O blog da AWS
Apresentando as exportações de dados para o gerenciamento de faturamento e custos da AWS
Por Zach Erdman, Sênior Product Manager
Hoje anunciamos a disponibilidade geral da Exportações de dados, um novo recurso do Gerenciamento de faturamento e custos, o qual permite criar exportações dos seus dados de faturamento e custos utilizando seleção de colunas e filtros de linha em SQL para selecionar os dados desejados. As exportações são entregues recorrentemente em um bucket da Amazon S3, para uso com soluções de business intelligence ou análise de dados.
Anteriormente, os clientes podiam usar os Relatórios de Custos e Uso da AWS (CUR) para receber exportações de seus dados granulares de custo e uso fornecidos pela AWS. Com o CUR, as colunas da exportação variariam ao longo do tempo, dependendo do uso da AWS pelo cliente, e os clientes não tinham controle sobre quais dados de custo e uso estavam contidos nele.
Com a Exportações de dados, os clientes podem criar exportações do novo Relatório de Custos e Uso da AWS 2.0 (CUR 2.0). O CUR 2.0 também fornece os dados de custo e uso mais granulares da AWS, além de oferecer várias melhorias. O CUR 2.0 permite selecionar as colunas que aparecem na exportação para facilitar a ingestão de dados, usar filtros para criar visualizações de custo e uso para suas unidades de negócios, ocultar determinados dados de custo e reduzir o tamanho da exportação para controlar os custos de armazenamento de dados. Ele também inclui duas colunas adicionais com os nomes das contas de usuário e pagador, “bill_payer_account_name” e “line_item_usage_account_name”, e tem uma nova estrutura de dados aninhada para reduzir a dispersão de dados. Com o CUR 2.0, você pode criar uma exportação que corresponda ao seu esquema CUR existente para trabalhar com seus pipelines de dados existentes ou criar uma nova exportação que aproveite as novas colunas CUR 2.0 e os recursos de filtragem da Exportações de dados.
Criar uma exportação usando a seleção de colunas
As Exportações de dados facilitam o controle de quais colunas aparecem em suas exportações usando SQL no console da AWS ou nos SDKs/CLI. Com o controle das colunas de exportação, você pode evitar os erros de ingestão ou processamento de dados que podem ocorrer como resultado da variação do esquema do CUR com base no seu uso da AWS.
Para controlar suas colunas de exportação usando o console, você pode usar o criador de consultas visuais ao criar ou editar uma exportação. Primeiro, você precisa selecionar a tabela que deseja exportar e todas as configurações de tabela que afetam o esquema e os dados da tabela, como a granularidade de tempo do item de linha. Em seguida, você pode usar o seletor de colunas para escolher quais colunas estão em sua exportação em uma lista. O seletor de colunas fornece descrições para cada coluna e uma barra de pesquisa para encontrar as que você precisa.

Figura 1: Um exemplo do seletor de colunas na página do console da Exportações dos dados. Depois de selecionar suas colunas, o console gerará a instrução SQL e a instrução JSON de configuração da tabela selecionando as colunas e os dados especificados. Você pode visualizar esse código com o botão “Visualize as configurações de consulta e tabela SQL” para compartilhar com seus colegas para referência ou para usar nas APIs. A criação da exportação é concluída especificando as preferências de entrega e clicando em criar na parte inferior do formulário.
