- الذكاء الاصطناعي المولّد›
- Amazon Bedrock›
- التقييمات
تقييمات Amazon Bedrock
يمكنك تقييم نماذج التأسيس، بما في ذلك النماذج المخصصة والمستوردة، للعثور على النماذج التي تناسب احتياجاتك. يمكنك أيضًا تقييم عملية الاسترجاع أو سير عمل التوليد المُعزَّز بالاسترداد (RAG) الشامل في قواعد المعرفة في Amazon Bedrock.
نظرة عامة
توفر Amazon Bedrock أدوات تقييم لك لتسريع اعتماد تطبيقات الذكاء الاصطناعي المولّد. قم بتقييم نموذج التأسيس لحالة الاستخدام ومقارنته وتحديده باستخدام ميزة تقييم النماذج (Model Evaluation). قم بإعداد تطبيقات التوليد المُعزز بالاسترداد (RAG) للإنتاج المبنية على قواعد المعرفة في Amazon Bedrock أو أنظمة التوليد المُعزز بالاسترداد (RAG) المخصصة من خلال تقييم وظائف الاسترداد والتوليد.
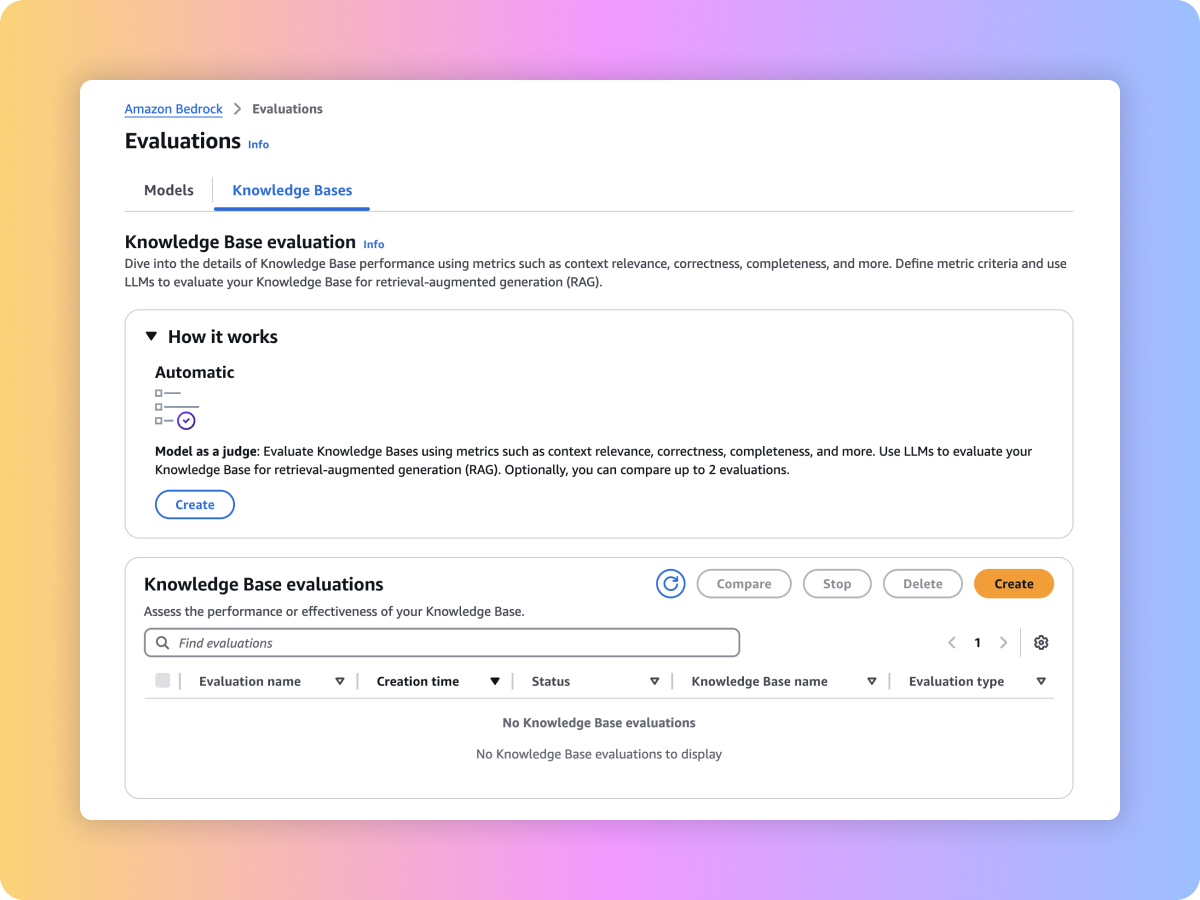
أنواع التقييم
استخدم "نموذج LLM كمُقيِّم" لتقييم مخرجات النموذج باستخدام مجموعات بيانات الأوامر المخصصة مع مقاييس مثل الصحة والاكتمال والضرر.
