルトの Auto Mode の設定で、Pod の終了を安全に完了できることがほとんどでしょう。
5-2. ステートフルなワークロード
ステートフルなワークロードはどうでしょうか。「ステートフル」と一言で言っても様々な定義がありますが、ここではデータベースなどの外部プロセスではなく、メモリやファイルシステムにアプリケーションの処理に必要な情報を保持しているワークロードを指します。
コンテナワークロードの一般的なベストプラクティスとして、このような情報はコンテナが終了する際にマウントしたネットワークストレージやデータベースなどの外部プロセスに保存する必要があります。
ネットワークストレージの利用という観点では、Auto Mode では、Persistent Volume を利用した Amazon EBS の利用が容易にできます。
-
Auto Mode では EBS の CSI ドライバーがビルドイン されており、Persistent Volume (PV) として Pod にマウントできる
-
Pod が終了した際にマウントされていた EBS のボリュームを、再スケジュールされた Pod でも継続して利用できる
-
EBS は Availability Zone (AZ) に属するリソースです。ノードが終了して、その上の Pod が EBS を利用していたとします。その Pod は Kubernetes により再スケジュールされますが、スケジュールされるノードは、終了したノードと同じ AZ にある必要があります。Auto Mode は、Pod が使用している PV の AZ を確認し、同じ AZ に新しいノードを起動します。そのため、Pod はノードが再作成されても、同じ EBS を継続して利用できます。
-
このような Auto Mode の性質を活用することで、ワークロードの状態をストレージに退避できます。アプリケーションが利用しているボリュームを PV としてマウントするだけでいい場合もありますが、メモリに状態を保持している場合など、SIGTERM をアプリケーションでハンドリングして状態をストレージに退避させるといった対応が必要になることもあります。
また、状態の退避に時間を要する場合、前述の「ワークロードの安全な終了方法」を参考に NodePool の terminationGracePeriod を調整する必要があるかもしれません。
5-3. 常時接続が必要な Web ワークロード
WebSocket など、常時接続が必要なアプリケーションはどうでしょうか。このようなアプリケーションでは、ノードの終了がトリガーされたとしても、接続がある間は Pod を起動し続けたいところです。
このケースでは、NodePool の terminationGracePeriod でノードが終了するまでの猶予期間を設けることができます。
たとえば、最低 24 時間は常時接続が必要だとします。この場合、terminationGracePeriod を 24 時間より長く設定します。その上で、まずアプリケーションが SIGTERM を受け取った際、新規の接続を行わないようにすると同時に、接続状態をプロセス内で監視します。24 時間経って、接続が全て完了したらプロセスを終了します。その後、terminationGracePeriod が経過した NodePool がノードを終了させます。
5-4. 実行に長時間要するバッチワークロード
バッチの中には、実行に長時間かかるワークロードもあるでしょう。例えば、実行に 36 時間必要なバッチワークロードがあるとします。Auto Mode ではノードの終了がトリガーされる直前にノードにそのバッチワークロードがスケジュールされることもあります。デフォルトでは、terminationGracePeriod は 24 時間なので、このようなケースではバッチの実行中にノードが強制終了され、実行が中断してしまいます。
この場合、terminationGracePeriod を 36 時間より長く設定することで、ノードが強制終了されるまでにバッチの処理を完了できるよう調整できます。
5-5. 21 日より長く実行する必要があるワークロード
上記の常時接続やバッチ処理においては、terminationGracePeriod を調整することで対応できました。しかし、Auto Mode では、terminationGracePeriod を無限に伸ばすことはできず、ノードの実行は最長 21 日と決まっています。したがって、21 日より長く実行する必要があるワークロードは Auto Mode では実行できません。この場合、Managed Node Group の併用を検討してください。
6. まとめ
本記事では、Amazon EKS Auto Mode におけるノードの自動更新メカニズムについて詳しく解説しました。Auto Mode は、多くのワークロードに対して運用の自動化と最適化をもたらしますが、ワークロードの特性を十分に理解し、適切な設定を行うことが成功の鍵となります。
本記事で解説した考え方や対応策を参考に、皆さんの環境に最適な Auto Mode の活用を検討いただければ幸いです。
筆者プロフィール
林 政利 (@literalice)
アマゾン ウェブ サービス ジャパン合同会社
コンテナスペシャリスト ソリューションアーキテクト
フリーランスや Web 系企業で業務システムや Web サービスの開発、インフラ運用に従事。近年はベンダーでコンテナ技術の普及に努めており、現在、AWS Japan で Amazon ECS や Amazon EKS でのコンテナ運用や開発プロセス構築を中心にソリューションアーキテクトとして活動中。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages