データラベリングとは何ですか?
データラベリングとは
機械学習におけるデータラベル付けとは、生データ(画像、テキストファイル、動画など)を識別し、機械学習モデルがそこから学習できるように、意味のある有益なラベルを1つ以上追加してコンテキストを提供するプロセスです。例えば、ラベルは、写真に鳥や車が含まれているかどうか、音声録音でどの単語が発声されたか、X 線に腫瘍が写り込んでいるかどうかを示すことがあります。データラベリングは、コンピュータビジョン、自然言語処理、音声認識など、さまざまなユースケースで必要になります。
データラベリングのしくみ
今日、ほとんどの実践的な機械学習モデルでは、1 つの入力を 1 つの出力にマッピングするアルゴリズムを適用する教師あり学習が利用されています。教師あり学習が機能するには、モデルが正しい判断を下すために学習できるデータのラベル付きセットが必要です。一般的に、データラベリングは、ラベル付けされていないデータに関する判断を人間に求めることから始まります。例えば、ラベル作成者にデータセット内の「写真に鳥が写っている」という条件が真となるすべての画像にタグを付けるように求めることが考えられます。タグ付けは、単純な「はい/いいえ」のように大まかな作業である場合もあれば、鳥に関連する画像内の特定のピクセルを識別するようなきめ細かい作業である場合もあります。機械学習モデルは、人間が提供したラベルを使用して、プロセスの基礎となるパターンを学習します (「モデルトレーニング」と呼ばれます)。 その結果は、新しいデータの予測に使用できるトレーニング済みモデルです。
機械学習では、特定のモデルをトレーニングして評価するための客観的な基準として使用するための適切にラベル付けされたデータセットを「グラウンドトゥルース」と呼ぶことがあります。 トレーニング済みモデルの精度はグラウンドトゥルースの精度に依存するため、時間とリソースを使って高精度のデータラベリングを確保することが不可欠です。
一般的なデータラベリングの種類
コンピュータビジョン
コンピュータービジョンシステムを構築する場合、まず画像、ピクセル、またはキーポイントにラベルを付けるか、デジタル画像を完全に囲む境界線 (境界ボックス) を作成して、トレーニングデータセットを生成する必要があります。例えば、画像を品質タイプ (商品画像とライフスタイル画像など) またはコンテンツ (画像自体に実際に含まれているもの) で分類することや、画像をピクセルレベルでセグメント化することができます。次に、このトレーニングデータを使用してコンピュータービジョンモデルを構築し、画像の分類、オブジェクトの位置の検出、画像内の重要なポイントの特定、または画像のセグメント化を自動的に行うことができます。
自然言語処理
自然言語処理では、最初にテキストの重要なセクションを手動で識別するか、テキストに特定のラベルを付けてトレーニングデータセットを生成する必要があります。例えば、テキストの宣伝文句の感情や意図の特定、品詞の特定、場所や人物などの固有名詞の分類、および画像、PDF、その他のファイル内のテキストの識別を行うことができます。そのためには、テキストの周囲に境界ボックスを描画し、トレーニングデータセット内のテキストの文字起こしを手動で行います。自然言語処理モデルは、感情分析、エンティティ名認識、および光学式文字認識に使用されます。
音声処理
音声処理は、音声、野生動物が発する音 (鳴き声、さえずり声など)、建物の音 (ガラスが割れる音、撮影音、アラーム) など、あらゆる種類の音を構造化された形式に変換して、機械学習で使用できるようにします。音声処理では、最初に手動でテキストを書き起こす必要があることがあります。そこから、タグを追加して音声を分類することで、音声に関する深いレベルの情報を明らかにすることができます。この分類された音声がトレーニングデータセットになります。
データラベリングのベストプラクティス
データラベリングの効率と精度を向上させる技法は多く存在します。いくつかの例を以下に示します。
- 直感的で合理化されたタスクインターフェースを使用すると、人間のラベル作成者の認知面での負荷とコンテキスト切り替えを最小限に抑えることができます。
- ラベル作成者のコンセンサスは、個々のアノテーターのミスや偏見を打ち消すのに役立ちます。ラベル作成者のコンセンサスを確立するには、各データセットオブジェクトを複数のアノテーターに送信し、その応答 (「アノテーション」) を単一のラベルに統合する必要があります。
- ラベルの監査を行ってラベルの正確性を検証し、必要に応じて更新します。
- アクティブ学習では、機械学習を利用して、人間がラベル付けすべき最も有用なデータを特定することでデータラベリングを効率化できます。
データラベリングを効率的に行うための方法
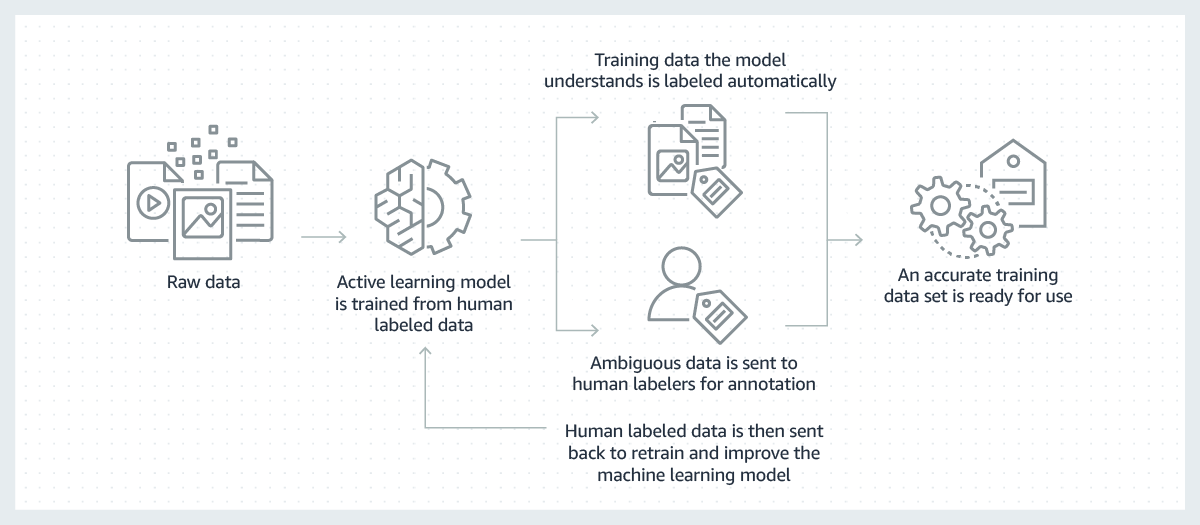
Machine Learning モデル構築の成功は、大量の高品質なトレーニングデータにかかっています。しかし、そのようなモデル構築に必要なトレーニングデータを作成するプロセスは、高価で複雑になり、時間がかかることがあります。現存するモデルの大部分では、Machine Learning モデルが正しい判断を行う方法を学習するために、人間が手動でデータにラベルを付ける必要があります。この課題を克服するために、機械学習モデルを使用してデータに自動的にラベルを付けることで、ラベル付けをより効率的に行うことができます。
このプロセスでは、人間によってラベル付けされた生データのサブセットを使用して、データにラベルを付けるための機械学習モデルをトレーニングします。学習内容に基づき、ラベル付けモデルの判断に高い信頼性がある場合は、ラベルは生データに自動的に適用されます。ラベル付けモデルの判断に対する信頼性が低い場合は、そのデータは人間に返されてラベル付けされます。その後、人間が生成したラベルは、学習および生データの次のセットへの自動ラベル設定の機能向上のためにラベリングモデルに戻されます。時間の経過とともに、モデルでは、より大量のデータに自動的にラベルを付けることが可能になり、トレーニングデータセットの作成を大幅に高速化させることができます。
AWS でのデータラベリング要件のサポート
Amazon SageMaker Ground Truth を使うと、トレーニング用データセットの作成に必要な時間と労力を大幅に減らすことができます。SageMaker Ground Truth では、パブリックおよびプライベートのラベル付け作業者を利用できます。また、一般的なラベル付けタスク用の組み込みワークフローとインターフェイスを提供しています。SageMaker Ground Truth は簡単に使い始めることができます。入門チュートリアルを使えば、最初のラベリングジョブを数分で作成できます。
今すぐアカウントを作成して、AWS でデータラベリングの使用を開始しましょう。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages