運用の可視性を高めるダッシュボードの構築
ソフトウェアの配信と運用 | レベル 300
はじめに
私たちは皆、ノートパソコン、タブレット、スマートフォンでアプリケーションを実行しています。デバイスに電源が入っているかどうか、Wi-Fi ネットワークが接続されているか、簡単に確認できます。画面には、空き容量不足の警告といった重要な通知が表示されます。実際に、ユーザーインターフェイス (UI) の全般的な速度や応答性は、アプリケーションにメモリや CPU などの十分なリソースがデバイスにあるかどうかを示す良い指標となります。
家族をリモートで技術的に手助けしたことのある人なら誰でも、デバイスを見ながら直接操作できないと、問題の検出や診断が少々難しいことをご存知でしょう。クラウドベースのサービスを実行する場合、同様の問題に直面します。これらのリモートサービスをどうモニタリングすればいいか? お客様が満足しているかを確認するにはどうすればよいか?
単一ホストサービスを監視するには、そのホストにログオンし、さまざまなランタイムモニタリングツールを実行し、ログを検査することで、ホストで発生している問題の根本的な原因を特定します。しかし、単一ホストソリューションは、最も単純で重要でないサービスでしか実行できません。もう 1 つの極端な例に、多層の分散型マイクロサービスが挙げられます。これは、数百または数千のサーバー、コンテナ、またはサーバーレス環境で実行するサービスです。
Amazon は、世界中にある数多くのリージョンの複数のアベイラビリティーゾーンで実行しているすべてのクラウドベースのサービスが、実際にどのように動作しているかをどうやって確認しているのでしょうか? 自動モニタリング、自動修復ワークフロー(トラフィックのシフトなど)、自動デプロイシステムは、このような大規模での多くの問題を検出し、解決するために重要です。ただし、さまざまな理由で、これらのサービス、ワークフロー、デプロイが何をしているのかをいつでも確認できる必要があります。
Amazon におけるダッシュボードの意義
Amazon ではダッシュボードを 1 つの機構として使用し、クラウドサービスで行われる処理を常に把握するという課題に対処しています。ダッシュボードはシステムを人間が理解できるかたちで表示し、時系列メトリクス、ログ、トレース、アラームデータを示して、システム動作の簡潔な概要を提供します。
Amazon では、これらのダッシュボードの作成、使用、継続的な管理を行うことをダッシュボード化と呼んでいます。ダッシュボード化は、最優先のアクティビティへと進化してきました。私たちのサービスを加速させるには、サービスの設計、コーディング、構築、テスト、デプロイ、スケーリングなどの他の日常的なソフトウェア配信や運用上の処理と同じくらい、ダッシュボード化は重要であるからです。
もちろん、オペレーターが常にダッシュボードをモニタリングすることはありません。ほとんどの場合、誰もこれらのダッシュボードを見ることはありません。実際に、ダッシュボードのレビュー頻度に関係なく、手動によるダッシュボードの確認を要する運用処理は、人為的エラーのためにうまく行かないことがわかっています。このようなリスクに対処するため、システムが発信する最も重要なモニタリングデータを常に評価する自動アラームを作成しました。通常ではこれらは、システムが何らかの制限に近づいている(影響が出る前の事前検出)、あるいはシステムが予期しない方法ですでに障害が出ている(影響が出た後の反応検出)のいずれかを示すメトリクスです。
これらのアラームは、自動修復ワークフローを実行し、問題があることをオペレーターに通知できます。オペレーターは通知によって、使用する必要がある正確なダッシュボードと Runbook に移動します。待機中にアラーム通知が問題を警告した場合、関連するダッシュボードをすばやく使用することで、お客様への影響を定量化し、根本原因を検証またはトリアージし、軽減して、復旧までの時間を短縮できます。アラームがすでに自動修復ワークフローを開始している場合でも、自動ワークフローが何をしているか、システムにどのような影響があるかを確認し、例外的な状況では、安全性が必要となる手順を人間が確認してワークフローを進めます。
イベントが進行中の場合、Amazon は通常、複数の待機オペレーターを利用します。オペレーターは、一連のタスクを順番に実行していく際に、異なるダッシュボードを使用していることがあります。これらのタスクには通常、お客様への影響の定量化、トリアージ、イベントの根本原因までの複数のサービス全体の追跡、自動修復ワークフローの監視、Runbook ベースの軽減手順の実行と検証が含まれます。その間に、ピアチームやビジネス関係者もダッシュボードを使用して、イベント中に進行している影響をモニタリングします。こうしたさまざまな関係者は、インシデント管理ツール、チャットルーム(AWS Chatbot などのボットを使用)、電話会議を通してやり取りします。各関係者は、ダッシュボードに表示されるデータを異なる視点から見ています。
Amazon のチームとさまざまな組織との間で、上級リーダー、マネージャー、多くのエンジニアが参加する運用レビュー会議も毎週実施しています。これらの会議では、一種のルーレット盤を使用し、上位のレベルから監査ダッシュボードを選択します。関係者は、お客様の体験や、可用性や待ち時間などの主要なサービスレベル目標を確認します。これらの関係者が使用する監査ダッシュボードは通常、すべてのアベイラビリティーゾーンとリージョンの運用データを表示します。
さらに、長期的なキャパシティの計画と予測を行う場合、Amazon はダッシュボードを使って、システムがより長い時間間隔で出力する最高レベルでのビジネス、使用状況、キャパシティのメトリクスを視覚化します。
ダッシュボードの種類
ダッシュボードを使用してサービスを手動でモニタリングしていますが、1 つのサイズですべてのユースケースに対応できるわけではありません。ほとんどのシステムでは多数のダッシュボードを使用し、各ダッシュボードが異なる視点からシステムの確認を行っています。こうしたいろんな角度から確認することで、ユーザーは、さまざまな視点から、さまざまな時間間隔で、システムがどのように動作しているかを把握できます。
それぞれのユーザーが見たいデータは、ダッシュボードによって大きく異なります。ダッシュボードを設計する際に、対象者に注目する重要性を学びました。ダッシュボードを使用するユーザー、およびダッシュボードを使用する理由に基づいて、各ダッシュボードに送信するデータを決定します。Amazon は顧客志向であると聞いたことがあるかもしれません。ダッシュボードの作成は、これをよく表しています。ユーザーが期待するニーズとその特定の要件に基づいて、ダッシュボードを作成します。
次の図は、さまざまなダッシュボードがシステム全体に対してどのようにさまざまなビューを提供するかを示しています:
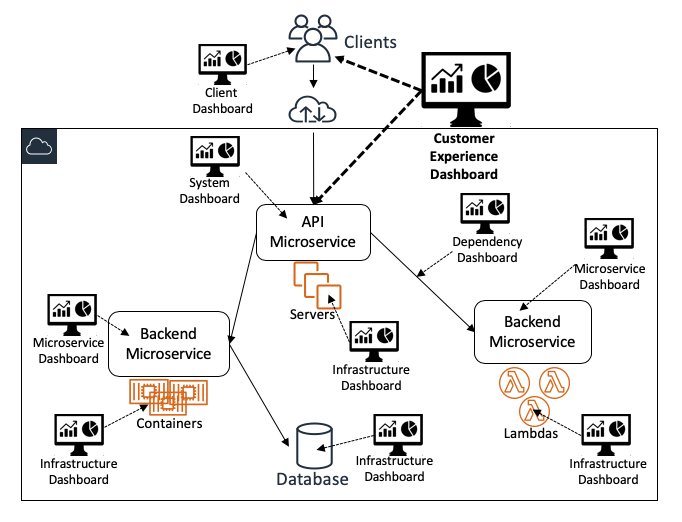
上位レベルのダッシュボード
カスタマーエクスペリエンスダッシュボード
Amazon で最も重要かつ広く使用されているダッシュボードは、カスタマーエクスペリエンスダッシュボードです。これらのダッシュボードは、サービスオペレーターや他の多くの関係者を含む幅広いユーザーグループが使用できるように設計されており、全体的なサービスの健全性や目標の順守に関するメトリクスを効率的に提示します。これらのダッシュボードは、サービス自体にとどまらず、クライアントインストルメンテーション、継続的テスター (Amazon CloudWatch Synthetics Canaries など)、自動修復システムからも供給されるモニタリングデータを表示します。これらのダッシュボードには、ユーザーが知りたい影響の深さや広がりについて知るのに役立つデータも含まれています。「影響を受ける顧客の数は?」、 「どの顧客が最も影響を受けるか?」といった疑問に答えます。
システムレベルでのダッシュボード
通常、UI と API エンドポイントがウェブベースのサービスへのエントリポイントであるため、専用のシステムレベルのダッシュボードには、オペレーターがシステムとその顧客向けエンドポイントの動作を確認するのに十分なデータを含んでいる必要があります。これらのダッシュボードには、主にインターフェイスレベルのモニタリングデータが表示されます。これらのダッシュボードには、各 API のモニタリングデータの 3 つのカテゴリが表示されます。
- 入力関連のモニタリングデータ。これには、キュー/ストリームから受信したリクエストまたはポーリングされた作業の数、リクエストのバイトサイズでのパーセンタイル、認証/承認の失敗数が含まれます。
- 処理関連のモニタリングデータ。これには、マルチモーダルビジネスロジックパス/ブランチ実行数、バックエンドマイクロサービスリクエスト数/失敗/レイテンシパーセンタイル、障害およびエラーのログ出力、リクエストトレースデータが含まれます。
- 出力関連のモニタリングデータ。これには、応答タイプ数(顧客によるエラー/障害応答の詳細を含む)、応答のサイズ、書き込み時間の最初の応答バイトと書き込み時間の完全応答のパーセンタイルが含まれます。
全般に、これらのカスタマーエクスペリエンスとシステムレベルのダッシュボードを、できるだけ高いレベルに保つことを目指しています。情報の過負荷は、これらのダッシュボードが伝える必要のある重要なメッセージを妨げる可能性があるため、これらのダッシュボードにはメトリクスを追加しすぎないようにしています。
サービスインスタンスダッシュボード
ダッシュボードをいくつか作成して、単一のサービスインスタンス(パーティションまたはセル)内のカスタマーエクスペリエンスを迅速かつ包括的に評価できるようにしています。この絞り込まれたビューにより、単一のサービスインスタンスで作業するオペレーターが、他のサービスインスタンスからの関係のないデータのせいで過負荷になることはありません。
サービス監査ダッシュボード
すべてのアベイラビリティーゾーンとリージョン全体で、あらゆるサービスのインスタンスのデータを意図的に表示するカスタマーエクスペリエンスダッシュボードも構築します。オペレーターはこれらのサービス監査ダッシュボードを使用して、すべてのサービスインスタンスの自動アラームを監査します。これらのアラームは、前述の毎週の運用会議中にも確認できます。
キャパシティプランニングと予測ダッシュボード
長期的なユースケースでは、キャパシティプランニングと予測のためのダッシュボードを作成して、サービスの成長を視覚化することもできます。
低レベルのダッシュボード
通常、バックエンドマイクロサービス全体でリクエストを調整して、Amazon API を実装します。これらのマイクロサービスは異なるチームが所有でき、各チームがリクエストに関する特定の処理を担当します。たとえば、一部のマイクロサービスは、リクエストの認証と承認、スロットル/制限の実施、使用状況の測定、リソースの作成/更新/削除、データストアからのリソースの取得、非同期ワークフローの開始に特化しています。通常、チームは少なくとも 1 つの専用マイクロサービスに特化したダッシュボードを作成します。このダッシュボードには、各 API のメトリクス、または作業単位(サービスがデータを非同期で処理している場合)が表示されます。
マイクロサービス固有のダッシュボード
マイクロサービスのダッシュボードは通常、サービスの深い知識を必要とする実装に特化したモニタリングデータを表示します。主にサービスを所有するチームが、これらのダッシュボードを使用します。ただし、Amazon のサービスは高度に計測されており、この計測から来るデータでオペレーターが圧倒されないようにデータを提示する必要があります。このため、これらのダッシュボードには通常、一部のデータが集計形式で表示されます。オペレーターは、集約されたデータの異常を特定すると、通常、他のいろいろなツールを使ってさらに深く掘り下げ、基礎となるモニタリングデータに対してアドホッククエリを実行し、データの集約、リクエストのトレース、関連するまたは相関するデータの開示を行います。
インフラストラクチャダッシュボード
私たちのサービスは、通常、メトリクスを発行する AWS インフラストラクチャで実行するため、専用のインフラストラクチャダッシュボードも用意しています。これらのダッシュボードは、Amazon Elastic Compute Cloud (EC2) インスタンス、Amazon Elastic Container Service (ECS)/Amazon Elastic Kubernetes Service (EKS) コンテナ、AWS Lambda 関数など、システムが実行するコンピューティングリソースが生成するメトリクスに主に焦点を当てています。CPU 使用率、ネットワークトラフィック、ディスク IO、スペース使用率などのメトリクスは、これらのコンピューティングリソースに関連するすべての関連クラスター、Auto Scaling、クォータメトリクスとともに、これらのダッシュボードで一般的に使用されます。
依存関係ダッシュボード
マイクロサービスは、コンピューティングリソースだけでなく他のマイクロサービスにも依存していることがよくあります。これらの依存関係を所有するチームがすでに独自のダッシュボードを持っている場合でも、各マイクロサービスの所有者は通常、専用の依存関係ダッシュボードを作成して、上流の依存関係(プロキシやロードバランサーなど)と下流の依存関係(データストア、キュー、ストリームなど)の両方がどのように動作しているかの情報(これらのサービスが測定したもの)を表示します。また、これらのダッシュボードは、セキュリティ証明書の有効期限やその他の依存関係クォータの使用状況など、その他の重要なメトリクスを追跡するためにも使用できます。
ダッシュボードの設計
Amazon では、良質なダッシュボードを設計するためには、データの表現に一貫性を持たせることが重要だと認識しています。効果を発揮させるためには、個別のダッシュボードだけでなく、すべてのダッシュボードにおいて、一貫性を実現する必要があります。当社では何年にもわたり、デザインの組合せや構成を、共通なパターンとして特定、適合、改良し続けてきました。それは、最大限に広範な利用者がアクセスできるダッシュボードを提供することで、最終的には当社の企業価値の向上につながると考えているからです。また、これまでの間に、こういったデザイン上の様式を、細かに評価し改善するための手法も獲得してきています。たとえば、新しい利用者がダッシュボードに表示されているデータを素早く理解して使いこなして、そのサービスの仕組みを学ぶことがでれば、そのダッシュボードが正しい情報を適切に表現していることを意味します。
ダッシュボードを設計する時によくある傾向の 1 つとして、ターゲットユーザーの分野の知識を過大評価または過小評価してしまうことがあります。ダッシュボードを、その作成者のセンスに完全に合わせて構築することは簡単です。しかしながら、そのダッシュボードが、ユーザーに価値を提供できるものになるとは限りません。当社では、こういったリスクを排除するために、お客様側の意向を重視しながら作業をすすめるという手法を取っています。
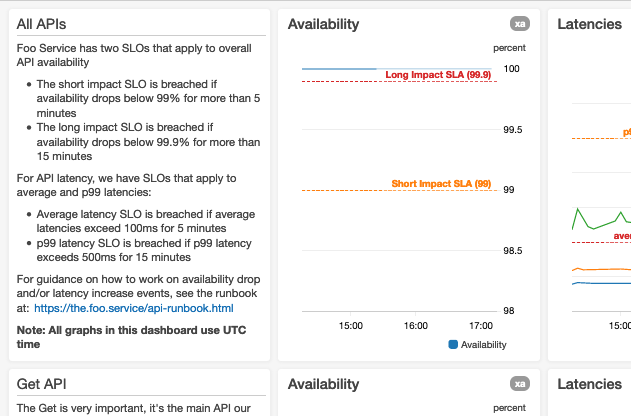
当社は現在までに、ダッシュボードにおけるデータのレイアウトを標準化する、デザイン様式を取り入れてきています。ダッシュボードは、上から下に描画されるものです。そして、ユーザーには、初期(ダッシュボードのローディング時)に表示されるグラフが、最も重要性が高いものと解釈される傾向があります。したがって、当社のデザイン様式では、最重要なデータを、ダッシュボードの最上部に配置することが奨励されています。可用性について集約/要約されたグラフや、エンドツーエンドのレイテンシーをパーセンタイルで表すグラフは、一般的にウェブサービスにとっては、最重要なダッシュボードであることが分かっています。
ここに示すスクリーンショットは、仮想的な Foo という名のサービスに関する、ダッシュボードの最上段を表しています:
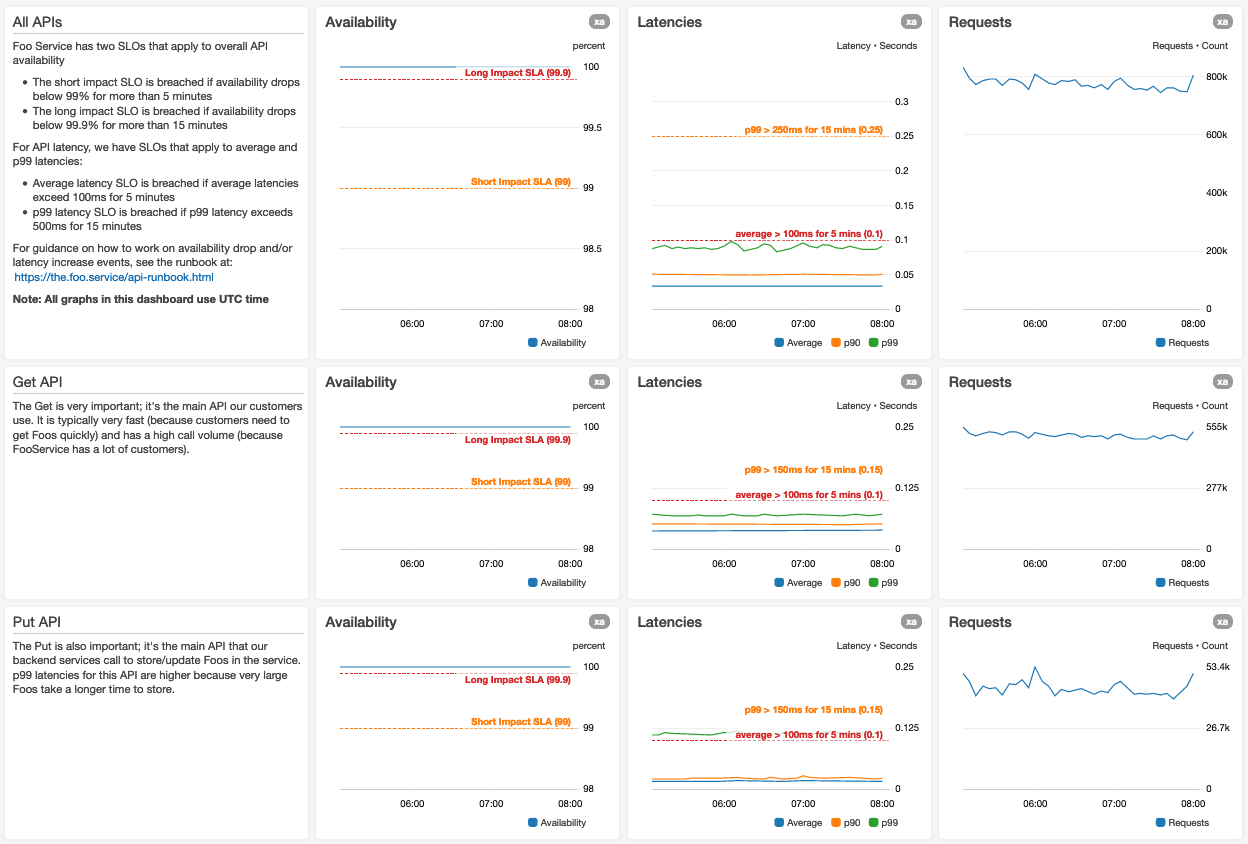
当社では、最重要なメトリクスには、大きなグラフを使用します
1 つのグラフに多くのメトリクスが含まれる場合、凡例的なグラフでは、データを縦方向にも横方向にも圧縮して表示するようなことはありません。グラフ内で検索クエリが使用されている場合には、その結果となるメトリクスを、普通のものより大きくできるようにしています。
グラフのレイアウトは、想定できる最小の表示解像度に合わせます
これによりユーザーは、横方向にスクロールする必要がなくなります。ノートパソコンを使い午前 3 時に電話をかけたオペレーターが、右側にもっとグラフがあることに気付かない限り 横方向のスクロールバーがあることにも気付かないでしょう。
タイムゾーンを表示します
日付と時間データを表示するダッシュボードの場合は、必ず、関連するタイムゾーンが視認できるようにしています。異なるタイムゾーンにいるオペレーターが同時に使用するダッシュボードでは、全員に関係がある 1 つのタイムゾーン(UTC)を、デフォルトで表示しています。この手法により、各ユーザーが単一のタイムゾーンを使用してコミュニケーションすることができ、それぞれが頭の中でタイムゾーンを切り替えるための、余計な時間と労力が節約できます。
最小の時間間隔とデータポイントピリオドを使用します
時間間隔とデータポイント期間は、最も一般的なユースケースにおいて妥当な値をデフォルトにしています。ダッシュボードのすべてのグラフは、初期状態では必ず、同一の時間幅と分解能でデータ表示を行います。ダッシュボードにおいて、1 つのセクションにあるすべてのグラフが、共通の横サイズを持つことのメリットを認識しているからです。これにより、グラフ間での時間的な相互関係を、容易に表すことが可能になります。
また、ダッシュボードのローディング時間が遅くならないよう、グラフ上で過多なデータポイントをプロットすることも避けています。加えて、実際のところ、過剰なデータポイントを表示することで、ユーザーが異常値を視認しにくくなるケースも存在します。たとえば、時間分解能が 1 分のデータポイントを 3 時間分、メトリクスごとに 180 個の値を表示するグラフであれば、小型のダッシュボードウィジェットでも明瞭に描画できます。データポイントがこのような数であれば、運用作業を選別しながら進行しているオペレーターに対しても、十分な情報を提供することができます。
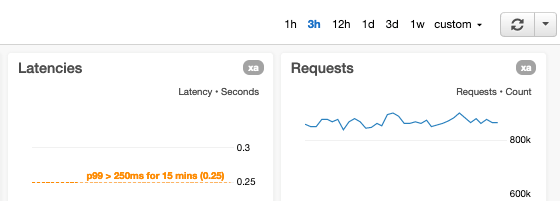
時間間隔とメトリクス期間は調整可能にしています
当社のダッシュボードでは、時間間隔とメトリクス期間の両方を、すばやく調整できる制御機能を提供しています。ダッシュボードで使用している、x 方向の一般的な解像度には、次のものがあります。
- 1 時間 x 1 分単位(60 個のデータポイント)– 実行中のイベントを監視するための拡大表示向き
- 12 時間 x 1 分単位(720 個のデータポイント)
- 1 日間 x 5 分単位(288 個のデータポイント)– 日次トレンドの表示向き
- 3 日間 x 5 分単位(864 個のデータポイント)
- 1 週間 x 1 時間単位(168 個のデータポイント)– 週次トレンドの表示向き
- 1 か月間 x 1 時間単位(744 個のデータポイント)
- 3 か月間 x 1 日単位(90 個のデータポイント)– 四半期のトレンド表示向き
- 9 か月間 x 1 日単位(270 個のデータポイント)
- 15 か月 x 1 日単位 (450 個のデータポイント) – 長期的なキャパシティの確認向き
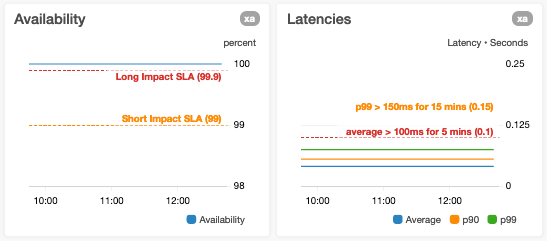
グラフにはアラームしきい値で注釈を付けます
自動的なアラームがあるメトリクスをグラフ表示する場合、そのアラームのしきい値が静的であるなら、グラフには水平ラインでの注釈を表示します。人工知能(AI)や機械学習(ML)を使用し生成された予測や推定に基づいていて、アラームのしきい値が動的である場合には、同一のグラフ内に実際の値としきい値、両方のメトリクスを表示します。既知の制限(テスト済み最大値、もしくはハードリソースの上限など)を持つサービスで、1 側面を測定するメトリクスを表示するグラフでは、既知の、もしくはテスト済みの制限がどこかを示す水平ラインにより、注釈を表示しています。ゴールがあるメトリクスの場合には、そのゴールをユーザーがすぐに視認できるよう、水平ラインを追加して表示します。
左と右の両方の y 軸をすでに表示しているグラフ上では、水平ラインを追加表示しません。
このようなグラフで水平ラインを表示すると、どちらの y 軸がそのラインと関係しているかを、ユーザーが理解しづらくなるからです。このような場合、曖昧さを避けるためにグラフを 2 つに分割して表示します。各グラフでは水平軸を 1 つのみ使用し、適切なグラフに対してのみ、水平ラインを追加表示しています。
値の範囲が大きく異なる複数のメトリクスでは、y 軸が過剰にローディングされないようにします
1 つ以上のメトリクスで相違点の視認性を落とすことにならないよう、こういったシチュエーションを避けるようにしています。これは例えば、p0 (最小) と p100 (最大) のレイテンシーを同一のグラフに表示する場合があたります。このグラフでは、p100 のデータポイントでの値は、p0 のものより数桁分大きくなり得ます。
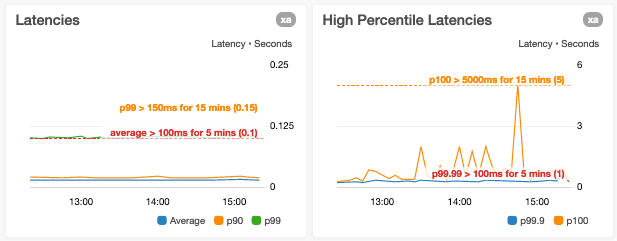
y 軸の境界を現在のデータポイントの値の範囲のみに縮小することには注意が必要です
データポイントの値に範囲が限られた y 軸を使用しているグラフは、大まかに見ることができ、メトリクスの変化を実際より認識しやすくできます。
単一グラフの過剰なローディングを避けています
1 つのグラフにおいて、統計情報を過多に表示したり、関連のないメトリクスを表示することがないようにしています。たとえば、リクエスト処理のためのグラフを追加する場合、通常は、次に示すようなダッシュボードにおいて、分割した適切なグラフを作成しています。
- 可用性 %(障害/リクエスト × 100)
- p10、平均、p90 レイテンシー
- p99.9 および最大(p100)レイテンシー
各メトリクスもしくはウィジェットの真の意味を、ユーザーが理解していることは前提にしていません
これは特に、実装に特化したメトリクスの場合に当てはまります。ダッシュボードのテキスト表示には、十分な情報を提供するようにします。たとえば、グラフの横や下に、説明分を表示するようにしています。オペレーターは、このテキストを読むことで、メトリクスの意味を理解できます。それによりオペレーターは、「正常」な状態がどのように見えるか、そして、グラフが「正常」ではない場合にどのような意味を持つのかを、解釈できるようになります。 このテキスト分には、オペレーターが根本原因を判断する際に使用できる、関連リソースへのリンクを含めています。次に、このリンクの事例をいくつか示します。
- ランブックへのリンク。各分野のエキスパートは、ダッシュボードをランブックとして使用できます。
- 「詳細検証」ダッシュボードへのリンク。
- 異なるクラスターもしくはパーティションでの、同等なダッシュボードへのリンク。
- デプロイパイプラインへのリンク。
- 依存関係の連絡先情報。
適切な場合には、アラームのステータス、単純な数値、および/または時系列グラフのウィジェットを活用します
ダッシュボードのユースケースによっては、ウィジェットで単一の数値 (メトリクスにおける最新の値など) やアラームステータスを表示する方が、最近のデータポイントに関する複雑な時系列グラフを表示するより適切な場合があります。

データが疎なメトリクスを表示するグラフに依拠しないようにします
希薄なメトリクスとは、特定のエラー状態がある場合にのみ、生成されるメトリクスのことです。必要な場合にのみこれらのメトリクスを生成するため、機器サービスにとっては有効なものですが、ダッシュボードのユーザーにとっては、空白もしくはほとんど値のないグラフは混乱を招きやすいものです。通常、ダッシュボードの設計中にこのようなメトリクスが表れた場合、エラー状況が発生しない限りは安全な値(つまりゼロ)を継続的にメトリクスとして出力するように、そのサービスを修正しています。これにより、サービスからのデータの欠落にはテレメトリーを正確に出力していないという意味が含まれることを、オペレーターが容易に理解できるようになります。
モードごとのメトリクス表示のためのグラフを追加します
これは、システム内での複数モデルの動作を収集したメトリクスを、グラフ表示する場合に行われます。これを行う可能性のある状況には、次が含まれます。
- 可変サイズのリクエストをサポートするサービスでは、リクエスト全体でのレイテンシーを示すグラフを作成する場合があります。さらに、小規模、中規模、そして大規模のリクエストに関するメトリクスを表示するグラフも、作成することがあります。
- サービスが入力パラメータの値 (または組み合わせ) に応じてさまざまな方法でリクエストを実行する場合、各実行モードをキャプチャするメトリクスのグラフを追加することがあります。
ダッシュボードの保守
最初に取り組むのは、システムに関し多くの内容を表示できるダッシュボードを構築することです。しかしながら、当社のシステムは常に進化と拡張を続けており、新機能が追加されアーキテクチャが強化される度に、ダッシュボードもそれに合わせ発展していく必要があります。当社におけるデベロップメントプロセスには、ダッシュボードの保守と更新が、本質的に備わっています。当社のデベロッパー達は、変更を完了する前のコードレビューの段階で、「ダッシュボードで何らかの更新が必要かい?」と質問をします。 基盤レベルで変更がデプロイされる以前に、ダッシュボードの修正が行われる仕組みになっています。デプロイされた変更内容を検証するために、システムのデプロイ中やその後の段階で、オペレーターによるダッシュボードの更新が必要になるといった状況を防いでいます。
ダッシュボードが、通常と比べてかなり詳細な情報を含んでいる場合もあります。この時オペレーターは、自動化されたアラーム発生や修復機能に代わり、ダッシュボードによる手動での異常検出に頼っていることも考えられます。当社では継続的にダッシュボードの監査を実施しながら、サービスの構成を改善し自動アラーム発生機能を強化することで、こういった手動による作業の削減につなげようとしています。同時に、ダッシュボードに価値を与えることがなくなったグラフの削除や更新にも、積極的に取り組んでいます。
デベロッパーがダッシュボードの更新を行えるようにすることで、実稼働前の(アルファ、ベータ、ガンマ)環境においても、完全に遜色ないダッシュボードの使用を実現しています。当社の自動デプロイパイプラインは、まず実稼働前環境に対し、変更点をデプロイします。つまり各チームは、関連したダッシュボード(および自動アラーム発生機能)を使用しながら、テスト環境において変更点の検証を容易に行うことができます。その際の検証方法は、変更点が実稼働環境にプッシュされた後に行われる検証との間で、完全な一貫性を持ちます。
多くのシステムでは、その要件が更新される度に継続的な発展を続けています。新機能の追加や、スケール拡大のためのソフトウェアアーキテクチャの変更が、常に行われています。当社においてダッシュボードは、提供するシステムにとっての基本的で重要なコンポーネントです。したがって、その維持のために、コードとしてのインフラストラクチャ(IaC)プロセスを採用しています。このプロセスにより、ダッシュボードのメンテナンスにバージョン制御システムが使用できます。また、デベロッパーやオペレーターがサービスに対し使用するツールと同様なものを使用して、変更点がダッシュボードにデプロイされるようにしています。
想定外の運用イベント発生に関する事後検討では、ダッシュボード(および自動アラーミング機能)をどのように改善すれば、そのイベントを未然に防ぐことができるのか、根本原因を特定できるのか、あるいは平均修復時間を短縮できるのかなどについて検討します。当社が自身に投げかける質問はこうです。「振り返って見て、このダッシュボードはユーザーに良い影響を与え、オペレーターが最終的な根本原因を割り出すことと、修復のための時間を図ることの助けになっていたと言えるだろうか?」 これらの疑問に対する回答に 1 つでも 「NO (いいえ) 」が存在した時は、事後検討でそのダッシュボードを改善するためのアクションを検討します。
まとめ
Amazon は、世界中で大規模なサービスを運用しています。自動化されたシステムが、継続的なモニタリングや検出、アラーム発生を行っており、そこに何等かの問題が発生した場合はそれを修復しています。これらのサービスと自動システムには、モニタリング、詳細調査、監査、およびレビューができる能力が求められています。これを実現するために、システムに関する多くの異なる表示を提供する、ダッシュボードの構築とメンテナンスが行われています。これらのダッシュボードの設計は、広範囲および特定の利用者の両方を対象にして、ユーザー側からの逆目線に立つことで進められます。オペレーターやサービス所有者にとって、ダッシュボードが理解しやすいものにするため、一貫したデザインの組合せや構成を採用することで、そのダッシュボードの操作性と有用性を高めています。
ダッシュボードにより、AWS のサービスの運用に関する異なる視点や表示が、数多く提供されます。これらは、Amazon の各チームがサービスについて理解し、運用や拡大をする助けとなることで、お客様に良質な操作体験を提供する上での重要な役割を果たします。今回の内容が、独自のダッシュボードを設計、構築、保守しているお客様にとって、一助になれればと願っております。 AWS のサービスを使用しながら、ダッシュボードを作成するサンプルをご希望の方は、こちらの短い動画や、セルフサービスガイドをご覧ください。
著者について
John O'Shea は、アマゾン ウェブ サービスのプリンシパルエンジニアです。 現在は、Amazon CloudWatch や他の Amazon 内部のモニタリングおよびオブザーバビリティサービスに注力しています。

関連コンテンツ
今日お探しの情報は見つかりましたか?
ページコンテンツの品質向上のため、皆さまのご意見をお寄せください