AWS News Blog
New AWS Public Data Sets – Anthrokids, Twilio/Wigle.net, Sparse Matrices, USA Spending, Tiger
We’ve added some important new community features to our Public Data Sets and we’ve also added some new and intriguing data to our collection. I’m writing this post to bring you up to date on this unique AWS feature and thought I would also show you how to instantiate and use an actual public data set.
 If the concept is new to you, allow me to give you a brief introduction. We have set up a centralized repository for large (tens or hundreds of gigabytes) public data sets, which we host at no charge. We currently have public data sets in a number of categories including Biology, Chemistry, Economics, Encyclopedic, Geographic, and Mathematics. The data sets are stored in the form of EBS (Elastic Block Storage) snapshots. These snapshots are used to create an EBS volume from scratch in a matter of seconds. Most data sets are available in formats suitable for use with both Linux and Windows. Once created, the volume is then mounted on an EC2 instance for processing. Once the processing is complete, the volume can be kept alive for further work, archived to S3 or simple deleted.
If the concept is new to you, allow me to give you a brief introduction. We have set up a centralized repository for large (tens or hundreds of gigabytes) public data sets, which we host at no charge. We currently have public data sets in a number of categories including Biology, Chemistry, Economics, Encyclopedic, Geographic, and Mathematics. The data sets are stored in the form of EBS (Elastic Block Storage) snapshots. These snapshots are used to create an EBS volume from scratch in a matter of seconds. Most data sets are available in formats suitable for use with both Linux and Windows. Once created, the volume is then mounted on an EC2 instance for processing. Once the processing is complete, the volume can be kept alive for further work, archived to S3 or simple deleted.
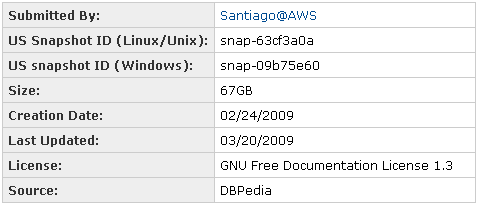 To make sure that you can get a lot of value from our Public Data Sets, we’ve added some new community features. Each set now has its own page within the AWS Resource Center. The page contains all of the information needed to start making use of the data, including submission information, creation date, update date, data source, and more. There’s a dedicated discussion forum for each data set, and even (in classic Amazon style) room to enter a review and a rating.
To make sure that you can get a lot of value from our Public Data Sets, we’ve added some new community features. Each set now has its own page within the AWS Resource Center. The page contains all of the information needed to start making use of the data, including submission information, creation date, update date, data source, and more. There’s a dedicated discussion forum for each data set, and even (in classic Amazon style) room to enter a review and a rating.
 We’ve also added a number of rich and intriguing data sets to our collection. Here’s what’s new:
We’ve also added a number of rich and intriguing data sets to our collection. Here’s what’s new:
- The Anthrokids data set includes the results of a pair of 1975 and 1977 studies which collected anthropomorphic data on children. This data can be used to help safety-conscious product designers build better products for children.
- The Twilio / Wigle.net Street Vector data set provides a complete database of US street names and address ranges mapped to Zip Codes and latitude/longitude ranges, with DTMF key mappings for all street names. This data can be used to validate and normalize street addresses, find a list of street addresses in a zip code, locate the latitude and longitude of an address, and so forth. This data is made available as a set of MySQL data files.
- The University of Florida Sparse Matrix Collection contains a large and ever-growing set of sparse matrices which arise in real-world problems in structural engineering, computational fluid dynamics, electromagnetics, acoustics, robotics, chemistry, and much more. The largest matrix in the collection has a dimension of almost 29 million, with over 760 million nonzero entries. Graphic representations of some of this data are shown at right, in images produced by Yifan Hu of AT&T Labs. The data is available in MATLAB, Rutherford-Boeing, and Matrix Market formats.
- The USASpending.gov data set contains a dump of all federal contracts from the Federal Procurement Data Center. This data summarizes who bought what, from whom, and where. The data was extracted by full360.com and is available in Apache CouchDB format.
- The 2008 Tiger/Line Shapefiles data set is a complete set of shapefiles for American states, counties, districts, places, and areas, along with associated metadata. This data is a product of the US Census Bureau.
We’ll continue to add additional public data sets to our collection over the coming months. Please feel free to submit your own data sets for consideration, or to propose inclusion of data sets owned by others.
It is really easy to instantiate an instance of a public data set. I wanted to process the 2003-2006 US Economic Data. Here’s what I need to do:
- Launch a fresh EC2 instance and note its availability one.
- Visit the home page for the data set and note the Snapshot ID (snap-0bdf3f62 for Linux in the US) and the Size (220 GB).
- Create a new EBS volume using the parameters from the first two steps. I’ll use the AWS Management Console:
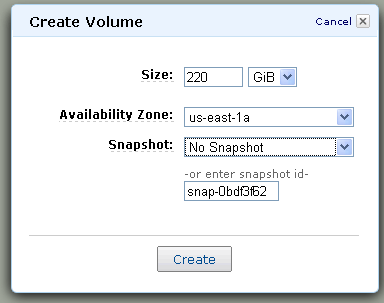
I hit the “Create” button, waited two seconds, and then hit “Refresh.” The volume status changed from “creating” to “available” so I knew that my data was ready.
- Attach the volume to my EC2 instance, again using the console:
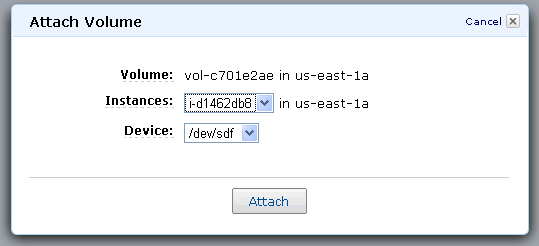
- Create a mount point and then mount the volume on my instance. This has to be done from the Linux command line:
- Now I have access to the data, and can do anything I want with it. Here’s a snippet of a directory listing:
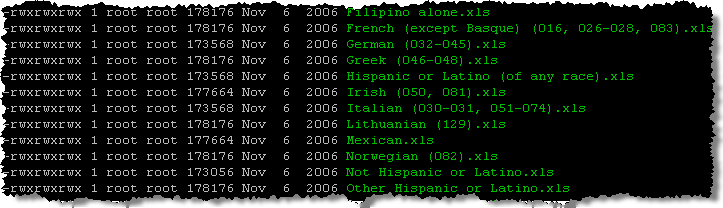
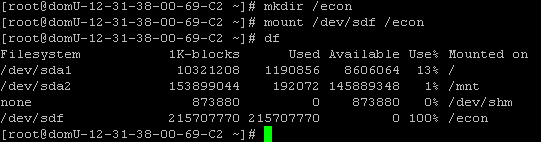
Once I am done I can simply unmount the volume, shut down the instance, and delete the volume. No fuss, no muss, and a total cost of 11 cents (10 cents for an hour of EC2 time and a penny or so for the actual EBS volume).
–Jeff;