Блог Amazon Web Services
Создание Auto Scaling Groups для Kubernetes в разных зонах доступности
Оригинал статьи: ссылка (Justin Garrison, Sr Developer Advocate, AWS containers team)
Kubernetes — это масштабируемый оркестратор контейнеров, который помогает проектировать отказоустойчивые приложения для облачной инфраструктуры. Также он позволяет обеспечить горизонтальную и вертикальную масштабируемость, управляет распределением контейнеров внутри кластера, и выделяет необходимые для работы вашего контейнера ресурсы.
Несмотря на то, что Kubernetes много чем управляет, он не может решить проблемы, о которых сам не знает. Это, так называемые «неизвестные неизвестные» (unknown unknowns) и находятся за пределами вашего приложения или API. Примером могут быть человеческие ошибки или природные катаклизмы.
Существуют факторы, которые системы типа Kubernetes не могут контролировать, но, если вы знаете ограничения вашего окружения, вы можете спроектировать ваши кластера для работы в рамках таких ограничений. В рамках AWS вы должны учитывать домены отказа и границы периметра сервисов, когда создаете кластеры, работающие в нескольких Регионах или нескольких Зонах доступности (AZ).
AWS относится к Регионам и Зонам доступности как к доменам отказа, что должно учитываться при проектировании высоко-доступной инфраструктуры. Если вы хотите, чтобы вебсайт продолжал работу даже в случае отказа какого-то конкретного Региона, вы должны запланировать развертывание в несколько Регионов. В каждом из Регионов, где развернуто приложение, вы должны использовать несколько Зон доступности для гарантии перераспределения трафика по двум или более доменам отказа.
Некоторые из перечисленных доменов отказа встроены в AWS сервисы в форме ограничений, позволяющих упростить проектирование ваших приложений и систем и избавить от непредсказуемых зависимостей. Например, если вам необходимо подключить Amazon EBS диск к EC2 инстансу, вы можете смонтировать EBS диск из определённой зоны доступности. В тоже время, хотя Amazon EBS доступен только в рамках одной зоны доступности, Amazon EFS можно использовать в нескольких зонах доступности в каждом Регионе. Другие сервисы, такие как IAM и Route 53 доступны глобально в рамках AWS аккаунта, и используют различные компромиссы для обеспечения производительности и доступности.
Запуск Kubernetes в рамках одной зоны доступности может обеспечить отказоустойчивость приложений в случае отказов единичных EC2 инстансов, но не сможет защитить от деградаций сервисов, распространяющихся на всю зону доступности. Рекомендуемой практикой считается создание высоко-доступного Kubernetes кластера, который распространяется на несколько зон доступности, чтобы приложения продолжали работать, даже в случае отказа одной из зон доступности.
В то же время одиночный Kubernetes кластер не должен использовать ресурсы инфраструктуры из нескольких AWS Регионов или работать через VPN или WAN подключения. Это продиктовано решениями проектирования, заложенными в Kubernetes на ранних стадиях — API-серверы и ноды с запущенными приложениями должны находиться в пределах надежного сетевого соединения с малой задержкой, чтобы избежать сегментации сети и необходимости реплицировать состояние через ненадежные соединения.
В AWS, рекомендуемым способом запуска высоко-доступного Kubernetes кластера является использование Amazon Elastic Kubernetes Service (EKS) с рабочими нодами, запущенными в трёх или более зонах доступности. Для приложений с требованием глобальной доступности, рекомендуется запускать разные EKS кластеры в разных Регионах с рабочими нодами в нескольких зонах доступности в каждом из Регионов.
Существует много способов создания рабочих нодов, распределенных по нескольким зонам доступности. Ниже мы рассмотрим наиболее надёжные способы запуска EKS кластеров и приложений в нескольких зонах доступности.
Важно отметить, что на контейнеры, которым не нужно сохранение состояния (stateless), не влияют ограничения, связанные с возможностью отказа зон доступности, но для них также есть преимущества, если настроить рабочие ноды с помощью Груп автоматического масштабирования (Auto-scaling Groups, ASG), которые учитывают распределение по зонам доступности.
Если в вашем приложении контейнеры сохраняют своё состояние во внешнем хранилище, таком как Amazon DynamoDB и отправляют файлы логов во внешние хранилища, как Amazon CloudWatch – в таких случаях гораздо проще справляться с отказами AZ. При такой конфигурации, балансировщики нагрузки (ELB, ALB или NLB), связанные с сервисами Kubernetes, позволяют перераспределить трафик по нескольким AZ, а DynamoDB имеет региональные точки доступа (endpoints) — например, https://dynamodb.us-west-2.amazonaws.com. Поэтому, отказ единичной AZ может потребовать переноса (re-schedule) подов, а также создания новых рабочих нодов (при помощи cluster autoscaler), но не должен повлиять на высоко-доступность вашего приложения.
Существует три способа для запуска рабочих нодов в нескольких AZ:
- Группы автоматического масштабирования (ASG) привязанные к конкретным AZ
- Регионально-распределённые группы автоматического масштабирования (ASG)
- Отдельные инстансы без ASG
Компонент автоматического масштабирования кластера Kubernetes (cluster autoscaler) является важным элементом обеспечения доступности вычислительных ресурсов вашего кластера. Этот пост не рассказывает о нюансах конфигурации данного компонента, или о методах оптимизации затрат. Дополнительную информация по лучшим практикам настройки данного компонента можно найти в этой статье.
ASG привязанные к конкретным AZ
Если ваши Kubernetes поды используют EBS тома, то нужно настроить ASG таким образом, чтобы было по одной ASG в каждой AZ, где могут быть запущены приложения. Это позволит определять метки доменов отказа с помощью групп рабочих нод (например, topology.kubernetes.io/zone=us-west-2b), и запускать поды на нодах в конкретных AZ.
Данные метки будут автоматически добавлены на рабочие инстансы с помощью интеграции Kubernetes с облаком AWS, а также к PersistentVolumes с помощью AWS EBS CSI драйвера. Это означает, что назначение пода на инстанс и создание EBS тома – будет прозрачным для вас при первичном запуске пода. Если под, использующий EBS том, будет перенесен, или инстанс будет удалён, то нужно убедиться, что под имеет nodeSelector соответствующий ярлыку топологии вашего кластера, и вам может потребоваться отдельное развёртывание Kubernetes (deployment) в рамках каждой AZ.
Причина, по которой нужно иметь ASG на каждую AZ – это ситуации, когда у вас нет необходимых вычислительный ресурсов в конкретной AZ. Например, ASG в AZ us-west-2b достигла максимальной ёмкости, а поду необходимо для работы иметь доступ к тому EBS в этой AZ. Компонент масштабируемости кластера (cluster autoscaler) должен иметь возможность добавить ресурсы для этой AZ, чтобы под смог запуститься.
Если вы запускаете ASG, распределённую по нескольким AZ, то компонент масштабируемости кластера (cluster autoscaler) не имеет возможности выбрать, в какой из AZ будет запущен новый инстанс. В этом случае, мы сможем добавить недостающие ресурсы в рамках ASG, но может потребоваться несколько попыток, прежде чем инстанс будет создан в нужной нам AZ.
В случае недоступности всей AZ, тома EBS в данной AZ будут недоступны, и все поды, работающие с этими томами, не смогут запуститься.
Ниже приведен пример StatefulSet конфигурации, которой необходим PersistentVolume в AZ us-west-2b. Обратите внимание, что пример показывает часть настроек, связанных с привязкой хранилища к MySQL контейнеру, но не является полноценно-рабочим примером StatefulSet. Для запуска полного примера StatefulSets в Kubernetes, ознакомьтесь с соответствующим разделом в EKS workshop.
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: mysql
name: mysql
spec:
selector:
matchLabels:
app: mysql
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: mysql-gp2
resources:
requests:
storage: 10GiВ общем случае, планировщик Kubernetes имеет возможность запустить под в правильной AZ, необходимой для EBS тома. Основным преимуществом наличия нескольких ASG является их взаимодействие с компонентом автоматического масштабируемости кластера Kubernetes и гарантии добавления вычислительных ресурсов в той же AZ, где расположены тома EBS.
В случае конфигурации с одной ASG для каждой AZ, нужно настроить компонент автоматического масштабирования кластера отдельно для каждой ASG. Вы сможете найти пример такой конфигурации на Github: Kubernetes examples on GitHub.
Для создания EKS кластера c одной ASG на каждую из AZ в us-west-2a, us-west-2b, и us-west-2c, вы можете использовать файл настроек для утилиты eksctl, и использовать его для создания кластера, как в примере ниже.
cat <<EOF | eksctl create cluster --file -
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: multi-asgs
region: us-west-2
nodeGroups:
- name: ng1
instanceType: m5.xlarge
availabilityZones:
- us-west-2a
- name: ng2
instanceType: m5.xlarge
availabilityZones:
- us-west-2b
- name: ng3
instanceType: m5.xlarge
availabilityZones:
- us-west-2c
EOFБольше информации о масштабировании, учитывающем AZ, и об утилите eksctl, можно найти в документации здесь.
Подход с запуском ASG для каждой AZ подразумевает дополнительные затраты времени и ресурсов на управление этими дополнительными ASG, и бОльшим количеством Kubernetes развёртываний (по одному на каждую AZ). Если вы можете избежать использования EBS томов в подах, то более простым подходом будет изпользование одной ASG, распределённой по нескольким AZ и использование EFS в качестве локального хранилища для подов.
Регионально-распределённые ASG
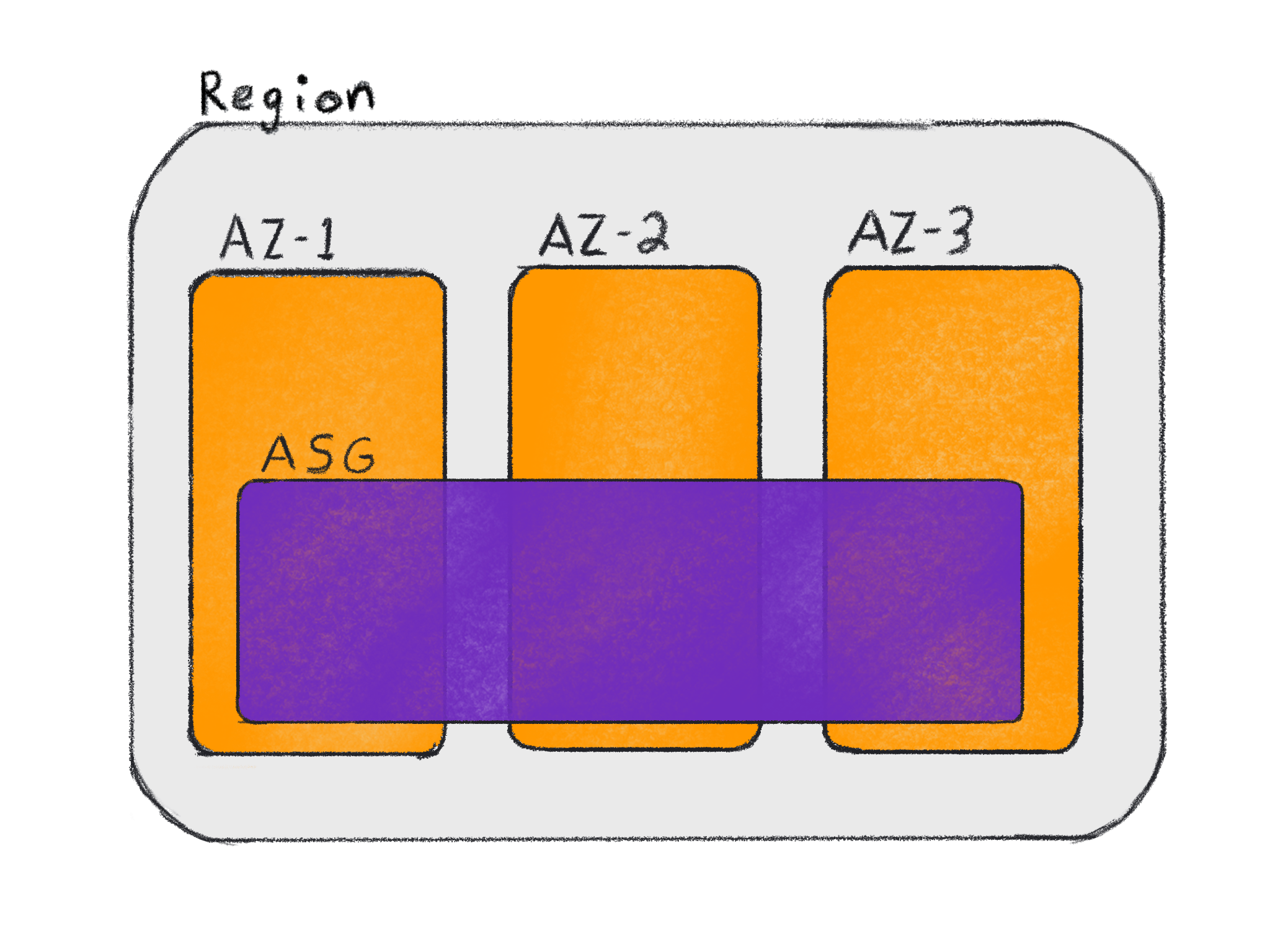
Весомой причиной использования Auto Scaling Groups в Kubernetes является то, что они позволяют вам автоматически масштабировать кластер Kubernetes для добавления вычислительных ресурсов в кластер. Региональные ASG позволяют распределить ресурсы по нескольким AZ, что позволяет приложениям быть устойчивыми к отказам или отключению ресурсов в рамках одной AZ.
ASG, распределённые по нескольким AZ, также могут использовать функционал авто-масштабирования кластера, а также любых других триггеров для масштабирования, предоставляемых AWS. Это может быть масштабирование кластера на основе внутренних метрик, а также внешних источников, как Amazon EventBridge.
ASG, распределённые по нескольким AZ, не могут масштабироваться в рамках конкретной AZ, но, если ваше приложение не использует ресурсы, специфичные для AZ (например EBS тома), тогда это не является ограничивающим фактором. Если вы можете использовать EFS или RDS для сохранения состояния вашего контейнера, то вы должны использовать именно такую конфигурацию: ASG, распределённую по нескольким AZ.
Использование одной ASG упрощает архитектуру, конфигурацию и взаимодействия между компонентами, что означает, что ваша система проще для понимания и для отладки. Также это упрощает Kubernetes развёртывание (одно на Регион) и упрощает устранение неполадок, так как что нужно отлаживать и проверять меньше компонентов.
Для создания EKS кластера с одной ASG и тремя AZ, используйте следующую команду:
eksctl create cluster --region us-west-2 --zones us-west-2a,us-west-2b,us-west-2cЕсли вам всё-таки необходимо в данной конфигурации использовать EBS тома, вы можете поменять настройку по-умолчанию для VolumeBindingMode на WaitForFirstConsumer, как описано в документации здесь. Изменение данной настройки приведёт к следующему поведению: “привязка и создание PersistentVolume будет отложена до момента, пока не будет создан под, использующий соответствующий PersistentVolumeClaim (PVC).” Тогда PVC будет создан в той же AZ, что и под, которому нужен PersistentVolume.
Если под удален, пересоздан или расформирован (descheduled), или инстанс, где был запущен под будет удален, тогда настройка WaitForFirstConsumer не поможет, потому что она применяется только к первому поду, который использует том. Когда под пере-использует существующий EBS том, то существует вероятность, что под будет запущен в AZ, где EBS том не существует.
Инстансы без ASG

Хотя вы можете запускать инстансы и без ASG, но в таком случае не получится использовать компонент авто-масштабирования кластера, работающий с провайдером AWS. Вы всё ещё можете воспользоваться другим провайдером, таким как как cluster-api, но тогда вы теряете некоторые возможности AWS при управлении отдельными инстансами EC2 вместо с ASG (например, масштабирование на основе CloudWatch метрик).
В общем случае не рекомендуется использовать EKS cluster с инстансами, не находящимися под управлением ASG, если только вы не используете другой сервис обеспечивающих создание новых инстансов и их учёт. Если вам интересно использование cluster-api совместно с ASG, то вам следует ознакомиться с подходом MachinePools.
Также нужно учитывать, что некоторые установщики (например, kops) создают ASG с настройками minimum, maximum, и desired count равными 1 для управляющих инстансов кластера. Такая настройка не подходит для масштабирования управляющих инстансов кластера, но позволяет легко заменить неисправный инстанс на новый, без опасения потери данных из-за использования EBS томов для хранения состояния.
Другие нюансы
Endpoints балансировщика нагрузки
Когда вы запускаете сервисы, распределённые по нескольким AZ, вам нужно проверить настройку externalTrafficPolicy в сервисе для уменьшения трафика между разными AZ. Значение по умолчанию для externalTrafficPolicy=“Cluster,” что позволяет каждой рабочей ноде в кластере принимать трафик каждого сервиса, вне зависимости от того, запущен ли на данной ноде под для этого сервиса или нет. Трафик затем перенаправляется на нужный нод с запущенным сервисом, с помощью kube-proxy.
Такой подход в целом выглядит нормально для небольших кластеров, или кластеров в рамках одной AZ. Но, когда ваше приложение начинает масштабироваться, у вас появляется больше копий подов для сервиса, которые могут быть запущены на разных нодах, а значит увеличивается вероятность, что появится дополнительная промежуточная точка передачи трафика перед тем, как будет достигнут инстанс, где непосредственно запущен под нужного сервиса.
Если установить externalTrafficPolicy=Local, только инстансы, на которых запущен контейнер сервиса, будут подключены к его балансировщику нагрузки, что уменьшит количество соединений на балансировщике и количество точек прохождения трафика до конечного пода.
Другим преимуществом использования Local политики является возможность сохранить исходный IP адрес вашего запроса. Так как пакеты маршрутизируются через балансировщик нагрузки прямо инстанс с вашим сервисом, то IP адрес из оригинального запроса может быть сохранён без дополнительного прохождения через kube-proxy.
Пример объекта сервиса с настройкой externalTrafficPolicy может выглядеть вот так:
apiVersion: v1
kind: Service
metadata:
name: example-service
spec:
selector:
app: example
ports:
- port: 8765
targetPort: 9376
externalTrafficPolicy: Local
type: LoadBalancerЕсли вы устанавливаете externalTrafficPolicy, то также имеет смысл установить anti-affinity подов для вашего деплоймента. Без anti-affinity подов существует вероятность, что все поды в итоге окажутся на одном инстансе, что может повлияет на отказоустойчивость приложения, если инсанс по какой-то причине деградирует.
Если инстансы содержат несбалансированное количество реплик пода, это также может оказаться проблемой. Балансировщики нагрузки не знают, сколько подов каждого сервиса запущено на конкретном инстансе, а только то, что этот инстанс принимает трафик на определенном порту. Если у вас два инстанса и три пода, то оба инстанса получат по 50% трафика, но в итоге два пода получат только по 25% трафика, так как локальный kube-proxy распределит полученные запросы.

Такая несбалансированность может оказаться гораздо хуже, если у вас больше инстансов и контейнеров. Kubernetes не будет перераспределять копии подов по новым нодам, добавленным в кластер, если только вы не будете вручную регулярно запускать команду наподобие descheduler.

Для настройки anti-affinity подов на основе hostname, нужно добавить такой фрагмент к вашему деплойменту:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-app
topologyKey: kubernetes.io/hostnameПри наличии anti-affinity подов трафик, возможно, не будет распределён одинаково по всем копиям подов, но, по крайней мере, при запуске подов планировщик Kubernetes постарается одинаково распределить контейнеры по запущенным инстансам. Всё еще может иметь смысл периодически запускать descheduler, если размер вашего кластера меняется время-от-времени, а ваши поды не масштабируются так же часто.

Сервисная топология
Благодаря тому, как Kubernetes интегрируется в AWS с помощью cloud provider, есть преимущество, которое можно получить вне зависимости от того, как настроены ваши ASG. Сервисная топология была выпущена как alpha функционал в Kubernetes 1.17. Она позволяет учитывать домены отказа AWS без дополнительной конфигурации инфраструктуры со стороны клиента.
EKS не позволяет использовать функционал в стадии alpha, поэтому вы можете или запустить свою сборку Kubernetes или подождать, пока функционал Сервисной топологии не перейдёт в стадию Beta в будущих версиях Kubernetes.
По умолчанию под определяет точку входа сервиса с помощью DNS round-robin и отправляет свои запросы без учёта доменов отказа, стоимости или задержки (latency). Маршрутизация трафика между разными AZ не должна добавлять большую задержку при вызовах сервиса, но при пересылке больших объёмов данных вам придётся учитывать цену за трафик.
Сервисную топологию можно использовать как для stateless, так и для stateful контейнеров. Она позволяет владельцу сервиса определять topologyKeys, которые нужно учитывать при выборе точки входа в сервис Kubernetes. Работа сервисной топологии схожа с принципами локализованной балансировкой нагрузки в Istio и позволяет уменьшить ошибки, улучшить производительность и избежать ненужных затрат.
Примером Сервиса, который в первую очередь маршрутизирует трафик в точку входа сервиса на том же инстансе, и только затем к любой точке входа сервиса в той же AZ выглядит примерно так:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "kubernetes.io/hostname"
- "topology.kubernetes.io/zone"Если не будет найдет точка входа в сервис на данном инстансе с тем же hostname или в той же AZ, то CoreDns не вернёт значение точки входа в сервис, и обнаружение сервиса (service discovery) закончится ошибкой. Это значит, что topologyKeys для сервиса должны определять все возможные параметры определения точки входа в сервис, чтобы ему быть обнаруженным во всех случаях.
Вы можете контролировать порядок определения точек входа в сервис путём расположения topologyKeys сверху вниз в Сервис манифесте. Например, если вы хотите приоритизировать совпадающую AZ и Регион, по сравнению с остальными вариантами, используйте такой порядок topologyKeys:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 9376
topologyKeys:
- "topology.kubernetes.io/zone"
- "topology.kubernetes.io/region"
- "*"Выводы
Существует множество аспектов, которые нужно учитывать для управления высоко-доступным Kubernetes кластером, каждая компания имеет свои требования и ограничения. Если возможно, старайтесь проектировать вашу инфраструктуру из соображений простоты и использовать сервисы, работающие в нескольких AZ, такие как EFS, RDS и ELB, чтобы упростить создание высоко-доступных приложений.
В зависимости от ваших задач, вы можете вообще не управлять нодами, используя управляемые группы инстансов или EKS Fargate. Вы можете получить многие преимущества, описанные выше, без каких-либо сложностей, связанных с управлением нодами самостоятельно.
Если выхотите ознакомиться с дополнительной информацией по управлению и настройки EKS кластеров, читайте лучшие практики написанные инженерами, которые создали EKS сервис. Мы приглашаем вас внести свой вклад в Kubernetes коммьюнити посредством special interest groups (SIGs). Вступайте в sig-aws и общайтесь с другими пользователями AWS, управляющими Kubernetes кластера или присоединяйтесь к нашему Slack-каналу: http://slack.k8s.io.