AWS News Blog
Amazon Bedrock adds reinforcement fine-tuning simplifying how developers build smarter, more accurate AI models

|
Organizations face a challenging trade-off when adapting AI models to their specific business needs: settle for generic models that produce average results, or tackle the complexity and expense of advanced model customization. Traditional approaches force a choice between poor performance with smaller models or the high costs of deploying larger model variants and managing complex infrastructure. Reinforcement fine-tuning is an advanced technique that trains models using feedback instead of massive labeled datasets, but implementing it typically requires specialized ML expertise, complicated infrastructure, and significant investment—with no guarantee of achieving the accuracy needed for specific use cases.
Today, we’re announcing reinforcement fine-tuning in Amazon Bedrock, a new model customization capability that creates smarter, more cost-effective models that learn from feedback and deliver higher-quality outputs for specific business needs. Reinforcement fine-tuning uses a feedback-driven approach where models improve iteratively based on reward signals, delivering 66% accuracy gains on average over base models.
Amazon Bedrock automates the reinforcement fine-tuning workflow, making this advanced model customization technique accessible to everyday developers without requiring deep machine learning (ML) expertise or large labeled datasets.
How reinforcement fine-tuning works
Reinforcement fine-tuning is built on top of reinforcement learning principles to address a common challenge: getting models to consistently produce outputs that align with business requirements and user preferences.
While traditional fine-tuning requires large, labeled datasets and expensive human annotation, reinforcement fine-tuning takes a different approach. Instead of learning from fixed examples, it uses reward functions to evaluate and judge which responses are considered good for particular business use cases. This teaches models to understand what makes a quality response without requiring massive amounts of pre-labeled training data, making advanced model customization in Amazon Bedrock more accessible and cost-effective.
Here are the benefits of using reinforcement fine-tuning in Amazon Bedrock:
- Ease of use – Amazon Bedrock automates much of the complexity, making reinforcement fine-tuning more accessible to developers building AI applications. Models can be trained using existing API logs in Amazon Bedrock or by uploading datasets as training data, eliminating the need for labeled datasets or infrastructure setup.
- Better model performance – Reinforcement fine-tuning improves model accuracy by 66% on average over base models, enabling optimization for price and performance by training smaller, faster, and more efficient model variants. This works with Amazon Nova 2 Lite model, improving quality and price performance for specific business needs, with support for additional models coming soon.
- Security – Data remains within the secure AWS environment throughout the entire customization process, mitigating security and compliance concerns.
The capability supports two complementary approaches to provide flexibility for optimizing models:
- Reinforcement Learning with Verifiable Rewards (RLVR) uses rule-based graders for objective tasks like code generation or math reasoning.
- Reinforcement Learning from AI Feedback (RLAIF) employs AI-based judges for subjective tasks like instruction following or content moderation.
Getting started with reinforcement fine-tuning in Amazon Bedrock
Let’s walk through creating a reinforcement fine-tuning job.
First, I access the Amazon Bedrock console. Then, I navigate to the Custom models page. I choose Create and then choose Reinforcement fine-tuning job.
I start by entering the name of this customization job and then select my base model. At launch, reinforcement fine-tuning supports Amazon Nova 2 Lite, with support for additional models coming soon.
Next, I need to provide training data. I can use my stored invocation logs directly, eliminating the need to upload separate datasets. I can also upload new JSONL files or select existing datasets from Amazon Simple Storage Service (Amazon S3). Reinforcement fine-tuning automatically validates my training dataset and supports the OpenAI Chat Completions data format. If I provide invocation logs in the Amazon Bedrock invoke or converse format, Amazon Bedrock automatically converts them to the Chat Completions format.
The reward function setup is where I define what constitutes a good response. I have two options here. For objective tasks, I can select Custom code and write custom Python code that gets executed through AWS Lambda functions. For more subjective evaluations, I can select Model as judge to use foundation models (FMs) as judges by providing evaluation instructions.
Here, I select Custom code, and I create a new Lambda function or use an existing one as a reward function. I can start with one of the provided templates and customize it for my specific needs.
I can optionally modify default hyperparameters like learning rate, batch size, and epochs.

For enhanced security, I can configure virtual private cloud (VPC) settings and AWS Key Management Service (AWS KMS) encryption to meet my organization’s compliance requirements. Then, I choose Create to start the model customization job.
During the training process, I can monitor real-time metrics to understand how the model is learning. The training metrics dashboard shows key performance indicators including reward scores, loss curves, and accuracy improvements over time. These metrics help me understand whether the model is converging properly and if the reward function is effectively guiding the learning process.

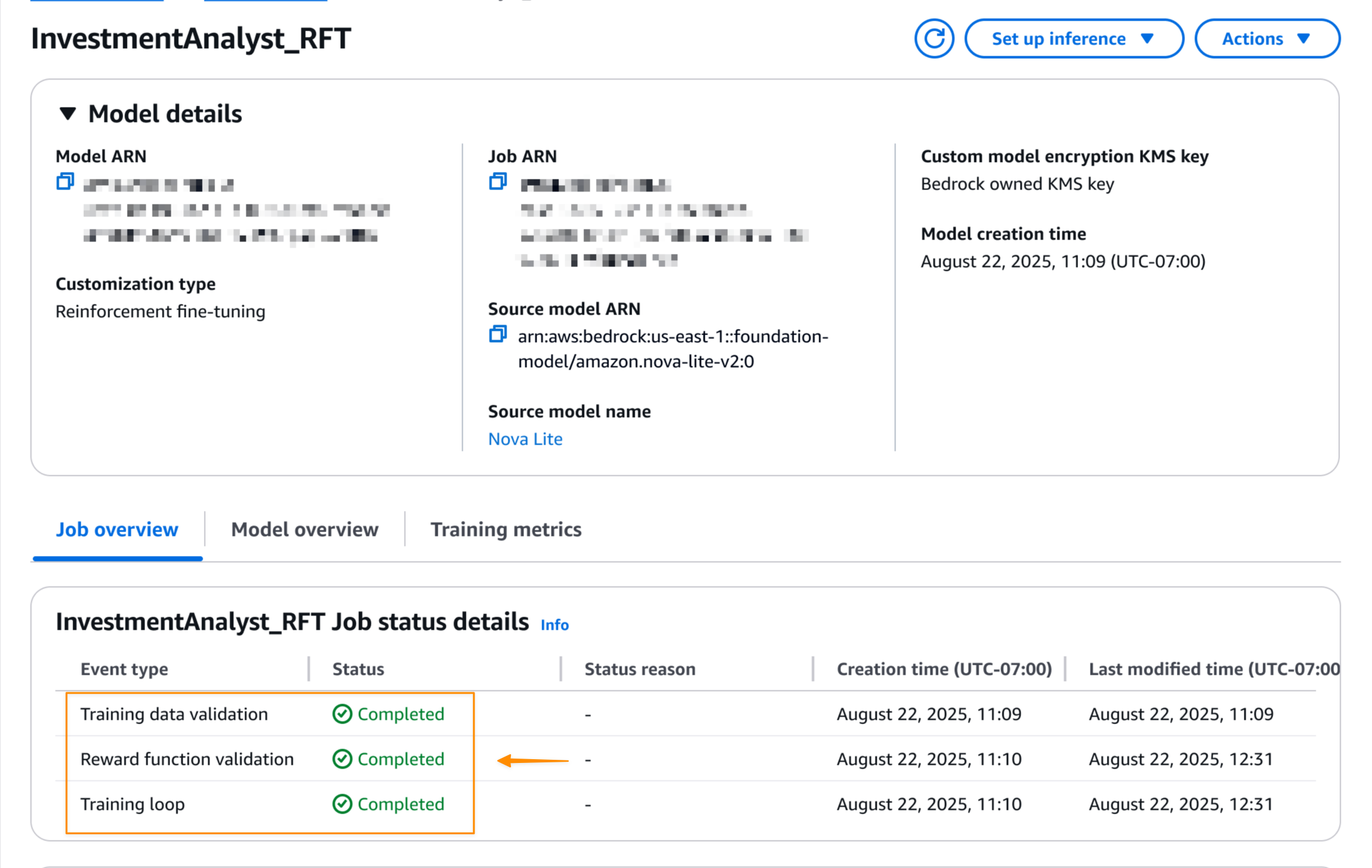
When the reinforcement fine-tuning job is completed, I can see the final job status on the Model details page.
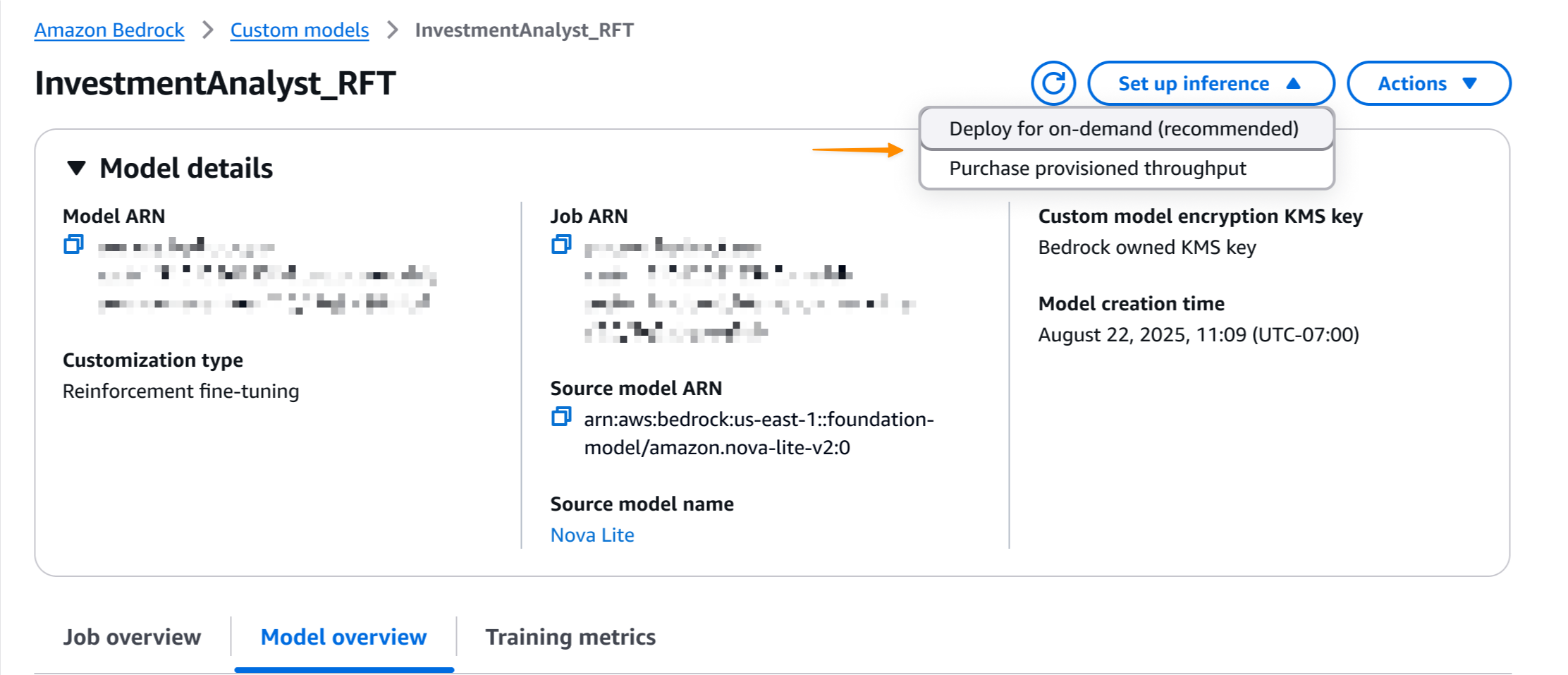
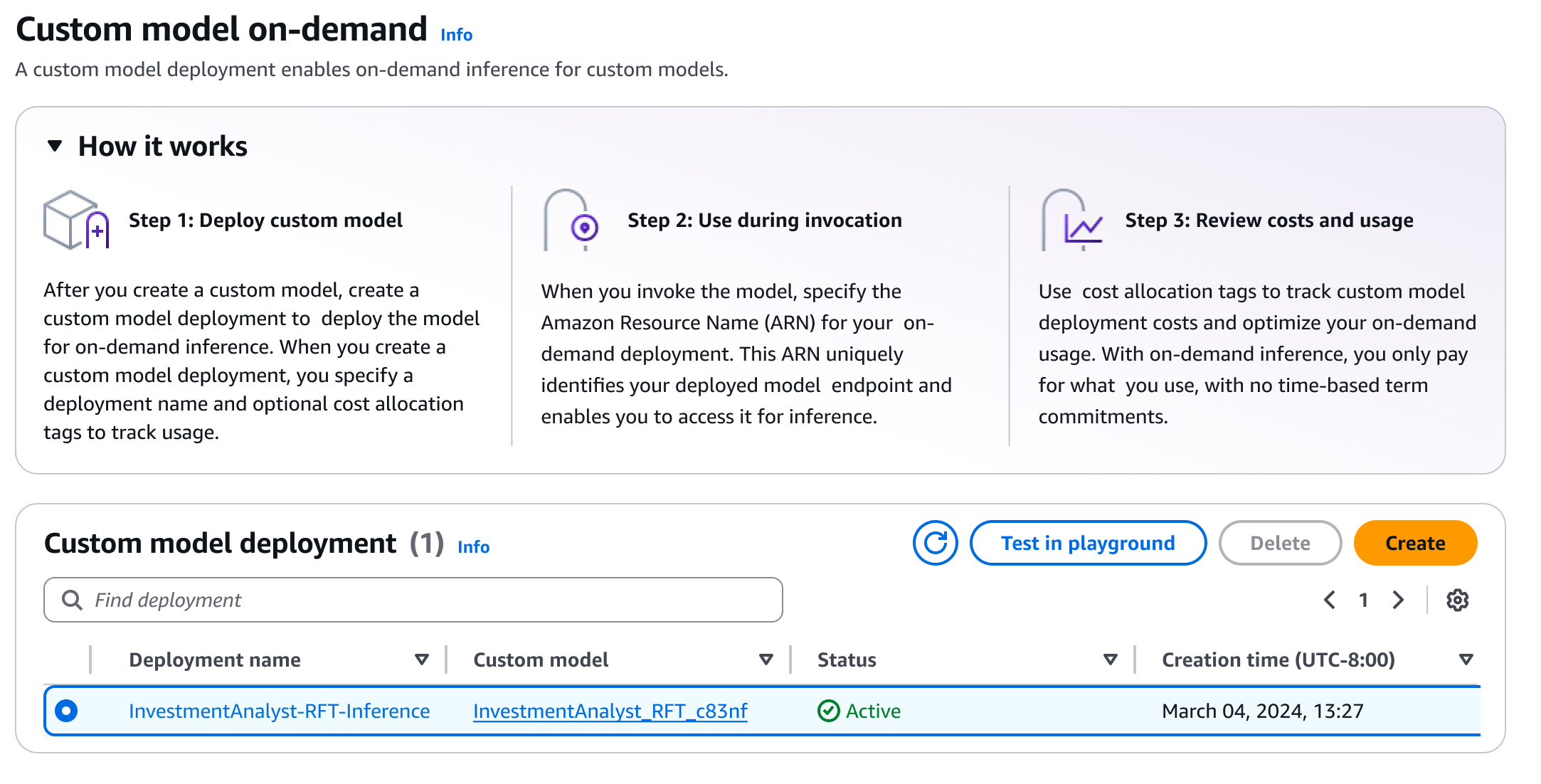
Once the job is completed, I can deploy the model with a single click. I select Set up inference, then choose Deploy for on-demand.
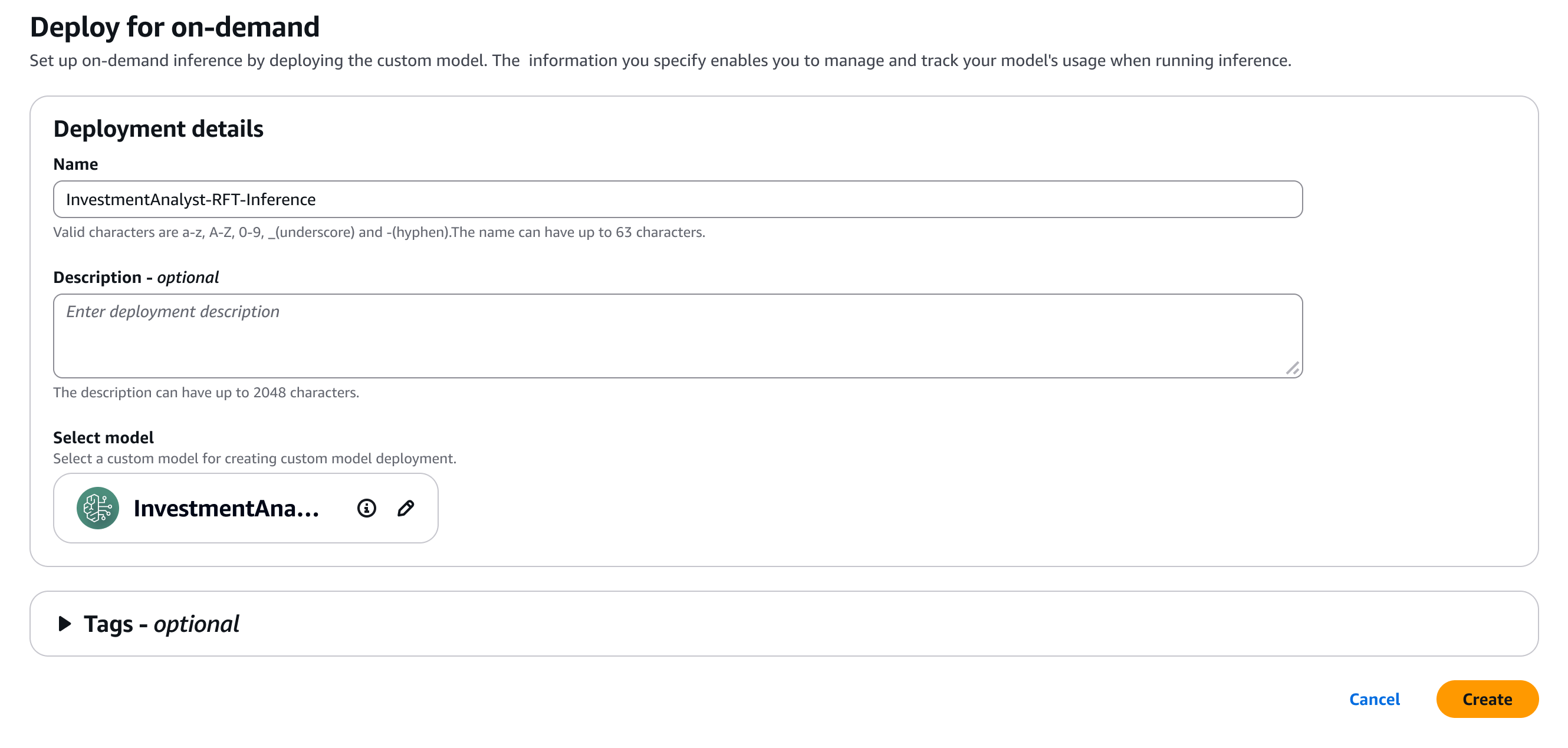
Here, I provide a few details for my model.
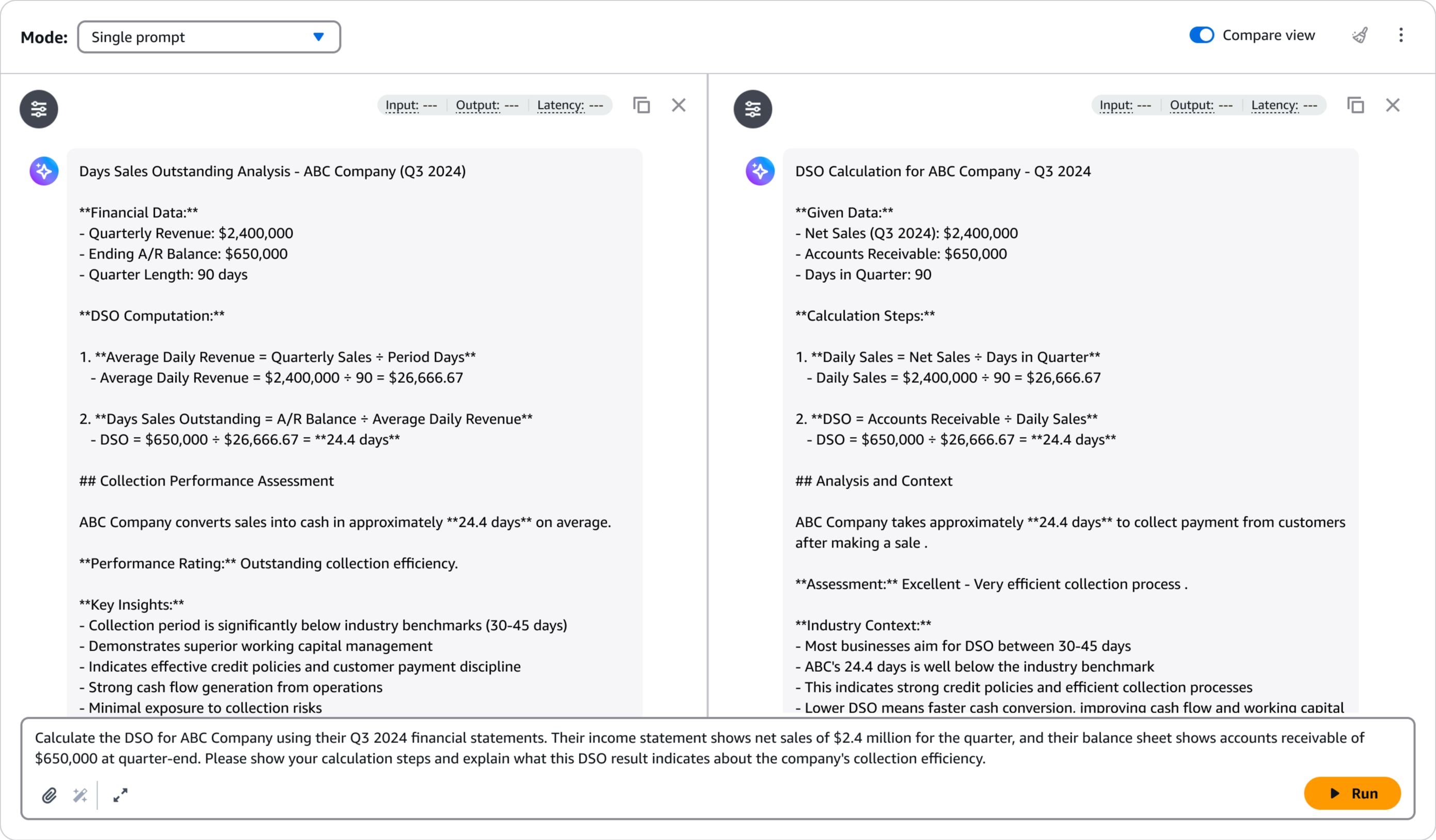
After deployment, I can quickly evaluate the model’s performance using the Amazon Bedrock playground. This helps me to test the fine-tuned model with sample prompts and compare its responses against the base model to validate the improvements. I select Test in playground.
The playground provides an intuitive interface for rapid testing and iteration, helping me confirm that the model meets my quality requirements before integrating it into production applications.
Interactive demo
Learn more by navigating an interactive demo of Amazon Bedrock reinforcement fine-tuning in action.

Additional things to know
Here are key points to note:
- Templates — There are seven ready-to-use reward function templates covering common use cases for both objective and subjective tasks.
- Pricing — To learn more about pricing, refer to the Amazon Bedrock pricing page.
- Security — Training data and custom models remain private and aren’t used to improve FMs for public use. It supports VPC and AWS KMS encryption for enhanced security.
Get started with reinforcement fine-tuning by visiting the reinforcement fine-tuning documentation and by accessing the Amazon Bedrock console.
Happy building!
— Donnie