- Machine Learning
- Amazon SageMaker AI
- Amazon SageMaker Pipelines
Amazon SageMaker Pipelines
Purpose-built service for machine learning workflows
What is Amazon SageMaker Pipelines?
Benefits of SageMaker Pipelines
-
Seamless integration with Amazon SageMaker features (e.g training, notebook jobs, inference) and the serverless infrastructure remove the undifferentiated heavy lifting involved in automating ML jobs.
-
You can use either the drag-and-drop UI or code (Python SDK, APIs) to create, execute, and monitor ML workflow DAGs (Directed Acyclic Graph).
-
Lift-and-shift your existing ML code to automate its execution tens of thousands of times. Build custom integrations tailored to your MLOps and LLMOps strategies.
Compose, execute, and monitor GenAI workflows
Create and experiment with variations of foundation model workflows with an intuitive drag-and-drop visual interface in Amazon SageMaker Studio. Execute the workflows manually or on a schedule to automatically update your ML models and inference endpoints when new data is available.
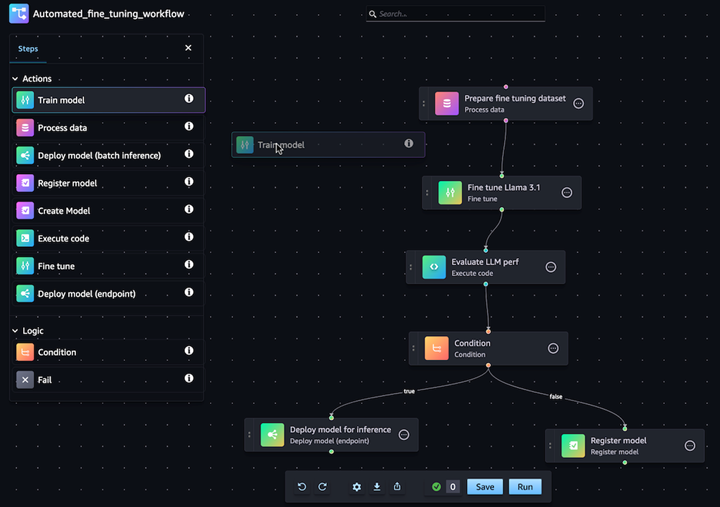
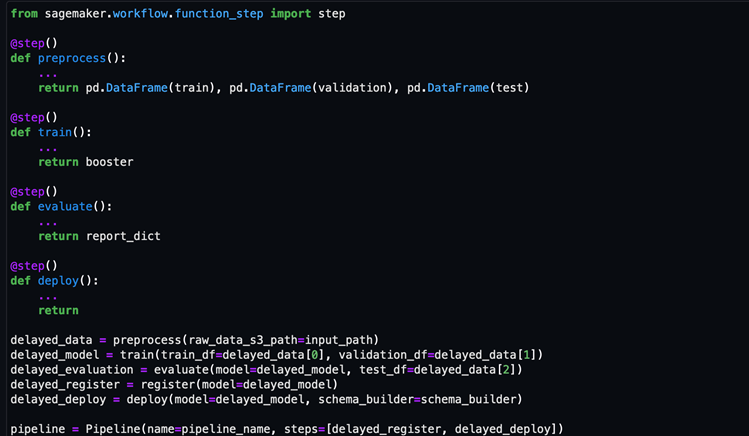
Lift-and-shift your machine learning code
Reuse any existing ML code and automate its execution in SageMaker Pipelines with a single Python decorator (@step). Execute a chain of Python Notebooks or scripts with the ‘Execute Code’ and ‘Notebook Job’ step types.
Audit and debug ML workflow executions
View a detailed history of the workflow structure, performance, and other metadata to audit ML jobs that were run in the past. Dive deep into individual components of the end-to-end workflow to debug job failures, fix them in the visual editor or code, and re-execute the updated Pipeline.