AWS Cloud Financial Management
Introducing Data Exports for AWS Billing and Cost Management
Today, we announced the general availability of Data Exports, a new Billing and Cost Management feature that enables you to create exports of your billing and cost management data using SQL column selections and row filters to select the data you want to receive. Exports are delivered on a recurring basis to an Amazon S3 bucket for use with business intelligence or data analytics solutions.
Previously, customers could use the AWS Cost and Usage Reports (CUR) to receive exports of their most granular cost and usage data provided by AWS. With the CUR, the columns of the export would vary over time depending on a customer’s usage of AWS and customers had no control over what cost and usage data was contained within it.
With Data Exports, customers can create exports of the new AWS Cost and Usage Report 2.0 (CUR 2.0). CUR 2.0 also provides the most granular cost and usage data in AWS, but offers several improvements. CUR 2.0 enables you to select the columns appearing in your export to facilitate data ingestion, use filters to create cost and usage views for your business units, hide certain cost data, and reduce the size of your export to control data storage costs. It also includes two additional columns with the account names of the usage and payer accounts, ‘bill_payer_account_name’ and ‘line_item_usage_account_name’, and has a new nested data structure to reduce data sparsity. With CUR 2.0, you can create an export that matches your existing CUR schema to work with your existing data pipelines, or create a new export that leverages the new CUR 2.0 columns and filtering capabilities of Data Exports.
Create an export using column selection
Data Exports makes it easy for you to control which columns appear in your exports using SQL in either the AWS console or the SDKs/CLI. With control over the export columns, you can prevent the data ingestion or processing errors that could happen as a result of CUR’s schema varying based on your usage of AWS.
To control your export columns using the console, you can use the visual query builder when creating or editing an export. You first need to select the table you want to export and any table configurations that affect the schema and data of the table, such as the line item time granularity. You can then use the column selector to choose what columns are in your export from a list. The column selector provides descriptions for each column and a search bar to find the ones you need.

Figure 1: An example of the column selector on the Data Exports console pageAfter selecting your columns, the console will generate the SQL statement and table configuration JSON statement that selects the columns and data you specified. You can view this code with the “Preview your query” button to share with your colleagues for reference or to use in the APIs. Export creation is completed by specifying the delivery preferences and clicking create at the bottom of the form.
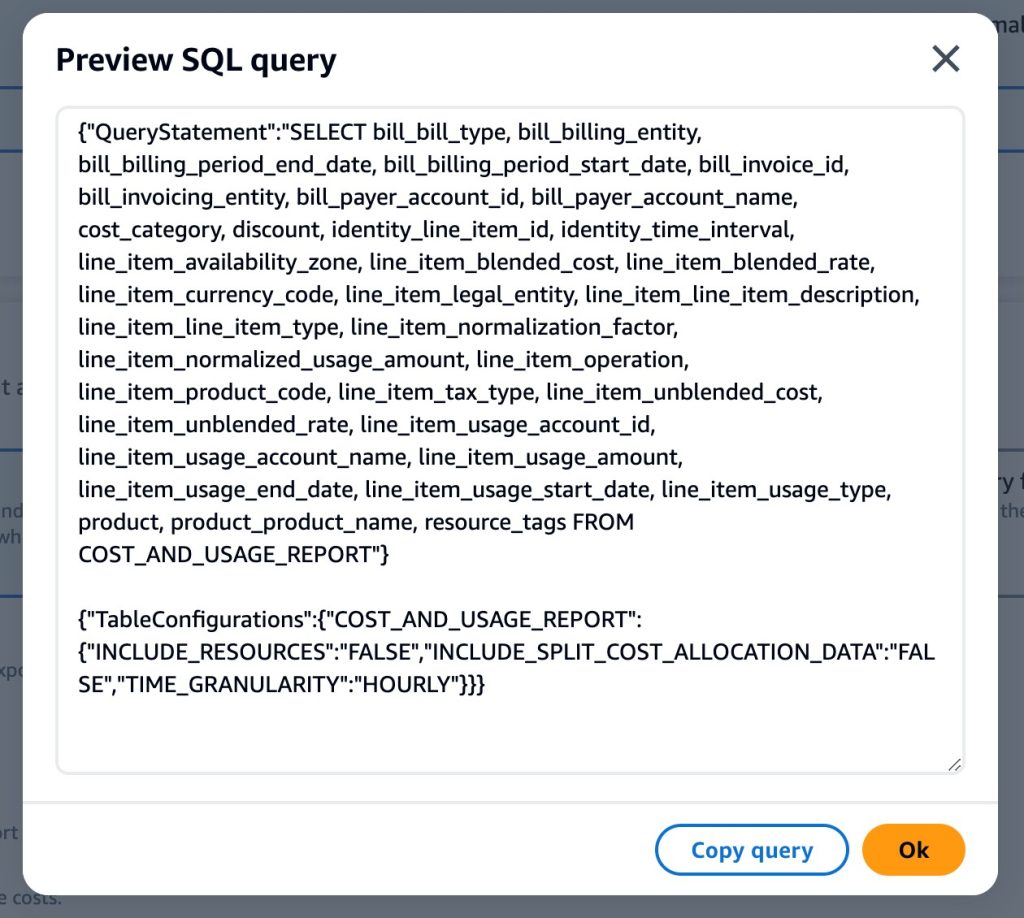
Figure 2: An example of the “Preview your query” output from the visual query builder in the Data Exports console page.