يمكنك تقييم مخرجات النموذج باستخدام خوارزميات ومقاييس اللغة الطبيعية التقليدية مثل BERT Score وF1 وتقنيات المطابقة الدقيقة الأخرى، باستخدام مجموعات بيانات الأوامر المضمنة أو بإمكانك إحضار مجموعات بيانات الخاصة.
يمكنك تقييم مخرجات النماذج عبر فريقك الداخلي أو تكليف AWS بإدارة التقييمات الخاصة بالاستجابات لمجموعات المطالبات المخصّصة لديك باستخدام مقاييس جاهزة أو مخصّصة.
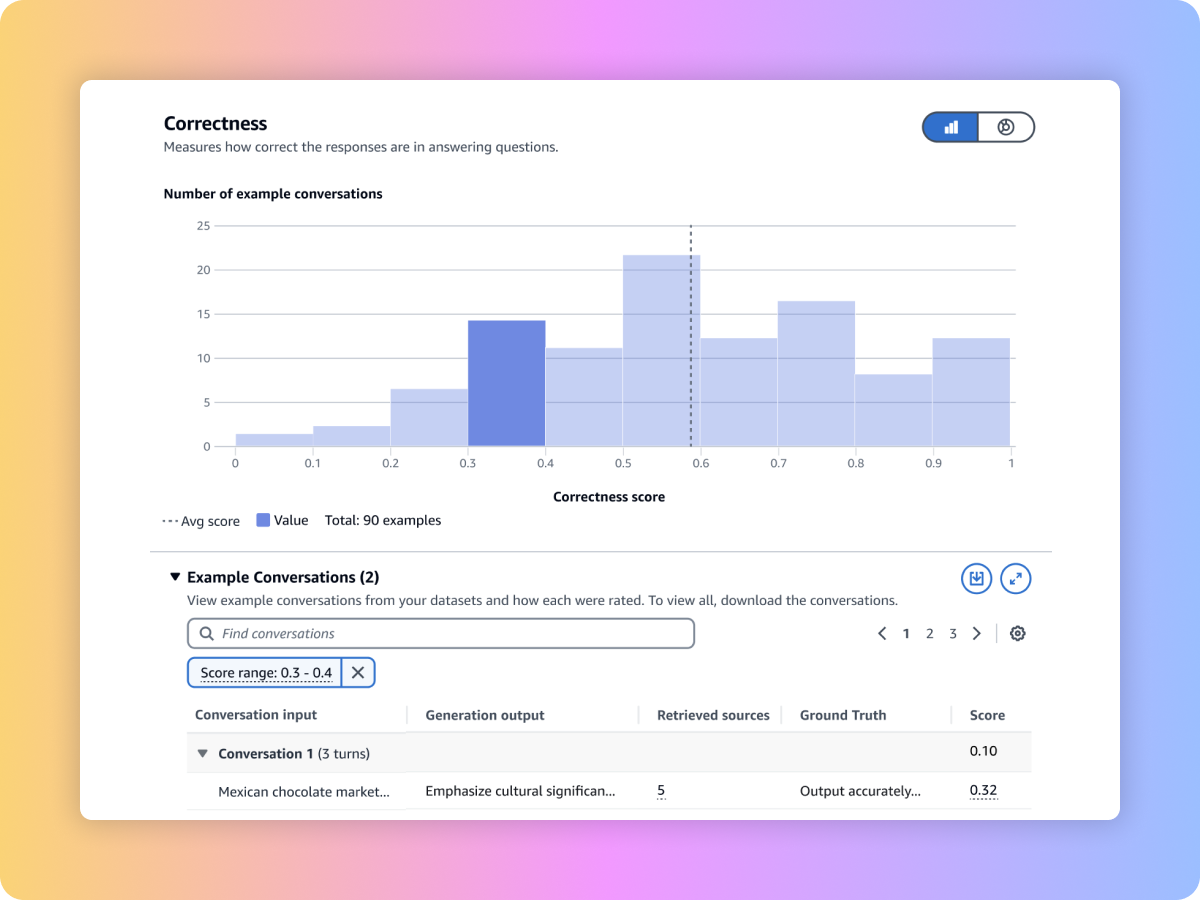
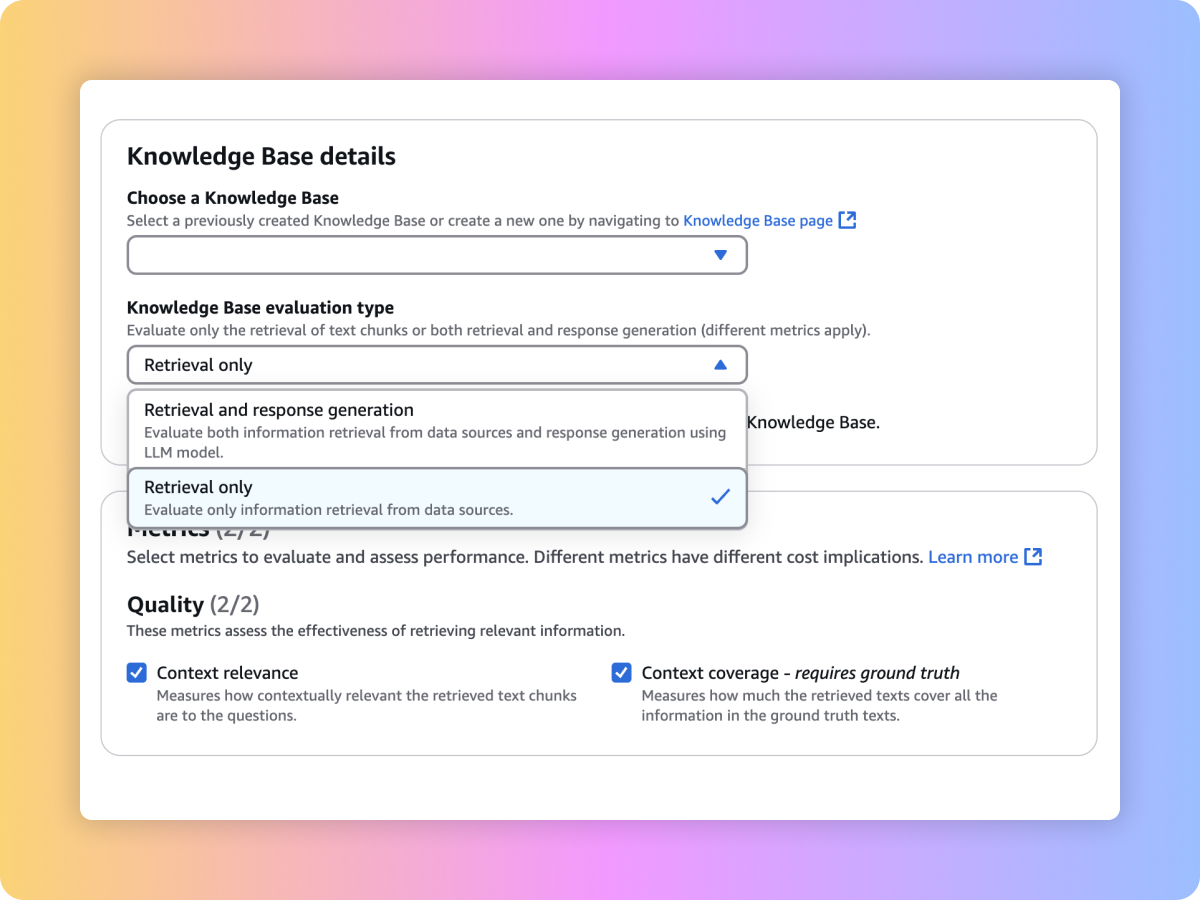
يمكنك تقييم مدى جودة الاسترجاع في نظام التوليد المُعزَّز بالاسترداد (RAG) المخصّص أو في قواعد المعرفة التابعة لـ Amazon Bedrock بالاعتماد على مطالباتك ومعايير مثل ملاءمة السياق وشموليته.
يمكنك تقييم المحتوى الناتج عن سير عمل التوليد المُعزَّز بالاسترداد (RAG) الكامل لديك، سواء أُنشئ عبر مسار RAG المخصّص أو من خلال قواعد المعرفة في Amazon Bedrock. كما يمكنك استخدام التعليمات والمقاييس مثل الإخلاص (اكتشاف الهلوسة) والصواب والاكتمال.
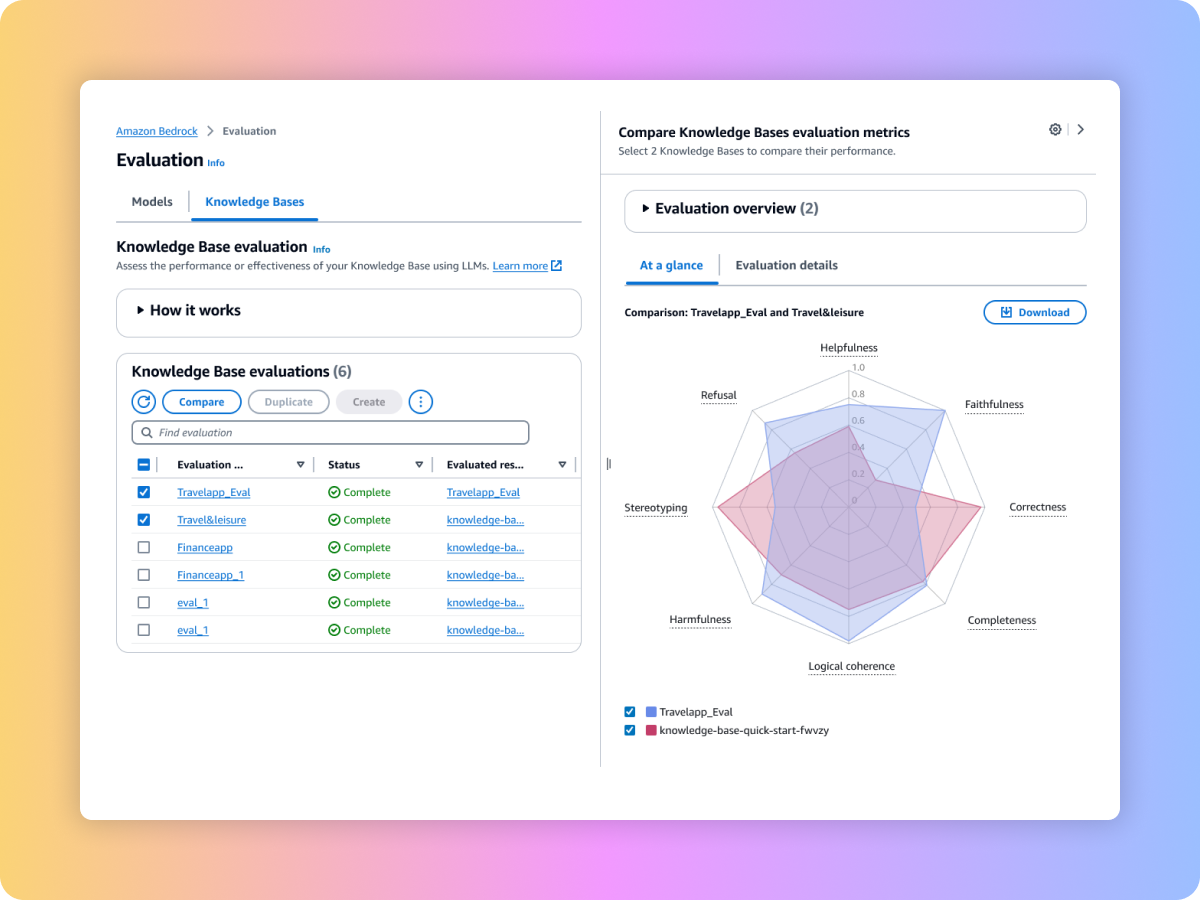
تقييم سير العمل الشامل الخاص بالتوليد المُعزَّز بالاسترداد (RAG)
تأكد من الاسترجاع الكامل والملائم من نظام التوليد المعزز للاسترداد (RAG)
تقييم نماذج التأسيس (FMs) لتحديد النموذج الأفضل لحالة الاستخدام الخاصة بك
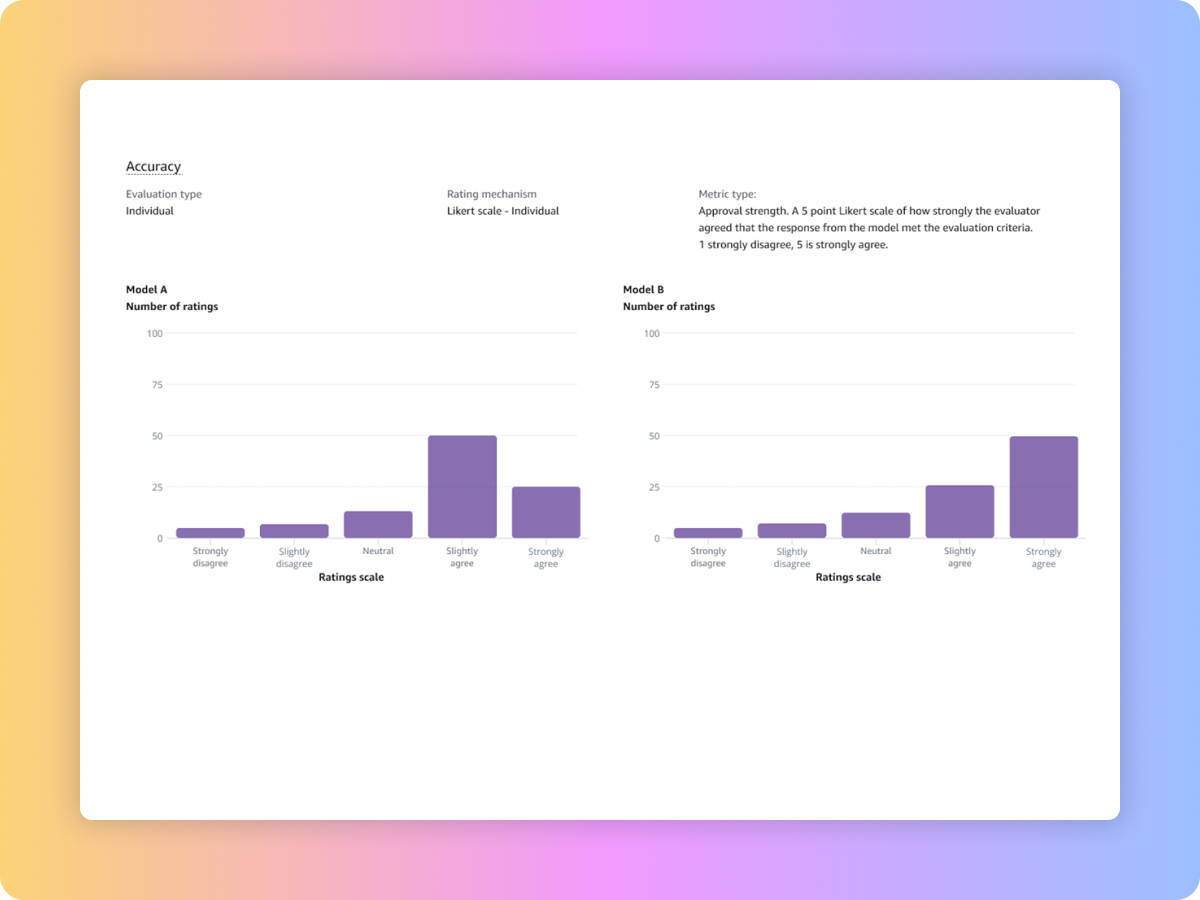
قارن النتائج عبر وظائف التقييم المتعددة لاتخاذ القرارات بشكل أسرع