AWS News Blog
Archiving Amazon S3 Data to Amazon Glacier

|
(Editor’s note, April 22, 2022: Since this article was originally published, additional helpful resources have also become available, including Getting started using the Amazon S3 Glacier storage classes and Best practices for archiving large datasets with AWS.)
AWS provides you with a number of data storage options. Today I would like to focus on Amazon S3 and Amazon Glacier and a new and powerful way for you to use both of them together.
Both of the services offer dependable and highly durable storage for the Internet. Amazon S3 was designed for rapid retrieval. Glacier, in contrast, trades off retrieval time for cost, providing storage for as little at $0.01 per Gigabyte per month while retrieving data within three to five hours.
How would you like to have the best of both worlds? How about rapid retrieval of fresh data stored in S3, with automatic, policy-driven archiving to lower cost Glacier storage as your data ages, along with easy, API-driven or console-powered retrieval?
Sound good? Awesome, because that’s what we have! You can now use Amazon Glacier as a storage option for Amazon S3.
There are four aspects to this feature — storage, archiving, listing, and retrieval. Let’s look at each one in turn.
Storage
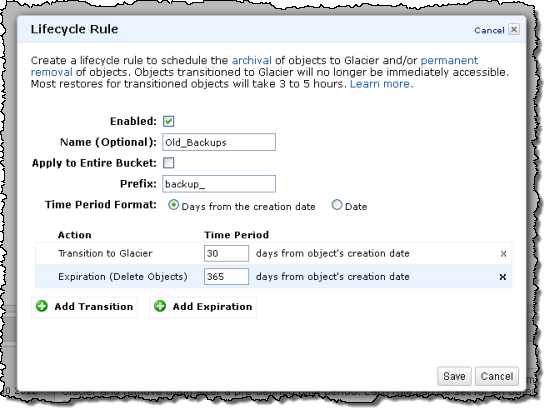
First, you need to tell S3 which objects are to be archived to the new Glacier storage option, and under what conditions. You do this by setting up a lifecycle rule using the following elements:
- A prefix to specify which objects in the bucket are subject to the policy.
- A relative or absolute time specifier and a time period for transitioning objects to Glacier. The time periods are interpreted with respect to the object’s creation date. They can be relative (migrate items that are older than a certain number of days) or absolute (migrate items on a specific date)
- An object age at which the object will be deleted from S3. This is measured from the original PUT of the object into the service, and the clock is not reset by a transition to Glacier.
You can create a lifecycle rule in the AWS Management Console:
Archiving
Every day, S3 will evaluate the lifecycle policies for each of your buckets and will archive objects in Glacier as appropriate. After the object has been successfully archived using the Glacier storage option, the object’s data will be removed from S3 but its index entry will remain as-is. The S3 storage class of an object that has been archived in Glacier will be set to GLACIER.
Listing
As with Amazon S3’s other storage options, all S3 objects that are stored using the Glacier option have an associated user-defined name. You can get a real-time list of all of your S3 object names, including those stored using the Glacier option, by using S3’s LIST API. If you list a bucket that contains objects that have been archived in Glacier, what will you see?
As I mentioned above, each S3 object has an associated storage class. There are three possible values:
- STANDARD – 99.999999999% durability. S3’s default storage option.
- RRS – 99.99% durability. S3’s Reduced Redundancy Storage option.
- GLACIER – 99.999999999% durability, object archived in Glacier option.
If you archive objects using the Glacier storage option, you must inspect the storage class of an object before you attempt to retrieve it. The customary GET request will work as expected if the object is stored in S3 Standard or Reduced Redundancy (RRS) storage. It will fail (with a 403 error) if the object is archived in Glacier. In this case, you must use the RESTORE operation (described below) to make your data available in S3.
Retrieval
You use S3’s new RESTORE operation to access an object archived in Glacier. As part of the request, you need to specify a retention period in days. Restoring an object will generally take 3 to 5 hours. Your restored object will remain in both Glacier and S3’s Reduced Redundancy Storage (RRS) for the duration of the retention period. At the end of the retention period the object’s data will be removed from S3; the object will remain in Glacier.
Although the objects are archived in Glacier, you can’t get to them via the Glacier APIs. Objects stored directly in Amazon Glacier using the Amazon Glacier API cannot be listed in real-time, and have a system-generated identifier rather than a user-defined name. Because Amazon S3 maintains the mapping between your user-defined object name and the Amazon Glacier system-defined identifier, Amazon S3 objects that are stored using the Amazon Glacier option are only accessible through the Amazon S3 API or the Amazon S3 Management Console.
Archiving in Action
We expect to see Amazon Glacier storage put to use in a variety of different ways. Toshiba’s Cloud & Solutions Division will be using it to store medical imaging. Tetsuro Muranaga, Chief Technology Executive of the division is very exciting about it. Here’s what he told us:
We currently provide a service enabling medical institutions to securely store patients medical images in Japan. We are excited about using Amazon Glacier through Amazon S3 to affordably and cost-effectively archive these images in large volumes for each of our customers. We will combine Toshibas cloud computing technology with Amazon Glaciers low costs and Amazon S3s lifecycle policies to provide a unique offering tailored to the needs of medical institutions. In addition, we expect we can build similarly tailored integrated solutions for our wide range of customers so that they can archive massive amounts of data in various business areas.
Pricing
You will pay standard Glacier pricing for data stored using S3’s new Glacier storage option.
Learn More
Learn how to archive your Amazon S3 data to Glacier by reading the Object Lifecycle Management topic in the Amazon S3 Developer Guide or check out the new Archiving Amazon S3 Data to Amazon Glacier video.