- การประมวลผลบนคลาวด์คืออะไร
- ฮับแนวคิดการประมวลผลบนคลาวด์
- การวิเคราะห์
การระบุประเภทข้อมูลคืออะไร
การระบุประเภทข้อมูลคืออะไร
ในการ เรียนรู้ของเครื่อง การติดฉลากข้อมูลคือกระบวนการระบุข้อมูลดิบ (รูปภาพ ไฟล์ข้อความ วิดีโอ ฯลฯ) และเพิ่มป้ายกำกับที่มีความหมายและให้ข้อมูลอย่างน้อยหนึ่งฉลากเพื่อจัดเตรียมบริบทเพื่อให้แบบจำลองการเรียนรู้ของเครื่องสามารถเรียนรู้จากมัน เช่น ฉลากอาจระบุว่ารูปถ่ายรูปนึงรูปนึงเป็นรูปของนกหรือรถยนต์ ซึ่งมีการเปล่งคำออกมาในไฟล์เสียง หรือในกรณีที่มีก้อนเนื้องอกในภาพเอ็กซเรย์ การระบุประเภทข้อมูลเป็นขั้นตอนที่จำเป็นสำหรับการใช้งานที่หลากหลาย เช่น คอมพิวเตอร์วิทัศน์ การประมวผลภาษาธรรมชาติ และการรู้จำคำพูด
การระบุประเภทข้อมูลทำงานอย่างไร
ทุกวันนี้ โมเดลของแมชชีนเลิร์นนิงที่ใช้งานได้จริงโดยส่วนใหญ่ใช้การเรียนรู้แบบมีผู้ดูแล ซึ่งจะใช้อัลกอริทึมจับคู่อินพุตหนึ่งรายการกับเอาต์พุตหนึ่งรายการ เพื่อให้การเรียนรู้แบบมีผู้ดูแลใช้ได้ผล คุณจำเป็นต้องมีชุดข้อมูลที่มีป้ายกำกับที่โมเดลสามารถเรียนรู้เพื่อการตัดสินใจที่ถูกต้อง การระบุประเภทข้อมูลมักจะเริ่มต้นด้วยการขอให้มนุษย์ตัดสินเกี่ยวกับข้อมูลที่ไม่มีป้ายกำกับที่ได้รับ ตัวอย่างเช่น อาจขอให้ผู้ติดป้ายกำกับติดแท็กรูปภาพทั้งหมดในชุดข้อมูลที่ “ภาพถ่ายมีนกหรือไม่” เป็นความจริง การติดแท็กอาจผิวเผินพอ ๆ กับคำตอบ ใช่/ไม่ ที่ไม่ซับซ้อน หรือละเอียดพอ ๆ กับการระบุพิกเซลเฉพาะในรูปภาพที่เกี่ยวข้องกับนก โมเดลของแมชชีนเลิร์นนิงใช้ป้ายกำกับที่มนุษย์จัดเตรียมไว้ในการเรียนรู้รูปแบบพื้นฐานในกระบวนการที่เรียกว่า “การฝึกอบรมโมเดล“ ผลลัพธ์ที่ได้คือโมเดลที่ผ่านการฝึกอบรมซึ่งใช้ในการทำนายข้อมูลใหม่ได้
ในแมชชีนเลิร์นนิง ชุดข้อมูลที่มีป้ายกำกับเหมาะสมที่คุณใช้เป็นมาตรฐานวัตถุประสงค์ในการฝึกอบรมและประเมินโมเดลที่ได้รับมักจะเรียกว่า “ผลเฉลย (Ground Truth)” ความถูกต้องของโมเดลที่ผ่านการฝึกอบรมของคุณจะขึ้นอยู่กับความถูกต้องของผลเฉลยของคุณ ดังนั้นการใช้เวลาและทรัพยากรเพื่อให้แน่ใจว่าการติดป้ายกำกับข้อมูลมีความถูกต้องสูงจึงเป็นสิ่งสำคัญ
ประเภททั่วไปของการระบุประเภทข้อมูลมีอะไรบ้าง
คอมพิวเตอร์วิชัน
เมื่อสร้างระบบการมองเห็นด้วยคอมพิวเตอร์ อันดับแรกคุณต้องติดป้ายกำกับรูปภาพ พิกเซล หรือจุดสำคัญ หรือสร้างเส้นขอบที่ครอบรูปภาพดิจิทัลอย่างสมบูรณ์ หรือที่เรียกว่ากล่องจำกัดขนาดเพื่อสร้างชุดข้อมูลการฝึกอบรมของคุณ ตัวอย่างเช่น คุณสามารถจำแนกภาพตามประเภทคุณภาพ (เช่น รูปภาพของผลิตภัณฑ์เทียบกับไลฟ์สไตล์) หรือเนื้อหา (สิ่งที่อยู่ในภาพจริงๆ) หรือคุณสามารถแบ่งส่วนรูปภาพได้ที่ระดับพิกเซล จากนั้นคุณสามารถใช้ข้อมูลการฝึกอบรมนี้เพื่อสร้างแบบจำลองการมองเห็นด้วยคอมพิวเตอร์ที่ใช้ในการจัดหมวดหมู่รูปภาพได้โดยอัตโนมัติ ตรวจจับตำแหน่งของอ็อบเจกต์ ระบุจุดสำคัญในรูปภาพ หรือแบ่งส่วนรูปภาพได้
การประมวลผลภาษาธรรมชาติ
การประมวลผลภาษาธรรมชาติกำหนดให้คุณต้องระบุส่วนสำคัญของข้อความด้วยตนเองหรือแท็กข้อความด้วยป้ายกำกับเฉพาะเพื่อสร้างชุดข้อมูลการฝึกอบรมของคุณเป็นอันดับแรก ตัวอย่างเช่น คุณอาจต้องการระบุความรู้สึกหรือเจตนาของคำกล่าวย่อ ระบุส่วนต่างๆ ของคำพูด จำแนกคำนามชี้เฉพาะ เช่น สถานที่และผู้คน และระบุข้อความในรูปภาพ ไฟล์ PDF หรือไฟล์อื่นๆ ในการทำเช่นนี้ คุณสามารถวาดกล่องจำกัดขนาดรอบข้อความ จากนั้นถอดเนื้อหาข้อความในชุดข้อมูลการฝึกอบรมด้วยตนเอง โมเดลการประมวลผลภาษาธรรมชาติใช้สำหรับการวิเคราะห์ความรู้สึก การรู้จำชื่อเอนทิตี และการรู้จำอักขระด้วยแสง
การประมวลผลเสียง
การประมวลผลเสียงจะแปลงเสียงทุกประเภท เช่น การพูด เสียงของสัตว์ป่า (เสียงเห่า เสียงผิวปาก หรือเสียงร้องจ๊อกแจ๊ก) และเสียงอาคาร (กระจกแตก สแกน หรือสัญญาณเตือนภัย) ให้เป็นรูปแบบที่มีโครงสร้างเพื่อให้นำไปใช้ในแมชชีนเลิร์นนิงได้ การประมวลผลเสียงมักจะกำหนดให้คุณต้องถอดเนื้อหาเป็นข้อความที่เขียนด้วยตนเองก่อน เมื่อทำเช่นนั้น คุณจะสามารถค้นพบข้อมูลที่ลึกซึ้งยิ่งขึ้นเกี่ยวกับเสียงได้โดยการเพิ่มแท็กและจัดหมวดหมู่เสียง เสียงที่จัดหมวดหมู่แล้วจะกลายเป็นชุดข้อมูลการฝึกอบรมของคุณ
แนวทางปฏิบัติที่ดีที่สุดสำหรับการระบุประเภทข้อมูลคืออะไร
มีเทคนิคมากมายในการปรับปรุงประสิทธิภาพและความถูกต้องของการระบุประเภทข้อมูล บางส่วนของเทคนิคเหล่านี้ ได้แก่
- อินเทอร์เฟซงานที่ใช้งานง่ายและคล่องตัว เพื่อช่วยลดภาระการรู้จำและการเปลี่ยนบริบทสำหรับผู้ติดป้ายกำกับให้น้อยที่สุด
- ฉันทามติของผู้ติดป้ายกำกับ เพื่อช่วยลดข้อผิดพลาด/อคติของคำอธิบายประกอบของแต่ละบุคคล ฉันทามติของผู้ติดป้ายกำกับจะเกี่ยวข้องกับการส่งอ็อบเจกต์ชุดข้อมูลแต่ละรายการไปยังคำอธิบายประกอบหลายรายการ จากนั้นรวมคำตอบ (เรียกว่า “คำอธิบายประกอบ”) เป็นป้ายกำกับเดียว
- การตรวจสอบป้ายกำกับ เพื่อตรวจสอบความถูกต้องของป้ายกำกับและอัปเดตตามความจำเป็น
- การเรียนรู้เชิงรุก เพื่อทำให้การระบุประเภทข้อมูลมีประสิทธิภาพมากขึ้นโดยการใช้แมชชีนเลิร์นนิงในการระบุข้อมูลที่มีประโยชน์มากที่สุดที่มนุษย์จะต้องติดป้ายกำกับให้
จะระบุประเภทข้อมูลอย่างมีประสิทธิภาพได้อย่างไร
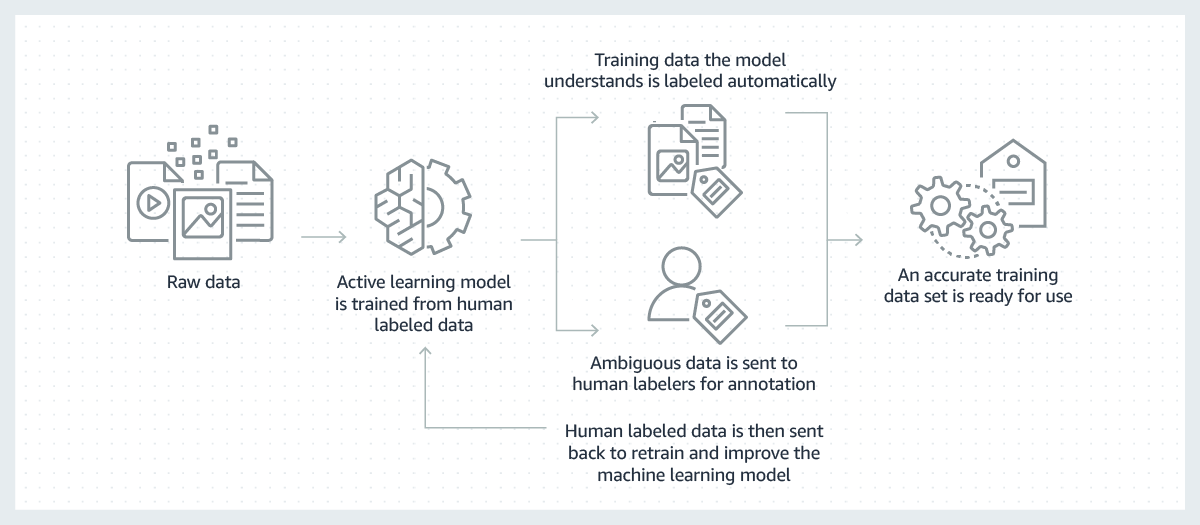
Machine Learning ที่ประสบความสำเร็จสร้างขึ้นบนข้อมูลการฝึกที่มีคุณภาพสูงจำนวนมาก แต่กระบวนการสร้างข้อมูลการฝึกที่จำเป็นในการสร้างโมเดลเหล่านี้มักมีราคาแพง ซับซ้อน และใช้เวลานาน โมเดลส่วนใหญ่ที่สร้างขึ้นในปัจจุบันกำหนดให้มนุษย์ต้องติดป้ายกำกับข้อมูลด้วยตนเองในลักษณะที่จะช่วยให้โมเดลสามารถเรียนรู้วิธีการตัดสินใจได้อย่างถูกต้อง เพื่อเอาชนะความท้าทายนี้ คุณสามารถทำให้การติดป้ายกำกับมีประสิทธิภาพมากขึ้นได้โดยการใช้โมเดลของแมชชีนเลิร์นนิงในการติดป้ายกำกับข้อมูลโดยอัตโนมัติ
ในกระบวนการนี้ โมเดลของแมชชีนเลิร์นนิงสำหรับการติดป้ายกำกับข้อมูลจะได้รับการฝึกอบรมเป็นครั้งแรกในชุดย่อยของข้อมูลดิบที่มนุษย์เป็นผู้ติดป้ายกำกับ ในกรณีที่โมเดลการติดป้ายกำกับมีผลลัพธ์ที่มีความเชื่อมั่นสูงโดยอิงตามสิ่งที่ได้เรียนรู้จนถึงปัจจุบัน โมเดลดังกล่าวจะใช้ป้ายกำกับกับข้อมูลดิบโดยอัตโนมัติ ในกรณีที่โมเดลการติดป้ายกำกับมีผลลัพธ์ที่มีความเชื่อมั่นต่ำ โมเดลดังกล่าวจะส่งต่อข้อมูลไปยังมนุษย์เพื่อให้ดำเนินการติดป้ายกำกับ จากนั้นป้ายกำกับที่มนุษย์สร้างขึ้นจะถูกส่งกลับไปยังโมเดลการติดป้ายกำกับ เพื่อให้โมเดลเรียนรู้และปรับปรุงความสามารถในการติดป้ายกำกับชุดข้อมูลดิบถัดไปโดยอัตโนมัติ เมื่อเวลาผ่านไป โมเดลจะติดป้ายกำกับข้อมูลได้มากขึ้นเรื่อย ๆ โดยอัตโนมัติ และจะทำให้การสร้างชุดข้อมูลการฝึกอบรมเร็วขึ้นเป็นอย่างมาก
AWS รองรับข้อกำหนดการระบุประเภทข้อมูลของคุณได้อย่างไร
Amazon SageMaker Ground Truth ช่วยลดเวลาและแรงงานที่ต้องใช้ในการสร้างชุดข้อมูลสำหรับการฝึกอบรมได้เป็นอย่างมาก SageMaker Ground Truth มอบการเข้าถึงที่ง่ายดายให้กับผู้ติดป้ายกำกับทั้งจากทางสาธารณะและส่วนตัว และมอบเวิร์กโฟลว์และอินเทอร์เฟซในตัวสำหรับงานการติดป้ายกำกับทั่วไป การเริ่มต้นใช้งาน SageMaker Ground Truth เป็นเรื่องง่าย สามารถใช้บทแนะนำสอนการเริ่มต้นใช้งานเพื่อสร้างงานติดป้ายกำกับครั้งแรกของคุณได้ภายในเวลาไม่กี่นาที
เริ่มต้นใช้งานการระบุประเภทข้อมูลบน AWS โดยการสร้างบัญชีวันนี้
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages