- AWS Solutions Library
- Guidance for Generative AI Model Optimization Using Amazon SageMaker
Guidance for Generative AI Model Optimization Using Amazon SageMaker
Optimizing generative AI models for speed and efficiency
Overview
This Guidance shows how you can optimize your generative AI models using Amazon SageMaker, a service where you can build, train, and deploy large language models (LLMs) at scale. By using advanced optimization techniques like speculative decoding, quantization, and compilation, you can achieve significant performance improvements. These optimizations can deliver higher throughput, lower latency, and reduced inference costs. The streamlined interface in SageMaker abstracts away the complex research and experimentation normally required to optimize generative AI models, allowing you to rapidly develop and deploy high-performing, cost-effective generative AI applications.
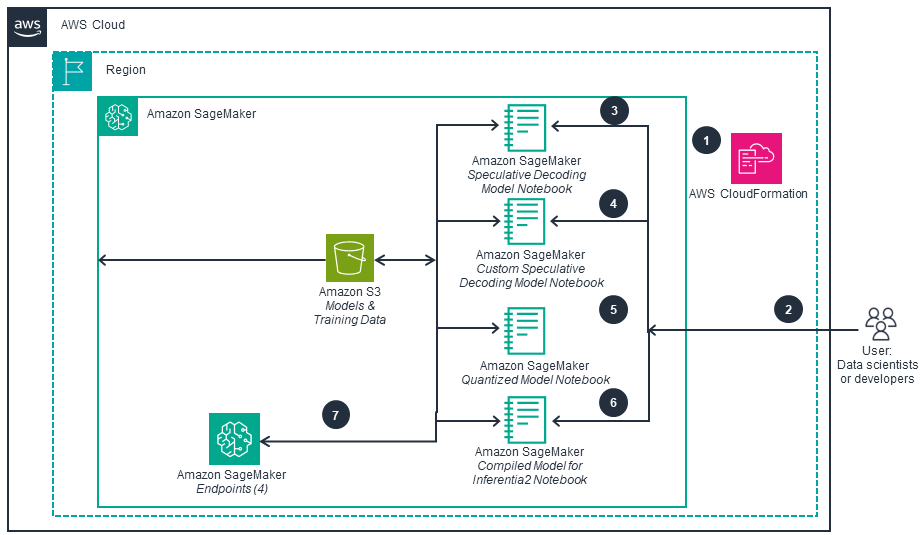
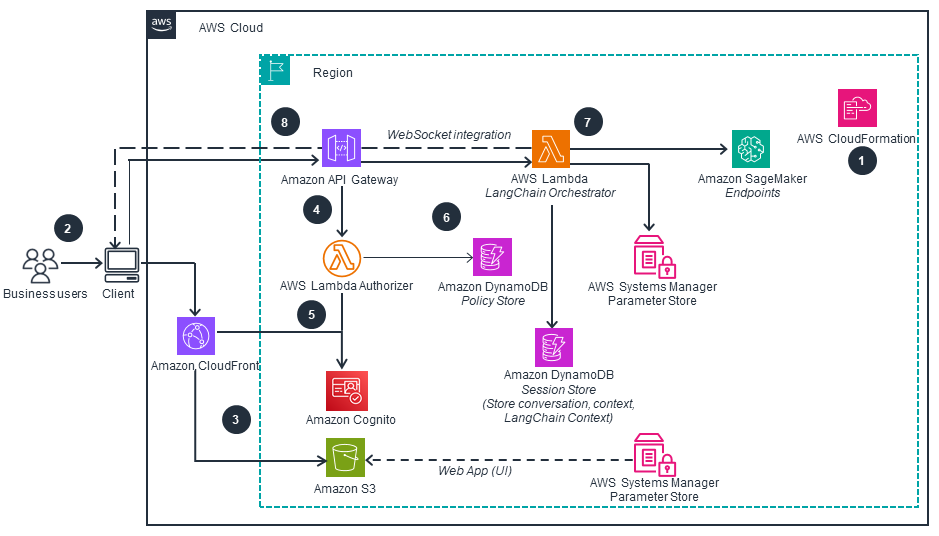
The provided diagrams illustrate the steps required to configure this application. The first diagram demonstrates how data scientists can optimize large language models (LLMs) within SageMaker. The second diagram outlines the deployment of those optimized LLMs.
How it works
Optimization for data scientists
This architecture diagram shows how data scientists can optimize Large Language Models (LLMs) within Amazon SageMaker to deliver responses that are not only faster, but also more accurate and cost-effective. The subsequent tab outlines the deployment of the optimized LLMs in Amazon SageMaker.
LLM deployment in applications
This architecture diagram shows how to deploy the optimized LLMs in SageMaker, including using AWS CloudFormation to provision all the necessary application resources.
Get Started
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
The use of managed services provides scalable and reliable infrastructure to handle fluctuating user loads with high availability. For example, Amazon CloudWatch offers centralized logging and monitoring for all services involved for efficient operations. SageMaker offers standard logging and metrics for monitoring and analyzing the performance of deployed machine learning models, helping you gain insights into operational health and make data-driven decisions for continuous improvement. Lastly, Lambda provides built-in logging and metrics capabilities, and when coupled with CloudWatch, you get consistent logging for the Lambda functions.
Amazon Cognito delivers robust user authentication and authorization capabilities, preventing unauthorized access to the application. Concurrently, the Parameter Store secures storage of sensitive configuration data, thereby reducing the risk of data breaches.
CloudFront, API Gateway, Lambda, and DynamoDB are managed services that handle the underlying infrastructure complexity. The capabilities of these services include high availability, scalability, and fault tolerance for the application. Specifically, CloudFront and API Gateway provide reliable and scalable infrastructure to handle fluctuating user loads, while Lambda and DynamoDB offer inherent reliability and durability, reducing the risk of downtime or data loss. The combination of these managed services allows the chat application to withstand failures and handle increased user traffic. Finally, Amazon S3 is designed to provide 99.999999999% (11 nines) durability and 99.99% availability of objects over a given year.
SageMaker and Lambda together facilitate two key advantages for this application: improved speed and scalability. First, the optimization techniques in SageMaker help deliver faster responses from the LLM while reducing the compute resources and costs required to run it. Second, the serverless nature of Lambda offers efficient use of compute resources, scaling up or down as needed to maintain high performance. The combined capabilities of these services enable the application to handle increasing user loads and adapt to evolving performance requirements without compromising efficiency.
SageMaker helps you achieve cost optimization in several ways. One, the optimized models require fewer compute resources to deliver the same or better performance, leading to lower overall infrastructure costs. Two, the ability to deploy the models on different hardware configurations, including Inferentia-based instances, allows for better hardware utilization and cost savings. And three, the faster responses from the optimized LLM can lead to reduced costs associated with cloud resources and data transfer.
The primary reason for using SageMaker is to support more sustainable workloads. This is because the inherent capabilities of SageMaker enable your team to reduce the compute resources and energy consumption required to run the LLM, minimizing the environmental impact of the application. By deploying the optimized models on hardware configurations that offer better energy efficiency, the application can further contribute to sustainability goals. Additionally, the cost-effectiveness of the optimized models is a key factor in the long-term viability and scalability of the application. By significantly reducing the inference costs through techniques like quantization and compilation, the application can be operated in a more sustainable manner, even as user demand and computational requirements scale over time.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages