- Amazon Builders' Library
- 分散システムでのフォールバックの回避
分散システムでのフォールバックの回避
アーキテクチャ | レベル 300
はじめに
重大な障害が発生したサービスからは、有用な結果を得ることができなくなります。たとえば、e コマースウェブサイトでは、製品情報のデータベースクエリが失敗すると、ウェブサイトは製品ページを正常に表示できません。Amazon のサービスは、信頼性を高めるために、重大な障害の大部分を処理する必要があります。重大な障害を処理するための戦略には、大きく次の 4 つのカテゴリーに分かれます。
-
再試行:失敗したアクティビティを直ちに、または少し遅れて再度実行します。
-
プロアクティブなリトライ:アクティビティを複数回並行して実行し、最初のアクティビティを使用して終了します。
-
フェイルオーバー:エンドポイントの別のコピーに対してアクティビティを再実行するか、できれば、アクティビティの複数のコピーを並行して実行して、少なくとも1つのアクティビティが成功する可能性を高めます。
-
フォールバック:同じ結果を得るには、別のメカニズムを使用してください。
この記事では、フォールバック戦略と、Amazon でそれをほとんど使用しない理由について説明します。これは意外かもしれません。結局のところ、エンジニアはしばしば設計の出発点として現実世界を利用します。また、現実世界では、フォールバック戦略を事前に計画し、必要なときに使用する必要があります。空港の表示板が消えたとしましょう。乗客はそれでもゲートを見つける必要があるため、この状況に対処するには、緊急事態計画 (職員がホワイトボードにフライト情報を書き込むなど) を用意する必要があります。けれども、この緊急事態計画がどれほどひどいものかを考えてみてください。ホワイトボードの読みづらさ、ホワイトボードを最新の状態に保つことの難しさ、さらに人間が誤った情報を追加するリスクがあります。ホワイトボードのフォールバック戦略は必要ではあるものの、数多くの問題があります。
分散システムの世界では、フォールバック戦略は、特に時間に敏感なサービスの場合、処理が最も難しい課題の 1 つです。この困難をさらに悪化させているのは、悪いフォールバック戦略は長い時間 (何年も) 影響を残す可能性があり、良い戦略と悪い戦略の違いが微妙だということです。この記事では、フォールバック戦略が問題を修正するよりも多くの問題を引き起こす可能性があることに焦点を当てます。フォールバック戦略が Amazon で問題を引き起こしたときの具体例を含めます。最後に、Amazon で使用しているフォールバックの代替案についても説明します。
サービスのフォールバック戦略の分析は直感的ではなく、分散システムではその波及効果を予測するのは難しいため、最初に単一マシンアプリケーションのフォールバック戦略を見てみましょう。
単一マシンのフォールバック
多くのアプリケーションでメモリ割り当てエラーを処理する一般的なパターンを示す次の C コードスニペットを検討してください。このコードは、malloc() 関数を使用してメモリを割り当ててから、何らかの変換を実行しながらイメージバッファをそのメモリにコピーします。
pixel_ranges = malloc(image_size); // allocates memory
if (pixel_ranges == NULL) {
// On error, malloc returns NULL
exit(1);
}
for (i = 0; i < image_size; i++) {
pixel_ranges[i] = xform(original_image[i]);
}単一マシンのフォールバック (続き)
コードは、malloc が失敗した場合に正常に回復しません。実際には、malloc の呼び出しが失敗することはめったにないため、開発者はコードの失敗を無視することがよくあります。なぜこの戦略はそれほど一般的なのでしょうか? その理由は、単一のマシンで、malloc が失敗した場合、マシンのメモリが不足している可能性があるためです。そのため、1 つの malloc 呼び出しが失敗するよりも大きな問題があります。それは、マシンがすぐにクラッシュする可能性があることです。そしてほとんどの場合、単一のマシンでは、それが健全な推論です。多くのアプリケーションは、このような厄介な問題を解決するために努力を払うに値するほど重要ではありません。けれども、エラーを処理したい場合はどうでしょうか? そのような状況で何か有益なことをする際は、注意が必要です。メモリを異なる方法で割り当てる malloc2 と呼ばれる 2 番目のメソッドを実装し、デフォルトの malloc 実装が失敗した場合に malloc2 を呼び出すとします。
pixel_ranges = malloc(image_size);
if (pixel_ranges == NULL) {
pixel_ranges = malloc2(image_size);
}単一マシンのフォールバック (続き)
一見、このコードは動作するように見えますが、問題があり、他のコードよりも問題が明らかではありません。そもそも、フォールバックロジックをテストするのは難しいです。malloc の呼び出しをインターセプトして障害を挿入することもできますが、それは本番環境で何が起こるかを正確にシミュレートしていない恐れがあります。本番環境では、malloc が失敗した場合、マシンのメモリが不足しているか、メモリが低下していると考えられます。このより広範なメモリ問題をどのようにシミュレートしたらよいでしょうか? 低メモリ環境を生成して (たとえば Docker コンテナで) テストを実行できたとしても、malloc2 フォールバックコードの実行と一致する低メモリ状態にするのにどう調整したらよいでしょうか?
もう 1 つの問題は、フォールバック自体が失敗する可能性があることです。以前のフォールバックコードは malloc2 の失敗を処理しなかったため、プログラムはユーザーが考えているほど多くの利点を提供しませんでした。フォールバック戦略により、完全な障害が発生する可能性は低くなりますが、完全に排除できるわけではありません。Amazon では、エンジニアリングリソースを使ってプライマリ (非フォールバック) コードの信頼性を高めると、通常、使用頻度の低いフォールバック戦略に投資するよりも成功の確率が高くなることがわかりました。
さらに、可用性が最優先事項である場合、フォールバック戦略はリスクに見合う価値がない可能性があります。malloc2 が成功する可能性が高いなら、なぜ malloc について悩まなければならないのでしょうか? 論理的には、malloc2 はより高い可用性と引き換えに必然的にトレードオフを行っています。恐らく、より高いレイテンシーで、より大きな SSD ベースのストレージにメモリを割り当てます。けれども、ここで問題が提起されます、なぜ malloc2 がこのトレードオフをすることは大丈夫なのでしょうか? このフォールバック戦略で発生する可能性のある一連のイベントを考えてみましょう。まず、顧客がアプリケーションを使用しています。突然 (malloc が失敗したため)、malloc2 が起動し、アプリケーションの速度が低下します。それはいけません。速度が遅くなっても実のところ大丈夫なのでしょうか? そして、問題はそれだけではありません。マシンのメモリ不足 (またはメモリの低下) の可能性が高いことを考慮してください。顧客は現在、1 つではなく 2 つの問題 (遅いアプリケーションと遅いマシン) に直面しています。malloc2 への切り替えの副作用により、全体的な問題がさらに悪化する可能性があります。たとえば、他のサブシステムも同じ SSD ベースのストレージをめぐって競合している可能性があります。
フォールバックロジックは、システムに予期しない負荷をかけることもあります。スタックトレースを使用してエラーメッセージをログに書き込むなどの単純な一般的なロジックでさえ、表面上は無害ですが、何かが突然変化してそのエラーが高速で発生した場合、CPU にバインドされたアプリケーションが突然 I/O にバインドされたアプリケーションに変化するかもしれません。また、ディスクがその速度で書き込みを処理したり、その量のデータを保存するようにプロビジョニングされていなかった場合、アプリケーションの速度が低下したりクラッシュしたりする可能性があります。
フォールバック戦略は問題を悪化させるだけでなく、潜在的なバグとして発生する可能性もあります。 本番環境ではめったにトリガーされないフォールバック戦略を開発するのは簡単です。前述の malloc2 へのフォールバックを使用して特定のコード行をトリガーするには、ちょうど 1 人の顧客のマシンでも実際に適切なタイミングでメモリが不足するまでに数年かかるかもしれません。フォールバックロジックにバグがあるか、全体的な問題を悪化させる何らかの副作用がある場合、コードを書いたエンジニアは、そもそもそれがどのように機能したかを忘れてしまい、コードを修正するのが難しくなってしまいます。単一マシンのアプリケーションの場合、これは許容できるビジネス上のトレードオフかもしれませんが、分散システムでは、後で説明するように、結果がはるかに甚大です。
これらの問題はすべて厄介ですが、私たちの経験では、単一マシンのアプリケーションでは問題を無視できることがよくあります。最も一般的なソリューションは、前述のソリューションです。メモリ割り当てエラーにアプリケーションをクラッシュさせるだけです。メモリを割り当てるコードは、マシンの残りの部分と運命を共有します。この場合、マシンの残りの部分も失敗する可能性がかなり高くなります。運命を共有していなくても、アプリケーションは予期していなかった状態になっており、すぐに失敗するのは良い戦略です。ビジネス上のトレードオフは合理的です。
メモリ割り当てが失敗した場合に動作する必要がある重要な単一マシンアプリケーションの場合、1 つの解決策は、起動時にすべてのヒープメモリを事前に割り当て、エラー状態でも malloc に依存しないことです。Amazon はこの戦略を複数回実装しています。たとえば、本稼働サーバーで実行されるデーモンの監視や、お客様の CPU バーストを監視する Amazon Elastic Compute Cloud (Amazon EC2) デーモンがあります。
分散フォールバック
Amazon では、分散システム、特にリアルタイムで応答することを目的としたシステムに、単一マシンアプリケーションと同じトレードオフをさせません。その理由の一つは、お客様との運命の共有の欠如です。アプリケーションは、お客様の目の前にあるマシンで実行されていると想定できます。アプリケーションのメモリが不足している場合、お客様はおそらくアプリケーションが実行し続けるとは思わないでしょう。サービスはお客様が直接使用しているマシンでは実行されないため、期待は異なります。さらに、お客様は通常、単一のサーバーでアプリケーションを実行するよりも可用性が高いため、サービスを正確に使用します。そのため、お客様がそうできるようにする必要があります。理論的には、これにより、サービスの信頼性を高める方法としてフォールバックを実装することになります。残念ながら、分散フォールバックは、重大なシステム障害に関しては、すべて同じ問題かそれ以上の問題を抱えています。
分散型フォールバック戦略はテストが困難です。 サービスのフォールバックは、単一マシンのアプリケーションの場合よりも複雑です。これは、複数のマシンとダウンストリームサービスが障害に関与しているためです。過負荷シナリオなどの障害モード自体は、複数のマシンにわたるテストオーケストレーションがすぐに利用できる場合でも、テストで再現するのは困難です。また、組み合わせにより、テストするケースの数が増加するため、より多くのテストが必要になり、セットアップがはるかに難しくなります。
分散型フォールバック戦略自体は失敗する可能性があります。フォールバック戦略は成功を保証するように思えるかもしれませんが、私たちの経験では、フォールバック戦略は通常、成功の確率を向上させるだけです。
分散型フォールバック戦略は、多くの場合、障害を悪化させます。 私たちの経験では、フォールバック戦略は障害の影響範囲が拡がり、復旧にかかる時間が長くなります。
分散フォールバック戦略は、多くの場合、リスクに見合うものではありません。 malloc2 の場合と同様に、フォールバック戦略はしばしば何らかのトレードオフを伴います。それがなければ、それを常時使用しているところでしょう。何かがすでに間違っているのに、さらに悪いフォールバックを使用するのはなぜでしょうか?
分散型フォールバック戦略には、導入から数か月または数年後など、ありそうもない一連の偶然が発生した場合にのみ潜在的なバグが発生することがよくあります。
実際に Amazon の小売ウェブサイトでフォールバックメカニズムによって引き起こされた大規模な停止は、これらすべての問題を示しています。停止は 2001 年頃に発生しました。原因は、ウェブサイトに表示されるすべての製品の最新の配送速度を提供する新しい機能にありました。
新しい機能は次のようなものです。

そこで、各 Web サーバーで個別のプロセスとして実行されるキャッシュレイヤーを追加しました。
当時、ウェブサイトのアーキテクチャには 2 つの層しかなく、このデータはサプライチェーンデータベースに格納されていたため、ウェブサーバーはデータベースに直接クエリを実行する必要がありました。しかし、データベースはウェブサイトからのリクエスト量に対応できませんでした。このウェブサイトには大量のトラフィックがあり、一部のページには 25 以上の製品が表示され、各製品の配送速度がインラインで表示されました。そこで、各ウェブサーバーで個別のプロセスとして実行されるキャッシュレイヤーを追加しました (Memcached に似ています)。
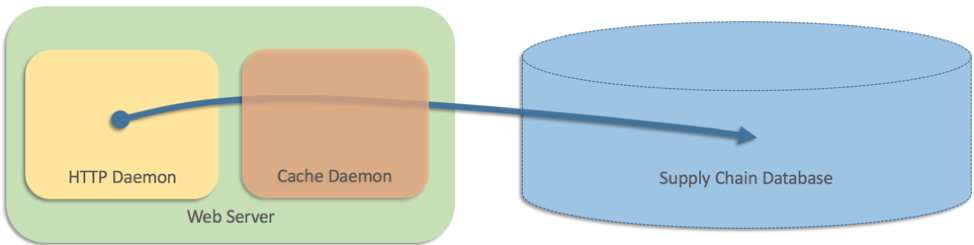
擬似コードでは、次のようなものを書きました。
これはうまく機能しましたが、チームはキャッシュ (別のプロセス) が何らかの理由で失敗した場合の処理も試みました。このシナリオでは、ウェブサーバーはデータベースの直接クエリに戻りました。擬似コードでは、次のように記述しました。直接データベースクエリに戻るのは、何ヶ月も機能した直感的な解決策でした。しかし、最終的にはすべてのキャッシュがほぼ同時に失敗したため、すべてのウェブサーバーがデータベースに直接アクセスしました。これにより、データベースを完全にロックするのに十分な負荷が発生しました。データベースですべてのウェブサーバープロセスがブロックされたため、ウェブサイト全体がダウンしました。このサプライチェーンデータベースはフルフィルメントセンターにとっても重要だったため、停電はさらに拡大し、問題が修正されるまで世界中のすべてのフルフィルメントセンターが停止しました。単一マシンのケースで見られた問題はすべて、分散型のケースでも発生し、より悲惨な結果をもたらしました。分散フォールバックのケースをテストするのは困難でした。キャッシュ障害をシミュレートしたとしても、トリガーするには複数のマシンで障害が発生するという問題は見つかりませんでした。そしてこのケースでは、フォールバック戦略自体が問題を増幅させ、フォールバック戦略がまったくない場合よりも悪い結果になりました。フォールバックにより、ウェブサイトの一部停止(配送速度を表示できない)がサイト全体の停止(ページがまったく読み込まれない)に変わり、バックエンドのAmazonフルフィルメントネットワーク全体が停止しました。この場合のフォールバック戦略の背後にある考え方は非論理的でした。データベースを直接ヒットする方がキャッシュを通過するよりも信頼性が高い場合、そもそもなぜキャッシュについて悩まなければならないのでしょうか? キャッシュを使用しないとデータベースに過負荷がかかるのではないかと心配しましたが、フォールバックコードが非常に有害である可能性が高いなら、それをわざわざ備えるのはなぜでしょうか? 早い段階でエラーに気づいたかもしれませんが、バグは潜在的なもので、停止の原因となった状況はリリースから数か月後に現れました。
if (cache_healthy) {
shipping_speed = get_speed_via_cache(sku);
} else {
shipping_speed = get_speed_from_database(sku);
}Amazon がフォールバックを回避する方法
分散フォールバックで遭遇したこれらの落とし穴を考え、Amazon は今ではほとんど常にフォールバックに代わる代替手段を選好しています。以下、その概要を説明します。
非フォールバックケースの信頼性を向上させる
前述のように、フォールバック戦略は完全な失敗の可能性を減らすだけです。メイン (フォールバックではない) コードをより堅牢にすれば、サービスの可用性が高まります。たとえば、2 つの異なるデータストア間にフォールバックロジックを実装する代わりに、チームは Amazon DynamoDB などの固有の可用性の高いデータベースの使用に投資できます。この戦略は、Amazon 全体で頻繁に使用され成功を収めています。たとえば、このトークでは、2017 年のプライムデーに DynamoDB を使用して amazon.com を強化する方法について説明します。
発信者にエラーを処理させる
重大なシステム障害の解決策の 1 つは、フォールバックするのではなく、呼び出しシステムに障害を処理させるようにすることです (たとえば、再試行することによって)。これは、CLI と SDK にリトライロジックがすでに組み込まれている AWS のサービスの推奨戦略です。Amazon は、可能な場合、特に運命を共有し、主要なケースが失敗する可能性を減らすために十分な努力が注がれている状況において、この戦略を選好しています (そしてフォールバックロジックが可用性を改善する可能性は非常に低いでしょう)。
データを積極的にプッシュする
フォールバックする必要がないようにするために使用するもう 1 つの方法は、要求に応答するときに可動部の数を減らすことです。たとえば、サービスが要求を満たすためにデータを必要とし、そのデータがすでにローカルに存在する場合 (フェッチする必要はありません)、フェイルオーバー戦略は必要ありません。その成功例として、 Amazon EC2 の AWS アイデンティティおよびアクセス管理 (IAM) ロールの実装があります。IAM サービスでは、EC2 インスタンスで実行されているコードに署名し、ローテーションされた認証情報を提供する必要があります。フォールバックする必要性を回避するために、認証情報はすべてのインスタンスに積極的にプッシュされ、何時間も有効なままになります。これは、IAM ロールに関連するリクエストが、プッシュメカニズムの混乱という万が一のイベントでも機能し続けていることを意味します。
フォールバックをフェイルオーバーに変換する
