AWS Thai Blog
วิเคราะห์เนื้อหาจาก AWS Certified AI Practitioner : จุดเริ่มต้นสู่ AI/ML – Domain 1
ทาง AWS ได้มี Challenge สำหรับ AWS AI and ML Get Certified ช่วง valid until November 4, 2025
โดยสามารถ register ได้ที่ Link ข้างล่างครับ
Link AWS AI and ML Get Certified Challenge-Get 50% on your exams.
ในช่วงไม่กี่ปีที่ผ่านมา เราจะได้เห็นว่า ปัญญาประดิษฐ์ (AI) และ Machine Learning (ML) ได้กลายเป็นหัวใจสำคัญของการเปลี่ยนผ่านทางดิจิทัลของหลายองค์กรทั้งภาพในประเทศและทั่วโลก ซึ่ง AWS Certified AI Practitioner ถือเป็นใบรับรองใหม่ที่ออกแบบมาเพื่อให้ผู้ที่เริ่มต้นเข้าใจหลักการสำคัญของ AI/ML อย่างเป็นระบบ โดยเฉพาะ Domain 1 ที่ปูพื้นฐานเรื่องแนวคิดหลักของ AI, วงจรชีวิตของโครงการ ML และการสร้างความรับผิดชอบในการใช้ AI (Responsible AI) จากประสบการณ์ของผม ที่ได้ทำงานกับองค์กรหลายแห่ง พบว่า “ปัญหาที่แท้จริงของการนำ AI มาใช้ ไม่ได้อยู่ที่เทคโนโลยี แต่คือความเข้าใจพื้นฐานที่ไม่ชัดเจน” หลายทีมเริ่มต้นด้วยการสร้างโมเดลโดยไม่เข้าใจ lifecycle ของ AI ซึ่งทำให้โครงการหยุดชะงักกลางทาง หรือไม่ราบรื่น หรือสับสน โดย Domain 1 ของใบรับรองนี้ จึงมีประโยชน์อย่างยิ่ง เพราะช่วยให้ทีมเทคนิคและทีมธุรกิจเข้าใจ framework เดียวกัน ก่อนจะมีการเริ่มต้น journey ของ AI
โดยในบทความนี้ ผมจะอธิบายและสรุปประเด็นสำคัญจาก Domain 1 ของ AWS Certified AI Practitioner เพื่อให้เห็นภาพว่า “พื้นฐานที่ถูกต้อง” สามารถกลายเป็นจุดเริ่มต้นของการสร้างประโยชน์ทางธุรกิจด้วย AI ได้อย่างไร
ตัว AWS Certified AI Practitioner เนื้อหานั้นจะ ประกอบด้วย 5 Domains (Exam Blueprint)
• Domain 1: Fundamentals of AI and ML (20% of scored content)
• Domain 2: Fundamentals of Generative AI (24% of scored content)
• Domain 3: Applications of Foundation Models (28% of scored content)
• Domain 4: Guidelines for Responsible AI (14% of scored content)
• Domain 5: Security, Compliance, and Governance for AI Solutions (14% of
scored content)
Domain 1: :ซึ่งมีจำนวน 20% ของตัว Certificate จะพูดถึงเรื่อง พื้นฐานของ AI และ ML โดยมีส่วนประกอบ 3 ส่วนหลักๆ:
[1] – (Explain basic AI concepts and terminologies)
แนวคิดพื้นฐานและคำศัพท์เกี่ยวกับ AI:
เนื้อหาได้อธิบาย อะไรคือ AI (Artificial Intelligence)/ML (Machine Learning)/Deep Learning/Generative Artificial Intelligence
วิวัฒนาการของ AI: จากพื้นฐานสู่การสร้างสรรค์
ในโลกของเทคโนโลยี Artificial Intelligence (AI) มีการพัฒนาอย่างต่อเนื่อง โดยเริ่มจาก AI ซึ่งเป็นระบบที่ออกแบบมาให้เลียนแบบความฉลาดของมนุษย์ ตอนแรกเราเริ่มจากระบบง่ายๆ ที่ทำงานตามกฎที่กำหนด เช่น ระบบควบคุมอุณหภูมิอัตโนมัติในบ้าน,ระบบเกมที่ปรับความยากตามผู้เล่น, หุ่นยนต์ทำความสะอาดอัตโนมัติ
แล้วค่อยๆ พัฒนามาเป็น Machine Learning (ML) ที่สามารถเรียนรู้ได้จากข้อมูล เช่น ระบบกรองสแปมในอีเมล,ระบบแนะนำสินค้าใน e-commerce,ระบบตรวจจับการฉ้อโกงบัตรเครดิต
จากนั้นเทคโนโลยีก็พัฒนาต่อมาเป็น Deep Learning (DL) ที่ใช้โครงข่ายประสาทเทียม(Neural Networks)หลายชั้น ทำให้สามารถจัดการกับข้อมูลที่ซับซ้อนอย่างภาพ เสียง และข้อความได้ดียิ่งขึ้น เช่น ระบบจดจำใบหน้าในสมาร์ทโฟน,ระบบจดจำเสียงพูด,ระบบวิเคราะห์ภาพทางการแพทย์
และล่าสุดเรามาถึงยุคของ Generative AI ที่สามารถสร้างเนื้อหาใหม่ได้ ไม่ว่าจะเป็นสร้างข้อความ,สร้างภาพ,สร้างวิดีโอ,สร้างโค้ด

คำศัพท์เฉพาะ
-Neural Networks คือโครงข่ายประสาทเทียมที่จำลองการทำงานของสมองมนุษย์ ประกอบด้วยชั้นข้อมูลนำเข้า (Input Layer), ชั้นซ่อน (Hidden Layers) และชั้นผลลัพธ์ (Output Layer) ใช้สำหรับการเรียนรู้และประมวลผลข้อมูล
-Natural Language Processing (NLP) คือเทคโนโลยีที่ทำให้คอมพิวเตอร์สามารถเข้าใจ วิเคราะห์ และประมวลผลภาษามนุษย์ได้ เช่น การแปลภาษา การวิเคราะห์ความรู้สึก และการสรุปความ
-Large Language Models (LLMs) คือโมเดล Deep Learning ที่ถูกสร้างขึ้นด้วยสถาปัตยกรรม Transformer ผ่านการเทรนด้วยข้อมูลขนาดมหาศาล ทำให้สามารถเข้าใจและสร้างข้อความเหมือนมนุษย์ได้ ตัวอย่างเช่น GPT, BERT และ LLaMA
นอกจากนี้เนื้อหายังได้อธิบายประเภทของการเรียนรู้:
–Supervised Learning (การเรียนรู้แบบมีผู้สอน) เป็นการเรียนรู้ที่เหมือนมีครูคอยสอน โดยข้อมูลที่ใช้จะมีคำตอบหรือป้ายกำกับ (Label) ชัดเจน โดยโมเดลจะเรียนรู้จากตัวอย่างและคำตอบที่ถูกต้องเหล่านี้ เพื่อสร้างความสัมพันธ์ระหว่างข้อมูลนำเข้าและผลลัพธ์ที่ต้องการ มักใช้สำหรับงานทำนาย (Prediction) และการจำแนกประเภท (Classification) เช่น แยกประเภทรูปภาพสัตว์ หรือการแยกอีเมลสแปม
–Unsupervised Learning (การเรียนรู้แบบไม่มีผู้สอน) เปรียบเสมือนการให้เด็กเรียนรู้และค้นพบด้วยตัวเอง โดยข้อมูลที่ใช้จะไม่มีสอน โมเดลต้องวิเคราะห์และค้นหารูปแบบ/แพทเทิร์นเอง นิยมใช้สำหรับการจัดกลุ่ม (Clustering) และการลดมิติข้อมูล (Dimensionality Reduction) ตัวอย่างเช่น การแบ่งกลุ่มลูกค้าตามพฤติกรรมการซื้อ หรือการหารูปแบบการใช้งานของผู้ใช้
–Reinforcement Learning (การเรียนรู้สิ่งต่างๆจากการลองผิดลองถูก) คล้ายกับการฝึกสัตว์เลี้ยงด้วยระบบรางวัลและการลงโทษ โมเดลจะเรียนรู้ผ่านการลองผิดลองถูก เมื่อทำถูกจะได้รับรางวัล-Reward เมื่อทำผิดจะถูกลงโทษ เหมาะสำหรับงานที่ต้องมีการตัดสินใจต่อเนื่องและการหาวิธีที่ดีที่สุด เช่น หุ่นยนต์เรียนรู้การเดิน หรือ AI เล่นเกม
Model performance: Overfitting และ Underfitting
–Overfitting: โมเดลเรียนรู้มากเกินไป จำทุกรายละเอียดของข้อมูลฝึกสอน ทำให้ใช้กับข้อมูลใหม่ไม่ได้ เหมือนท่องจำข้อสอบเก่า แต่ทำข้อสอบจริงไม่ได้
–Underfitting: โมเดลเรียนรู้น้อยเกินไป ไม่เข้าใจรูปแบบสำคัญของข้อมูล ทำให้ทำนายทั้งข้อมูลเก่าและใหม่แย่ เหมือนเรียนรู้เนื้อหาไม่พอ ทำข้อสอบไม่ได้เลย
นอกจากนี้ ยังได้พูดถึง ความแตกต่างของชนิด data ต่างๆ ใน AI models
-Structured vs Unstructured Data: ข้อมูลที่มีโครงสร้าง vs ไม่มีโครงสร้าง
Amazon Relational Database Service/Amazon Redshift vs Amazon DynamoDB/Amazon DocumentDB
(with MongoDB compatibility)
-Labeled vs Unlabeled: ข้อมูลที่มีป้ายกำกับ vs ไม่มีป้ายกำกับ
-ข้อมูลแบบต่างๆ:
Time-series data: Amazon Timestream
Unstructured data: S3
[2] – ระบุการใช้งาน AI ใน usecase ต่างๆ:
ปัจจุบัน AI และ ML กำลังเปลี่ยนแปลงวิธีการดำเนินธุรกิจอย่างมาก เทคโนโลยีเหล่านี้ช่วยเพิ่มประสิทธิภาพการทำงาน ตั้งแต่การวิเคราะห์ข้อมูลขนาดใหญ่ การตรวจจับการฉ้อโกง ไปจนถึงการพยากรณ์แนวโน้มทางธุรกิจ
อย่างไรก็ตาม การนำ AI/ML มาใช้ต้องพิจารณาอย่างรอบคอบ ทั้งเรื่องต้นทุนการลงทุน การจัดการข้อมูล และการฝึกอบรมบุคลากร นอกจากนี้ ยังต้องคำนึงถึงข้อจำกัดของเทคโนโลยี เช่น การอธิบายที่มาของผลลัพธ์ที่อาจทำได้ยาก หรือลักษณะการทำงานที่อิงความน่าจะเป็น
สำหรับบางกรณี อาจมีทางเลือกอื่นที่เหมาะสมกว่า AI/ML การตัดสินใจนำเทคโนโลยีมาใช้จึงควรขึ้นอยู่กับความต้องการทางธุรกิจ และการวิเคราะห์ความคุ้มค่าอย่างละเอียด เพื่อให้เกิดประโยชน์สูงสุดต่อองค์กร
คำแนะนำการพิจารณาทางเลือกระหว่าง AI/ML หรือใช้ระบบอื่น: (Considering AI/ML alternatives)
แม้ว่า AI/ML จะเป็นเทคโนโลยีที่ทรงพลัง แต่ไม่ใช่คำตอบที่เหมาะสมสำหรับทุกปัญหา การตัดสินใจนำมาใช้ควรพิจารณาปัจจัยสำคัญ 3 ประการ:
- การวิเคราะห์ต้นทุนและผลประโยชน์: ต้องประเมินค่าใช้จ่ายในการจัดการข้อมูล การฝึกฝน และการดูแลรักษาโมเดล เทียบกับประโยชน์ที่จะได้รับ
- ความต้องการด้านการอธิบายผล: โมเดล AI/ML โดยเฉพาะ Neural Networks อาจอธิบายเหตุผลของการทำนายได้ยาก หากต้องการความโปร่งใสสูง อาจต้องเลือกใช้ระบบที่อธิบายได้ง่ายกว่า
- ระบบที่ต้องการผลลัพธ์แน่นอน: AI/ML ให้ผลลัพธ์แบบความน่าจะเป็น ในขณะที่บางงานต้องการผลลัพธ์ที่แน่นอนตายตัว ในกรณีนี้ระบบกฎ (Rule-based) อาจเหมาะสมกว่า
ประเภทของปัญหา Machine Learning-ML แบ่งประเภทตามลักษณะข้อมูลและเป้าหมายการเรียนรู้เป็น 3 แบบหลัก:
- Supervised Learning เป็นการเรียนรู้จากข้อมูลที่มีคำตอบกำกับ แบ่งเป็น Classification ที่ทำนายคำตอบแบบหมวดหมู่ เช่น แยกประเภทรูปภาพ และ Regression ที่ทำนายค่าต่อเนื่อง เช่น ทำนายราคาบ้าน เหมือนการเรียนที่มีครูคอยบอกคำตอบที่ถูกต้อง
- Unsupervised Learning เป็นการเรียนรู้จากข้อมูลที่ไม่มีคำตอบกำกับ โดยให้โมเดลค้นหารูปแบบหรือความสัมพันธ์ในข้อมูลเอง เช่น Clustering ที่จัดกลุ่มข้อมูลที่คล้ายกัน เหมือนการให้นักเรียนค้นพบความรู้ด้วยตัวเอง
- Anomaly Detection เป็นเทคนิคพิเศษที่ใช้ค้นหาข้อมูลผิดปกติที่แตกต่างจากข้อมูลทั่วไป มักใช้ในการตรวจจับการฉ้อโกง ความผิดปกติของระบบ หรือเหตุการณ์ที่เกิดขึ้นน้อย สามารถใช้ได้ทั้งแบบมีและไม่มีคำตอบกำกับ
บริการด้าน AI/ML ของ AWS:
Amazon Kendra: บริการค้นหาอัจฉริยะที่ใช้ ML ในการค้นหาและตอบคำถามจากเอกสารองค์กร รองรับหลายรูปแบบเอกสาร เหมาะสำหรับสร้างระบบค้นหาภายในองค์กร
Amazon Personalize: บริการสร้างระบบแนะนำแบบเรียลไทม์โดยใช้ ML เทคโนโลยีเดียวกับ Amazon.com เหมาะสำหรับแนะนำสินค้า เนื้อหา หรือประสบการณ์ที่เฉพาะเจาะจง
Amazon Translate: บริการแปลภาษาอัตโนมัติแบบเรียลไทม์ที่ใช้ Neural Machine Translation รองรับหลายภาษา เหมาะสำหรับแปลเอกสาร เว็บไซต์ หรือแอพพลิเคชัน
Amazon Lex: บริการสร้างแชทบอทและระบบสนทนาอัตโนมัติ ใช้เทคโนโลยี Deep Learning เดียวกับ Alexa เหมาะสำหรับสร้างระบบโต้ตอบอัจฉริยะ
Amazon Transcribe: บริการแปลงเสียงพูดเป็นข้อความอัตโนมัติที่แม่นยำ รองรับหลายภาษา เหมาะสำหรับถอดเสียงการประชุม พอดแคสต์ หรือวิดีโอ
Amazon Polly: บริการแปลงข้อความเป็นเสียงพูดที่เป็นธรรมชาติ รองรับหลายภาษาและเสียงที่หลากหลาย เหมาะสำหรับอ่านข้อความหรือสร้างเสียงบรรยาย
Amazon Comprehend: บริการประมวลผลภาษาธรรมชาติที่ใช้ ML วิเคราะห์ข้อความ อารมณ์ และเนื้อหา เหมาะสำหรับเข้าใจความหมายและจัดการข้อมูลที่ไม่มีโครงสร้าง
Amazon Fraud Detector: บริการตรวจจับการฉ้อโกงที่ใช้ ML และประสบการณ์จาก Amazon เหมาะสำหรับระบุธุรกรรมที่น่าสงสัยและป้องกันการฉ้อโกง
Amazon Bedrock: บริการ Foundation Models แบบ fully managed สำหรับ Gen AI รองรับหลายโมเดลจากผู้ให้บริการชั้นนำ เหมาะสำหรับพัฒนาแอพพลิเคชัน Gen AI
Amazon SageMaker: แพลตฟอร์ม ML แบบครบวงจรที่ให้เครื่องมือสำหรับสร้าง ฝึกฝน และ deploy โมเดล ML เหมาะสำหรับนักพัฒนาและนักวิทยาศาสตร์ข้อมูล

[3] – วงจรการพัฒนา ML development lifecycle:
ML Pipeline เป็นกระบวนการพัฒนาโมเดลอย่างเป็นระบบ โดยเริ่มจากการกำหนดเป้าหมายทางธุรกิจและวางกรอบปัญหาให้สามารถแก้ไขด้วย ML ตามด้วยขั้นตอนการเตรียมข้อมูล ซึ่งรวมถึงการรวบรวมข้อมูลที่มีคุณภาพ การประมวลผลข้อมูลเบื้องต้น และการสร้าง Features ที่เหมาะสม ข้อมูลเพิ่มเติม
สถาปัตยกรรม ML Lifecycle
- Business Goal Phase: เริ่มจากการกำหนดเป้าหมายธุรกิจ ประเมินความเหมาะสมของการใช้ ML กำหนด KPIs และวางแผนทรัพยากรที่จำเป็น
- Problem Framing Phase: แปลงโจทย์ธุรกิจให้เป็นปัญหาที่แก้ได้ด้วย ML เลือกประเภทโมเดลที่เหมาะสม กำหนดข้อมูลที่ต้องการและวิธีวัดผลสำเร็จ
