Блог Amazon Web Services
Основные возможности Amazon SageMaker Feature Store
Зарегистрируйтесь, чтобы получать приглашения на мероприятия AWS на русском языке.
Оригинал статьи: ссылка (Lakshmi Ramakrishnan, Ravi Khandelwal, Romi Datta, Mark Roy)
Одной из самых сложных задач в сфере машинного обучения (ML) является конструирование признаков (feature engineering) – процесс преобразования данных для создания признаков для ML. Признаки являются результатом обработки наборов данных. Они используются и в процессе обучения ML-моделей, и при эксплуатации развернутых моделей с целью повышения точности предсказаний. Аналитики данных и ML-инженеры зачастую тратят до 60-70% своего времени на конструирование признаков. Обычно эта работа к тому же повторяется разными командами внутри одной организации – теми командами, которые используют одни и те же данные для построения ML-моделей для разных проектов. Это еще сильнее увеличивает количество времени и усилий, затрачиваемых на конструирование признаков, в масштабах компании. Также важно, чтобы сгенерированные признаки были легко доступны как для тренировки, так и для использования модели в промышленной эксплуатации, чтобы обеспечить согласованность версий признаков между обучением модели и выводом предсказаний.
Отдельное хранилище признаков для машинного обучения помогает получать высококачественные предсказания с использованием согласованного набора признаков. Оно также помогает снизить затраты на ML за счет устранения дублирования усилий по проектированию признаков разными командами. Согласование версий признаков нужно между разными отделами в организации, а также между обучением и эксплуатацией любой ML-модели. Кроме того, необходимо, чтобы хранилища признаков соответствовали высоким требованиям к производительности, масштабируемости и доступности, что позволит быстро отдавать признаки в режиме, близком к реальному времени, для получения прогнозов. Из-за этого организации часто вынуждены самостоятельно создавать и поддерживать хранилища признаков, которые могут стать дорогими и трудными в обслуживании.
В AWS мы постоянно прислушиваемся к нашим клиентам и создаем сервисы и услуги, которые их радуют. Клиенты говорили о трудностях, с которыми сталкиваются их команды специалистов по работе с данными, при управлении признаками ML. Мы использовали эти отзывы для создания Amazon SageMaker Feature Store, который был запущен на re:Invent 1 декабря 2020г. Amazon SageMaker Feature Store – это управляемое специализированное хранилище, предназначенное для безопасного хранения, обновления, публикации и совместного использования ML признаков.
SageMaker Feature Store предлагает много разных возможностей, в этом посте мы сосредоточимся на ключевых – по вводу данных, обеспечению доступа к данным, а также безопасности и контроля доступа.
Обзор SageMaker Feature Store
SageMaker Feature Store – это специализированное хранилище признаков для машинного обучения, которое позволяет вам делать следующее:
- Безопасно хранить и предоставлять признаки для приложений реального времени и приложений пакетной обработки данных. SageMaker Feature Store отдает ML-признаки с очень низкой задержкой. Он позволяет вам использовать ML для принятия решений в режиме, близком к реальному времени, так как выдача векторов признаков происходит с миллисекундными задержками (95й перцентиль задержек вызовов – меньше 10 миллисекунд для вектора размером 15 килобайт).
- Ускорять разработку ML-моделей за счет повторного и совместного использования признаков. Конструирование признаков – это длительный и утомительный процесс, который часто повторяется несколькими командами в организации, работающими над одними и теми же данными. SageMaker Feature Store помогает аналитикам тратить меньше времени на подготовку данных и вычисление признаков, и выделять больше времени на сами идеи ML, позволяя им находить и использовать уже разработанные признаки в масштабах всей организации.
- Обеспечить доступ к истории данных. Хорошее хранилище признаков должно обеспечивать легкий и быстрый доступ к предыдущим значениям признаков для воссоздания тренировочных наборов данных в определенный момент времени в прошлом. Amazon SageMaker Feature Store поддерживает запросы данных на конкретный момент времени, что позволяет воссоздавать состояние признаков в прошлом.
- Уменьшить отличия между обучением и использованием модели. Команды ML-специалистов часто борются с расхождениями во время обучения и эксплуатации моделей, вызванными несоответствием тренировочных данных и данных для прогнозирования после запуска модели. Эти расхождения могут привести к тому, что модели будут работать хуже, чем ожидалось. SageMaker Feature Store сокращает отличия между тренировкой и эксплуатацией, сохраняя согласованность ML-признаков между этими двумя этапами.
- Обеспечить шифрование данных и контроль доступа. Безопасность ML-данных, как и всех остальных типов данных, имеет первостепенное значение для всех организаций. В AWS безопасность и эффективное управление являются нашими главными приоритетами, а SageMaker Feature Store предоставляет набор инструментов для обеспечения безопасности данных и контроля доступа к ним на уровне компании, включая шифрование данных при хранении и при передаче, а также контроль доступа на основе ролей с использованием AWS Identity and Access Management (IAM).
- Гарантировать надежную, отказоустойчивую работу. Использование хранилища признаков в промышленной эксплуатации требует соглашений об уровне обслуживания (SLA), гарантирующих желаемую производительность и доступность. SageMaker Feature Store обладает непревзойдённой надёжностью, масштабируемостью и эксплуатационной эффективностью, аналогично другим сервисам AWS.
SageMaker Feature Store призван играть центральную роль в ML-архитектурах, помогая реализовать жизненный цикл ML-разработки и обеспечивая беспроблемную интеграцию со многими другими сервисами. Например, вы можете использовать такие инструменты, как AWS Glue DataBrew и SageMaker Data Wrangler, для редактирования признаков. С помощью Amazon EMR, AWS Glue и SageMaker Processing совместно с SageMaker Feature Store можно выполнять задачи по преобразованию данных для вычисления признаков. Вы можете использовать инструменты вроде SageMaker Pipelines, AWS Step Functions или Apache AirFlow для планирования и организации конвейеров для автоматизации конструирования признаков. Если у вас уже есть признаки в хранилище, вы можете отдавать их с небольшой задержкой для использования в моделях, развернутых на хостинге с помощью таких сервисов, как SageMaker Hosting. Можно использовать существующие инструменты, такие как Amazon Athena, Presto, Spark и EMR, для извлечения наборов данных из внешних хранилищ и обработки их в SageMaker Training или пакетными трансформациями. Наконец, вы можете использовать Amazon Kinesis, Apache Kafka и AWS Lambda для потокового конструирования признаков. Следующая диаграмма иллюстрирует некоторые из сервисов, которые могут быть интегрированы с SageMaker Feature Store.
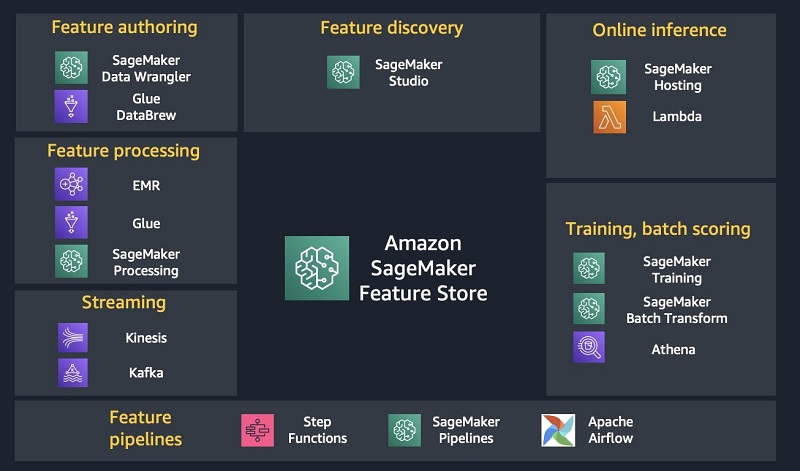
Перед тем, как углубиться в детали, мы вкратце представим некоторые концепции SageMaker Feature Store:
- Feature group – группа признаков, логическая группировка ML-признаков
- Record – единичный набор значений признаков в группе признаков
- Online store – онлайн-хранилище, высокодоступное хранилище с низкой задержкой, позволяющее просматривать и искать признаки в режиме реального времени.
- Offline store – офлайн-хранилище (автономное хранилище), хранилище признаков, которое управляет их предыдущими значениями, сохраненными в вашем бакете Amazon Simple Storage Service (Amazon S3), и используется для исследования и тренировки моделей
Для получения дополнительной информации см. раздел «Начало работы с Amazon SageMaker Feature Store».
Прием данных
SageMaker Feature Store предоставляет множество способов приема данных, включая пакетную загрузку, прием потоковых данных и сочетание обоих способов. SageMaker Feature Store построен по модульному принципу и предназначен для приема данных из различных источников, как например – напрямую из SageMaker Data Wrangler или из Kinesis и Apache Kafka. На следующей диаграмме показаны различные механизмы приема данных, поддерживаемые SageMaker Feature Store.

Прием потоковых данных
SageMaker Feature Store предоставляет PutRecord API с низкой задержкой и высокой пропускной способностью, оптимизированный по расходам. Этот API разработан для использования в различных фреймворках, поэтому вы можете использовать разные потоковые источники, такие как Apache Kafka, Kinesis, Spark Streaming и другие, для вычисления признаков в режиме реального времени и загрузки их непосредственно в онлайн-хранилище или сразу и в онлайн, и в офлайн-хранилище.
Для еще более быстрого приема данных можно распараллелить вызовы PutRecord API, чтобы получить бóльшую пропускную способность на запись. Данные из всех этих PUT-запросов синхронно записываются в онлайн-хранилище, а также буферизируются и записываются в автономное хранилище в Amazon S3, если эта опция выбрана. Запись данных в офлайн-хранилище происходит в течение нескольких минут после приема. SageMaker Feature Store может осуществлять проверку данных и схемы во время загрузки для обеспечения качества данных. Проверки проводятся для того, чтобы убедиться, что входные данные соответствуют определенным типам данных, и что входящий набор содержит все нужные признаки. Если вы настроили офлайн-хранилище, SageMaker Feature Store автоматически реплицирует туда принятые данные для последующего использования при обучении моделей, а также для исторического доступа к записям.
Пакетный прием данных
Вы можете выполнить пакетную выгрузку в SageMaker Feature Store, интегрировав его с конвейерами создания и обработки признаков. У вас есть возможность создавать конвейеры для признаков с использованием выбранных вами технологий. После выполнения любых преобразований данных и пакетного агрегирования конвейеры обработки могут загружать данные признаков в SageMaker Feature Store посредством пакетной загрузки.
Вы можете выполнять пакетную загрузку в следующих трех режимах:
- Пакетная загрузка в онлайн-хранилище – это можно сделать, вызвав синхронный API-метод PutRecord. SageMaker Feature Store дает вам возможность настроить только онлайн-хранение признаков для тех случаев, когда вам не требуются возможности офлайн-хранилища. Этот подход снижает ваши расходы, избегая оплаты ненужного хранения предыдущих версий признаков. Если вы настроили свою группу признаков как доступную только для онлайн-доступа, последние значения записи перезаписывают более ранние значения.
- Пакетная загрузка в офлайн-хранилище – вы можете загружать данные непосредственно в автономное хранилище. Это может быть полезно, когда вы хотите заполнить предыдущие значения признаков для сценариев обучения моделей. Это можно сделать из SageMaker Data Wrangler или напрямую из Spark-контейнера задачи SageMaker Processing Job. Офлайн-хранилище находится в вашем AWS аккаунте и использует Amazon S3 для хранения данных. Это дает вам все преимущества Amazon S3, включая низкую стоимость хранения, долговечность, надежность и гибкий контроль доступа. Кроме того, к группе признаков, сохраненной в автономном хранилище, могут быть добавлены соответствующие метаданные, чтобы позволит искать эти данные, а также автоматически создать каталог данных AWS Glue Data Catalog.
- Пакетная загрузка в онлайн- и в офлайн-хранилище одновременно – если ваша группа признаков настроена на хранение и в онлайн, и в офлайн хранилищах, вы можете выполнить пакетную загрузку, вызвав метод API PutRecord. В этом случае в онлайн-хранилище будут только самые последние значения, а в автономном хранятся как ваши старые записи, так и самая последняя запись. В автономное хранилище данные можно только дописывать, но не перезаписывать.
Чтобы увидеть пример того, как можно объединить потоковое и пакетное конструирование признаков машинного обучения, посмотрите статью: Using streaming ingestion with Amazon SageMaker Feature Store to make ML-backed decisions in near-real time.
Доступ к данным
В этом разделе мы обсудим детали доступа к данным в реальном времени, доступа к автономному хранилищу, и создания сложных запросов к хранилищу.
Доступ к данным в реальном времени
SageMaker Feature Store предоставляет API метод GetRecord с низкой задержкой. Он предназначен для выдачи признаков в реальном времени. Это синхронный API, который обеспечивает строгую согласованность чтения и может быть распараллелен для поддержки приложений с высокой пропускной способностью. GetRecord API позволяет получить весь набор со всеми его признаками или определенное подмножество признаков, что помогает оптимизировать доступ к общим группам признаков, содержащим сотни или тысячи функций.
Доступ к данным из автономного хранилища
SageMaker Feature Store использует S3-бакет в вашем аккаунте для хранения офлайн-данных. Вы можете использовать сервисы запросов, такие как Athena, подключив к ним в качестве источника бакет вашего офлайн-хранилища в Amazon S3. Таким образом вы сможете анализировать данные признаков или объединять несколько групп признаков в одном запросе. SageMaker Feature Store автоматически создает каталог данных в AWS Glue Data Catalog во время создания группы признаков, и затем вы можете использовать этот каталог для доступа и запроса данных из автономного хранилища с помощью Athena или даже таких инструментов как Presto. Вы можете настроить сканер AWS Glue Crawler для работы по расписанию, чтобы обеспечить постоянную актуальность вашего каталога. Поскольку автономное хранилище находится в Amazon S3 в вашем AWS аккаунте, вы можете использовать любые возможности Amazon S3, например репликацию.
Пример, показывающий, как можно выполнить запрос Athena к набору данных, содержащему две группы признаков, с использованием каталога данных, который был создан автоматически, можно увидеть тут: Build Training Dataset. Подробные примеры запросов можно увидеть в статье: Athena and AWS Glue in Feature Store. Эти запросы также доступны в SageMaker Studio.
Сложные запросы к хранилищу признаков
Архитектура SageMaker Feature Store позволяет вам получать доступ к своим данным с помощью сложных запросов. Например, легко выполнить запрос к офлайн-хранилищу, чтобы узнать, как выглядели ваши данные месяц назад («путешествие во времени»). Для SageMaker Feature Store требуется наличие параметра с именем EventTimeFeatureName в вашей группе признаков, чтобы сохранять время события для каждой записи. Этот параметр, в сочетании с особенностью автономного хранилища, разрешающего только добавление новых записей, позволяет легко использовать механизмы запросов для получения моментального снимка ваших данных на конкретное время. Другие возможности запросов включают в себя получение дедуплицированных данных, восстановление состояния набора признаков на момент предыдущего обучения ML-моделей, а также получение данных для аудита, необходимого для обеспечения соблюдения нормативных требований.
В ближайшее время мы планируем опубликовать подробный пост о том, как использовать сложные шаблоны запросов (включая «путешествия во времени»).
Безопасность: шифрование и контроль доступа
В AWS мы очень серьезно относимся к безопасности данных, и поэтому архитектура SageMaker Feature Store обеспечивает сквозное шифрование, детализированные механизмы контроля доступа и возможность настройки доступа через приватные подсети VPC.
Шифрование в состоянии покоя и при передаче
После приема ваши данные всегда шифруются при хранении и передаче. При создании группы признаков для онлайн- или офлайн-хранилища вы можете добавить ваш клиентский ключ шифрования (CMK) в AWS Key Management Service (AWS KMS). С его помощью данные будут зашифрованы при хранении. Если вы не предоставляете собственный ключ, мы обеспечиваем шифрование на стороне сервера с помощью ключа, управляемого AWS. Мы также поддерживаем использование разных CMK для онлайн- и офлайн-хранилищ.
Контроль доступа
SageMaker Feature Store позволяет настраивать детализированный контроль доступа к вашим данным и API-интерфейсам с помощью ролей и политик пользователей IAM, разрешающих или запрещающих определенные действия. Вы можете настроить контроль доступа на уровне API или вашего AWS аккаунта, чтобы применять одни политики для всех групп признаков, или отдельные – для разных групп. Создание, удаление, описание и перечисление групп признаков — всеми этими операциями можно управлять с помощью политик IAM. Вы также можете настроить доступ ко всем операциям в вашем приложении из приватных подсетей VPC через AWS PrivateLink.
Резюме
В Amazon работа с запросами клиентов лежит в основе всего, что мы делаем. Мы потратили много времени, выслушивая наших клиентов и разбираясь в их основных проблемах с управлением признаками машинного обучения на корпоративном уровне, и использовали эти требования для разработки SageMaker Feature Store.
SageMaker Feature Store — это специализированное хранилище, которое позволяет вам определять признаки один раз как для масштабного автономного создания ML-моделей, так и для сценариев получения прогнозов в пакетном режиме, а также для использования признаков для прогнозирования в реальном времени, с миллисекундными задержками. Вы можете легко именовать, систематизировать, искать группы признаков и совместно использовать их в разных командах специалистов по обработке данных – и все это в Amazon SageMaker Studio. SageMaker Feature Store обеспечивает согласованность признаков между обучением и эксплуатацией моделей, автоматически реплицируя значения функций из онлайн-хранилища в автономное хранилище по мере конструирования новых признаков. Он тесно интегрирован с SageMaker Data Wrangler и SageMaker Pipelines для создания конвейеров конструирования признаков, но также он является достаточно модульным, чтобы легко интегрироваться с вашими существующими процессами обработки данных и получения прогнозов. SageMaker Feature Store обеспечивает сквозное шифрование, безопасный доступ к данным и контроль на уровне API для обеспечения надлежащей защиты ваших данных. Для получения дополнительной информации смотрите пост: New – Store, Discover, and Share Machine Learning Features with Amazon SageMaker Feature Store
Мы понимаем, насколько важно для вас получить правильный уровень обслуживания (SLA), чтобы вы могли с уверенностью использовать Amazon SageMaker Feature Store в ваших критически важных приложениях. Поэтому SageMaker Feature Store имеет те же гарантии обслуживания, к которым привыкли клиенты AWS.