Блог Amazon Web Services
Представляем глобальные кластеры для Amazon DocumentDB (MongoDB-совместимая)
Оригинал статьи: ссылка (Karthik Vijayraghavan, Senior DocumentDB Specialist Solutions Architect)
Amazon DocumentDB (MongoDB-совместимая) – это быстрый, хорошо масштабируемый, высокодоступный и полностью управляемый сервис баз данных, который поддерживает рабочие нагрузки MongoDB. Вы можете использовать тот же исходный код, драйверы и другие инструменты, работающие с MongoDB 3.6 или 4.0, для запуска, управления и масштабирования рабочих нагрузок на Amazon DocumentDB, не задумываясь об используемой инфраструктуре. Так как Amazon DocumentDB является документно-ориентированной базой данных, она позволяет хранить, запрашивать и индексировать данные в формате JSON.
Мы выпустили новую функциональность глобальных кластеров, с помощью которой в Amazon DocumentDB вы можете развернуть кластер сразу в нескольких регионах AWS. Эта функциональность позволяет реплицировать ваши данные в кластеры, которые могут находиться в пяти разных регионах, практически без влияния на производительность. Глобальные кластеры обеспечивают более быстрое восстановление в случае сбоев в масштабах региона, а также позволяют выполнять операции чтения из разных точек мира с более низкой задержкой.
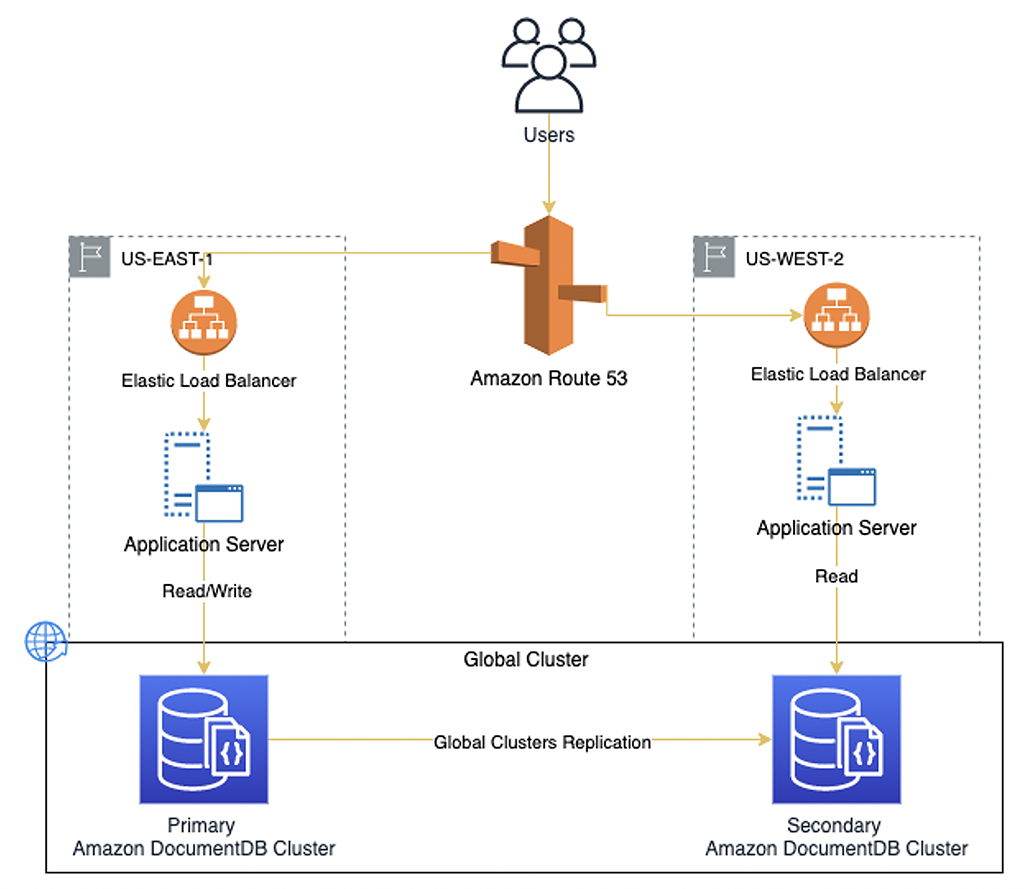
Глобальный кластер состоит из основного кластера, в котором разрешены операции чтения и записи, а также до пяти вторичных кластеров в других регионах, в которых разрешены только операции чтения. Репликация между основным и вторичными кластерами происходит в одном направлении и позволяет вам создавать кластеры по схеме active / passive. Диаграмма ниже показывает эту архитектуру.

Преимущества глобальных кластеров Amazon DocumentDB
Глобальные кластеры в Amazon DocumentDB обладают следующими преимуществами:
- Аварийное восстановление при сбоях в масштабах региона: хотя это и случается очень редко, глобальные кластеры позволят вам восстановиться после сбоев в масштабах региона меньше, чем за 60 секунд. Позже в этой статье мы продемонстрируем, как вы можете перевести вторичный кластер в полностью отдельный кластер и пересоздать глобальную базу данных в другом регионе без потери данных.
- Глобальные операции чтения с низкой задержкой: если ваше приложение распределено глобально, вы можете использовать глобальные кластеры для репликации данных, чтобы пользователи могли читать их из вторичного кластера в ближайшем к ним регионе. Глобальные кластеры хорошо подходят для сценариев, когда операции чтения превалируют над операциями записи, так как обслуживают запросы на чтение локально с низкой задержкой, тогда как для записей используется основной кластер.
- Масштабируемые вторичные кластеры: количество и тип инстансов в основном и вторичных кластерах не обязательно должны совпадать. Вы можете создавать вторичные кластеры с одним инстансом и масштабировать до 16 в зависимости от требований. Масштабирование в Amazon DocumentDB занимает менее 10 минут, независимо от объёма данных.
- Высокоскоростная репликация между кластерами: глобальные кластеры используют быструю физическую репликацию во вторичные кластеры в других регионах на уровне системы хранения данных. Сами вычислительные инстансы, которые созданы в основном и вторичных регионах, не принимают участия в репликации, благодаря чему могут обрабатывать запросы от ваших приложений.
Подготовка
Чтобы создать глобальный кластер Amazon DocumentDB, вам необходим кластер Amazon DocumentDB, который будет выступать в качестве основного. Вы можете использовать уже существующий кластер или создать новый. По умолчанию новые кластеры создаются на уровне одного региона.
Основной кластер глобального кластера должен находиться в одном регионе, а вторичные – в других.
Создайте глобальный кластер Amazon DocumentDB
Чтобы настроить глобальный кластер, выполните следующие шаги:
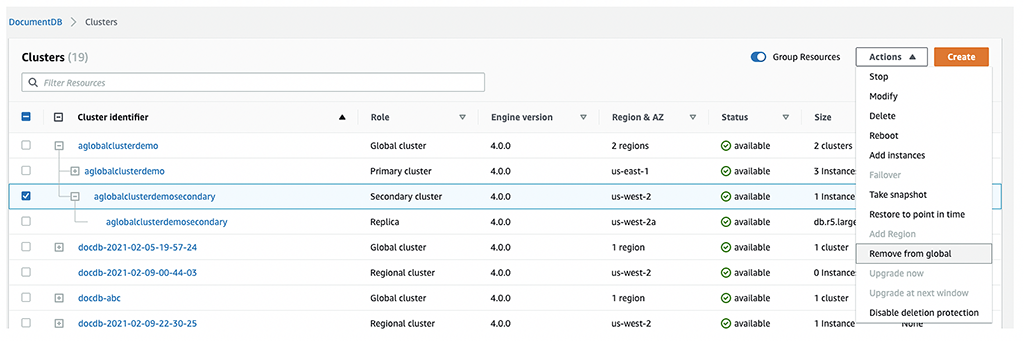
- В консоли Amazon DocumentDB нажмите Clusters.
- Выберите ваш кластер, имеющий роль Regional Cluster в консоли.
- В меню Actions нажмите Add Region.

- В выпадающем списке Secondary region выберите регион для вторичного кластера.

- Введите идентификатор глобального кластера, а также идентификатор вторичного кластера.

- Выберите инстанс-класс (размер) и их количество.

- Оставьте остальные настройки по умолчанию и нажмите Create cluster.
Если вы отключили шифрование данных для основного кластера, то вторичные кластеры тоже не будут его использовать.
Теперь кластер будет изменён и станет глобальным. Данные будут автоматически реплицироваться во вторичные кластеры.

Давайте теперь рассмотрим сценарии использования глобальных кластеров Amazon DocumentDB.
Сценарий 1: аварийное восстановление
До появления глобальных кластеров вы могли развернуть кластер Amazon DocumentDB с инстансами в трёх зонах доступности. Хоть это и является высокодоступной архитектурой, она не защищает от сбоев на уровне региона. Глобальные кластеры позволяют вам переключиться на вторичный кластер в другом регионе. Это означает, что ваш кластер сможет восстановить работоспособность даже в маловероятном случае проблем или сбоев в работе региона.

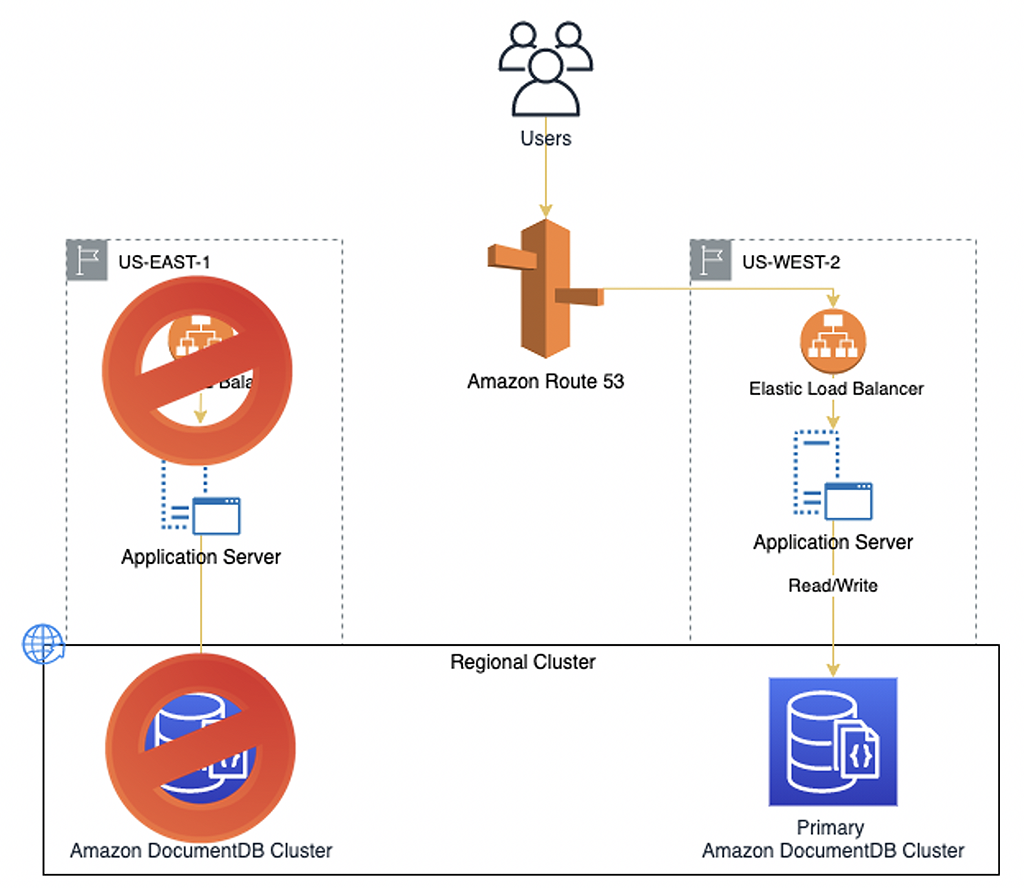
До сбоя архитектура выглядит следующим образом:
Для аварийного переключения глобального кластера Amazon DocumentDB выполните следующие шаги:
- Остановите операции записи из приложения в основной регион.
- Найдите вторичный кластер, обладающий минимальными задержками с учётом местонахождения ваших пользователей.
- Удалите вторичный кластер из глобального.
Это действие переводит вторичный кластер в статус полностью отдельного, который может выполнять операции чтения и записи. Если вы настроили другие вторичные кластеры, мы рекомендуем также удалить их из глобального кластера, так как они будут доступны для локальных операций чтения независимо от возможных проблем с основным регионом. - Измените настройки вашего приложения, чтобы перенаправить операции записи в этот отдельный кластер, используя его новую точку доступа.
- Добавьте регионы к отдельному кластеру, чтобы сделать его глобальным (как было описано выше в этой статье).
После переключения архитектура выглядит следующим образом:
Сценарий 2: глобальные операции чтения с низкой задержкой
С помощью глобальных кластеров Amazon DocumentDB вы можете запускать глобально распределённые приложения в нескольких регионах. Только основной кластер может выполнять операции записи. Приложения, которым требуется выполнить запись, подключаются к точке доступа основного кластера. Её можно найти на вкладке Connectivity & security этого кластера.

Вы можете масштабировать каждый вторичный кластер независимо друг от друга путём добавления одной или более реплик, которые смогут обслуживать запросы на чтение. Вы можете найти точки доступа для вторичных кластеров на соответствующих вкладках Connectivity & security.
В следующем примере исходного кода мы подключаемся к основному региону из инстанса Amazon Elastic Compute Cloud (Amazon EC2), развёрнутого в том же регионе, а затем добавляем несколько записей. Мы получаем точку доступа из переменной окружения, которая должна быть настроена заранее, например, используя команду export END_POINT='<endpoint>'.
Далее мы читаем данные, которые были добавлены в основной кластер, из вторичного кластера, используя инстанс EC2 в соответствующем регионе. Установите точку доступа так же, как было описано выше.
На скриншоте ниже показан результат одновременного запуска приложений для записи и для чтения.

Приложение добавляет пять записей в основном регионе и затем читает их из вторичного. Данные, как правило, доступны во вторичном регионе менее чем за секунду. С помощью глобальных кластеров вы можете предоставлять доступ к данным вашим пользователям по всему миру, как показано на диаграмме ниже.

Следующая диаграмма показывает пример архитектуры для такого сценария.

Заключение
В этой статье мы представили глобальные кластеры Amazon DocumentDB. Вы узнали, как организовать аварийное переключение в случае региональных сбоев, а также как перенести данные ближе к вашим приложениям в разных регионах.
Чтобы начать использование, перейдите по ссылке.