To control your export columns in the SDK/CLI, you will need to write your own SQL statement and table configurations. As mentioned earlier, table configurations control the schema and data contained within the table you are querying. With CUR 2.0, table configurations control the time granularity, resource-level granularity, and whether split cost allocation data is included. The example below shows table configurations of hourly granularity, resource-level granularity, and including split cost allocation data for the CUR 2.0
{“TableConfigurations”: {
“COST_AND_USAGE_REPORT”: {
“INCLUDE_RESOURCES”: “TRUE”,
“TIME_GRANULARITY”: “HOURLY”,
“INCLUDE_SPLIT_COST_ALLOCATION_DATA”: “TRUE”
}
}
}
To select the columns you want included in your export, you must write a SQL statement. You can view the list of columns available for query either by viewing the {Table Dictionary} in the Data Exports user guide or by using the get-table API which lists out all columns available for the specified table. See the {SQL Support} page in the Data Exports user guide for information about what SQL is supported. See below for a simple SQL query selecting columns from the CUR 2.0 table.
{“QueryStatement”:
“SELECT identity_line_item_id, identity_time_interval, line_item_usage_amount, line_item_availability_zone, line_item_unblended_cost
FROM COST_AND_USAGE_REPORT”
}Data Exports will always deliver its exports with the schema specified in either the console or using the SDK/CLI. With this assurance, customers can build data ingestion pipelines that never break or have errors due to schema variability.
Create exports with filters for different business units
It’s common today for companies using AWS to host multiple applications or business units in either a single AWS account or across multiple AWS accounts all linked to the same management account. This means that when processing the CUR for a specific application team or business unit, the cost and usage data from the CUR must be filtered by a data engineer to only include the data needed for that team or business unit. This is important to prevent confusion with cost attribution and to ensure teams can only see their cost data.
With Data Exports, you can create exports of CUR 2.0 using SQL to only include the cost and usage data required by a specific team or business unit. Let’s consider an example where a company using AWS has three business units operating on one payer account with many linked accounts. Let’s also say that the company does not want their business units to have visibility into the discounts they are receiving as a company.
As a data engineer, I want to create a CUR 2.0 export for each business unit that filters for only the cost and usage they require and removes any discount line items. I can accomplish this filtering by writing the following SQL query and using it in either the AWS CLI or SDKs to create a CUR 2.0 export from the payer account in Data Exports. (Applying row filters is currently only possible via the CLI/SDKs).
{“QueryStatement”:
“SELECT identity_line_item_id, identity_time_interval, line_item_usage_amount, line_item_availability_zone, line_item_blended_cost, …
FROM COST_AND_USAGE_REPORT
WHERE cost_category.BusinessUnit = ‘Business Unit A’ AND NOT line_item_type = ‘Discount’”
}
To filter data for each business unit, I use a WHERE clause to only include resources labeled with the right business unit. To filter discounts, I add to my WHERE clause to exclude any “Discount” line item types. I would then create two more exports with the same query for the two other business units, but changing which one is in the WHERE clause.
With these three CUR 2.0 exports, each business unit can ingest and process their respective export and guarantee that only their cost and usage data will be included without any discounts. These exports could also be linked directly to a business intelligence tool for data visualization and making cost management decisions. At launch, customers will be able to create a maximum of 5 exports per account.
Create a CUR 2.0 export that is backwards compatible with CUR
Some customers may be interested in creating a CUR 2.0 export with a schema and data that matches their CUR today so they don’t need to update their CUR ingestion and processing pipeline. This can be accomplished by creating an export with a specific SQL query and table configuration.