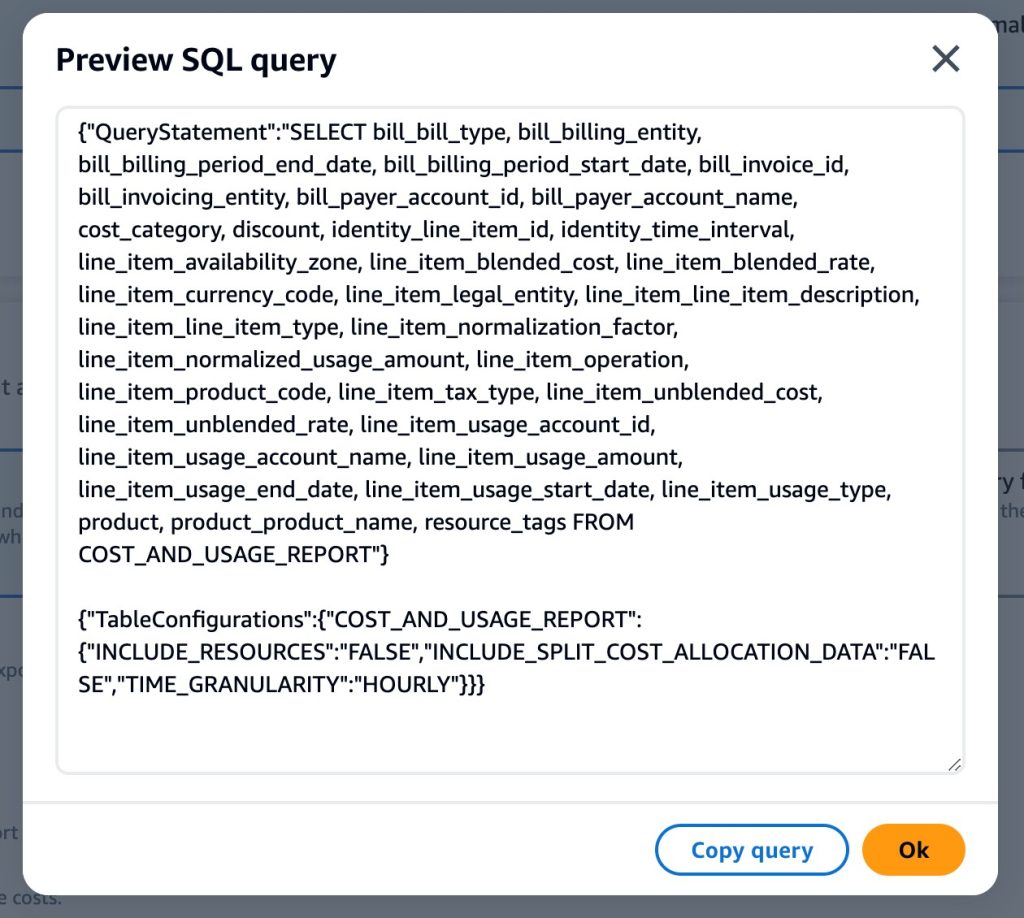
Figura 2: Um exemplo da saída “Visualize as configurações de consulta e tabela SQL” do criador de consultas visuais na página do console Exportações de dados.
Para controlar suas colunas de exportação no SDK/CLI, você precisará escrever sua própria instrução SQL e configurações de tabela. Conforme mencionado anteriormente, as configurações da tabela controlam o esquema e os dados contidos na tabela que você está consultando. Com o CUR 2.0, as configurações da tabela controlam a granularidade do tempo, a granularidade no nível do recurso e se os dados de alocação de custos divididos estão incluídos. O exemplo abaixo mostra as configurações de tabela de granularidade horária, granularidade em nível de recurso e incluindo dados de alocação de custos divididos para o CUR 2.0
{ “TableConfigurations”: {
“COST_AND_USAGE_REPORT”: {
“INCLUDE_RESOURCES”: “TRUE”,
“TIME_GRANULARITY”: “HOURLY”,
“INCLUDE_SPLIT_COST_ALLOCATION_DATA”: “TRUE”
}
}
}Para selecionar as colunas que você deseja incluir na exportação, você deve escrever uma instrução SQL. Você pode ver a lista de colunas disponíveis para consulta visualizando o {Table Dictionary} no guia do usuário Exportações de dados ou usando a API get-table, que lista todas as colunas disponíveis para a tabela especificada. Consulte a página {SQL Support} no guia do usuário do Exportações de dados para obter informações sobre qual SQL é compatível. Veja abaixo uma consulta SQL simples selecionando colunas da tabela CUR 2.0.
{“QueryStatement”:
“SELECT identity_line_item_id, identity_time_interval,
line_item_usage_amount, line_item_availability_zone,
line_item_unblended_cost
FROM COST_AND_USAGE_REPORT”
}As exportações de dados sempre entregarão suas exportações com o esquema especificado no console ou usando o SDK/CLI. Com essa garantia, os clientes podem criar pipelines de ingestão de dados que nunca quebram ou apresentam erros devido à variabilidade do esquema.
Crie exportações com filtros para diferentes unidades de negócios
Atualmente é comum para as empresas que usam a AWS hospedarem aplicações de times ou unidades de negócios em uma única conta AWS ou em várias contas AWS, todas as contas vinculadas à mesma conta de gerenciamento. Isso significa que, ao processar o CUR para uma equipe de aplicação ou unidade de negócios específica, os dados de custo e uso do CUR devem ser filtrados por um engenheiro de dados para incluir somente os dados necessários para essa equipe ou unidade de negócios. Isso é importante para evitar confusão com a atribuição de custos e garantir que as equipes só possam ver seus dados de custo.
Com as Exportações de dados, você pode criar exportações do CUR 2.0 usando SQL para incluir apenas os dados de custo e uso exigidos por uma equipe ou unidade de negócios específica. Vamos considerar um exemplo em que uma empresa que usa a AWS tem três unidades de negócios operando em uma conta pagante (payer) com várias contas vinculadas (linked accounts). Digamos também que a empresa não queira que suas unidades de negócios tenham visibilidade dos descontos que estão recebendo como empresa.
Como engenheiro de dados, quero criar uma exportação CUR 2.0 para cada unidade de negócios que filtre apenas o custo e o uso necessários e remova todos os itens da linha de desconto. Posso realizar essa filtragem escrevendo a seguinte consulta SQL e usando-a na AWS CLI ou nos SDKs para criar uma exportação CUR 2.0 da conta do pagador em Exportações de dados. (Atualmente, a aplicação de filtros de linha só é possível por meio da CLI/SDKs).
{“QueryStatement”:
“SELECT identity_line_item_id, identity_time_interval,
line_item_usage_amount, line_item_availability_zone,
line_item_blended_cost,
…
FROM COST_AND_USAGE_REPORT
WHERE cost_category.BusinessUnit = ‘Business Unit A’
AND NOT line_item_type = ‘Discount’”
}
Para filtrar os dados de cada unidade de negócios, eu uso uma cláusula WHERE para incluir somente recursos rotulados com a unidade de negócios correta. Para filtrar descontos, adiciono à minha cláusula WHERE para excluir qualquer tipo de item da linha “Desconto”. Em seguida, eu criaria mais duas exportações com a mesma consulta para as duas outras unidades de negócios, mas alterando qual delas está na cláusula WHERE.
Com essas três exportações CUR 2.0, cada unidade de negócios pode ingerir e processar sua respectiva exportação e garantir que somente seus dados de custo e uso sejam incluídos sem descontos. Essas exportações também podem ser vinculadas diretamente a uma ferramenta de inteligência de negócios para visualização de dados e tomada de decisões de gerenciamento de custos. No lançamento, os clientes poderão criar no máximo 5 exportações por conta.
Crie uma exportação CUR 2.0 que seja compatível com a versão anterior do CUR
Alguns clientes podem estar interessados em criar uma exportação de CUR 2.0 com um esquema e dados que corresponda ao CUR atual, para que não precisem atualizar seu pipeline de ingestão e processamento do CUR. Isso pode ser feito criando uma exportação com uma consulta SQL específica e uma configuração de tabela.
Para determinar as colunas que correspondem ao seu CUR, você pode visualizar o esquema de um dos seus arquivos CSV/Parquet do CUR ou extraí-la do . Em seguida, você pode escrever a instrução SQL e a configuração da tabela usando o método descrito na seção acima chamada: “Criando uma exportação com seleção de coluna”.
Ao escrever a instrução SQL, é importante observar que o CUR 2.0 tem uma estrutura de dados aninhada para as colunas resource_tags_* e cost_category_* e certas colunas discount_* e product_* onde cada coluna contém pares de valores-chave das colunas originais. Se quiser que as colunas originais apareçam como colunas separadas na exportação do CUR 2.0, você precisará consultá-las usando o dot-operator. Por exemplo, para gerar uma exportação CUR 2.0 que corresponda a uma CUR com as colunas resource_tags_user:creator, cost_category_business_unit e product_from_location, você escreveria uma consulta em Exportações de dados da seguinte forma:
{“QueryStatement”:
“SELECT identity_line_item_id, identity_time_interval,
line_item_usage_amount,
resource_tags.user:creator AS resource_tags_user:creator,
cost_category.business_unit AS cost_category_business_unit,
product.from_location AS product_from_location,
…
FROM COST_AND_USAGE_REPORT”
}Essa consulta extrai as chaves especificadas das colunas cost_category e product e as gera como colunas individuais que correspondem à estrutura do CUR. Com o dot-operator, você pode criar uma exportação que corresponda ao esquema do CUR que você estava recebendo anteriormente. No entanto, uma diferença importante é que o esquema de sua exportação de CUR 2.0 não irá variar com o tempo à medida que seu uso da AWS mudar. Você precisará atualizar sua consulta SQL CUR para começar a receber novas colunas em suas exportações.
Como faço para começar com as Exportações de dados?
Para usar as exportações de dados no console da AWS, faça login no console “Billing and Cost Management” e navegue até a página “Exportações de dados” ou clique neste link. Na página inicial do Exportações de dados, você pode ver todas as exportações CUR existentes que você criou ou clique em “Criar” no canto superior direito da tabela “Exportar e lista de painéis” para começar a criar uma nova exportação CUR 2.0 com o criador de consultas visuais.
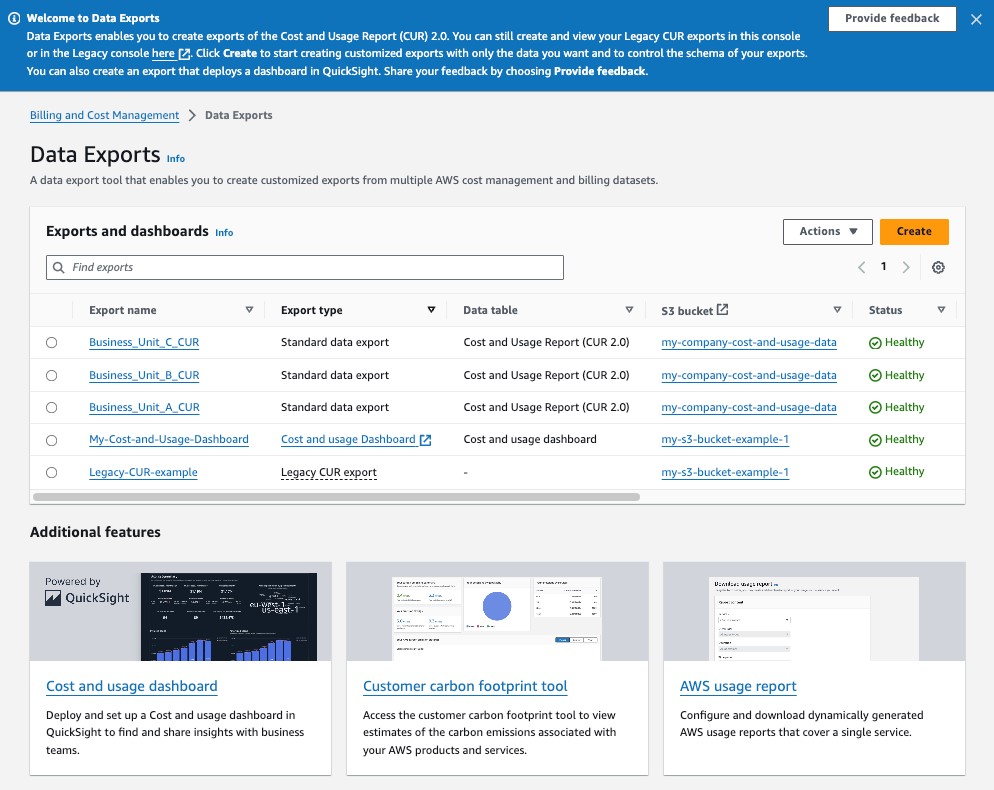
Figura 3: A página inicial das exportações de dados no console do AWS Billing and Cost Management
Para usar as exportações de dados na CLI/SDKs, procure o namespace ou os SDKs “bcm-data-exports”. Com os CLI/SDKs, você pode escrever seu próprio SQL personalizado para gerar exportações. As exportações de dados são compatíveis em todas as regiões da AWS, exceto GovCloud e China.
Este blog é uma tradução do contéudo original em inglês (link aqui).
Biografia do Autor
 |
Zach Erdman é gerente sênior de produtos da AWS e trabalha em exportações de dados para faturamento e gerenciamento de custos na plataforma de comércio. Ele se concentra na criação de ferramentas para ajudar engenheiros de dados e especialistas em FinOps a ingerir, processar e entender com mais facilidade seus dados de uso e custo da nuvem. |
Biografia do tradutor
 |
Gustavo Carreira é Arquiteto de Soluções sênior na AWS, trabalhando na indústria de FSI. Sua experiência profissional com mais de 10 anos de experiência em Arquitetura e 7 anos com banco de dados relacional e infraestrutura. Atualmente ajuda os clientes na definição e planejamento de diversas soluções corporativas. |
Biografia do Revisor
 |
Daniel Camargo é Arquiteto de Soluções na AWS, especializado no setor de Serviços Financeiros e Seguros (FSI). Com mais de 7 anos de experiência trabalhando com serviços AWS, ele ajuda clientes da indústria financeira em suas jornadas de adoção e migração para a nuvem. Seus principais focos de atuação atualmente são Gestão Financeira de Nuvem e Observabilidade |