AWS News Blog
New AWS Public Data Sets – Economics, DBpedia, Freebase, and Wikipedia

|
We have just released four additional AWS public data sets, and have updated another one.
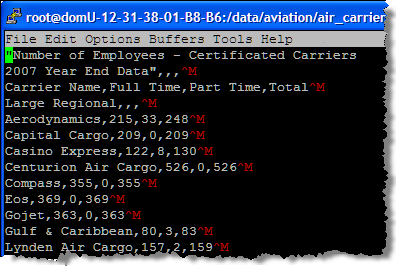 In the Economics category, we have added a set of transportation databases from the US Bureau of Transportation Statistics. Data and statistics are provided for aviation, maritime, highway, transit, rail, pipeline, bike & pedestrian, and other modes of transportation, all in CSV format. I was able to locate employment data for our hometown airline and found out that they employed 9,322 full-time and 1,122 part-time employees as of the end of 2007.
In the Economics category, we have added a set of transportation databases from the US Bureau of Transportation Statistics. Data and statistics are provided for aviation, maritime, highway, transit, rail, pipeline, bike & pedestrian, and other modes of transportation, all in CSV format. I was able to locate employment data for our hometown airline and found out that they employed 9,322 full-time and 1,122 part-time employees as of the end of 2007.
In the Encyclopedic category, we have added access to the DBpedia Knowledge Base, the Freebase Data Dump, and the Wikipedia Extraction, or WEX.
The DBpedia Knowledge Base currently describes more than 2.6 million things including 213,000 people, 328,000 places, 57,000 music albums, 36,000 films, and 20,000 companies. There are 274 million RDF triples in the 67 GB data set.
The 66 GB Freebase Data Dump is an open database of the world’s information, covering millions of topics in hundreds of categories.
The Wikipedia Extraction (WEX) is a processed, machine-readable dump of the English-language section of the Wikipedia. At nearly 67 GB, this is a handly and formidable data set. The data is provided is the TSV format as exported by PostgreSQL.
 Finally, we have updated the NCBI’s Genbank data. Weighing in at a hefty quarter of a petabyte terabyte, this public data set contains information on over 85 billion bases and 82 million sequence records.
Finally, we have updated the NCBI’s Genbank data. Weighing in at a hefty quarter of a petabyte terabyte, this public data set contains information on over 85 billion bases and 82 million sequence records.
Instantiating these data sets is basically trivial. You create a new EBS volume of the appropriate size, basing it on the snapshot id of the data. Next, you attach the volume to a running EC2 instance in the same availability zone. Finally, you create a mount point and mount the EBS volume on the instance. The last step can take a minute or two for a large volume; the other steps are essentially instantaneous. Instead of spending days or weeks downloading these data sets you can be up and running from a standing start in minutes. Once again, cloud computing reduces the friction between “I have a good idea” and “here’s the realization of my idea.” You don’t need loads of bandwidth, processing power, or local disk space in order to do interesting and significant work with these world-scale data sets.
— Jeff;