- AWS Solutions Library
- Guidance for Optimizing Data Architecture for Sustainability on AWS
Guidance for Optimizing Data Architecture for Sustainability on AWS
Overview
How it works
These steps provide an overview of this architecture. For diagrams highlighting different aspects of this architecture, open the tabs below.
Data ingestion
This diagram shows a real-time and batch data ingestion pattern, and a database replication pattern with recommended AWS services that serve these capabilities.
Data storage
This diagram shows the storage layer with frequently accessed data stores for operational use, and two popular storage patterns for analytics use – the data lake and the data warehouse.
Data processing
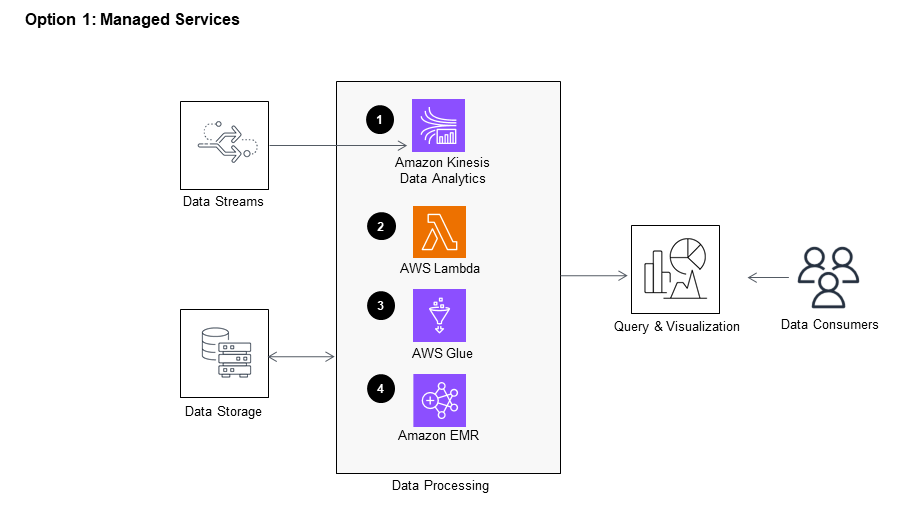
Managed services
This diagram shows the data processing layers with different AWS services that could be used to process data in real-time or in batch processing mode. Use either managed services (option 1) or self-managed (option 2).
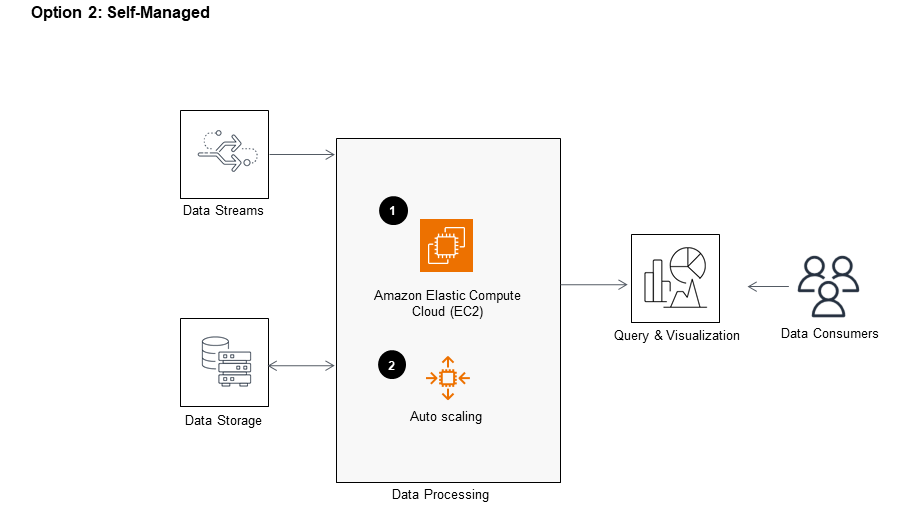
Self-managed
This diagram shows the data processing layers with different AWS services that could be used to process data in real-time or in batch processing mode. Use either managed services (option 1) or self-managed (option 2).
Data consumers
This diagram shows the data query and visualization layer with different AWS services that helps users to query and visualize data
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
To swiftly respond to incidents and events, customize Amazon CloudWatch metrics, alarms, and dashboards. This service allows you to monitor the operational health of the Guidance and notify operators of faults.
Resources deployed by this Guidance are protected by AWS Identity and Access Management (IAM) policies and principles. For example, authentication to services like Aurora, TimeStream, AWS IoT SiteWise, Amazon S3, and Amazon Redshift are managed by IAM. With IAM identity-based policies, administrators can set what actions users can perform, on which resources, and under what conditions.
Amazon S3, Aurora, DynamoDB, and Amazon Redshift are built for data storage, backup, and recovery. We recommend using AWS Backup to back up TimeStream tables. And AWS IoT SiteWise uses the highly available and durable Amazon S3 for backups.
This Guidance uses purpose-built services for each layer of its data architecture. For storage, it selects services based on access patterns (transactional, analytical), and frequency of access (hot, cold, archival). For data ingestion, it selects services based on data velocity (data streaming services, batch data ingestions). And for data processing, it selects services based on consumption patterns (real-time, batch). For query and visualization, it selects services based on personas (business insights consumers, data analysts, data engineers, and data scientists).
You can use proxy metrics—metrics that best quantify the effect of any changes you make with the associated resources. Examples of proxy metrics include CPU Utilization, Memory Utilization, and Storage Utilization that you can use to measure and optimize this Guidance based on changes you make.
This Guidance uses serverless services that reduce compute costs on data ingestion and data processing by provisioning the appropriate resources and disposing resources when processes are not running. For storage, this Guidance recommends using serverless services such as Aurora for hot data storage, as well as cost-effective and scalable services for colder layers like Amazon S3.
This Guidance uses technologies based on data access and storage patterns. For frequently accessed data, it guides you to use hot storage layers supported by Aurora, TimeStream, DynamoDB, and AWS IoT SiteWise. For lower frequency or batch consumption, it guides you to use services for colder storage layers, like Amazon S3. For specialized access patterns, like aggregations on normalized tables, it uses Amazon Redshift.
This Guidance recommends you select serverless services to reduce the chances of overprovisioning your resources. In addition, Lambda functions powered by Graviton2 are designed to deliver up to 19 percent better performance at 20 percent lower cost, leading to the additional benefit of improved environmental sustainability as a result of potential increased performance. We also recommend you review the delivery SLA to choose the appropriate patterns that reduce the consumption of resources when the resources are not needed. For example, moving to a batch ingestion pattern from real-time streaming patterns when real-time consumption is not required. Finally, it helps you to implement automation to terminate resources when not in use.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages