Amazon SageMaker HyperPod の特徴
数千の AI アクセラレーターで生成 AI モデル開発をスケールおよび加速する
チェックポイントレストレーニング
Amazon SageMaker HyperPod でのチェックポイントレストレーニングにより、インフラストラクチャの障害から手動で操作しなくても数分で自動的に復旧できます。これにより、クラスター全体の一時停止、問題の修正、保存されたチェックポイントからの回復を必要とする障害復旧のためのチェックポイントベースのジョブレベルの再起動の必要性が軽減されます。SageMaker HyperPod は障害のあるコンポーネントを自動的に交換し、正常な AI アクセラレータからモデルとオプティマイザーの状態をピアツーピアで転送してトレーニングを回復するので、チェックポイントレストレーニングは障害があってもトレーニングの進行を維持します。これにより、何千もの AI アクセラレータを使用してクラスターで 95%以上のトレーニングが可能になります。 チェックポイントレストレーニングにより、数百万のコンピューティングコストを節約し、トレーニングを数千の AI アクセラレーターにスケールし、モデルをより迅速に本番環境に移行できます。
エラスティックトレーニング
Amazon SageMaker HyperPod のエラスティックトレーニングは、コンピューティングリソースの可用性に基づいてトレーニングジョブを自動的にスケールし、以前はトレーニングジョブの再設定に費やされていた週あたりのエンジニアリング時間を節約します。AI アクセラレーターの需要は、推論ワークロードがトラフィックパターンに応じてスケールされたり、完了した実験によってリソースが解放されたり、新しいトレーニングジョブがワークロードの優先順位を変えたりするにつれて、常に変動します。SageMaker HyperPod は、実行中のトレーニングジョブを動的に拡張してアイドル状態の AI アクセラレーターを吸収し、インフラストラクチャの利用率を最大化します。推論や評価などの優先度の高いワークロードにリソースが必要な場合は、完全に停止することなくより少ないリソースで継続できるようにトレーニングを縮小します。これにより、タスクガバナンスポリシーを通じて確立された優先順位に基づいて必要な能力を引き出します。エラスティックトレーニングは、十分に活用されていないコンピューティングによるコスト超過を減らしながら、AI モデル開発を加速するのに役立ちます。
タスクガバナンス
柔軟なトレーニングプラン
Amazon SageMaker HyperPod のスポットインスタンス
SageMaker HyperPod のスポットインスタンスを利用すると、大幅に低いコストでコンピューティングキャパシティにアクセスできます。スポットインスタンスは、バッチ推論ジョブなどのフォールトトレラントなワークロードに最適です。料金はリージョンとインスタンスタイプによって異なり、通常、SageMaker HyperPod オンデマンド料金と比較して最大 90% の割引が適用されます。スポットインスタンス料金は Amazon EC2 で設定され、スポットインスタンス容量に対する長期の需給傾向に基づいて緩やかに調整されます。インスタンスの実行期間に適用されるスポット料金をお支払いいただきます。事前の契約は必要ありません。スポットインスタンスの見積料金とインスタンスの可用性の詳細については、EC2 スポットインスタンスの料金ページにアクセスしてください。HyperPod でスポットとして使用できるのは、HyperPod でもサポートされているインスタンスのみであることにご留意ください。
モデルをカスタマイズするための最適化されたレシピ
SageMaker HyperPod レシピを使用すると、あらゆるスキルレベルのデータサイエンティストやデベロッパーが最新のパフォーマンスの恩恵を受けることができ、Llama、Mixtral、Mistral、DeepSeek モデルなど、公開されている基盤モデルのトレーニングとファインチューニングをすぐに開始できます。さらに、Nova Micro、Nova Lite、Nova Pro などの Amazon Nova モデルを、教師ありファインチューニング (SFT)、知識蒸留、直接優先最適化 (DPO)、近位ポリシー最適化 (DPO)、継続的な事前トレーニングなどの一連の手法を使用してカスタマイズできます。また、SFT、蒸留、DPO にわたるパラメータ効率の高いトレーニングオプションとフルモデルトレーニングオプションの両方がサポートされています。各レシピには、AWS によってテストされたトレーニングスタックが含まれています。これにより、さまざまなモデル設定をテストする何週間もの煩雑な作業が不要になります。1 行のレシピ変更で GPU ベースと AWS Trainium ベースのインスタンスを切り替えたり、トレーニングの回復力を高めるために自動モデルチェックポイントを有効にしたり、SageMaker HyperPod において本番でワークロードを実行したりできます。
Amazon Nova Forge は、Nova を使用して独自のフロンティアモデルを構築するための、極めて簡単かつ費用対効果の高い方法を組織に提供する初のプログラムです。Nova モデルの中間チェックポイントからアクセスしてトレーニングしたり、トレーニング中に Amazon が厳選したデータセットと所有データを組み合わせたり、SageMaker HyperPod レシピを使用して独自のモデルをトレーニングしたりできます。Nova Forge を使用すると、独自のビジネスデータを活用して、ユースケース固有のインテリジェンスを得て、タスクのコストパフォーマンスを向上させることができます。
高性能分散トレーニング
高度なオブザーバビリティと実験ツール
SageMaker HyperPod オブザーバビリティは、Amazon Managed Grafana で事前に設定された統合ダッシュボードを提供し、モニタリングデータは Amazon Managed Prometheus ワークスペースに自動的に公開されます。パフォーマンスメトリクス、リソース使用率、クラスターの状態を単一のビューでリアルタイムで確認できるため、チームはボトルネックをすばやく特定し、コストのかかる遅延を防ぎ、コンピューティングリソースを最適化できます。SageMaker HyperPod は Amazon CloudWatch Container Insights との統合により、クラスターのパフォーマンス、正常性、使用状況に関するより深いインサイトを提供できます。SageMaker でのマネージド TensorBoard は、モデルアーキテクチャを視覚化して収束の問題を特定および是正することで、開発時間を節約するのに役立ちます。SageMaker でのマネージド MLflow は、実験を大規模かつ効率的に管理するのに役立ちます。
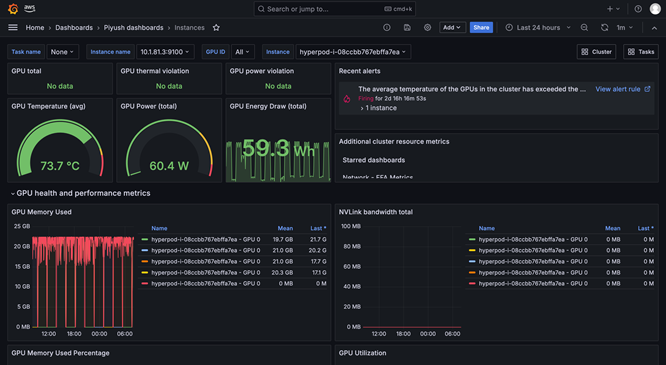
ワークロードのスケジューリングとオーケストレーション
クラスタのヘルスチェックと自動修復
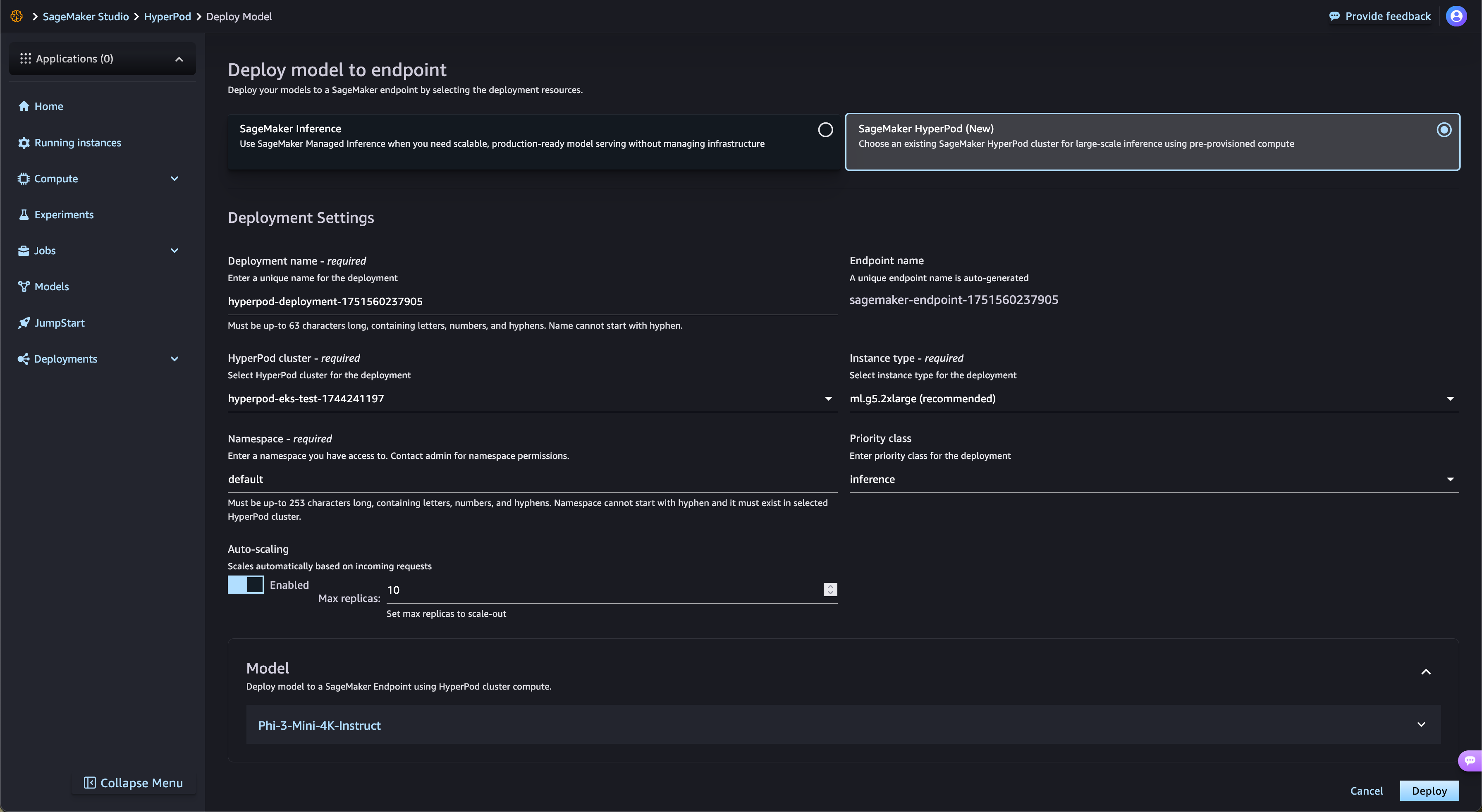
SageMaker Jumpstart からオープンウェイトモデルのデプロイを加速
SageMaker HyperPod は、SageMaker JumpStart のオープンウェイトの FM や、Amazon S3 や Amazon FSx のファインチューニングされたモデルのデプロイを自動的に効率化します。SageMaker HyperPod は必要なインフラストラクチャを自動的にプロビジョニングし、エンドポイントを設定するので、手動プロビジョニングは不要です。SageMaker HyperPod のタスクガバナンスでは、エンドポイントのトラフィックを継続的に監視し、コンピューティングリソースを動的に調整すると同時に、包括的なパフォーマンスメトリックをオブザーバビリティダッシュボードに公開し、リアルタイムの監視と最適化を行います。
マネージド型の階層化されたチェックポイント
SageMaker HyperPod のマネージド型の階層化されたチェックポイント作成機能は、CPU メモリを使用してチェックポイントを頻繁に保存して迅速な復旧を可能にすると同時に、データを定期的に Amazon Simple Storage Service (Amazon S3) に保存して長期的な耐久性を実現します。このハイブリッドアプローチによって、トレーニングの損失を最小限に抑え、障害発生後にトレーニングを再開するまでの時間を大幅に短縮できます。お客様は、インメモリ階層と永続ストレージ階層の両方においてチェックポイントの作成頻度と保存ポリシーを設定できます。メモリに頻繁に保存することで、ストレージコストを最小限に抑えながら迅速に復旧できます。この新機能は PyTorch の分散チェックポイント機能 (DCP) と連携しているため、ユーザーはインメモリストレージのパフォーマンス上の利点を得ながら、わずか数行のコードでチェックポイント作成機能を簡単に実装できます。
GPU パーティショニングによるリソース使用率の最大化
SageMaker HyperPod を使用すると、管理者は GPU リソースをより小さな分離されたコンピューティングユニットに分割して、GPU の使用率を最大化できます。リソースのごく一部しか必要としないタスクにフル GPU を割り当てる代わりに、さまざまな生成 AI タスクを 1 つの GPU で実行できます。GPU パーティション全体にわたるリアルタイムのパフォーマンスメトリクスとリソース使用率モニタリングにより、タスクがコンピューティングリソースをどのように使用しているかを可視化できます。この最適化された割り当てと簡素化されたセットアップにより、生成 AI による開発速度が向上し、GPU の利用率が向上し、大規模なタスク全体で GPU リソースを効率的に使用できるようになります。
今日お探しの情報は見つかりましたか?
ぜひご意見をお寄せください。ページのコンテンツ品質の向上のために役立てさせていただきます