O blog da AWS
Melhorando o throughput de cargas de trabalho serverless de streaming para Kafka
Por Anton Aleksandrov, Prin. SSA, Serverless e Alexander Vladimirov, Sr. SSA, Serverless.
Aplicações orientadas a eventos frequentemente precisam processar dados em tempo real. Quando você usa AWS Lambda para processar registros de tópicos Apache Kafka, você frequentemente encontra dois requisitos típicos: você precisa processar volumes muito altos de registros em tempo quase real, e você quer que seus consumidores tenham a capacidade de escalar rapidamente para lidar com picos de tráfego. Alcançar ambos requer entender como o Lambda consome streams Kafka, onde estão os potenciais gargalos, e como otimizar configurações para alto throughput e melhor desempenho.
Nesta publicação, discutimos como otimizar o processamento Kafka com Lambda tanto para alto throughput quanto para escalabilidade previsível. Exploramos o dimensionamento dos Kafka Event Source Mappings (ESMs) do Lambda, técnicas de otimização disponíveis durante o consumo de registros, como usar o Modo Provisionado ESM para cargas de trabalho com picos, e quais métricas de observabilidade você precisa usar para otimização de desempenho.
Visão geral
Para começar a processar registros de um tópico Kafka com uma função Lambda, seja usando Amazon Managed Streaming for Apache Kafka (Amazon MSK) ou um cluster Kafka autogerenciado, você cria um ESM: um recurso serverless leve que consome registros de tópicos Kafka e invoca sua função.
O comportamento de dimensionamento dos Kafka ESMs é baseado no offset lag. Esta é uma métrica que indica o número de registros no tópico que ainda não foram consumidos pela função Lambda. Esta métrica tipicamente cresce quando produtores publicam novos registros mais rápido do que os consumidores os processam. À medida que o lag cresce, o serviço Lambda gradualmente adiciona mais consumidores Kafka (também conhecidos como pollers) ao seu ESM. Para preservar garantias de ordenação, o número máximo de pollers é limitado pelo número de partições no tópico. O Lambda também reduz pollers automaticamente quando o lag diminui.
Cada ESM segue um fluxo de trabalho de polling consistente: poll -> filter -> batch -> invoke, conforme mostrado no diagrama a seguir. Cada estágio tem opções configuráveis que afetam diretamente o desempenho, latência e custo.
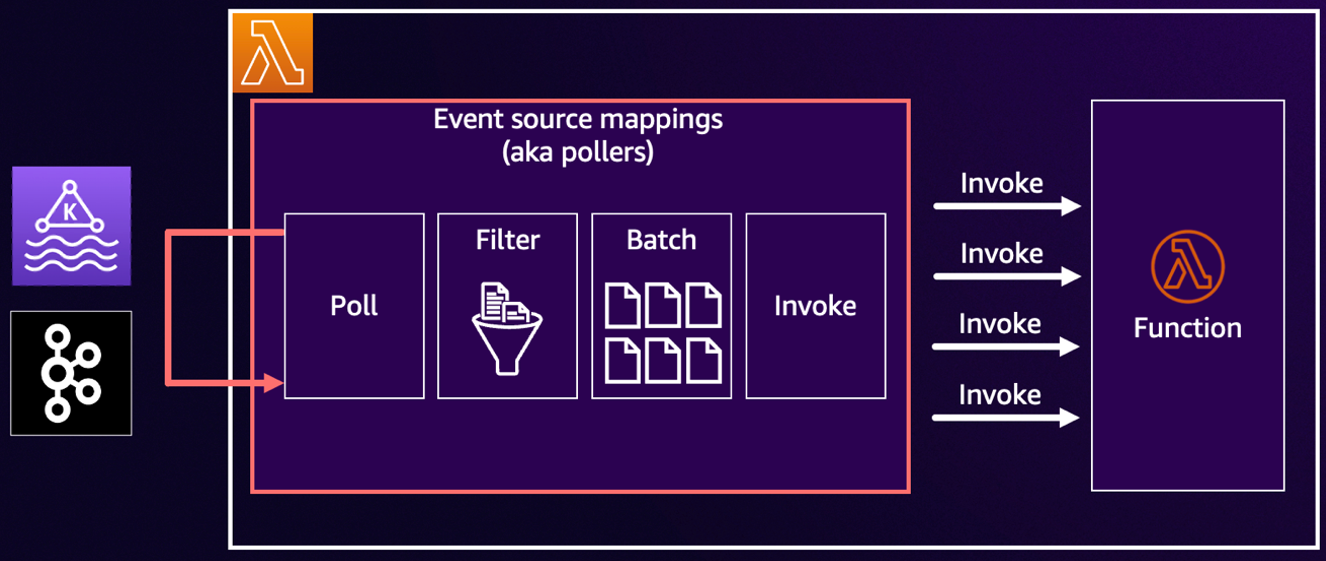
Figura 1. Fluxo de trabalho de processamento ESM.
Polling: Aumentando a previsibilidade com o Modo Provisionado
Por padrão, o Kafka ESM usa o modo de polling sob demanda. Neste modo, o ESM começa com um poller, adiciona automaticamente mais pollers quando o offset lag cresce, e reduz o número de pollers à medida que o lag diminui. O modo sob demanda não precisa de configuração de dimensionamento antecipada e é a opção de menor custo para cargas de trabalho estáveis. Para muitas aplicações, este comportamento é suficiente: o dimensionamento pode levar vários minutos, mas o throughput eventualmente alcança, e você paga apenas pelos recursos que usa, como número de invocações.
No entanto, se suas cargas de trabalho têm picos e são sensíveis à latência, então o dimensionamento sob demanda pode não ser rápido o suficiente e pode resultar em um lag crescendo rapidamente. Isso pode ser resolvido mudando para o Modo Provisionado, que lhe dá controle mais refinado para configurar um número mínimo e máximo de pollers sempre ativos para seu Kafka ESM. Esses pollers permanecem conectados mesmo quando o tráfego está baixo, então o consumo começa imediatamente quando ocorre um pico, e o dimensionamento dentro da faixa configurada é mais rápido e previsível.
O diagrama a seguir mostra as melhorias de desempenho ao usar o ESM no Modo Provisionado para cargas de trabalho com picos. Você pode ver que no modo sob demanda levou mais de 15 minutos para o ESM eventualmente alcançar o novo volume de tráfego, enquanto no Modo Provisionado o ESM lidou com o aumento de tráfego instantaneamente.
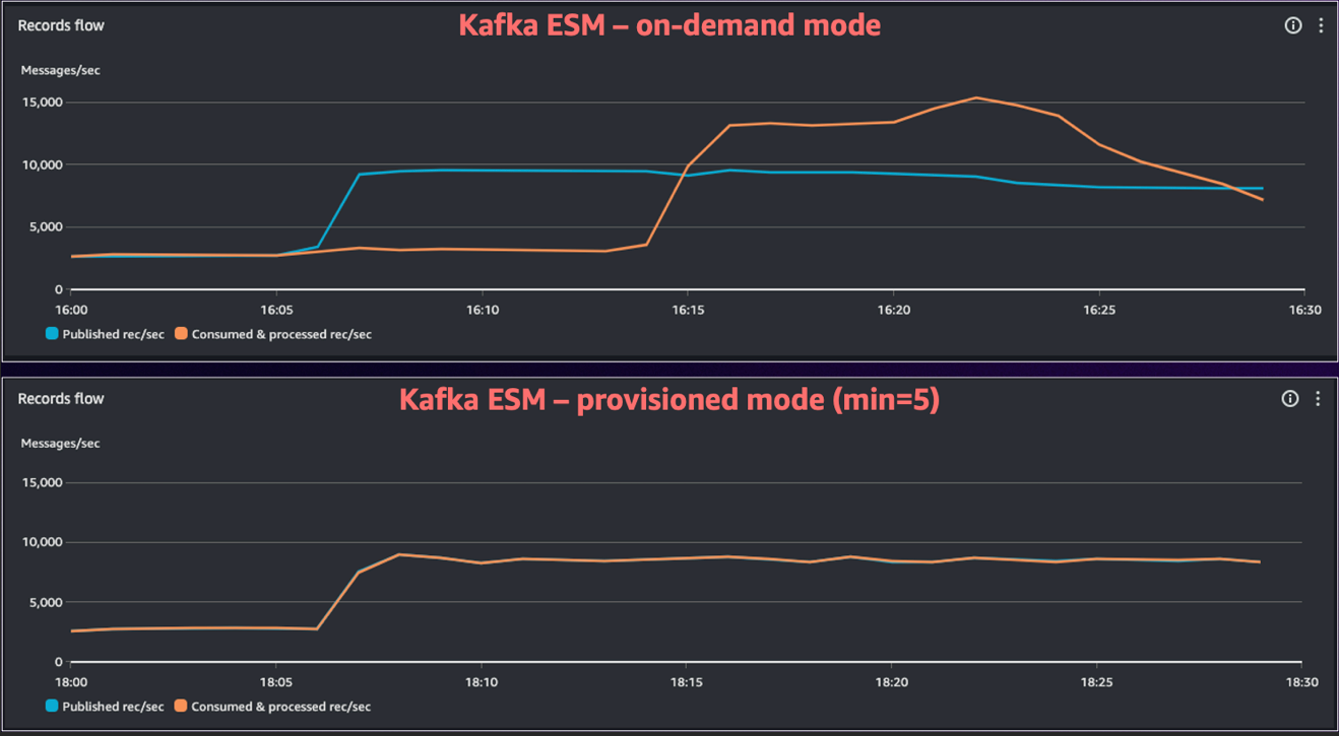
Figura 2. Comparando Kafka ESM sob demanda e Modo Provisionado.
Melhores práticas para usar o Modo Provisionado:
- Comece pequeno: O Modo Provisionado é uma capacidade paga. A AWS recomenda que para tópicos menores (menos de 10 partições) você comece com um único poller provisionado para avaliar o throughput e observar o comportamento da carga de trabalho. Para tópicos maiores, você pode começar com um número maior de pollers provisionados para acomodar o consumo de linha de base. Você pode ajustar esta configuração a qualquer momento conforme aprende os padrões de tráfego e refina seus objetivos de desempenho.
- Estime o throughput: Um único poller provisionado pode processar até 5 MB/s de dados Kafka. Monitore o tamanho médio de registro e o tempo de processamento por registro para estabelecer uma linha de base para pollers mínimos e máximos, então valide com métricas de carga de trabalho reais.
- Defina um piso baixo e teto flexível: Escolha um número mínimo de pollers que garanta que os objetivos de latência sejam atendidos quando ocorrer um pico de tráfego, então permita que o ESM dimensione para um máximo mais alto conforme necessário.
Veja Processamento de baixa latência para fontes de eventos Kafka para mais informações.
Para resumir:
- Use o Modo Provisionado para tráfego com picos, SLOs rigorosos, ou quando backlogs representam risco downstream.
- Use o modo de polling sob demanda para tráfego estável, requisitos de latência flexíveis, ou quando minimizar custo é o objetivo principal.
Filtragem: Descarte registros irrelevantes cedo
Por padrão, todos os registros do Kafka são entregues à sua função Lambda. Esta abordagem é direta e flexível. Seu código handler decide quais registros processar e quais ignorar. Este comportamento padrão é altamente eficiente para cargas de trabalho onde quase todos os registros são valiosos.
Quando você se encontra descartando uma grande porção de registros no seu código handler, você pode usar capacidades nativas de filtragem ESM para descartar registros irrelevantes antes que eles cheguem à sua função. Você pode filtrar cedo para reduzir custo, liberar concorrência, aumentar throughput, e garantir que sua função Lambda gaste ciclos apenas em trabalho valioso.
O diagrama a seguir mostra a aplicação de um filtro ESM para processar apenas telemetria que atende uma condição especificada.
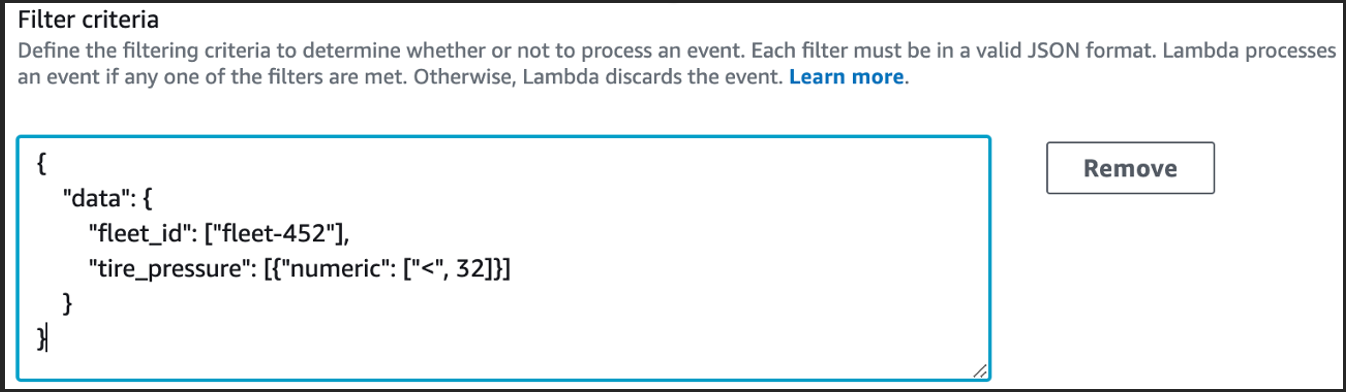
Figura 3. Configuração de filtragem ESM.
Batching: Processando mais registros por invocação
Você pode agrupar múltiplos registros Kafka juntos para processar mais dados por invocação e aumentar a eficiência de suas funções Lambda. Lotes maiores ajudam você a alcançar maior throughput e reduzir custos fazendo melhor uso de cada execução de invocação. Para obter os melhores resultados, você deve equilibrar o tamanho do lote e os objetivos de latência e ajustar a configuração com base nos padrões de tráfego específicos e SLOs da sua carga de trabalho.
O Lambda oferece dois controles principais para configurar o comportamento de batching do ESM:
- Janela de lote: Este é o tempo que o ESM espera para acumular registros antes de invocar sua função. Uma janela mais curta produz lotes menores e invocações mais frequentes. Uma janela mais longa (até 5 minutos) produz lotes maiores e invocações menos frequentes.
- Tamanho do lote: Este é o número máximo de registros que o ESM pode acumular antes de invocar sua função, até 10.000.
Não há uma configuração única que funcione universalmente para todas as cargas de trabalho. Sua configuração ideal depende de características da carga de trabalho, como tolerância à latência e tamanho do registro. A AWS recomenda começar com os valores padrão e então ajustar gradualmente a configuração com base em seus requisitos. Por exemplo, você pode aumentar o tamanho do lote enquanto monitora a duração da função, taxas de erro e latência de ponta a ponta.
O diagrama a seguir mostra como configurar a janela e o tamanho do lote usando Terraform:
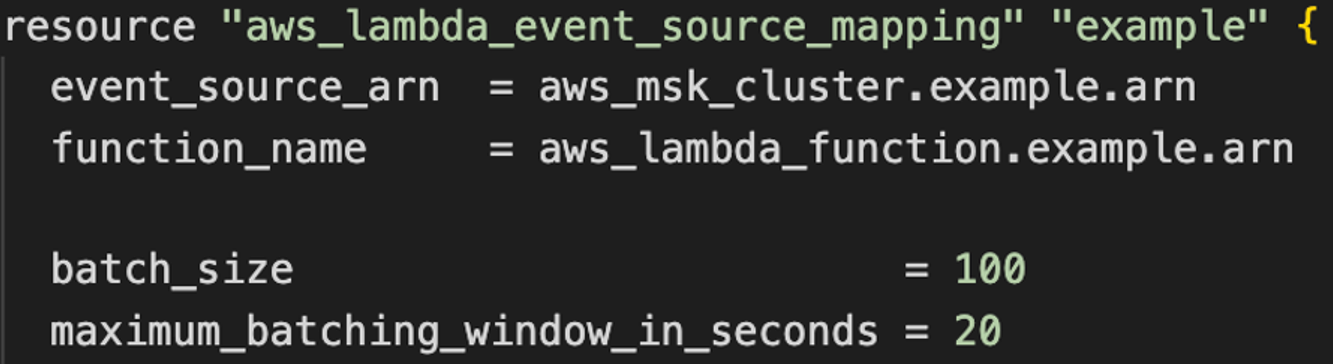
Figura 4. Configuração de janela de lote e tamanho de lote ESM com Terraform.
O ESM invoca sua função quando uma das três condições a seguir é atendida:
- A janela de lote expira.
- O lote acumulado atinge o tamanho máximo de lote configurado.
- O payload acumulado se aproxima do limite máximo de payload de invocação de 6 MB do Lambda.
Ao usar valores de janela de lote mais altos durante picos de tráfego, você tipicamente vê mais registros por lote e durações de invocação de função mais longas. Isso é normal: lotes maiores podem levar mais tempo para processar. Sempre interprete a métrica Duration no contexto do tamanho do lote sendo processado.
Invoke: Processe cada lote mais rápido e eficientemente
Você controla quão rapidamente cada lote é concluído através de dois fatores principais: a eficiência do seu código de função e os recursos de computação que você aloca às suas funções. Você pode melhorar ambos para processar mais registros por segundo, reduzir a concorrência necessária e diminuir o custo.
Otimize seu código: Revise o código handler da sua função para identificar onde você pode reduzir trabalho por registro. Por exemplo, elimine serialização redundante, inicialize dependências uma vez durante a inicialização da função, e considere processamento paralelo dentro do handler (onde aplicável). Para cargas de trabalho críticas de desempenho, você também pode escolher linguagens que compilam para binário, como Go ou Rust, que tipicamente entregam alto desempenho com menor uso de recursos.
Ajuste recursos de computação: Aumentar a alocação de memória da função aumenta proporcionalmente a vCPU. Use a ferramenta Lambda PowerTuning para encontrar a configuração de memória que melhor equilibra desempenho e custo para sua carga de trabalho.
Correlacione métricas: À medida que você otimiza, monitore Duration e Concurrency. Você deve ver a concorrência cair à medida que a duração melhora. Essa correlação confirma que suas mudanças estão melhorando o throughput e a eficiência do sistema.
Quando você combina otimizações de handler com filtragem antecipada e batching eficiente, mesmo pequenas melhorias podem tornar seu pipeline notavelmente mais rápido para operar sob carga.
Observabilidade impulsiona boas decisões
Você não pode otimizar o que não pode ver. Para ajustar seu pipeline de processamento de dados, use uma combinação de OffsetLag, métricas de invocação de função, e métricas de broker Kafka para entender o desempenho do seu processamento de dados. OffsetLag informa se sua função está acompanhando os registros recebidos, conforme mostrado na figura a seguir. Métricas de função como Duration, Concurrency, Errors e Throttles mostram quão eficientemente seu código está processando lotes de registros. Se você usar o Modo Provisionado, então você pode usar a métrica Provisioned Pollers para rastrear a capacidade do poller.
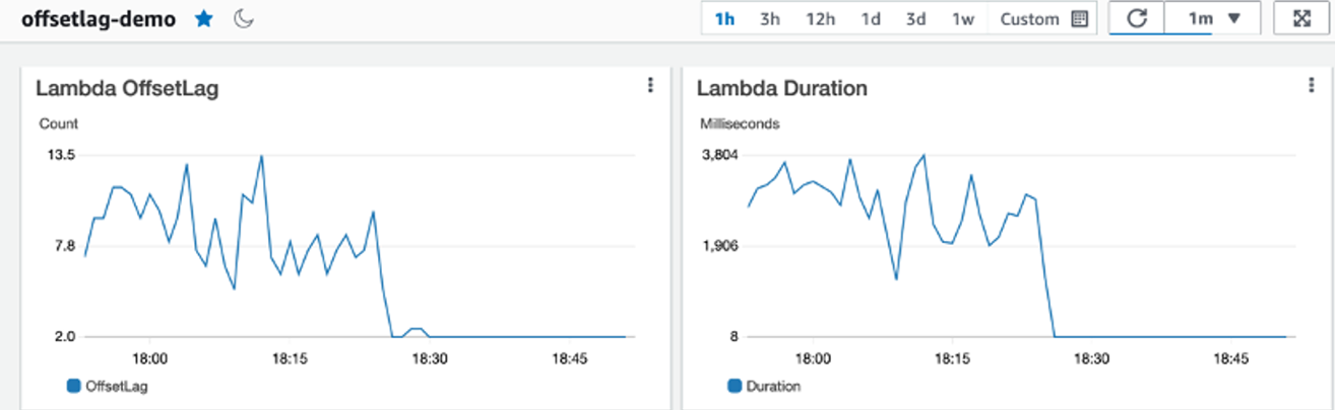
Figura 5. Observabilidade de consumo Kafka com Amazon CloudWatch.
Sempre interprete a duração da função no contexto do tamanho do lote. Durante picos de tráfego, você pode tipicamente observar tanto a duração quanto o tamanho real do lote aumentarem, o que é amortização esperada, não uma regressão. Para alertas, monitore o crescimento do lag, quedas inesperadas na taxa de invocação e picos de erro. Com esses sinais em vista, você pode detectar problemas cedo e ajustar sua configuração com confiança.
Um exemplo de loop de otimização passo a passo
- Estabeleça uma linha de base limpa: Torne seu handler idempotente e consciente de lote, comece com uma janela de lote curta e tamanho de lote moderado. Monitore seu ESM e confirme que o offset lag permanece próximo de zero em estado estável.
- Filtre cedo: Mova verificações estáticas (tipo de registro, versão, outras propriedades personalizadas) para filtragem ESM e verifique que as contagens invocadas caem em relação às contagens polled, provando que o filtro economiza custo e concorrência.
- Aumente o tamanho do lote gradualmente enquanto monitora as métricas de duração, taxas de erro e latência. Estenda a janela de lote ligeiramente se picos causarem muitas invocações.
- Acelere o handler: Aumente a memória para mais CPU, reduza I/O por registro, remova serialização redundante e paralelizar com segurança dentro do lote enquanto rastreia métricas de duração e concorrência juntas.
- Prove prontidão para picos: Reproduza surtos realistas, monitore offset lag e tempo de drenagem, e habilite o Modo Provisionado com um mínimo pequeno se a recuperação levar muito tempo, ajustando com estimativas de MB/s por poller.
- Implemente alertas: Observe crescimento sustentado do lag, lacunas inesperadas entre polled e invoked, e picos de erro vinculados a partições ou lotes grandes. Sempre leia métricas no contexto com o tamanho do lote.
- Reavalie periodicamente: Remeça o throughput do sistema, confirme a eficácia do filtro e reajuste as configurações de lote e memória regularmente conforme as cargas de trabalho evoluem.
Conclusão
Otimizar o processamento de streams Kafka com AWS Lambda requer entender como os ESMs funcionam e ajustar os componentes de consumo: polling, filtragem, batching e invocação. Filtrar registros redundantes cedo remove trabalho desnecessário, batching ajuda você a processar mais registros por invocação, e otimizações de handler garantem que você aproveite ao máximo a computação que você aloca. Juntos, esses ajustes permitem que você dimensione eficientemente e mantenha o offset lag sob controle.
Quando sua carga de trabalho tem picos, use o Modo Provisionado para absorver picos sem longos tempos de recuperação. Com os alertas certos sobre lag, erros e comportamento inesperado de polled versus invoked, você pode identificar problemas cedo e ajustar antes que eles impactem os usuários. Seguir este guia de otimização oferece uma maneira prática de medir, ajustar e revisitar sua configuração conforme os padrões de tráfego mudam.
Para aprender mais sobre otimização de consumo Kafka, veja a sessão AWS re:Invent 2024 sobre Melhorando throughput e monitoramento de cargas de trabalho serverless de streaming.
Para aprender mais sobre construção de arquiteturas Serverless veja Serverless Land.
Este conteúdo foi traduzido da publicação original do blog, que pode ser encontrado aqui.
Autores
 |
Anton Aleksandrov, Prin. SSA, Serverless |
 |
Alexander Vladimirov, Sr. SSA, Serverless |
Tradutores
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. https://www.linkedin.com/in/danielabib/ |