O blog da AWS
Reduzindo custos do EKS em 35% com ajustes no Karpenter
Por Rafael Barbosa, Arquiteto de Soluções Sênior para o setor Financeiro na AWS; Marcio Passos Ribeiro líder do time K8s Captains na Stone e Johnny Tardin, Site Reliability Engineer (SRE) na Stone.
À medida que as organizações escalam suas cargas de trabalho no Amazon Elastic Kubernetes Service (Amazon EKS), serviço gerenciado da AWS para executar Kubernetes, as equipes de plataforma enfrentam um dilema clássico: equilibrar a alta disponibilidade com a eficiência de custos. Regras rígidas de anti-afinidade de pods e configurações conservadoras de autoscaling frequentemente resultam na proliferação de infraestrutura, onde uma vasta quantidade de nós operam com baixa taxa de utilização.
Sobre a plataforma Karavela
Antes de mergulhar nas otimizações, é fundamental entender o contexto. A Karavela é a Plataforma Interna de Desenvolvedores (IDP) da Stone, construída sobre o Amazon EKS. Ela fornece clusters Kubernetes padronizados em múltiplos ambientes (produção, staging e sandbox), servindo como fundação para todas as cargas de trabalho containerizadas da empresa.
A plataforma impõe padrões consistentes de networking, segurança e observabilidade, permitindo que os desenvolvedores façam o deploy de aplicações sem precisarem gerenciar a complexidade da infraestrutura subjacente.
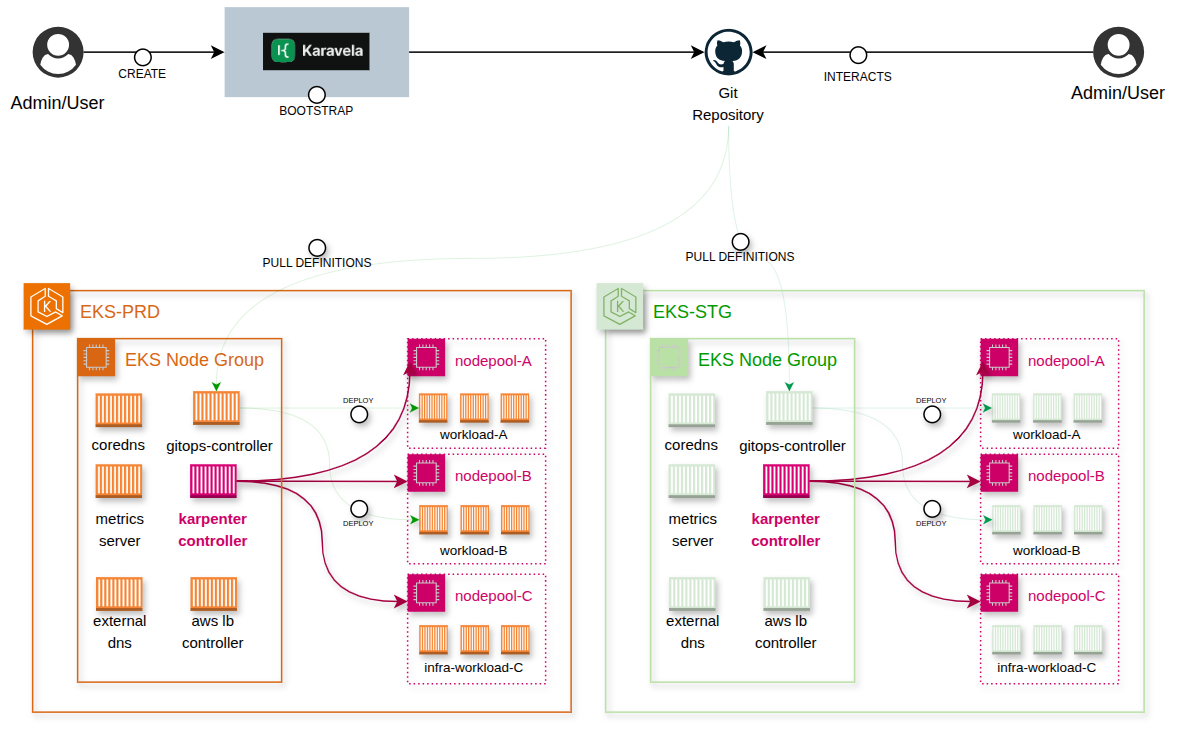
O desafio: Baixa densidade e desperdício de recursos
A equipe de plataforma identificou gargalos interconectados que estavam afetando a eficiência de custos:
- Proliferação de instâncias pequenas: A análise revelou que o cluster estava criando numerosas instâncias do tipo large em vez de consolidar cargas de trabalho em nós maiores, consequentemente diminuindo a quantidade de nós. Esse padrão emergiu de uma combinação de configurações padrão do Karpenter e configurações de deploy das aplicações.
- Regras agressivas de anti-afinidade: Muitas aplicações utilizavam configurações de podAntiAffinity topologySpreadConstraints restritivas com maxSkew definido como 1, o que permitia somente um domínio de desequilíbrio por hostname. Embora isso garantisse distribuição máxima para alta disponibilidade, forçava a criação de muitos nós com poucas réplicas em cada nó. Uma aplicação com 100 réplicas solicitando 200 millicores por pod poderia exigir 100 nós, utilizando apenas 10% da capacidade de cada nó e desperdiçando 90% dos recursos provisionados.
- Esgotamento de endereços IP: A proliferação de nós consumia endereços IP das subnets da VPC a uma taxa insustentável, criando desafios operacionais à medida que as subnets se aproximavam dos limites de capacidade.
- Desperdício no ambiente de staging: As mesmas regras rígidas de disponibilidade e anti-afinidade aplicadas em produção também eram impostas em ambientes de staging, onde alta disponibilidade é tipicamente desnecessária. Isso dobrava a ineficiência para cargas de trabalho de pré-produção.
- Ciclos lentos de consolidação: A configuração padrão do Karpenter de consolidateAfter (parâmetro que controla o tempo de espera antes da consolidação) de 10 minutos mostrou-se excessiva para os padrões dinâmicos de carga de trabalho da Stone. O scheduler do Kubernetes alocava novos pods em nós subutilizados antes que o Karpenter pudesse consolidá-los, “resetando” o timer e impedindo a remoção do nó.
- Falta de preferência por Spot e bloqueio de consolidação: Sem uma preferência explícita configurada, o scheduler frequentemente alocava pods compatíveis com Spot em nós On-Demand ociosos (devido à lógica padrão de bin-packing, que busca acomodar mais cargas de trabalho em menos nós para maximizar o uso dos recursos). Isso gerava dois problemas: pagava-se mais caro desnecessariamente e a presença desses pods impedia o Karpenter de eliminar o nó On-Demand subutilizado.Para que o Karpenter priorize Spot mas utilize On-Demand automaticamente em momentos de escassez, é crucial não utilizar seletores rígidos nos manifestos da aplicação. Para priorizar Spot com fallback para On-Demand, evite usar nodeSelector ou affinity rígidos para instâncias Spot nos manifestos. Se você forçar a label de Spot via manifesto, o scheduler fica proibido de usar On-Demand caso falte capacidade Spot, causando indisponibilidade.
Esse padrão gerava dois impactos significativos na eficiência do cluster:
Aumento de custos: Cargas de trabalho compatíveis com Spot permaneciam executando em instâncias On-Demand mais caras, mesmo havendo disponibilidade de capacidade Spot mais econômica no cluster.
Bloqueio da consolidação: A presença de pods agendados desnecessariamente em um nó On-Demand era suficiente para impedir o Karpenter de consolidar aquele nó. Isso prolongava a existência de instâncias mais caras que poderiam ser eliminadas, e seus pods alocados em nós menores ou em outros nós.
Em ambientes de grande escala, esse comportamento causa desperdício acumulado significativo, reduzindo a eficiência geral do cluster e comprometendo a estratégia de otimização de custos baseada em instâncias spot.

Visão geral da solução
A estratégia de otimização focou em três pilares: habilitação da consolidação ativa, ajuste fino dos tempos de consolidação e relaxamento das restrições de densidade. Essas mudanças atuaram em conjunto para permitir que o Karpenter empacotasse cargas de trabalho de forma mais eficiente, enquanto mantinha garantias de disponibilidade.
O fluxo de trabalho é o seguinte:
- O Karpenter monitora ativamente a utilização dos nós e identifica oportunidades de consolidação durante janelas de disrupção agendadas.
- Quando a consolidação é acionada, o Karpenter drena pods de nós subutilizados e os reagenda em nós existentes com capacidade disponível.
- Nós vazios são terminados imediatamente, enquanto nós elegíveis para consolidação são removidos após um período de carência configurável.
- Para cargas de trabalho de CI/CD com jobs de curta duração, configurações agressivas de consolidação garantem remoção rápida de nós após a conclusão do job.
Pré-requisitos
Para implementar otimizações similares em seu ambiente, você precisará de:
- Uma conta AWS com um cluster Amazon EKS existente (versão 1.24 ou posterior).
- Karpenter instalado e configurado (versão 0.27 ou posterior recomendada).
- AWS Command Line Interface (AWS CLI) configurada.
- Ferramenta CLI kubectl instalada e configurada para acesso ao cluster.
- Helm 3.9+ (se gerenciando o Karpenter via Helm).
- Permissões IAM para modificar configurações do Karpenter e node pools.
- Ferramentas de monitoramento para rastrear utilização de nós e custos (como Kubecost, para visibilidade de custos em Kubernetes, ou AWS Cost Explorer, para análise de custos e uso na AWS).
Passo a passo
Passo 1: Habilitar budgets de disrupção para consolidação controlada
A primeira otimização envolveu mover de remoção passiva de nós para consolidação ativa. Por padrão, o Karpenter apenas remove nós quando ficam completamente vazios (política whenEmpty). A Stone implementou budgets de disrupção para permitir que o Karpenter consolidasse ativamente nós subutilizados durante janelas agendadas.
Edite sua configuração de NodePool do Karpenter para adicionar budgets de disrupção:
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
budgets:
- nodes: "10%"
schedule: "*/15 * * * *" # Janela a cada 15 minutos
duration: 15mEsta configuração cria quatro janelas de 15 minutos por hora, durante as quais o Karpenter pode interromper até 10% dos nós para consolidação. O limite percentual assegura que a consolidação ocorra gradualmente sem sobrecarregar o cluster com reagendamento de pods.
Aplique a configuração:
kubectl apply -f nodepool-disruption.yamlVerifique a configuração do NodePool:
kubectl get nodepool default -o yamlPasso 2: Ajustar o parâmetro consolidateAfter
O valor padrão de 10 minutos para consolidateAfter provou ser muito excessivo para os padrões de carga de trabalho. Novos pods eram frequentemente agendados em nós subutilizados antes que o timer de consolidação expirasse, resetando a contagem regressiva e prevenindo a remoção de nós.
Após testes em um cluster de não-produção, foi reduzido esse valor para 30 segundos para cargas de trabalho gerais:
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 30sEsta configuração permite que o Karpenter identifique e aja rapidamente em oportunidades de consolidação. O insight chave é que 30 segundos são suficientes para o scheduler do Kubernetes colocar quaisquer pods pendentes, após esse período, o Karpenter pode avaliar com segurança se um nó deve ser consolidado.
Consideração importante: Esta configuração deve ser ajustada com base nas características da sua carga de trabalho. Clusters com agendamento de pods muito frequente podem precisar de valores ligeiramente maiores para evitar ciclos repetitivos de consolidação.
Passo 3: Otimizar consolidação de runners de CI/CD
Para pods de runners do GitHub Actions, a Stone implementou uma configuração ainda mais agressiva. Jobs de CI/CD são tipicamente de curta duração e em rajadas, causando ociosidade dos nós após a execução dos jobs. O delay padrão de consolidação de 30 segundos ainda era muito longo para este caso de uso.
Crie um NodePool separado para cargas de trabalho de CI/CD.
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: github-runners
spec:
disruption:
consolidationPolicy: WhenEmpty
consolidateAfter: 2s # Remoção quase instantânea após o fim do job
template:
metadata:
labels:
workload-type: ci-cd
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"] # on-demand como fallback
nodeClassRef:
name: default
group: karpenter.k8s.aws
kind: EC2NodeClassConfigure seus pods de runner do GitHub para direcionar este NodePool:
apiVersion: v1
kind: Pod
metadata:
name: github-runner
spec:
nodeSelector:
workload-type: ci-cd
containers:
- name: runner
image: <sua-imagem-de-runner>
resources:
requests:
cpu: 200m
memory: 512MiCom um valor de consolidateAfter de 2 segundos, os nós são removidos quase imediatamente após os pods de runner completarem, minimizando o tempo ocioso. Esta otimização sozinha reduziu os custos de infraestrutura de CI/CD de 73%.
Passo 4: Reduzir restrições de anti-afinidade de pods
Originalmente, as aplicações utilizavam podAntiAffinity estrita com maxSkew: 1, forçando cada réplica a ocupar um nó exclusivo em sua maioria. A equipe redefiniu essa estratégia aplicando regras de densidade baseadas no tamanho e na criticidade de cada carga de trabalho. Essa abordagem passou a permitir múltiplas réplicas por nó, preservando, contudo, a preferência pela distribuição entre zonas de disponibilidade para garantir a resiliência.
Exemplo da configuração estrita original:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 100
selector:
matchLabels:
app: example-app
template:
metadata:
labels:
app: example-app
spec:
topologySpreadConstraints:
- maxSkew: 1 # Permitia um desequilíbrio de até 1 pod por nó
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: example-app
- maxSkew: 1 # Permitia um desequilíbrio de até 1 pod por zona
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway # Preferência suave
labelSelector:
matchLabels:
app: example-app
containers:
- name: app
image: k8s.gcr.io/pause:3.9Configuração otimizada permitindo maior densidade:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 100
selector:
matchLabels:
app: example-app
template:
metadata:
labels:
app: example-app
spec:
topologySpreadConstraints:
- maxSkew: 4 # Permite um desequilíbrio de até 4 pods por domínio
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
minDomains: 5
labelSelector:
matchLabels:
app: example-app
- maxSkew: 1 # Ainda mantém distribuição por AZ
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway # Preferência suave
labelSelector:
matchLabels:
app: example-app
containers:
- name: app
image: k8s.gcr.io/pause:3.9Isso significa que o cluster aceita um desequilíbrio de até 4 pods entre os nós, permitindo maior densidade de réplicas na mesma máquina. Essa estratégia aumenta drasticamente a eficiência de CPU e memória ao evitar o espalhamento forçado da regra anterior, enquanto a distribuição entre Zonas de Disponibilidade (AZs) mantém a garantia de tolerância a falhas.
Passo 5: Diferenciar configurações de staging e produção
A Stone removeu restrições desnecessárias de alta disponibilidade de ambientes de staging, onde tolerância a falhas é menos crítica. Isso foi realizado usando diferentes configurações de NodePool e manifestos de deployment por ambiente.
Para ambientes de staging, use restrições de topologia mais simples:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 100
selector:
matchLabels:
app: example-app
template:
metadata:
labels:
app: example-app
spec:
topologySpreadConstraints:
- maxSkew: 5
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway # Preferência suave
labelSelector:
matchLabels:
app: example-app
containers:
- name: app
image: k8s.gcr.io/pause:3.9Esse ajuste permite que o scheduler compacte pods com mais liberdade em staging — reduzindo a pegada de nós — enquanto ainda prioriza uma distribuição equilibrada entre zonas de disponibilidade quando houver capacidade disponível.
Resultados e impacto
As otimizações combinadas entregaram melhorias significativas em múltiplas dimensões:
Redução de custos: O impacto mais expressivo ocorreu na infraestrutura de CI/CD, que registrou uma queda de 73% nos custos diários com runners do GitHub. Simultaneamente, os custos gerais do cluster diminuíram de forma substancial, reflexo direto da redução na contagem de nós e do aumento na eficiência da utilização.
Melhor aproveitamento dos recursos computacionais: Em determinados clusters, a taxa de desperdício de recursos foi reduzida de cerca de 40% para 15% em média, permitindo manter o desempenho com menos nós.

Melhorias operacionais: A contagem reduzida de nós simplificou o gerenciamento do cluster e diminuiu a taxa de consumo de endereços IP nas subnets da VPC.
Trade-offs de performance (CI/CD): Identificamos um aumento marginal na latência de inicialização (cold start) restrito aos NodePools de CI/CD. Esse atraso ocorre pontualmente, apenas quando o provisionamento de novos nós é necessário. No entanto, esse tempo adicional é pequeno e totalmente negligenciável frente à redução de custos e aos ganhos operacionais obtidos.
Considerações importantes
Ao implementar otimizações similares, considere o seguinte:
Teste em não-produção primeiro: A Stone validou todas as mudanças de configuração em um cluster de teste antes de aplicá-las em produção. Isso permitiu que a equipe identificasse os valores ótimos de consolidateAfter e entendesse o impacto nos padrões de agendamento de pods.
Monitore o comportamento de consolidação: Use métricas e logs do Karpenter para entender padrões de consolidação. As métricas karpenter_nodes_terminated e karpenter_consolidation_actions fornecem visibilidade sobre a frequência com que nós estão sendo consolidados e se as configurações estão muito agressivas.
Equilibre densidade e disponibilidade: Embora maior densidade de pods reduza custos, garanta que você mantenha tolerância a falhas suficiente para cargas de trabalho de produção. A Stone manteve distribuição estrita por AZ mesmo relaxando restrições por nó.
Considere características da carga de trabalho: O valor ótimo de consolidateAfter depende da sua frequência de agendamento de pods. Cargas de trabalho com alta rotatividade de pods podem precisar de valores maiores para evitar tentativas excessivas de consolidação.
Budgets de disrupção, Pod Disruption Budgets (PDBs) e annotations para proteção em camadas: O budget de disrupção de 10% assegura que a consolidação dos nós aconteça de forma gradual, evitando picos de evicção. No entanto, é indispensável o uso conjunto de Pod Disruption Budgets (PDB), que impedem o Kubernetes de autorizar a remoção de pods se isso violar a disponibilidade mínima do serviço. Por fim, para cargas de trabalho sensíveis que não podem sofrer interrupção alguma (como batch jobs críticos ou processos stateful sensíveis), utilize a annotation karpenter.sh/do-not-disrupt: “true”. Essa configuração instrui o Karpenter a ignorar completamente o nó durante os ciclos de consolidação, protegendo o pod até que termine sua execução
NodePools separados para diferentes tipos de carga de trabalho: Cargas de trabalho de CI/CD se beneficiam de consolidação muito agressiva (2 segundos), enquanto aplicações de longa duração podem funcionar melhor com configurações mais conservadoras (30 segundos). Usar NodePools separados permite otimizar cada tipo de carga de trabalho independentemente.
Limpeza
Se você criou recursos de teste ao seguir este passo a passo, remova-os para evitar cobranças contínuas:
# Deletar NodePools de teste
kubectl delete nodepool github-runners# Se você criou um cluster de teste, delete-o
eksctl delete cluster --name karpenter-optimization-test --region us-east-1Conclusão
Neste post, demonstramos como a Stone reduziu seus custos de infraestrutura no Amazon EKS ajustando configurações do Karpenter e reduzindo restrições de agendamento de pods. Ao habilitar a consolidação ativa com budgets de disrupção, reduzir o parâmetro consolidateAfter para 30 segundos (e 2 segundos para cargas de trabalho de CI/CD) e permitir maior densidade de pods sem abrir mão da distribuição por zona de disponibilidade, a Stone alcançou 35% de redução de custos de infraestrutura e 73% de redução nos custos diários de runners do GitHub.
Essas otimizações destacam a importância de entender seus padrões de carga de trabalho e ajustar o comportamento de autoscaling de acordo com a criticidade da aplicação, a frequência de agendamento dos pods e os objetivos de custo e disponibilidade. Configurações padrão priorizam segurança e estabilidade, mas organizações frequentemente podem alcançar economias substanciais de custos ajustando cuidadosamente esses parâmetros com base em seus requisitos específicos.
Encorajamos você a analisar seus próprios clusters EKS para oportunidades de otimização similares. Comece examinando taxas de utilização de nós, revisando regras de anti-afinidade de pods e testando configurações mais agressivas de consolidação do Karpenter em ambientes de não-produção. Ajustar os parâmetros do Karpenter e das aplicações ao comportamento real da sua carga de trabalho é a chave para desbloquear economias substanciais. Para mais informações, veja os seguintes recursos:
- Documentação do Karpenter
- Guia de Melhores Práticas do Amazon EKS – Otimização de Custos
- Controles de Disrupção do Karpenter
Autores
 |
Rafael Barbosa com 17 anos de experiência em Tech e os últimos 10 mergulhado na nuvem AWS. Sou apaixonado por resolver problemas complexos em escala — geralmente envolvendo containers, segurança e aquele tipo de desafio onde uma decisão técnica errada pode custar caro (literalmente). Atualmente trabalho como Arquiteto de Soluções Sênior para o setor Financeiro na AWS,
onde ajudo grandes instituições a destravar programas críticos. Minha missão é traduzir complexidade técnica e regulatória em decisões claras e garantir que elas virem resultado de verdade. |
 |
Marcio Passos Ribeiro, tenho 38 anos de idade e somo 17 anos de experiência em Tech. Sou apaixonado por resolver problemas complexos — geralmente com Kubernetes no centro da história. Atualmente trabalho na Stone, onde lidero o time de K8s Captains, responsáveis pela infraestrutura que sustenta a plataforma interna da companhia. No dia a dia, atuo para manter os clusters saudáveis, as entregas fluindo e a vida dos times de produto mais tranquila (com boas doses de pragmatismo e bom humor) |
 |
Johnny Tardin é Site Reliability Engineer (SRE) na Stone, atuando na construção de plataformas Kubernetes resilientes e escaláveis em ambientes cloud. Entusiasta de otimização de custos e eficiência operacional, trabalha na simplificação de ambientes complexos por meio de práticas de engenharia de confiabilidade. |