- AWS Solutions Library
- Guidance for a Laboratory Data Mesh on AWS
Guidance for a Laboratory Data Mesh on AWS
Overview
How it works
Overview
This architecture diagram shows an overview about how you can accelerate the launch of a scientific data management system that integrates both your laboratory instruments and software with cloud data governance, data discovery, and bioinformatics pipelines, capturing key metadata events along the way. For more details on each component, open the other tab.
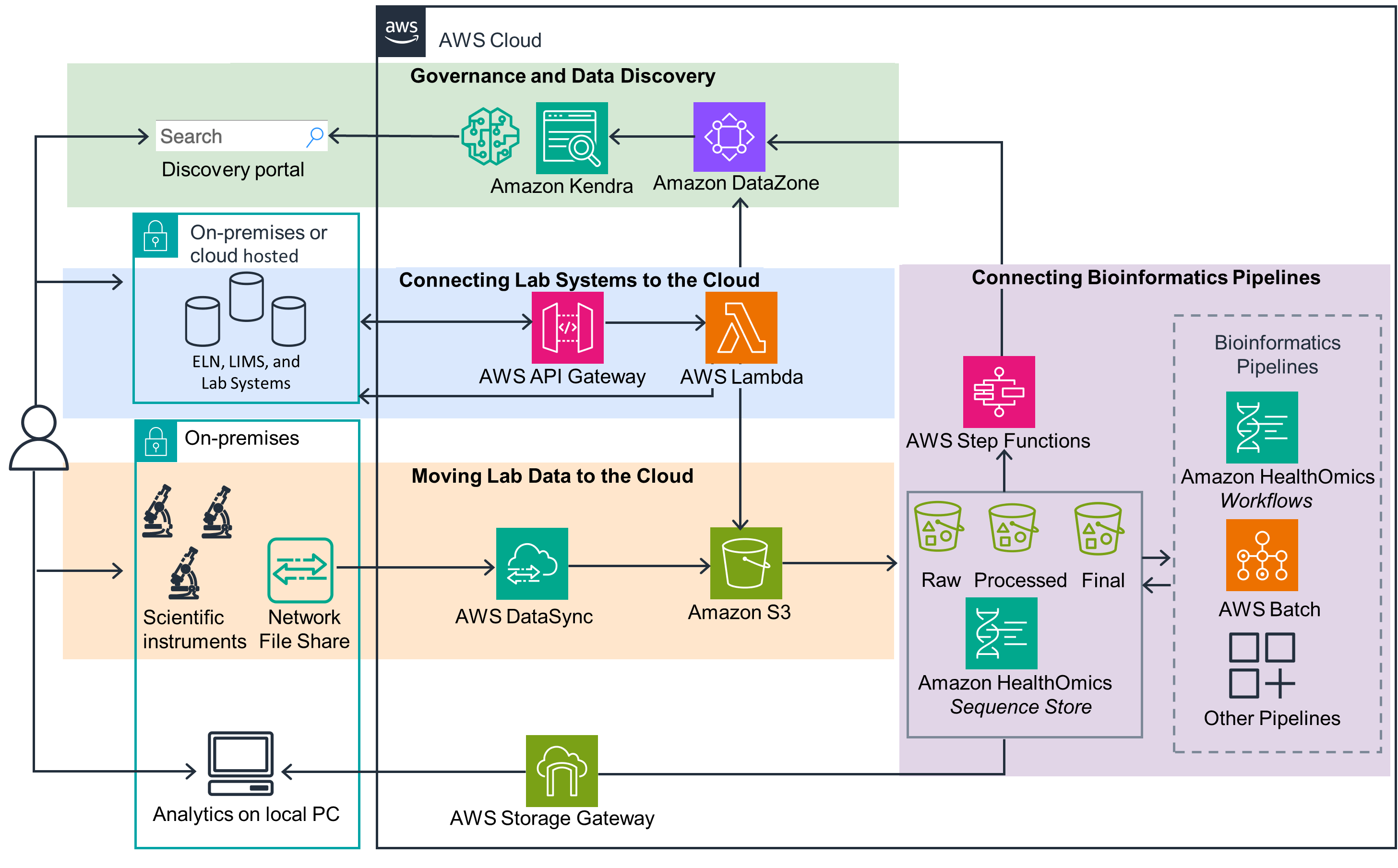
Main architecture
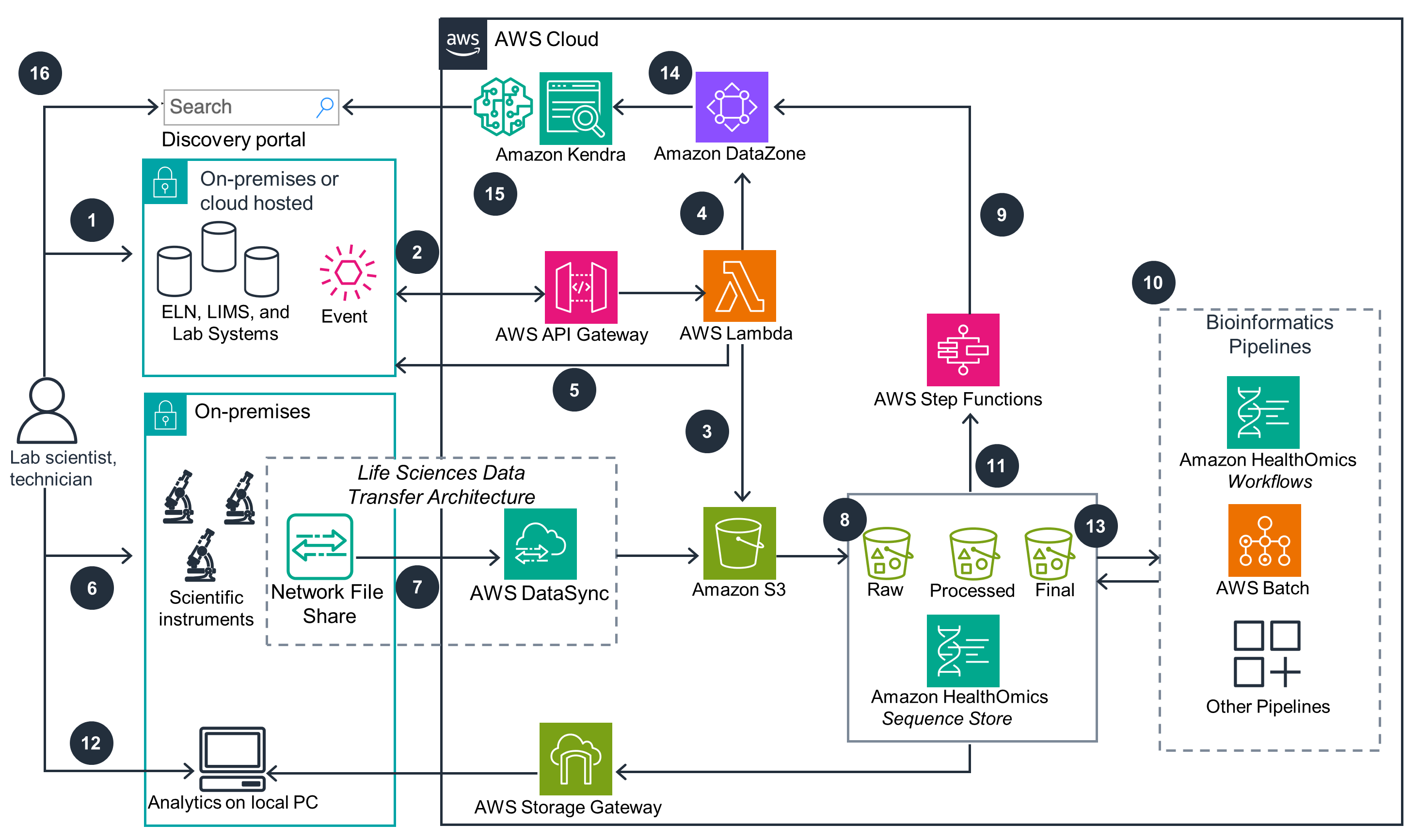
This architecture diagram shows the main architecture and provides more details about each component. For more details and architectural considerations, visit the Implementation Guide.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
This Guidance was configured with Amazon API Gateway and Step Functions, two AWS services that are purpose-built to help you run and monitor your research systems effectively, gain insights into operations, and continually improve your processes. Specifically, API Gateway creates RESTful APIs to enable two-way communication between AWS and your lab software. It acts as a front door for lab software and AWS to share logic and metadata, which enables up-to-date contextualization of datasets in ELN and AWS. Step Functions is a visual workflow service to automate microservice processes between the data store, metadata store, and lab software, creating an orchestration event that removes the need for manual updates of metadata, and keeps the ELN, the data store, and the metadata store in sync with one another.
Amazon DataZone and Storage Gateway work in concert to improve your security posture, protecting your data, systems, and assets. Amazon DataZone lets users access data in accordance with their organization’s security and compliance regulations, providing unified access controls to scientific data across multiple data domains and third-party data stores. Storage Gateway supports data integrity efforts with encryption, audit logging, and write-once, read-many (WORM) storage from on-premises applications to the data mesh. It provides lab users access to cloud-backed files for use in report generation or local analysis, while making it easy to maintain metadata tagging in the data mesh.
Amazon S3 and DataSync are built to ensure your workloads perform their intended functions correctly and consistently while allowing you to recover quickly from failure. Amazon S3 is a highly available and durable object store with cross-Region options for global organizations. DataSync provides managed data transfer with advanced features, including bandwidth throttling, migration scheduling, task filtering, and task reporting. By liberating data from on-premises file stores, DataSync and Amazon S3 provide a reusable transfer and storage architecture that can scale from small to large.
AWS Batch and HealthOmics both help you monitor performance and maintain efficiency for your workloads as business needs evolve. AWS Batch offers a flexible, high-performance computing configuration and virtually unlimited scale, allowing bioinformatics groups to tune and scale infrastructure as life science workloads dictate. It brings instant access to virtually unlimited computing resources to accelerate genomics, proteomics, cell imaging, electron microscopy, and high throughput simulation.
HealthOmics allows for Ready2Run workflows or bring-your-own private bioinformatics workflows to simplify the deployment of high-performance compute workflows. It includes pre-built workflows designed by industry-leading third-party software companies along with common, open-source pipelines to help you get started quickly.
Amazon S3 Intelligent-Tiering storage class delivers automatic storage cost savings when data access patterns change through the lifecycle of instrument data, allowing for automatic cost savings that align with the way that scientific data is used. For example, you can move raw instrument data to lower access frequency storage classes once that data has been processed. Another way cost is optimized with this Guidance is with HealthOmics sequence stores. These are genomics-aware data stores that support large-scale analysis and collaborative research across entire populations, reducing long-term storage costs by automatically moving data objects that have not been accessed within 30 days to an archive storage class. HealthOmics also supports petabytes of omics data to be stored efficiently and cost effectively, allowing scientific discovery at population scale.
DataSync and HealthOmics work in tandem to minimize the environmental impacts of running cloud workloads. For example, DataSync rapidly migrates instrument files to the cloud for data storage and archival, relieving the need for an expanding on-premise data center. And, HealthOmics automatically provisions and scales your compute infrastructure, removing the need to manage servers and giving unused compute services back to the service, reducing the amount of wasted resources.
Implementation resources
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages