O blog da AWS
Migre seu PostgreSQL de forma homogênea para AWS com AWS DMS
Por Marcelo Oliveira, Arquiteto de Soluções; Ernesto dos Santos (Tito), Arquiteto de Soluções Senior e Diogo Nomura, Arquiteto Especialista Database Senior.
Migrar um banco de dados PostgreSQL para a nuvem pode parecer uma tarefa complexa, mas com o AWS Database Migration Service (AWS DMS), o processo se torna mais direto e acessível.
Muitas empresas estão migrando seus bancos de dados para a nuvem, buscando maior escalabilidade, disponibilidade, e redução de custos de infraestrutura. No entanto, a migração de um banco de dados on-premises para a nuvem nem sempre é um processo fácil. Neste sentido, o AWS DMS foi projetado especificamente para simplificar este processo, permitindo que você migre seus dados de maneira rápida, segura, e com o mínimo de interrupção.
Neste post exploraremos como usar o AWS DMS para migrar seu banco de dados PostgreSQL de maneira homogênea, e sem esforço para a Amazon Web Services (AWS). Vamos guiá-lo através das etapas e configurações necessárias, os benefícios desta abordagem, e as melhores práticas para uma migração bem-sucedida.
Antes de iniciarmos, vale ressaltar que existe uma lista de databases suportados como origem, e como destino para o AWS DMS, confira em “Provedores de dados de origem para migrações de dados homogêneas do DMS“, e “Destinos para migrações de dados homogêneas do DMS“.
Importante ressaltar também que existem regras e/ou limitações que se aplicam quando você pratica migrações de dados homogêneas:
- O suporte para “selection rules” em migrações de dados AWS DMS homogêneas depende do mecanismo de banco de dados de origem e do tipo de migração. As fontes compatíveis com PostgreSQL e MongoDB oferecem suporte a “selection rules” para todos os tipos de migração.
- As migrações de dados homogêneas não fornecem uma ferramenta integrada para validação dos dados.
- Ao usar migrações de dados homogêneas com o PostgreSQL, AWS DMS migra “views“, transformando-as em tabelas em seu banco de dados de destino.
- Você não pode usar migrações de dados homogêneas AWS DMS para migrar dados de uma versão superior do banco de dados para uma versão inferior do banco de dados
- As migrações de dados homogêneas não são compatíveis com o estabelecimento de uma conexão com instâncias de banco de dados que residem em intervalos CIDR secundários em uma VPC.
- Caso o “listener” de seu banco de dados origem esteja disponível na porta 8081, isso impedirá o funcionamento do AWS DMS em uma migração homogênea. Neste caso você deve considerar alterar esta porta, caso deseje utilizar o AWS DMS.
Cenário
No decorrer deste blogpost utilizaremos como referência em nossa migração homogênea, duas bases de dados PostgreSQL. A base de dados origem reside em um servidor on-premises, e a base de dados destino residirá em uma instancia Amazon RDS PostgreSQL (Figura 1).
No entanto seria perfeitamente possível utilizarmos como destino uma instância Amazon EC2, que hospedasse um banco de dados com a engine PostgreSQL.
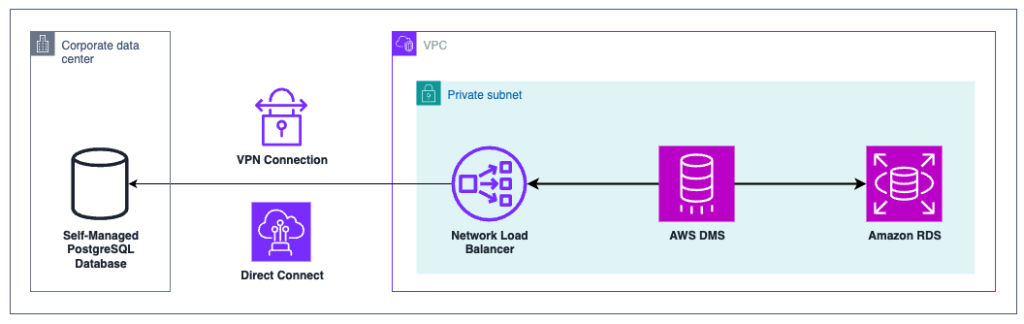
Figura 1 – Diagrama de arquitetura, com o caminho da migração (banco de dados on-premises, para Amazon RDS)
Neste blogpost não entraremos nos detalhes de configuração de uma VPC, VPN site-to-site, e/ou Direct Connect, porém para uma conexão privada do DMS com o banco de dados residente em uma “subnet” privada, é necessário a existência de roteamento entre estas redes.
Também não entraremos nos detalhes de configuração inicial de uma instancia Amazon RDS, onde espera-se que você já possua sua instância (que figurará no papel de “destino”) previamente configurada.
No entanto, antes de iniciarmos, será necessário o ajuste de um parâmetro específico em sua instância Amazon RDS (destino), para que a mesma suporte a funcionalidade de replicação que será utilizada no decorrer do texto.
Além disso, será necessário também o ajuste de algumas permissões na base de dados de origem.
Ajuste do “Parameter groups”, na instância Amazon RDS (destino)
Acesso a console do serviço Amazon RDS (Figura 2).
Figura 2 – Acessando a console do serviço Amazon RDS
A partir da console do serviço Amazon RDS, utilizando o menu lateral, acesse a opção “Parameter groups” (Figura 3).
Figura 3 – Selecionando a opção “Parameter groups”
A partir da tela que se abre, selecione a aba “Custom“, e na sequencia clique no botão “Create parameter group” (Figura 4).
Figura 4 – Iniciando a criação de um novo “Parameter group”
Utilizando-se do grupo de configurações “Create parameter group“, forneça o nome que seu Parameter group receberá (em nosso exemplo, utilizamos o nome “postgres13-logical-replication”).
Escolha a engine de sua instância Amazon RDS (em nosso caso, “PostgreSQL”), e a família apropriada para a versão que você esteja utilizando em seu banco de dados (em nosso exemplo, “postgres13”).
Ao final, clique no botão “Create” (Figura 5).
Figura 5 – Definindo as configurações do novo “Parameter group”
Após a criação do Parameter group, selecione o mesmo na lista (utilizando a checkbox lateral), e a partir do botão “Actions“, escolha a opção “Edit” (Figura 6).
Figura 6 – Editando o “Parameter group” recém criado.
Utilizando-se da barra de busca, pesquise pelo parâmetro “rds.logical_replication“, alterando o valor do mesmo, de “0”, para “1”, clicando em “Save Changes” após o ajuste (Figura 7).

Figura 7 – Ajustando o parâmetro “rds.logical_replication”, no “Parameter group” recém criado.
Utilizando-se do menu lateral da console do serviço Amazon RDS, selecione a opção “Databases“, localize a sua instância, selecione-a através da checkbox ao lado da mesma, e clique no botão “Modify” (Figura 8).
Figura 8 – Modificando as configurações da instância Amazon RDS, para associar o “Parameter group” recém criado.
Dentre as configurações passiveis de serem ajustadas, procure pela sessão de configurações chamada “Additional configuration“.
Após locar a mesma, utilize a caixa de seleção, para indicar que você pretende utilizar o “Parameter group” que criamos nos passos anteriores (Figura 9).
Após concluir o ajuste, role a tela para baixo, até encontrar o botão “Save“, clicando no mesmo.
Figura 9 – Associando o “Parameter group” recém criado à instância Amazon RDS.
Criando o “replication slot”, na base de dados (origem)
A partir da console do banco de dados origem, você precisará criar o “replication slots”, afim de que possa realizar a tarefa de CDC (Change Data Capture).
Você poderá utilizar o exemplo abaixo, ajustando os parâmetro <db_name> para o nome da base de dados que você estará replicando, e o parâmetro <db_role> para a role que será utilizada na operação.
-- Privilégios no banco
GRANT CONNECT ON DATABASE <db_name> TO <db_role>;
GRANT USAGE ON SCHEMA role TO role;
GRANT SELECT ON ALL TABLES IN SCHEMA <db_role> TO <db_role>;
-- Para criar replication slots
GRANT pg_create_logical_replication_slot TO <db_role>;
-- Para monitorar replicação
GRANT pg_monitor TO <db_role>;Sobre o AWS DMS Convert and Migrate
O AWS DMS Convert and Migrate é uma funcionalidade que simplifica significativamente o processo de migração de um bancos de dados. A partir daqui você aprenderá como configurá-lo.
Mas antes de chegar a este passo, você precisa considerar o fato de que seu banco de dados on-premises (origem) reside em sua rede privada, além do fato de que seu banco de dados destino também seguirá esta boa prática de segurança.
Você precisará então contar com outros serviços AWS, afim de que você possa realizar os acessos necessários para a movimentação dos dados, da origem até o destino.
Considerando o diagrama exemplo acima, você irá como primeiro passo, configurar um Network Load Balancer (NLB).
Configurando o Network Load Balancer (NLB)
Neste roteiro de configuração do NLB, iremos evidenciar as sessões e/ou campos os quais iremos ajustar. Evitaremos com isso comentar sobre os campos que permanecerão com as propriedades default.
Conforme a figura abaixo:
Acesse a console do serviço Amazon EC2. Usando o menu à esquerda, clique na opção “Load balancers“. Na sequencia clique no botão “Create load balancer” (Figura 10).
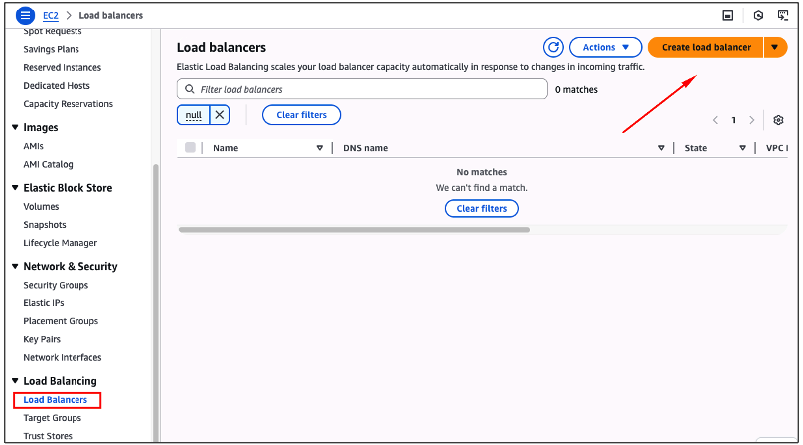
Figura 10 – Criação de um Elastic Load Balancer.
Na tela de criação de “Load Balancers“, escolha a opção “Network Load balancer“, clicando para isso no botão “Create” equivalente (Figura 11).
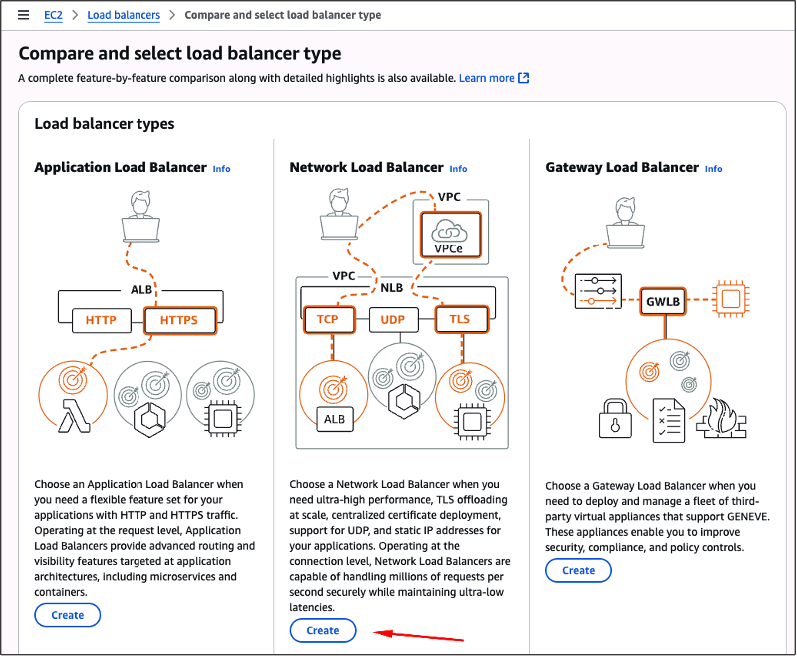
Figura 11 – Criando um Network Load Balancer.
Na tela “Basic configurations“, através do campo “Load balancer name“, informe o nome que seu balanceador de cargas terá. Escolha o esquema de posicionamento deste balanceador, escolhendo através da configuração “Scheme” a opção “Internal“. Para a configuração “Load balancer IP address type“, mantenha a opção “IPv4” (Figura 12).
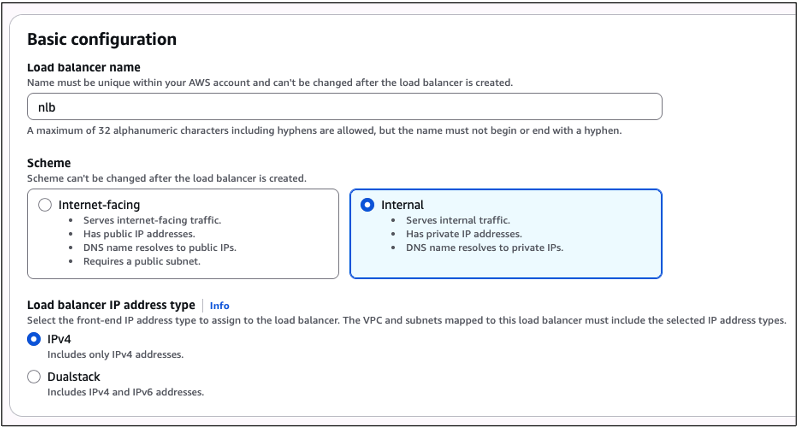
Figura 12 – Escolhendo as configurações do Network Load Balancer: nome, esquema (interno), e tipo de endereçamento (IPV4)
Para a sessão “Network mapping“, estamos considerando que você já possui a sua VPC, e respectivas subnets, as quais serão utilizadas para abrigar sua instância de banco de dados destino.
Utilizando-se então do seletor de “VPC“, escolha a VPC que você elegeu para abrigar o banco de dados destino. Ainda nesta sessão, utilizando-se da opção “Availability Zones and subnets“, escolha quais as subnets você irá utilizar (para estas configurações, escolha a opção “Assigned from CIDR …“) (Figura 13).
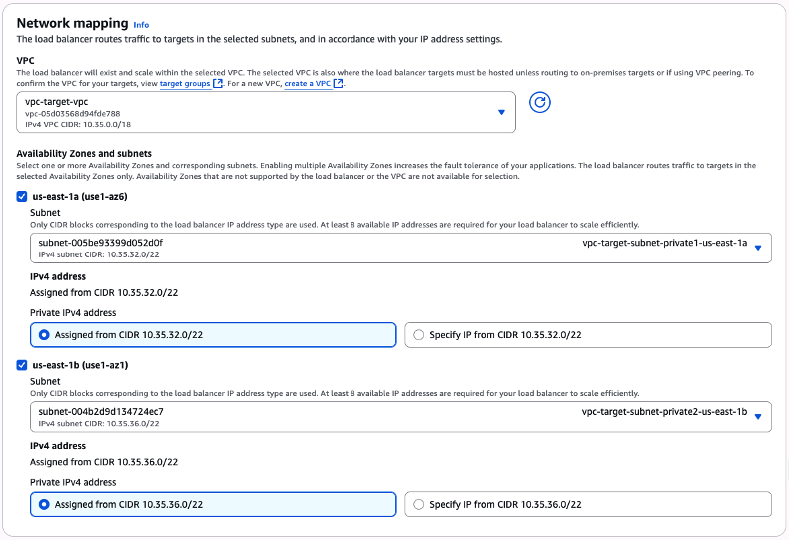
Figura 13 – Definição das configurações da sessão “Network mapping”.
Na sessão “Security groups“, a partir do seletor, escolha qual Security Group você utilizará para ser associado ao Listener deste Network Load Balancer (Figura 14).
Caso você não tenha um Security Group já criado e disponível para seleção, você poderá criar um novo a partir do weblink “create a new security group“.
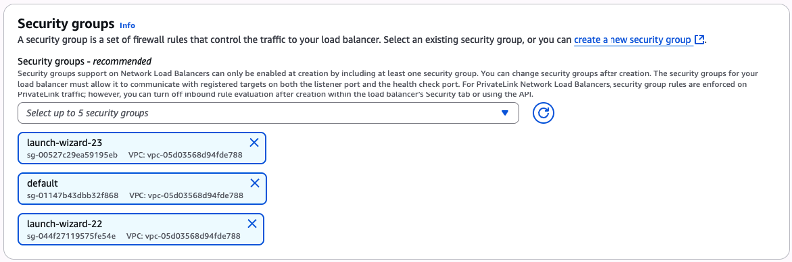
Figura 14 – Seleção de qual Security Group será selecionado para a associação com o NLB que está sendo criado.
Na sessão “Listeners and routing“, você irá criar o listener que este NLB irá utilizar. Nesta sessão, a partir do campo “Port“, indique que você irá utilizar a porta “5432“. No campo “Default action“, usando o weblink “Create target group” indicado pela seta vermelha (Figura 15), indique que você irá criar um novo “Target group“.
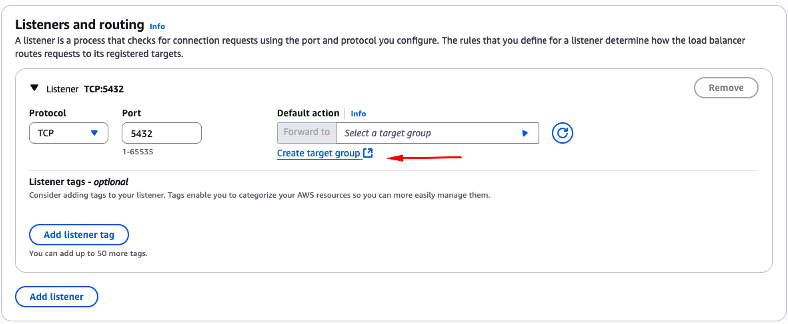
Figura 15 – Criação e configuração do listener, utilizado no NLB que está sendo criado.
Ao clicar no weblink da figura mencionado na acima (Figura 15), uma nova tela será apresentada. A partir desta nova tela, na sessão “Specify group details“, indique que você deseja utilizar a configuração baseada em endereços IP. No campo “Target group name” informe o nome que você dará para este Target Group (em nosso exemplo usamos o nome “sourcedb”) (Figura 16).
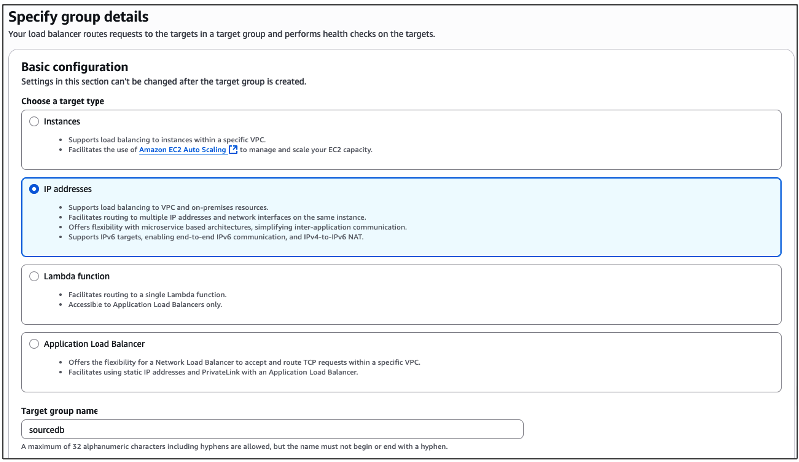
Figura 16 – Especificando os detalhes do Target Group.
A partir do campo “Protocol: Port“, você escolhera o protocolo, que neste caso será “HTTP“, além de indicar a porta a ser utilizada, neste caso “5432“. No campo “VPC” você deve indicar qual VPC irá utilizar, afim de que você possa se conectar com sua instância de banco de dados que está hospedada em seu ambiente on-premises. Ou seja, a VPC que permite o roteamento até este ponto. Após esta escolha, clique no botão “Next“, no rodapé desta sessão (Figura 17).
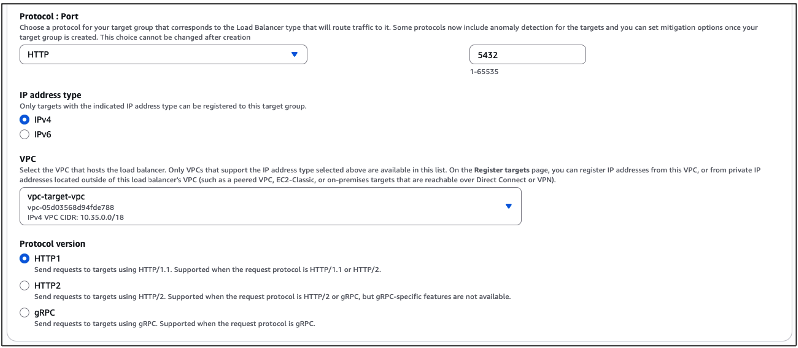
Figura 17 – Escolha do protocolo, porta, tipo de endereçamento IP, e VPC utilizada no Target Group.
A partir da sessão “IP address“, você irá indicar qual IP e Porta sua instância de banco de dados on-premises (origem) utiliza (Figura 18).
No “Step 1: Choose a network“, a partir do campo “Network“, escolha a opção “Other private IP address“. No “Step 2: Specify IPs and define ports“, a partir do campo “Enter a private IP address“, indique o IP que sua instância de banco de dados on-premisses (origem) utiliza.
Ainda no “Step 2“, a partir do campo “Ports“, indique qual porta seu banco de dados on-premises está “escutando” (aqui em nosso exemplo utilizamos a porta 5432, mas você pode ter configurado seu banco de dados on-premises configurado em uma porta diferente desta). Clique no botão “Include as pending below“.
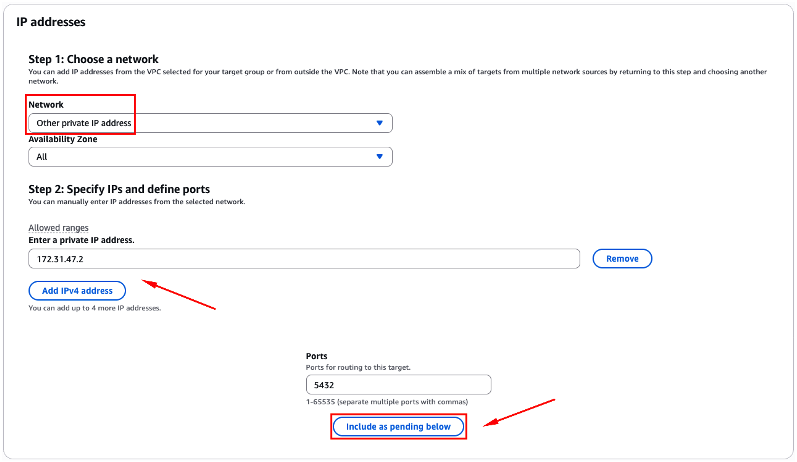
Figura 18 – Configuração do IP + Porta, utilizados na instancia de banco de dados on-premises (origem).
A partir da sessão “Review targets“, revise as configurações que você realizou, e clique no botão “Create target group” (Figura 19).
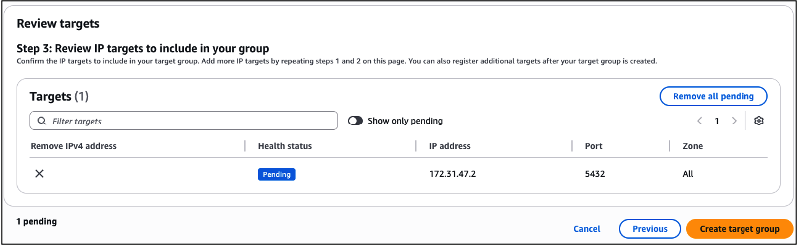
Figura 19 – Revisando as configuração de IP + Porta, de seu Target Group.
A partir deste ponto, você estará de volta à sessão “Listeners and routing“, onde agora você irá concluir a configuração de seu Network Load balancer (NLB).
Confira através do campo “Port“, se a porta que você indicou anteriormente “5432” ainda se mantém. Agora com o nosso Target Group criado, selecione o mesmo através da lista disponível (Figura 20).
Role a página até seu rodapé, e clique no botão “Create load balancer“.
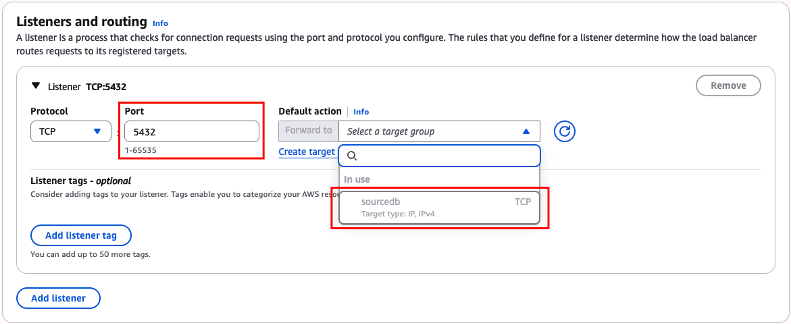
Figura 20 – Selecionando o Target Group recém criado.
Configurando o “AWS DMS Convert and Migrate”
Para configurar o “AWS DMS Convert and Migrate“, acesse o console do serviço AWS DMS (Figura 21).
Figura 21 – Acessando o console do serviço AWS DMS.
Utilizando-se do menu a esquerda, expanda a sessão “Convert and migrate“, onde você precisará passar pela configuração dos 3 componentes indicados nas opções (Figura 22).
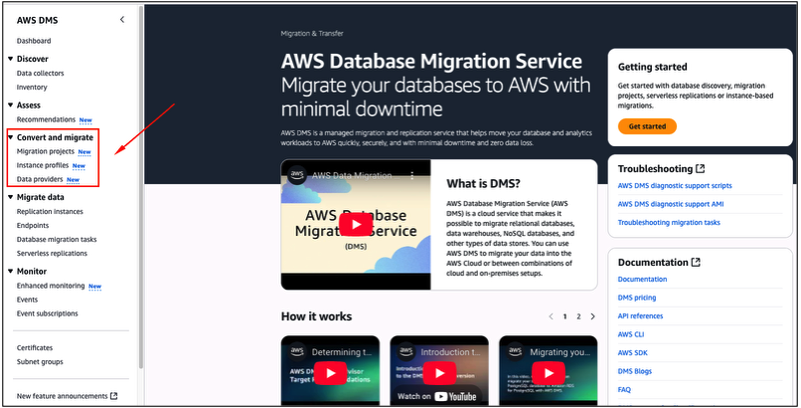
Figura 22 – Onde estão as 3 opções necessárias para a configuração do “Convert and migrate”.
Configurando o “Data provider” de origem
A partir da sessão “Convert and migrate“, escolha a opção “Data providers” (Figura 23).

Figura 23 – Selecionando a opção de “Data provider” no menu da console do AWS DMS.
Na tela que se abre, clique no botão “Create data provider” (Figura 24).
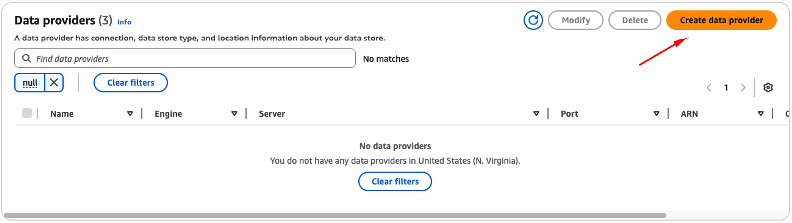
Figura 24 – Criando um novo “Data provider”.
A partir da sessão “Configuration“, usando o campo “Name“, forneça o nome de seu “Data provider” de origem (neste exemplo “sourcedbnlb”). No campo “Purpose“, escolha a opção “Move to managed (Homogenous data migrations)” (Figura 25).
Em “Engine Type“, escolha “PostgreSQL”, sendo que na opção “Engine Configuration“, escolha “Enter manually“. Em “Server name“, onde se deve fornecer a URL de seu banco de dados, você irá utilizar a URL do “Network Load Balancer” que foi criado no passo anterior.
No campo “Port” forneça 5432 (que foi a porta definida no Listener do NLB. Por fim forneça o nome do banco de dados de origem (aqui em nosso exemplo “db1”).
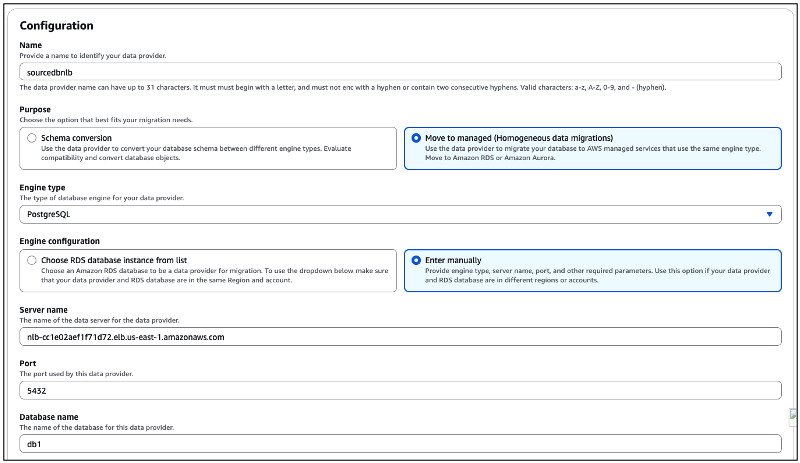
Figura 25 – Especificando as configurações do “Data provider” de origem.
Configurando o “Data provider” de destino
Ainda a partir da opção “Data providers“, clique no botão “Create data provider“.
A partir da tela que se abrirá, usando a sessão “Configuration“, utilize o campo “Name” para fornecer o nome de seu “Data provider” de destino (neste exemplo “destdbrds”). No campo “Purpose“, escolha a opção “Move to managed (Homogenous data migrations)” (Figura 26a e 26b).
Em “Engine Type“, escolha “PostgreSQL“. Em “Engine Configuration” escolha “Choose RDS database instance from list“, e em “Database from RDS“, selecione a instância de RDS que será utilizada como destino (OBS: Estamos considerando aqui que esta instância já foi previamente criada e configurada).
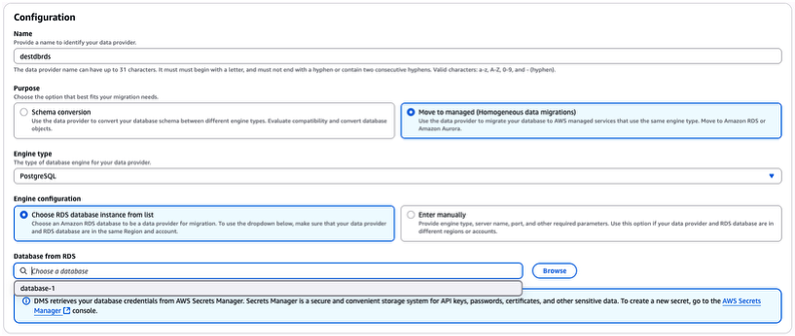
Figura 26a – Especificando as configurações do “Data provider” de destino.
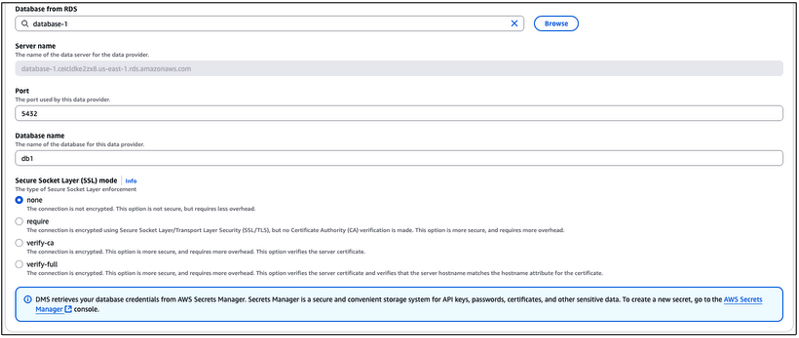
Figura 26b – Detalhando as configurações do banco de dados destino, durante a criação do “Data provider” de destino.
Configurando o “Instance profile”
Antes de iniciar a criação do “Instance Profile“, você irá criar um “Subnet Group“, afim de indicar quais possíveis subnets serão utilizadas para abrigar o banco de dados destino.
Para isso, usando o menu de opções à esquerda (Figura 27), escolha a opção “Subnet groups“.

Figura 27 – Escolhendo a opção “Subnet groups”, a partir do menu lateral.
A partir da tela que se abre (Figura 28), clique no botão “Create subnet group” .
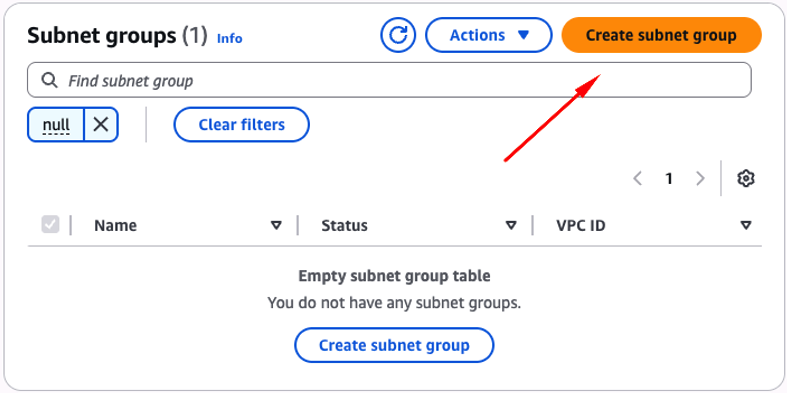
Figura 28 – Criando um novo “Subnet groups”.
A partir da sub-sessão “Subnet group configuration“, informe o nome que seu subnet group terá (aqui em nosso exemplo “mydbsubnetgroup”). Escolha também a descrição a ser usada.
Nesta mesma sub-sessão, a partir do campo “VPC“, selecione a VPC que abriga o banco de dados destino (instância RDS).
Na sequência, a partir da sub-sessão “Add subnets“, selecione quais subnets (pertencentes a esta VPC) pode ter a possibilidade de abrigar a instância de seu banco de dados destino (Figura 29).
Ao finalizar as configurações, clique no botão “Create subnet group“.
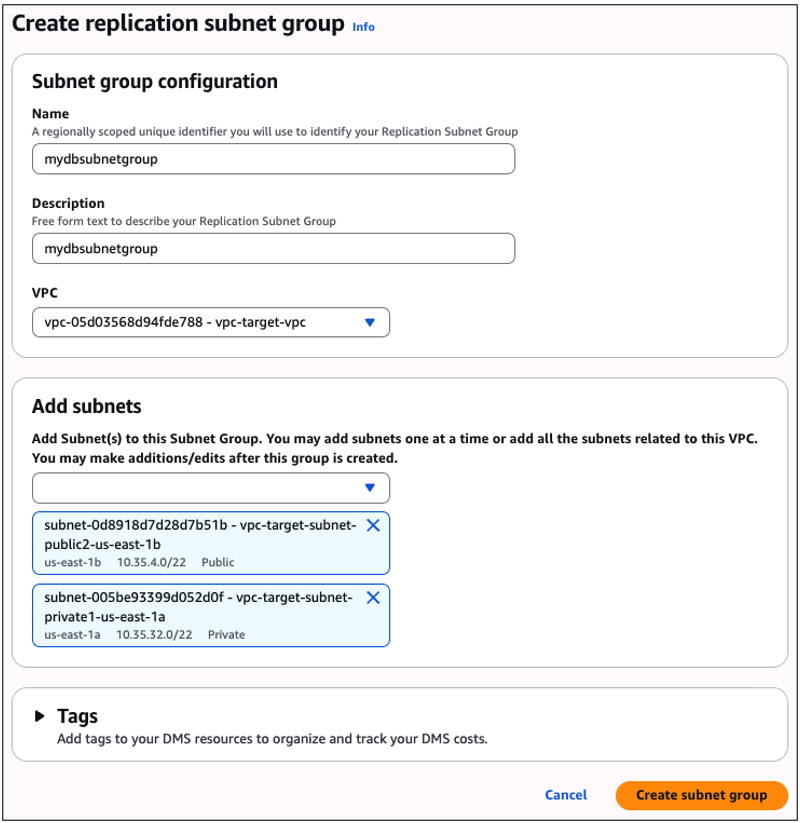
Figura 29 – Fornecendo os detalhes de configuração do “Subnet groups” que está sendo criado.
Com o subnet group criado, usando o menu de opções à esquerda, a partir da sessão “Convert and migrate“, escolha a opção “Instance profile” (Figura 30).
Na sequência, clique no botão “Create instance profile“.
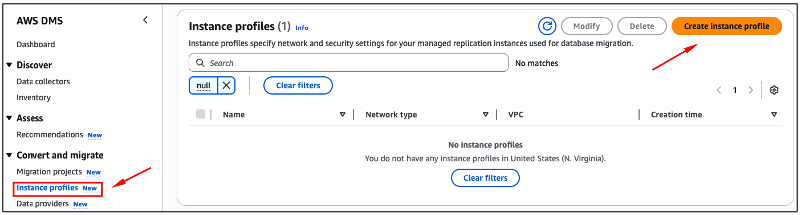
Figura 30 – Criando um novo “Instance profile”.
A partir da tela de criação “Create instance profile“, usando a sub-sessão “General“, indique o nome que você dará a este profile (em nosso exemplo “postgresql-instance-profile”), e a descrição opcional a ser utilizada (Figura 31).

Figura 31 – Fornecendo os primeiros dados do “Instance profile” que está sendo criado.
A partir da sub-sessão “Connectivity and security“, no campo “Network type“, escolha a opção “IPv4“. A partir do campo “Virtual private cloud (VPC) for IPv4“, selecione a VPC onde sua instância RDS que abriga seu banco de dados destino reside.
Esta mesma VPC, precisa também possuir roteamento/acesso à rede onde reside o banco de dados origem.
Selecione então o “Subnet group” que você criou acima. Na sequência, usando o campo “VPC Security Group“, escolha o Security group que você pode ter criado anteriormente para atender as necessidades de acesso à sua instância de banco de dados destino, ou utilize a opção de Security group “default“, que é selecionada por padrão, quando você escolhe a VPC a ser utilizada (Obs: caso você decida por utilizar a opção “default” Security group, este necessita possuir uma “Inbound rule” que permita o acesso ao banco de dados destino).
Por fim, usando o campo “Assign public IP“, selecione a opção “No“, pois para o cenário deste blogpost não necessitaremos de um IP público associado ao Instance profile que está sendo criado (Figura 32).
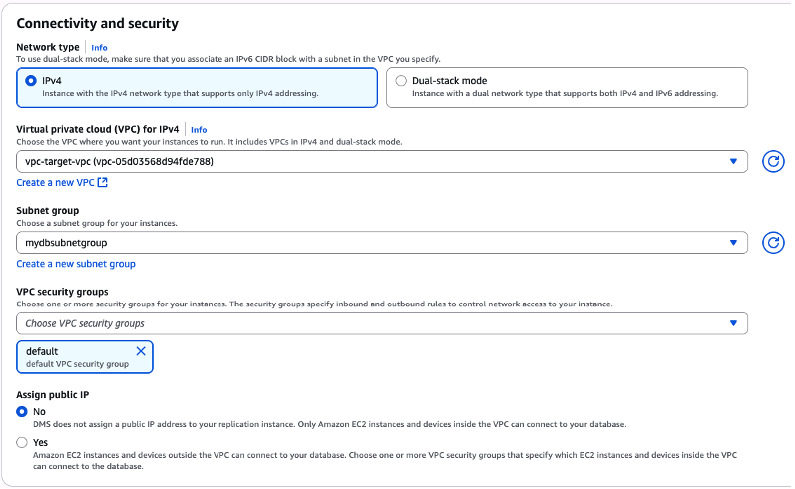
Figura 32 – Fornecendo o restante dos dados relacionados ao “Instance profile” que está sendo criado.
Para concluir a criação do Instance profile, clique no botão “Create instance profile” (Figura 33).
Figura 33 – Concluindo a criação do “Instance profile”.
Configurando o “Migrate Projects”
Com o “Instance Profile“, e os “Data Providers” criados, agora você partirá para a criação do “Migration Project“.
Para isso, usando o menu de opções lateral, a partir da sessão “Convert and migrate“, escolha a opção “Migration Projects” (Figura 34).
Figura 34 – Iniciando a criação do “Migration project”.
Após a escolha da opção, a partir da tela que se abre, clique no botão “Create migration project” (Figura 35).
Figura 35 – Criando o “Migration project”.
Usando a sessão “Configuration“, indique o nome de sua configuração (em nosso exemplo “migrationproject”).
Selecione então em “Project purpose” a opção “Move to managed (Homogenous data migration)“.
Utilizando a opção “Instance profile“, selecione o Instance Profile que você criou nos passos anteriores (Figura 36).
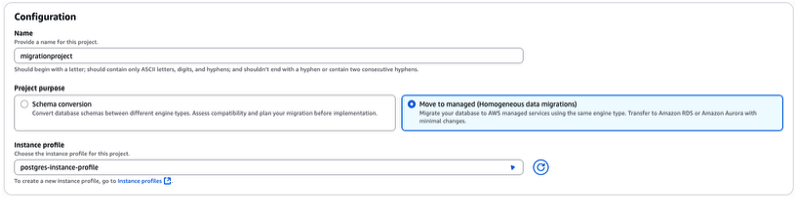
Figura 36 – Fornecendo as primeiras configurações do “Migration project” que está sendo criado.
Utilizando a sessão “Data providers“, a partir do campo “Source“, selecione o Data provider de origem (criado nos passos anteriores). A partir do campo “Secret” será necessário também prover uma Secret do AWS Secrets Manager, contendo os dados de acesso à base de dados origem (usuário e senha). Em nosso exemplo (imagem abaixo), a Secret já criada e escolhida chama-se “dms/sourcedb/db1”. Caso você não possua uma Secret com os dados da base de dados origem criada em sua AWS Account, saiba como criar este recurso através desta referência.
O próximo passo será fornecer uma AWS IAM Role, para habilitar que o DMS possa acessar a Secret escolhida. No exemplo (figura abaixo), a partir do campo “IAM role for Secret“, optou-se pela criação de uma nova AWS IAM Role, especificamente para este fim (Figura 37).
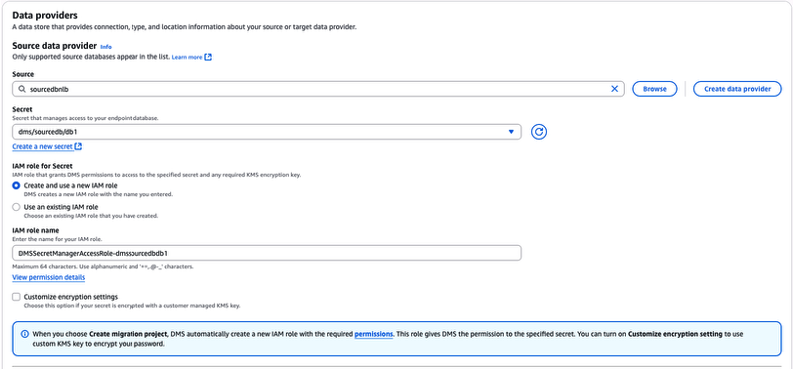
Figura 37 – Fornecendo as configurações relacionadas ao “Data provider” de origem, para o “Migration project” que está sendo criado.
Na sequência (Figura 38), a partir do campo “Target“, selecione o Data provider de destino (criado também nos passos anteriores). A partir do campo “Secret” será necessário prover uma Secret do AWS Secrets Manager, contendo neste caso os dados de acesso à base de dados destino (usuário e senha). Em nosso exemplo (imagem abaixo), a Secret já criada e escolhida chama-se “dms/destdb/database-1”. Caso você não possua uma Secret com os dados da base de dados de destino criada em sua AWS Account, saiba como criar este recurso através desta referência.
Como você já criou uma nova AWS IAM Role no passo acima, selecione a check-box “Use the same IAM role for target data provider”.
Com os todos os dados fornecidos, clique no botão “Create migration project“.
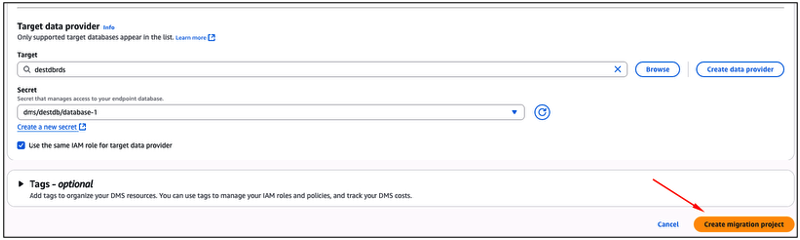
Figura 38 – Fornecendo as configurações relacionadas ao “Data provider” de destino, para o “Migration project” que está sendo criado.
Uma vez criado o Migration project, selecione o mesmo clicando sobre o seu link (Figura 39).

Figura 39 – Selecionando o “Migration project” recém criado.
A partir da tela “Migration projects” do projeto selecionado, clique na aba “Data migrations“, e na sequência clique no botão “Create data migration” (Figura 40).
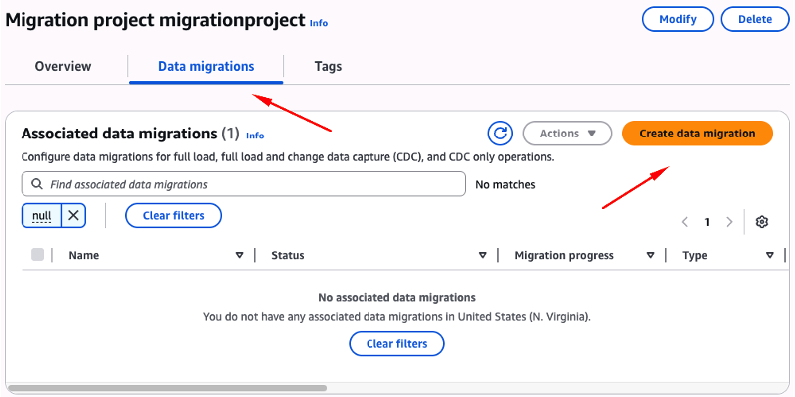
Figura 40 – Criando um “data migration”, a partir do “Migration project” recém criado.
Na tela que se abre a partir da sessão “Create data migration“, escolha um nome para o seu projeto (em nosso exemplo o nome utilizado foi “DataMigration”). Na sequência, você precisará escolher qual o tipo de replicação será utilizada.