- Data Processing Phase: จัดการข้อมูลตั้งแต่การรวบรวม ทำความสะอาด และสร้าง features ใช้บริการ AWS เช่น S3, Glue สร้าง data pipeline
- Model Development Phase: พัฒนาโมเดลด้วย SageMaker ทดลองอัลกอริทึม เทรนโมเดล และประเมินผล มีการจัดการ version control
- Deployment Phase: นำโมเดลไปใช้งานจริงผ่าน SageMaker Endpoints ออกแบบระบบให้ยืดหยุ่น สเกลได้ และปลอดภัย
- Monitoring Phase: ติดตามประสิทธิภาพโมเดลด้วย CloudWatch และ Model Monitor ตรวจสอบ data drift และตั้งระบบแจ้งเตือน


สรุป ML Lifecycle: Link
ML Lifecycle เริ่มต้นที่การระบุเป้าหมายทางธุรกิจ(Business Goal)และตรวจสอบความเหมาะสมในการใช้ ML(ML Problem Framing) ต้องมีการพิจารณาความชัดเจนของปัญหาและเป้าหมาย ประเมินความพร้อมและคุณภาพของข้อมูล รวมถึงวิเคราะห์ความคุ้มค่าในการลงทุน
การประมวลผลข้อมูล(Data Processing)เป็นขั้นตอนสำคัญที่ต้องเลือกใช้เครื่องมือที่เหมาะสม ลดการใช้ทรัพยากรที่ไม่จำเป็น และจัดการ data pipeline ให้มีประสิทธิภาพ เพื่อประหยัดทั้งเวลาและทรัพยากรในการประมวลผล
ในส่วนของการพัฒนาโมเดล(Model Development) ควรเน้นความพัฒนาแบบlongtermด้วยการเลือกอัลกอริทึมที่เหมาะสมกับงาน ใช้ทรัพยากรการประมวลผลอย่างมีประสิทธิภาพ และมีการทดสอบและปรับแต่งอย่างเป็นระบบ
การ Deployment และ Monitoring ต้องออกแบบระบบให้สเกลตามการใช้งานจริง มีการติดตามประสิทธิภาพอย่างต่อเนื่อง และพร้อมปรับปรุงเมื่อพบโอกาสในการพัฒนา
Model Options และบริการ AI/ML ของ AWS:
- AI/ML Hosted Service เป็นบริการที่พร้อมใช้งานทันที ใช้งานผ่าน API ไม่ต้องฝึกฝนโมเดล เหมาะสำหรับงานทั่วไป เช่น Amazon Comprehend ที่วิเคราะห์ข้อความ Amazon Personalize สำหรับระบบแนะนำ และ Amazon Rekognition สำหรับวิเคราะห์รูปภาพและวิดีโอ
- Pre-trained Models มีโมเดลที่ผ่านการเทรนมาแล้ว สามารถปรับแต่งเพิ่มเติมได้ เช่น Amazon SageMaker JumpStart ที่มีโมเดลสำเร็จรูปหลากหลาย และ Amazon Bedrock ที่ให้บริการ Foundation Models จากผู้ให้บริการชั้นนำ
- Fully Custom Model สำหรับสร้างโมเดลเองทั้งหมด ใช้ Amazon SageMaker ที่ให้เครื่องมือครบวงจรสำหรับพัฒนา เทรน และ deploy โมเดล ML เหมาะสำหรับปัญหาเฉพาะที่ต้องการโซลูชันแบบกำหนดเอง
แต่ละตัวเลือกมีข้อดีและข้อจำกัดต่างกัน การเลือกใช้ขึ้นอยู่กับความซับซ้อนของปัญหา ทรัพยากรที่มี และความต้องการในการปรับแต่งโมเดล
การประมวลผลข้อมูลสำหรับ ML (Data Processing) บน AWS: Link
- กระบวนการจัดการข้อมูลเริ่มจากการรวบรวมข้อมูลฝึกสอนจากแหล่งต่างๆ ผ่านการทำ ETL (Extract, Transform, Load) และการติดป้ายกำกับข้อมูล โดยใช้ AWS Glue เป็นเครื่องมือหลักในการทำ ETL และ AWS Glue Data Catalog สำหรับจัดการเมตาดาต้า
- การเตรียมข้อมูลใช้ AWS Glue DataBrew สำหรับทำความสะอาดและแปลงข้อมูล ส่วน SageMaker Ground Truth ช่วยในการติดป้ายกำกับข้อมูล ขณะที่ SageMaker Canvas ช่วยในการวิเคราะห์ข้อมูลเบื้องต้นแบบ visual interface
- การทำ Feature Engineering และการเลือก Features ที่เหมาะสมใช้ Amazon SageMaker Feature Store เพื่อจัดการ สร้าง และเก็บ features สำหรับการเทรนโมเดล รวมถึงการแบ่งข้อมูลเป็นชุดสำหรับเทรน ตรวจสอบ และทดสอบ
บริการเหล่านี้ทำงานร่วมกันเพื่อสร้าง data pipeline ที่มีประสิทธิภาพ ช่วยให้การเตรียมข้อมูลสำหรับ ML เป็นไปอย่างมีระบบและมีประสิทธิภาพ เหมาะสำหรับการพัฒนาโมเดล ML ที่มีคุณภาพ Link
การ Deploy โมเดลด้วย Amazon SageMaker
SageMaker model deployment เริ่มจากการเตรียมโมเดลที่ผ่านการเทรนแล้วและ custom container ที่มีโค้ดสำหรับ inference โดยใช้ Docker image ที่เก็บไว้ใน Amazon ECR ซึ่ง container นี้ต้องมีการกำหนด endpoint สำหรับ ping, invocations และการจัดการโมเดลตามมาตรฐานของ SageMaker
การสร้าง endpoint เริ่มจากการสร้าง SageMaker model resource ที่เชื่อมโยงกับ container image และโมเดลที่เก็บไว้ใน S3 จากนั้นกำหนดค่า endpoint configuration ที่ระบุรายละเอียดของ compute resources เช่น instance type และจำนวน instances ที่ต้องการ
เมื่อสร้าง endpoint แล้ว SageMaker จะจัดการการ deploy โดยอัตโนมัติ รวมถึงการ scale และการจัดการ traffic โดยสามารถเรียกใช้โมเดลผ่าน API ได้ทันที นอกจากนี้ยังสามารถติดตามประสิทธิภาพและการทำงานของ endpoint ผ่าน CloudWatch metrics
การ deploy บน SageMaker ช่วยลดความซับซ้อนในการจัดการโครงสร้างพื้นฐาน ทำให้นักพัฒนาสามารถโฟกัสที่การพัฒนาโมเดลและการปรับแต่งประสิทธิภาพได้อย่างมีประสิทธิภาพ โดยไม่ต้องกังวลเรื่องการจัดการ infrastructure

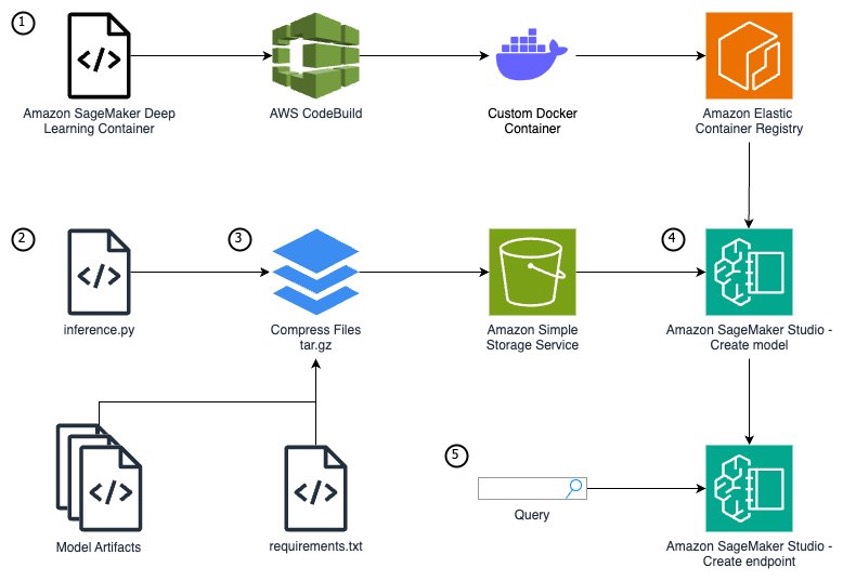
รูปภาพตัวอย่างการทำ SageMaker model deployment – สามารถอ่านเพิ่มเติมได้จากบทความ รูป1 ,รูป2
ต่อมา ขอพูดถึง การนำโมเดล Machine Learning ไปใช้งาน หรือ Amazon SageMaker Inference:
Amazon SageMaker Inference คือบริการสำหรับการนำโมเดล Machine Learning ไปใช้งานจริง หรือ เรียกว่า (Model Deployment) โดยมี 4 ปแบบที่ออกแบบมาเพื่อตอบสนองความต้องการที่แตกต่างกัน:
- Real-time Inference เหมาะสำหรับงานที่ต้องการการตอบสนองทันที เช่น ระบบแนะนำสินค้า การตรวจจับการฉ้อโกง และแชทบอท มีความเร็วในระดับมิลลิวินาที รองรับการเรียกใช้ต่อเนื่อง เหมาะกับแอพพลิเคชันที่ต้องการความเร็วสูง
- Batch Transform ใช้สำหรับประมวลผลข้อมูลจำนวนมากในคราวเดียว เช่น การวิเคราะห์เอกสาร การประมวลผลภาพจำนวนมาก หรือการวิเคราะห์ข้อมูลลูกค้ารายเดือน ประหยัดต้นทุนและสามารถทำงานตามกำหนดเวลาได้
- Serverless Inference เหมาะกับงานที่มีการใช้งานไม่สม่ำเสมอ เช่น การทดสอบโมเดลใหม่หรือแอพพลิเคชันขนาดเล็ก ไม่ต้องจัดการเซิร์ฟเวอร์ จ่ายตามการใช้งานจริง และปรับขนาดอัตโนมัติ
- Asynchronous Inference ใช้สำหรับงานที่ต้องการประมวลผลไฟล์ขนาดใหญ่ เช่น วิดีโอ เอกสารขนาดใหญ่ หรือการวิเคราะห์เสียง ไม่จำเป็นต้องรอผลทันที และช่วยประหยัดทรัพยากร
การเลือกใช้ Inference แต่ละประเภทขึ้นอยู่กับลักษณะงาน ความต้องการด้านประสิทธิภาพ และต้นทุน การเข้าใจจุดเด่นของแต่ละประเภทจะช่วยให้เลือกใช้งานได้อย่างเหมาะสมและมีประสิทธิภาพสูงสุด
ที่นี้เรามาพูดถึง การวัดผล Metrics สำหรับการประเมินโมเดล ML:
การวัดผลด้านเทคนิค-
- Classification Metrics (การวัดผลโมเดลจำแนกประเภท):
Confusion Matrix: ตารางเปรียบเทียบการทำนายกับค่าจริง ดูว่าทำนายถูก-ผิดอย่างไรบ้าง
Accuracy: สัดส่วนการทำนายถูกต้องทั้งหมด (0-1) เช่น 0.95 คือทำนายถูก 95%
Precision: จากที่ทำนายว่าเป็นบวก ทำนายถูกกี่เปอร์เซ็นต์ (0-1) สำคัญเมื่อไม่ต้องการทำนายบวกผิด
Recall: จากข้อมูลที่เป็นบวกจริง จับได้กี่เปอร์เซ็นต์ (0-1) สำคัญเมื่อต้องจับให้ได้มากที่สุด
F1 Score: ค่าเฉลี่ยระหว่าง Precision และ Recall (0-1) ใช้เมื่อต้องการความสมดุล
ROC: กราฟแสดงความสามารถในการแยกแยะข้อมูล (พื้นที่ใต้กราฟ 0-1) ยิ่งสูงยิ่งดี - Regression Metrics (การวัดผลโมเดลทำนายค่าต่อเนื่อง):
Mean squared error(MSE): ค่าเฉลี่ยความผิดพลาดยกกำลังสอง (0-∞) ยิ่งต่ำยิ่งดี ลงโทษความผิดพลาดมากหนัก
Root mean squared error (RMSE): รากที่สองของ MSE (0-∞) อ่านค่าง่ายเพราะหน่วยเดียวกับข้อมูล
Mean absolute error (MAE): ค่าเฉลี่ยความผิดพลาดแบบสัมบูรณ์ (0-∞) เข้าใจง่าย ไม่สนใจเครื่องหมาย
การวัดผลด้านธุรกิจ-การวัดผลกระทบทางธุรกิจของโครงการ AI/ML-AI/ML business metrics
- กำหนดเป้าหมายทางธุรกิจตั้งแต่เริ่มต้น-ระบุว่าต้องการแก้ปัญหาหรือพัฒนาอะไร เช่น ลดต้นทุน เพิ่มยอดขาย ปรับปรุงบริการลูกค้า
- ระบุตัวชี้วัดทางธุรกิจที่ต้องการปรับปรุง-กำหนด KPIs ที่วัดได้จริง เช่น อัตราการเติบโตของรายได้ ความพึงพอใจลูกค้า ประสิทธิภาพการทำงาน
- ประเมินความเสี่ยงและต้นทุนของข้อผิดพลาด-วิเคราะห์ผลกระทบที่อาจเกิดขึ้นและค่าใช้จ่ายที่ต้องรับผิดชอบหากเกิดความผิดพลาด
- วัดการปรับปรุงที่เกิดขึ้นจริง-ติดตามผลลัพธ์ที่ได้เทียบกับเป้าหมาย
- วัดต้นทุนที่เกิดขึ้นจริง-ติดตามค่าใช้จ่ายทั้งหมดในการพัฒนาและดำเนินการ
- เปรียบเทียบกับแบบจำลองต้นทุน-ผลประโยชน์ROI-เทียบผลลัพธ์จริงกับที่คาดการณ์ไว้
- คำนวณผลตอบแทนจากการลงทุน-วัดความคุ้มค่าของโครงการโดยรวม เพื่อประเมินความสำเร็จและวางแผนในอนาคต
บริการจัดการ ML Pipeline ของ AWS ที่เกี่ยวกับส่วนนี้
Amazon SageMaker Feature Store คือคลังเก็บ features สำหรับงาน ML ครับ เหมือนมีห้องเก็บของที่ทุกคนในทีมมาหยิบของไปใช้ได้ ไม่ต้องทำงานซ้ำซ้อน แถมมั่นใจได้ว่าทุกคนใช้ข้อมูลชุดเดียวกัน
Amazon SageMaker Model Registry เป็นที่เก็บโมเดล ML บอกได้ว่าใครสร้าง แก้ไขอะไร เมื่อไหร่ และต้องได้รับอนุมัติก่อนเอาไปใช้จริง ทำให้การจัดการโมเดลเป็นระบบมากขึ้น
Amazon SageMaker Pipelines ใช้สร้างและจัดการ ML pipeline แบบอัตโนมัติ ตั้งแต่การเตรียมข้อมูล การเทรนโมเดล ไปจนถึงการ deploy ช่วยให้กระบวนการพัฒนา ML เป็นระบบและทำซ้ำได้ เช่น ช่วยสร้างflowการผลิตโมเดล ML อัตโนมัติ ตั้งแต่เตรียมข้อมูลไปถึงเอาไปใช้งาน เหมือนมีผู้ช่วยที่คอยทำงานให้เป็นขั้นเป็นตอน ไม่มีตกหล่น
AWS Step Functions โดยเชื่อมต่อบริการต่างๆ ของ AWS เข้าด้วยกัน เหมาะสำหรับสร้าง ML pipeline ที่ซับซ้อน
Amazon MWAA จัดการ Apache Airflow เป็นบริการจัดการ Apache Airflow แบบ managed service ใช้ออกแบบ จัดตารางเวลา และติดตาม data pipeline และ ML workflow โดยไม่ต้องจัดการ infrastructure เอง เราแค่โฟกัสที่การออกแบบและจัดการ workflow ได้เลย ไม่ต้องมานั่งตั้งค่าหรือดูแลระบบเอง
สุดท้าย จากข้อมูลจะเห็น ได้ว่าเนื้อหาใน Domain 1 ของ AWS Certified AI Practitioner จะเห็นว่าใบรับรองนี้ไม่ได้สอนแค่คำศัพท์หรือเทคนิคของ AI/ML เท่านั้น แต่กำลังปูรากฐานให้ผู้เรียนเข้าใจแนวคิด “AI lifecycle” และมุมที่เชื่อมโยงเทคโนโลยีเข้ากับกลยุทธ์ทางธุรกิจอย่างแท้จริง ที่ช่วยให้ตัดสินใจในการวางแผลและใช้งาน ML
จากประสบการณ์ ผมที่ได้ร่วมกับทีมเทคนิคและผู้บริหารในหลายองค์กร พบว่าการเข้าใจ Domain 1 อย่างลึกซึ้งนั้น ช่วยให้เกิด แนวคิดและความเข้าใจ ทั้งฝ่ายเทคนิคและฝ่ายธุรกิจ ซึ่งเป็นจุดที่มักถูกละเลย สำหรับโครงการ AI ขนาดใหญ่
อีกทั้งเมื่อทั้งสองฝ่ายเข้าใจ framework เดียวกัน การวางเป้าหมาย การจัดการข้อมูล และการนำโมเดลไปใช้งานจริงจะเกิดประสิทธ์ภาพได้ดียิ่งขึ้นแน่นอน
ในมุมมองของผม Domain 1 จึงไม่ได้เป็นเพียงส่วนหนึ่งของข้อสอบ แต่เป็น blueprint สำหรับการเริ่มต้น AI อย่างมีระบบ ที่สามารถลดความเสี่ยง,เพิ่มความเร็ว เพิ่มประสิทธฺ์ภาพในการนำ AIไปใช้ในองค์กร ไม่ว่าจะอยู่ในระดับเริ่มต้นหรือกำลังขยายการใช้งาน ML ใน production — นี่คือคุณค่าที่แท้จริงของการมี “พื้นฐานที่ถูกต้อง” ก่อนก้าวเข้าสู่โลกของ AI/ML ได้เป็นอย่างดี แน่นอน
Reference & ข้อมูลเพิ่มเติม:
AWS Certified AI Practitioner information page: Link
Skillbuilder Exam Prep Plan: AWS Certified AI Practitioner (AIF-C01 – English): Link
Skillbuilder AWS Artificial Intelligence Practitioner Learning Plan: Link
Official Practice Question Set: AWS Certified AI Practitioner (AIF-C01 – English): Link
ML lifecycle: Link