To determine the columns to match your CUR, you can either view the schema of one of your CUR CSV/Parquet files or extract the column list from the CUR manifest file. You can then write the SQL statement and table configuration using the method described in the section above named: “Creating an export with column selection”.
When writing the SQL statement, it’s important to note that CUR 2.0 has a nested data structure for resource_tags_* and cost_category_* columns, and certain discount_* and product_* columns where each column contains key-value pairs of the original columns. If you want the original columns to appear as separate columns in your CUR 2.0 export, you will need to query them using the dot-operator. For example, to generate a CUR 2.0 export that matches a CUR with resource_tags_user_creator, cost_category_business_unit, and product_from_location columns, you would write a query in Data Exports like the following:
{“QueryStatement”:
“SELECT identity_line_item_id, identity_time_interval, line_item_usage_amount, resource_tags.user_creator AS resource_tags_user_creator,
cost_category.business_unit AS cost_category_business_unit,
product.from_location AS product_from_location, …
FROM COST_AND_USAGE_REPORT”
}This query extracts the specified keys from the cost_category, and product columns and outputs them as individual columns matching the CUR’s structure. With the dot-operator, you can create an export that matches the schema of the CUR that you previously were receiving. However, an important difference is that the schema of your CUR 2.0 export will not vary over time as your usage of AWS changes. You will need to update your CUR SQL query in order to start receiving new columns in your exports.
How do I get started with Data Exports?
To use Data Exports in the AWS console, log into the “Billing and Cost Management” console and navigate to the “Data Exports” page or click this link. From the Data Exports home page you can view any existing CUR exports you created or click “Create” at the top right of the “Export and dashboard list” table to start creating a new CUR 2.0 export with a visual query builder.
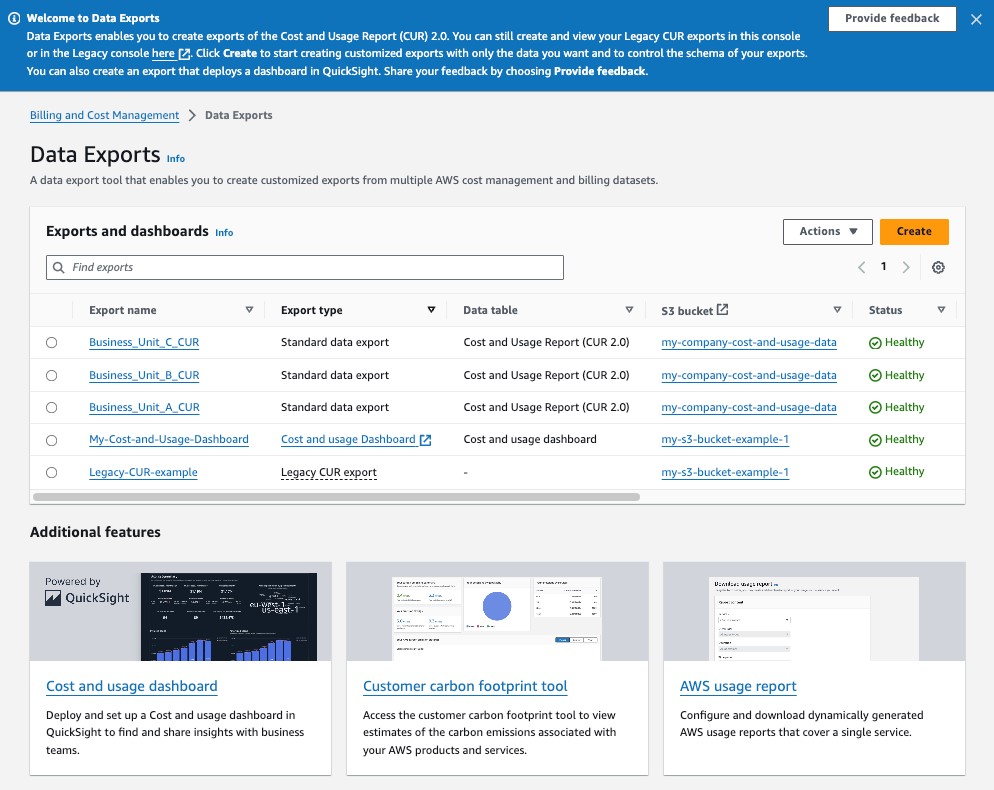
Figure 3: The Data Exports home page in the AWS Billing and Cost Management console
To use Data Exports in the CLI/SDKs, look for the “bcm-data-exports” namespace or SDKs. With the CLI/SDKs, you can write your own custom SQL to generate exports. Data Exports supports all AWS regions except GovCloud and China.