Para o cenário deste blogpost, escolha a opção “Full load and change data capture (CDC)“. Afim de trazer visibilidade, escolha habilitar a geração de logs, através do check-box “Turn on CloudWatch logs” (Figura 41).
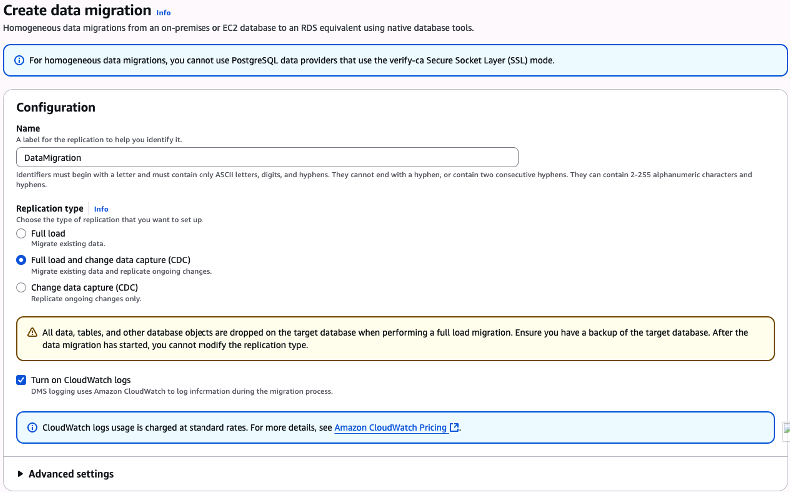
Figura 41 – Fornecendo a primeira parte das configurações do “data migration” que está sendo criado.
Agora, você irá definir qual será a abrangência de dados que serão migrados entre a origem, e o destino.
Ainda na mesma tela, e a partir da sessão “Selection rules – optional“, clique no botão “Add selection rule” (Figura 42).
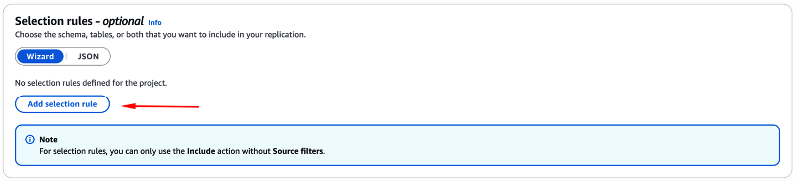
Figura 42 – Fornecendo a segunda parte das configurações do “data migration” que está sendo criado.
A partir da sessão que se abre “Rule settings“, utilizando-se do campo “Schema“, selecione a opção “Enter a schema” (Figura 43).
Você pode optar por considerar todos os schemas do seu banco de dados origem, mantendo o “Schema name” com o valor de “%” (que é o wildcard que define “todos” em consultas SQL), ou você pode indicar um schema específico, digitando o nome do mesmo.
A regra vale para a definição das tabelas a serem consideradas, onde você pode manter “%“, ou especificar o nome de uma tabela em especial.
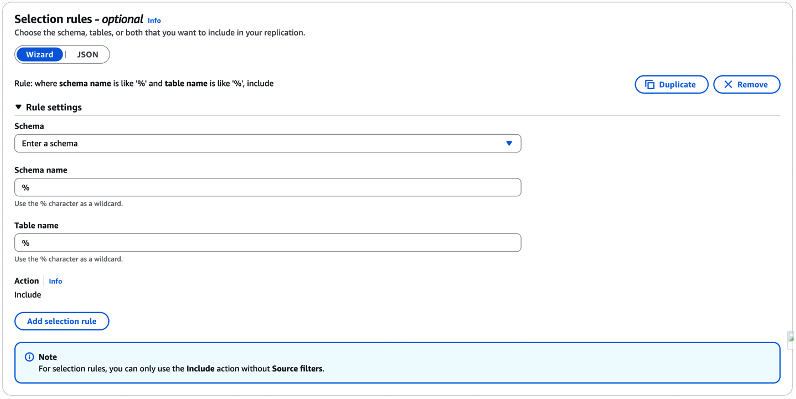
Figura 43 – Fornecendo a terceira parte das configurações do “data migration” que está sendo criado.
Com a regra de migração definida, você irá agora especificar uma AWS IAM Role, para que o DMS possa ter os acessos necessários para outros serviços AWS, como por exemplo, o AWS CloudWatch.
Você precisará criar esta IAM Role de previamente, para que possa então selecioná-la. Caso você necessite de uma referência (JSON exemplo), você poderá utilizar o weblink “permissions“.
No exemplo da imagem abaixo (Figura 44), o nome da IAM Role utilizada é “dms-migration-role-teste”, mas fique a vontade para definir o nome de sua escolha.
Para finalizar, a partir da sessão “Stop mode settings“, você precisará definir até que momento do tempo seu Migration Project funcionará. Em nosso exemplo, manteremos a rotina de CDC funcionando de maneira ininterrupta. Para isso selecione a opção “Do not stop CDC“.
Com todas as opções configuradas, clique no botão “Create data migration“.
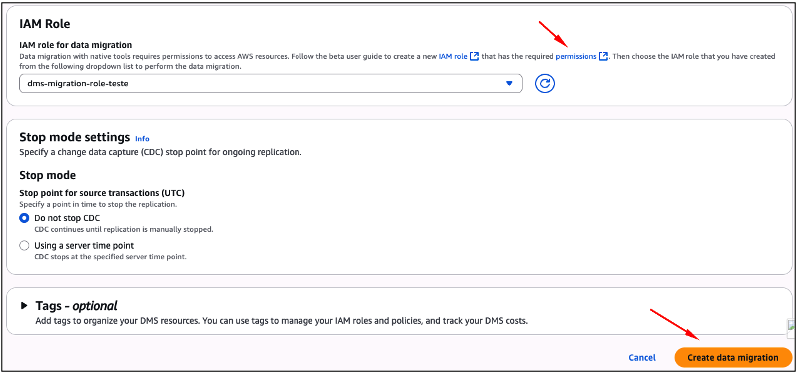
Figura 44 – Finalizando as configurações do “data migration” que está sendo criado.
Ao final da etapa de configuração, seu Data migration estará disponível na lista “Associated data migrations“, com o status “Ready” (Figura 45).
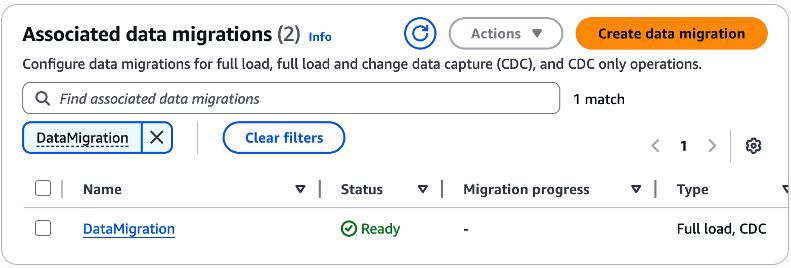
Figura 45 – “Data migration” recém configurado, disponível na lista de “Associated data migrations”.
Selecione seu Data migration utilizando-se do check-box equivalente, clique no botão “Actions“, e escolha a opção “Start” (Figura 46).
Esta ação fará com que seu Migration project seja iniciado.
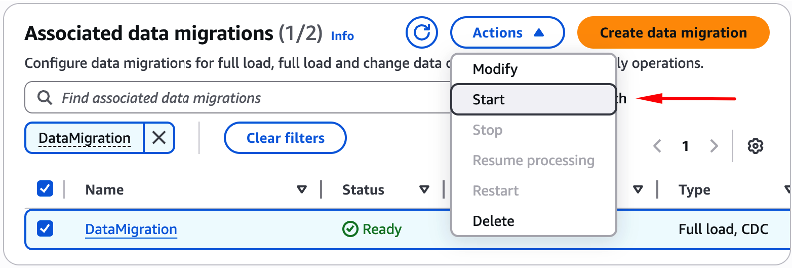
Figura 46 – Iniciando o “Migration project” recém configurado.
Após selecionar a opção “Start“, clique sobre o nome do “Data Migration” recém iniciado (Figura 47).
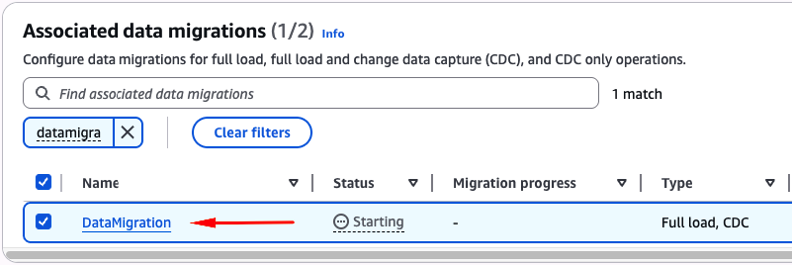
Figura 47 – Acessando os detalhes do “Data Migration”, recém iniciado.
Você será levado para a tela onde poderá acompanhar a atividade de início do “Data Migration” (Figura 48).
A partir desta tela, você poderá também constatar que, pelo fato da escolha de se ter os logs registrados no Amazon CloudWatch, você notará o indicador como “On“.
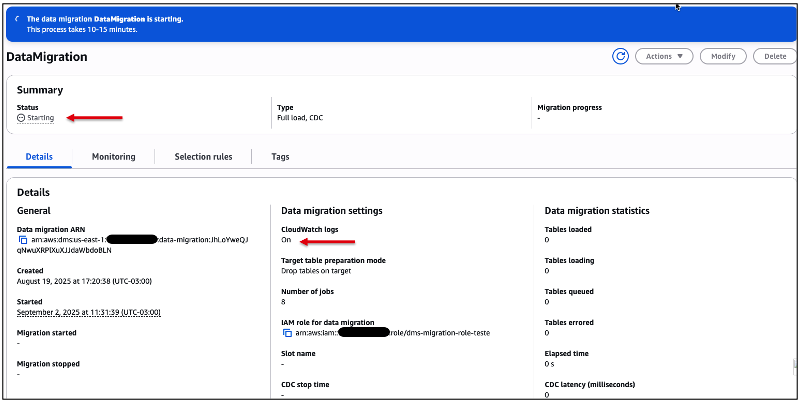
Figura 48 – Acompanhando a execução do “Data Migration”, recém iniciado.
Após início da rotina de sincronização do “Data Migration”, você poderá acompanhar os detalhes do andamento através do Amazon CloudWatch, clicando na opção indicada na figura abaixo (Figura 49).
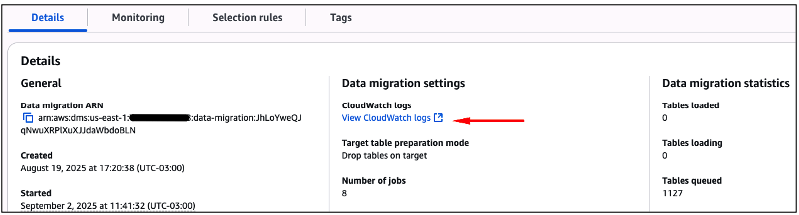
Figura 49 – Acessando os detalhes da execução do “Data Migration”, através do Amazon CloudWatch.
Ao clicar na opção de visualização do CloudWatch Logs, você será levado à tela onde poderá acompanhar o Log Group com as informações relacionadas a sincronização (Figura 50).
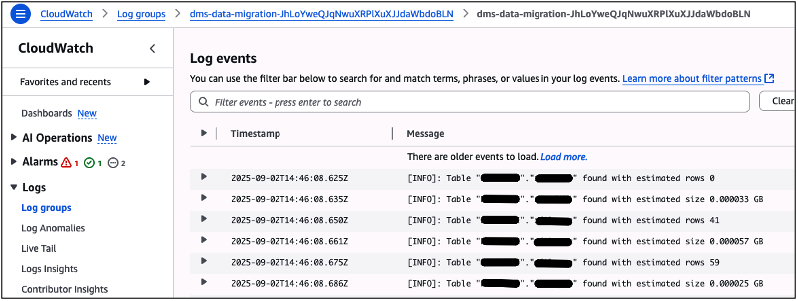
Figura 50 – Exemplo de linhas de log no Amazon CloudWatch, relacionados à execução do “Data Migration”.
A partir deste ponto, se todos os passos foram executados com sucesso, você terá o seu Data Migration com o indicador de progresso “Complete“, e com o status “Load complete, replication ongoing“, indicando que a operação de replicação permanecerá continuamente em execução (Figura 51).

Figura 51 – “Data Migration” com o status de “Complete”, e em execução contínua.
Efetuando o “cut-over”, pós sincronização realizada
Após o período de sincronização das bases de dados origem e destino, chegará o momento que você optará pela operação de “cut-over“, que compreende o momento no qual você decide realizar o chaveamento de uso, entre a base de dados origem, e destino.
Realizar o “cut-over“, significa que você precisará realizar a operação de “Stop” no Data Migration utilizado durante a sincronização.
Para isso, utilizando a console do serviço AWS DMS, escolha a opção “Migration Project“, e clique sobre o nome do Migration project utilizado.
A partir da tela que se abre, selecione a aba “Data migration“, clicando sobre o nome do Data migration utilizado.
Na tela do Data migration, clique no botão “Actions“, e escolha a opção “Stop“.
Alguns segundos depois, o status do Data migration se tornará “Stopped” (Figura 52).

Figura 52 – “Data migration” em status “Stopped”.
Benefícios do Convert and Migrate em comparação ao método tradicional
Eliminação do uso da instância de replicação, usualmente presente no uso convencional do DMS.
O principal diferencial do Convert and Migrate é que não é necessário provisionar e gerenciar uma instância de replicação, o que traz diversos benefícios:
- Redução de custos: Não necessidade de se arcar com os custos de uma instância EC2, dedicada ao processo de replicação.
- Simplificação operacional: Eliminação da necessidade de gerenciamento, monitoração, e manutenção de recursos adicionais.
- Configuração simplificada: Interface intuitiva que guia o usuário pelo processo de migração.
- Menor tempo de configuração: Redução significativa do tempo necessário para o início uma migração.
Casos de uso ideias
O Convert and Migrate é especialmente vantajoso para:
- Migrações pontuais (one-time) de bancos de dados.
- Empresas com recursos limitados de TI.
- Projetos de curto prazo.
- Organizações que buscam reduzir custos operacionais.
Conclusão
Neste blog post, demonstramos como realizar uma migração de ponta a ponta de um banco de dados PostgreSQL local para o Amazon RDS usando o AWS DMS Convert and Migrate. Esta funcionalidade representa uma evolução significativa na forma como as migrações de bancos de dados são realizadas na AWS. Ao eliminar a necessidade de instâncias de replicação e simplificar todo o processo, a AWS oferece uma solução mais acessível e eficiente, permitindo que as organizações foquem mais em seus dados e menos na infraestrutura necessária para migrá-los.
Para saber mais sobre o AWS DMS Convert and Migrate, consulte a [documentação oficial do serviço].
Autores
 |
Marcelo Oliveira é Solutions Architect no time AWS. Apoia clientes do setor DNB (Digital Native Business) em sua jornada para nuvem AWS. Tem foco em projetos que envolvam arquiteturas distribuídas e escaláveis, além de grande interesse na área de Infraestrutura, Networking, Segurança e Containers. |
 |
Ernesto dos Santos (Tito) é Senior Solutions Architect na AWS. Apoia clientes ISV (Independent Software Vendor) em sua jornada para a nuvem AWS. Tem foco em projetos que envolvam arquiteturas distribuídas e escaláveis, além de grande interesse em Cyber Security, Infraestrutura, Networking e Containers. |
 |
Diogo Nomura é arquiteto de soluções especialista em banco de dados, trabalha com tecnologia há mais de 20 anos, sendo 4 na AWS. Tem interesses por banco de dados, tecnologia, sketching and literatura em geral. |