フォールバックで最悪のことの 1 つは、定期的に実行されず、停止中にトリガーされたときに失敗するか、影響範囲が拡大する可能性があることです。フォールバックをトリガーする状況は、自然に発生するのに数か月または数年もかかる場合もあります。 フォールバック戦略の潜在的な障害の問題に対処するには、本番環境で定期的に実行することが重要です。サービスは、フォールバックロジックと非フォールバックロジックの両方を連続して実行する必要があります。フォールバックケースを実行するだけでなく、同等に有効なデータソースとして扱う必要があります。たとえば、サービスは、フォールバック応答と非フォールバック応答の両方をランダムに選択して (両方が戻ってきた場合)、両方が機能していることを確認します。ただし、この時点では、戦略をフォールバックと見なすことはできなくなり、フェイルオーバーのカテゴリにしっかりと分類されます。
再試行とタイムアウトがフォールバックにならないようにする
再試行とタイムアウトについては、「タイムアウト、リトライ、およびジッターによるバックオフ」の記事で説明されています。この記事では、再試行は、一時的なエラーやランダムなエラーに直面した場合に、高可用性を実現するための強力なメカニズムであると述べています。言い換えれば、再試行とタイムアウトは、偽りのパケット損失、無相関の単一マシン障害などの軽微な問題による偶発的な障害に対する保証を提供します。ただし、再試行とタイムアウトは間違えやすく、多くの場合、サービスは何度も再試行する必要なく数か月以上継続して提供されます。これは、チームがテストしたことのないシナリオで最終的に奏功する可能性があります。このため、Amazon では全体的な再試行率を監視するメトリクスと、再試行が頻繁に発生した場合にチームに警告するアラームを維持しています。
再試行がフォールバックにならないようにするもう 1 つの方法は、プロアクティブな再試行 (ヘッジまたはパラレルリクエストとも呼ばれます) を使用して常に実行することです。この手法は、クォーラムの読み取りまたは書き込みを実行するシステムに本質的に組み込まれています。ここでは、システムは、応答するために 3 つのうち 2 つのサーバーからの応答を必要とする可能性があります。プロアクティブな再試行は、絶え間ない作業の設計パターンに従います。冗長な要求は常に行われているため、冗長な要求の必要性が増すにつれて、再試行による余分な負荷がシステムに加わることはありません。
まとめ
Amazon では、証明するのが難しく、その有効性をテストするのが難しいため、システムのフォールバックを避けています。フォールバック戦略では、物事が壊れ始める最も混沌とした瞬間にのみシステムが入る操作モードを導入しており、このモードへの切り替えはカオスを増大させるだけです。多くの場合、フォールバック戦略が実装されてから本番環境で発生するまでに長い遅延があります。
代わりに、本番環境でまれにではなく継続的に実行されるコードパスを優先します。Amazon では、重要な時間にリモートコールのプルや障害のリスクを回避するのではなく、データを必要とするシステムにデータをプッシュするなどのパターンを使用して、プライマリシステムの可用性を向上させることに焦点を当てています。最後に、コード内の微妙な振る舞いに注意します。この振る舞いは、あまりにも多くの再試行を実行するなど、フォールバックのような動作モードに切り替わる可能性があります。
システムでフォールバックが不可欠な場合、本番環境で可能な限り頻繁にフォールバックを実行することで、フォールバックが主要な動作モードと同じくらい信頼性が高く予測どおりに動作するようにします。
著者について
Jacob Gabrielson は、アマゾン ウェブ サービスのシニアプリンシパルエンジニアです。彼は、Amazon に入社して 17 年になり、主に社内のマイクロサービスプラットフォームで勤務しています。過去 8 年間、彼はソフトウェアデプロイシステム、コントロールプレーンサービス、スポット市場、Lightsail、そして最近ではコンテナを含む、EC2 と ECS に取り組んでいます。Jacob の情熱は、システムプログラミング、プログラミング言語、および分散コンピューティングです。彼が最も嫌うのは、特に障害状態でのバイモーダルシステムの挙動です。彼はシアトルのワシントン大学でコンピューターサイエンスの学士号を取得しました。
