AWS Architecture Blog
Internet Routing and Traffic Engineering
Internet Routing
Internet routing today is handled through the use of a routing protocol known as BGP (Border Gateway Protocol). Individual networks on the Internet are represented as an autonomous system (AS). An autonomous system has a globally unique autonomous system number (ASN) which is allocated by a Regional Internet Registry (RIR), who also handle allocation of IP addresses to networks. Each individual autonomous system establishes BGP peering sessions to other autonomous systems to exchange routing information. A BGP peering session is a TCP session established between two routers, each one in a particular autonomous system. This BGP peering session rides across a link, such as a 10Gigabit Ethernet interface between those routers. The routing information contains an IP address prefix and subnet mask. This translates which IP addresses are associated with an autonomous system number (AS origin). Routing information propagates across these autonomous systems based upon policies that individual networks define.
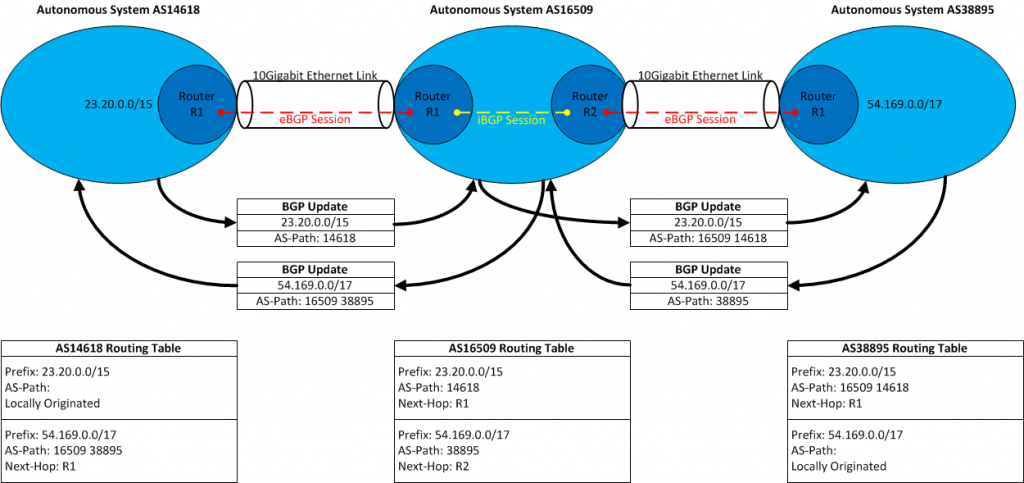
This is where things get a bit interesting because various factors influence how routing is handled on the Internet. There are two main types of relationships between autonomous systems today: Transit and Peering.
Transit is where an autonomous system will pay an upstream network (known as a transit provider) for the ability to forward traffic towards them who will forward that traffic further. It also provides for the autonomous system purchasing (who is the customer in this relationship) to have their routing information propagated to their adjacencies. Transit involves obtaining direct connectivity from a customer network to an upstream transit provider network. These sorts of connections can be multiple 10Gigabit Ethernet links between each other’s routers. Transit pricing is based upon network utilization in a particular dominant direction with 95th percentile billing. A transit provider will look at a months worth of utilization and in the traffic dominant direction they will bill on the 95th percentile of utilization. The unit used in billing is measured in bits-per-second (bps) and is communicated in a price per Mbps (for example – $2 per Mbps).

Peering is where an autonomous system will connect to another autonomous system and agree to exchange traffic with each other (and routing information) of their own networks and any customers (transit customers) they have. With peering, there are two methods that connectivity is formed on. The first is where direct connectivity is established between individual networks routers with multiple 10Gigabit Ethernet or 100Gigabit Ethernet links. This sort of connectivity is known as “private peering” or PNI (Private Network Interconnect). This sort of connection provides both parties with clear visibility into the interface utilization of traffic in both directions (inbound and outbound). Another form of peering that is established is via Internet Exchange switches, or IX’s. With an Internet Exchange, multiple networks will obtain direct connectivity into a set of Ethernet switches. Individual networks can establish BGP sessions across this exchange with other participants. The benefit of the Internet Exchange is that it allows multiple networks to connect to a common location and use it for one-to-many connectivity. A downside is that any given network does not have visibility into the network utilization of other participants.

Most networks will deploy their network equipment (routers, Dense Wave Division Multiplexing (DWDM) transport equipment) into colocation facilities where networks will establish direct connectivity to each other. This can be via Internet Exchange switches (which are also found in these colocation facilities) or direct connections which are fiber optics cables ran between individual suites/racks where the network gear is located.

Routing Policy
Networks will define their routing policy to prefer routing to other networks based upon a variety of items. The BGP best path decision process in a routers operating system dictates how a router will prefer one BGP path over another. Network operators will write their policy to influence that BGP best-path decision process based upon factors such as the cost to deliver traffic to a destination network in addition to performance.
A typical routing policy within most networks will dictate that internal (their own) and routes learned from their own customers are to be preferred over all other paths. After that, most networks will then prefer peering routes since peering is typically free and often times can provide a shorter/optimal path to reach a destination. Finally the least preferred route to a destination is over paid transit links. When it comes to transit paths, both cost and performance are typically factors in determining how to reach a destination network.
Routing policies themselves are defined on routers in a simple text-based policy language that is specific to the router operating system. They contain two types of functions: matching on one or multiple routes and an action for that match. The matching can include a list of actual IP prefixes and subnet lengths, ASN origins, AS-Paths or other types of BGP attributes (communities, next-hop, etc). The actions can include resetting BGP attributes such as local-preference, Multi-Exit-Discriminators (MED) and various other values (communities, Origin, etc). Below is a simplified example of a routing policy on routes learned from a transit provider. It has multiple terms to permit an operator to match on specific Internet routes to set a different local-preference value to control what traffic should be forwarded through that provider. There are additional actions to set other BGP attributes related to classifying the routes so they can be easily identified and acted upon by other routers in the network.

Network operators will tune their routing policy to determine how to send traffic and how to receive traffic through adjacent autonomous systems. This practice is generally known as BGP traffic-engineering. Making outbound traffic changes is by far the easiest to implement because it involves identifying the particular routes you are interested in directing and increasing the routing preference to egress through a particular adjacency. Operators must take care to examine certain things before and after any policy change to understand the impact of their actions.
Inbound traffic-engineering is a bit more difficult as it requires a network operator to alter routing information announcements leaving your network to influence how other autonomous systems on the Internet prefer to route to you. While influencing the directly adjacent networks to you is somewhat trivial, influencing networks further beyond those directly connected can be tricky. This technique requires the use of features that a transit provider can grant via BGP. In the BGP protocol, there is a certain type of attribute known as Communities. Communities are strings you can pass in a routing update across BGP sessions. Most networks use communities to classify routes as transit vs. peer vs. customer. The transit-customer relationship usually gives certain capabilities to a customer to control the further propagation of routes to their adjacencies. This grants a network with the ability to traffic-engineer further upstream to networks it is not directly connected to.
Traffic-engineering is used for several reasons today on the Internet. The first reason might be to reduce bandwidth costs by preferring particular paths (different transit providers). The other is for performance reasons, where a particular transit provider may have less-congested/lower-latency path to a destination network. Network operators will view a variety of metrics to determine if there is a problem and start to make policy changes to examine the outcome. Of course on the Internet, the scale of the traffic being moved around counts. Moving a few Gbps of traffic from one path to another may improve performance, but if you move tens of Gbps over you may encounter congestion on this newly selected path. The links between various networks on the Internet today operate where they scale capacity based upon observed utilization. Even though you may be paying a transit provider for connectivity, this doesn’t mean every link to external networks is scaled for the amount of traffic you wish to push. As traffic grows, links will be added between individual networks. So causing a massive change in utilization on the Internet can result in congestion as these new paths are handling an increased amount of traffic than they never had before. The result is that network operators must pay attention when moving traffic over in increments as well as communication with other networks to gauge the impact of any traffic moves.


Complicating the above traffic engineering operations is that you are not the only person on the Internet trying to push traffic to certain destinations. Other networks are also in a similar position where they’re trying to deliver traffic and will perform their own traffic-engineering. There are also many networks that will refuse to peer with other networks for several reasons. For example, some networks may cite an imbalance in in vs. outbound (traffic ratios) or feel that traffic is being dumped on their network. In these cases, the only way to reach these destinations is via a transit provider. In some cases, these networks may offer a “paid peering” product to provide direct connectivity. That paid peering product may be priced at a value that is lower the price of what you would pay for transit or could offer an uncongested path that you’d normally observe over transit. Just because you have a path via transit doesn’t mean the path is uncongested at all hours of the day (such as during peak hours).
One way to eliminate the hops between networks is to do just that – eliminate them via direct connections. AWS provides a service to do this known as AWS Direct Connect. With Direct Connect, customers can connect their network directly into the AWS network infrastructure. This will enable bypassing the Internet via direct physical connectivity and remove any potential Internet routing or capacity issues.
Traceroute
In order to determine the paths traffic is taking, tools such as traceroute are very useful. Traceroute operates by sending sending packets to a given destination network and it sets the initial IP TTL value to one. The upstream device will generate an ICMP TTL Exceeded message back to you (the source) which will reveal the first hop in your path to the destination. Subsequent packets will be sent from the source and increment the IP TTL value to show each hop along the way towards the destination. It is important to remember that Internet routing typically involves asymmetric paths – the traffic going towards a destination will take a separate set of hops on the return path. When performing traceroutes to diagnose routing issues it is very useful to obtain the reverse path to help isolate a particular direction of traffic being an issue. With an understanding of both directions traffic is taking, it is then easier to understand what sort of traffic-engineering changes can be made. When dealing with Network Operation Centers (NOCs) or support groups, it is important to provide the Public IP of the source and destination addresses involved in the communication. This provides individuals with the information they can use to help reproduce the issue that is being encountered. It is also useful to include any specific details surrounding the communication, such as if it was HTTP (TCP/80) or HTTPS (TCP/443). Some traceroute applications provide the user with the ability to generate its probes using a variety of protocols such as ICMP Echo Request (ping), UDP or TCP packets to a particular port. Several traceroute programs by default will use ICMP Echo Request or UDP packets (destined to a particular port range). While these work most of the time, various networks on the Internet may filter these sorts of packets and it is recommended to use a traceroute probe that replicates the type of traffic you intend to use to the destination network. For example, using traceroute with TCP/80 or TCP/443 can yield better results when dealing with firewalls or other packet filtering.
An example of a UDP based traceroute (using well-defined traceroute port ranges), where multiple routes will permit generating TTL Exceeded for packets bound for those destination ports:

Note that the last hop does not respond, since it most likely denies UDP packets destined to high ports.
With the same traceroute using TCP/443 (HTTPS), we find multiple routers do not respond but the destination does respond since it is listening on TCP/443:
TCP Traceroute to port 443 (HTTPS):

The hops revealed within traceroute provide some insight into the sort of network devices your packets are traversing. Many network operators will add descriptive information in the DNS reverse PTR records, though each network is going to be different. Typically the DNS entries will indicate the router name, some sort of geographical code and the physical or logical router interface the traffic has traversed. Each individual network names their own routers different so the information here is going to usually indicate if a device is a “core” router (no external or customer interfaces) or an “edge” router (with external network connectivity). Of course, this is not a hard rule and it is common to find multi-function devices within a network. The geographical identifier can vary between IATA airport codes, telecom CLLI codes (or a variation upon them) or internally generated identifiers that are unique to that particular network. Occasionally shortened versions of a physical address or city names will appear in here as well. The actual interface can indicate the interface type and speed, though these are only as accurate as you believe an operator is to publicly reveal this and keep their DNS entries up to date.

One important part of traceroute is that the data should be taken with some skepticism. Traceroute will display round-trip-time (RTT) of each individual hop as the packets traverse through the network to their destination. While this value can provide some insight into the latency to these hops, the actual value can be influenced from a variety of factors. For instance, many modern routers today treat packets that TTL expire on them as a low priority when compared to other functions the router is doing (forwarding packets, routing protocols). As a result, the handling of the TTL expired packets and subsequent ICMP TTL Exceeded message generated can take some period of time. This is why it is very common to occasionally see high RTT on intermediate hops within a traceroute (up to hundreds of milliseconds). This does not always indicate that there is a network issue and individuals should always measure the end-to-end latency (via ping or some application tests). In situations where the RTT does increase at a particular hop and continue to increase, this can be an indicator of an overall increase in latency at a particular point in the network. Another item frequently observed in traceroutes are hops that do not respond to traceroute which will be displayed as *’s. This means that the router(s) at this particular hop have either dropped the TTL expired packet or has not generated the ICMP TTL Exceeded message. This is usually the result of two possible things. The first is that many modern routers today implement Control-Plane Policing (CoPP) which are packet filters on the router to control how certain types of packets are handled. In many modern routers today, the use of ASICs (Application-Specific Integrated Circuit) have improved packet lookup & forwarding functions. When a router ASIC receives a packet with the TTL value of one, they will punt the packet to an additional location within the router to handle the ICMP TTL Exceeded generation. On most routers, the ICMP TTL Exceeded generation is done on a CPU integrated on a linecard or the main brain of the router itself (known as a route processor, routing engine or supervisor). Since the CPU of a linecard or routing engine is busy performing things such as forwarding table programming and routing protocols, routers will allow protections to be put in place to restrict the rate of how many TTL exceeded packets can be sent to these components. CoPP allows an operator to set functions such as limiting TTL Exceeded messages to a value such as 100 packets per second. Additionally the router itself may have an additional rate-limiter to address how many ICMP TTL Exceeded messages can be generated as well. In this situation, you’ll find that hops in your traceroute may sometimes not reply at all because of the use of CoPP. This is also why when performing pings to individual hops (routers) on a traceroute you will see packet loss because CoPP is dropping the packets. The other area where CoPP can be applied is where the router may simply deny all TTL exceeded packets. Within traceroute, these hops will always respond with *’s no matter how many times you execute traceroute.
A good presentation that explains using traceroute on the Internet and interpreting its results is found here: https://www.nanog.org/meetings/nanog45/presentations/Sunday/RAS_traceroute_N45.pdf
Troubleshooting issues on the Internet is no easy task and it requires examining multiple sets of information (traceroute, BGP routing tables) to come to a conclusion as to what can be occurring. The use of Internet looking glasses or route servers is useful to providing a different vantage point on the Internet when troubleshooting. The Looking Glass Wikipedia page has several links to sites which you can use to perform pings, traceroutes and examining a BGP routing table from different spots around the world in various networks.
When reaching out to networks or posting in forums looking for support for Internet routing issues it is important to provide useful information for troubleshooting. This includes the source IP address (the Public IP, not a Private/NAT translated one), the destination IP (once again, the Public IP), what protocol and ports being used (TCP/80 for example) and the specific time/date of when you observed the issue. Traceroutes in both directions are incredibly useful since paths on the Internet can be asymmetric.