AWS News Blog
New Hands-On Course for Business Analysts – Practical Decision Making using No-Code ML on AWS

|
Artificial intelligence (AI) is all around us. AI sends certain emails to our spam folders. It powers autocorrect, which helps us fix typos when we text. And now we can use it to solve business problems.
In business, data-driven insights have become increasingly valuable. These insights are often discovered with the help of machine learning (ML), a subset of AI and the foundation of complex AI systems. And ML technology has come a long way. Today, you don’t need to be a data scientist or computer engineer to gain insights. With the help of no-code ML tools such as Amazon SageMaker Canvas, you can now achieve effective business outcomes using ML without writing a single line of code. You can better understand patterns, trends, and what’s likely to happen in the future. And that means making better business decisions!
Today, I’m happy to announce that AWS and Coursera are launching the new hands-on course Practical Decision Making using No-Code ML on AWS. This five-hour course is designed to demystify AI/ML and give anyone with a spreadsheet the ability to solve real-life business problems.

Course Highlights
Over the course of three lessons, you will learn how to address your business problem using ML, how to build and understand an ML model without any code, and how to use ML to extract value to make better decisions. Each lesson walks you through real-life business scenarios and hands-on exercises using Amazon SageMaker Canvas, a visual, no-code ML tool.
Lesson 1 – How To Address Your Business Problem Using ML
In the first lesson, you will learn how to address your business problem using ML without knowing data science. You will be able to describe the four stages of analytics and discuss the high-level concepts of AI/ML.
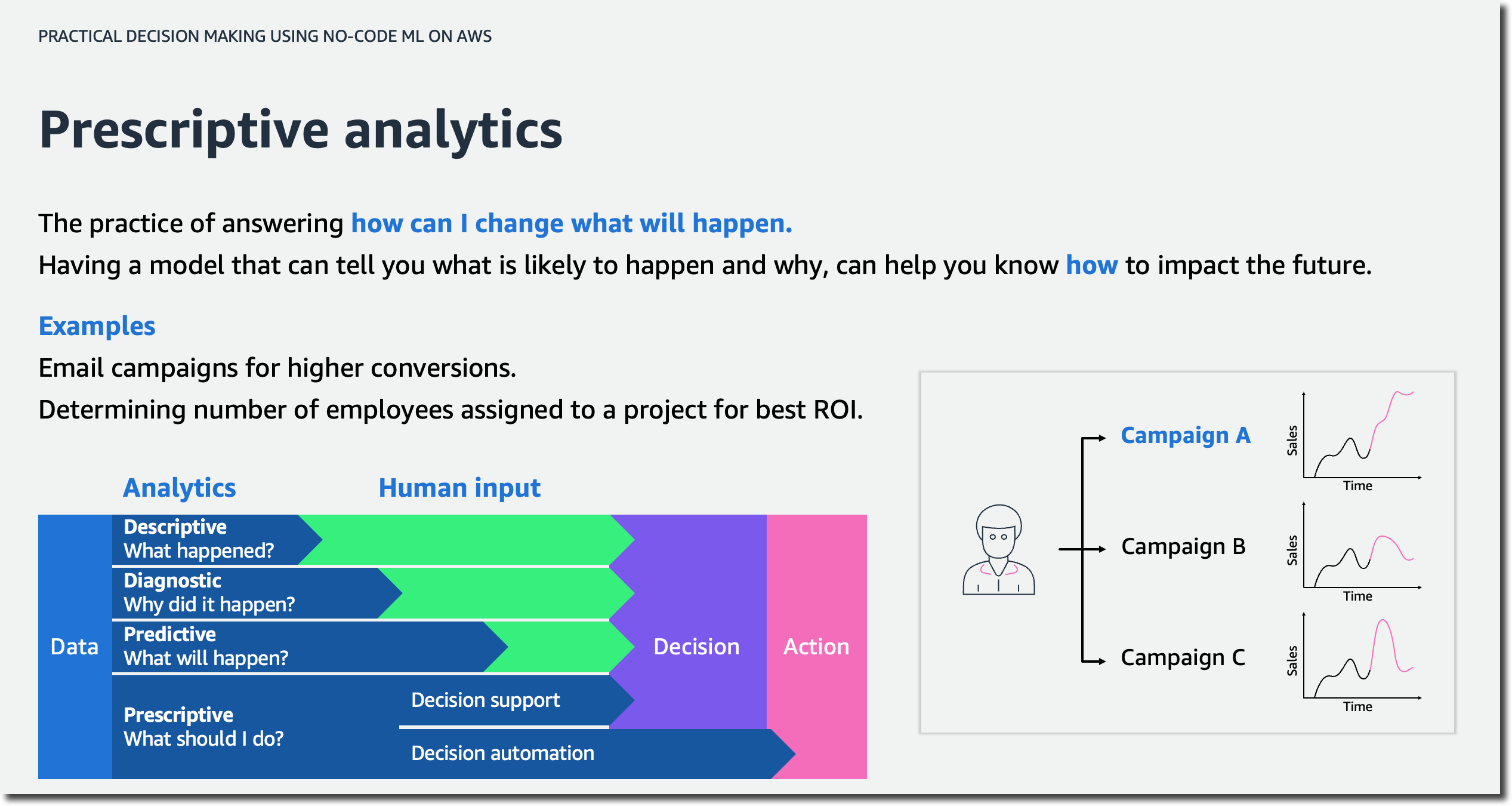
This lesson will also introduce you to automated machine learning (AutoML) and how AutoML can help you generate insights based on common business use cases. You will then practice forming business questions around the most common machine learning problem types.
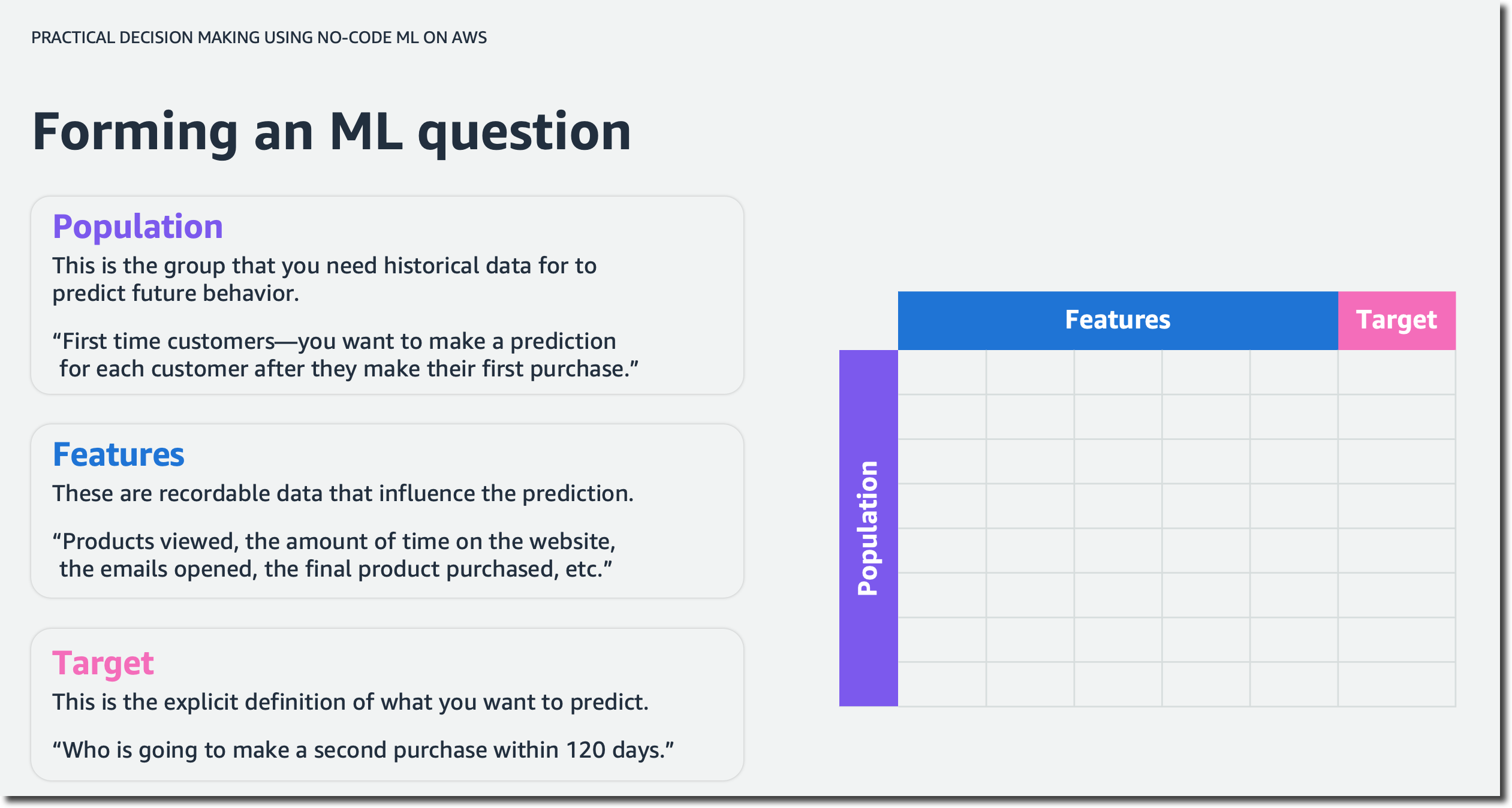
For example, imagine you are a business analyst at a ticketing company. You manage ticket sales for large venues—concerts, sporting events, and so on. Let’s assume you want to predict cash flow. A question to solve with ML could be: “How can you better forecast ticket sales?” This is an example of time series forecasting. You will also explore numeric and category ML problems throughout the course. They will help you answer business questions such as “What’s the likely annual revenue for a customer?” and “Will this customer buy another ticket in the next three months?”.
Next, you will learn about the iterative process of asking questions for machine learning to make the questions more explicit and explore how to pick the highest value problems to work on.

The first lesson wraps up with a deep dive on how time influences your data across forecasting and nonforecasting business problems and how to set up your data for each ML problem type.
Lesson 2 – Build and Understand an ML Model Without Any Code
In the second lesson, you learn how to build and understand an ML model without any code using Amazon SageMaker Canvas. You will focus on a customer churn example with synthetically generated data from a cellular services company. The problem question is, “Which customers are most likely to cancel their service next month?”
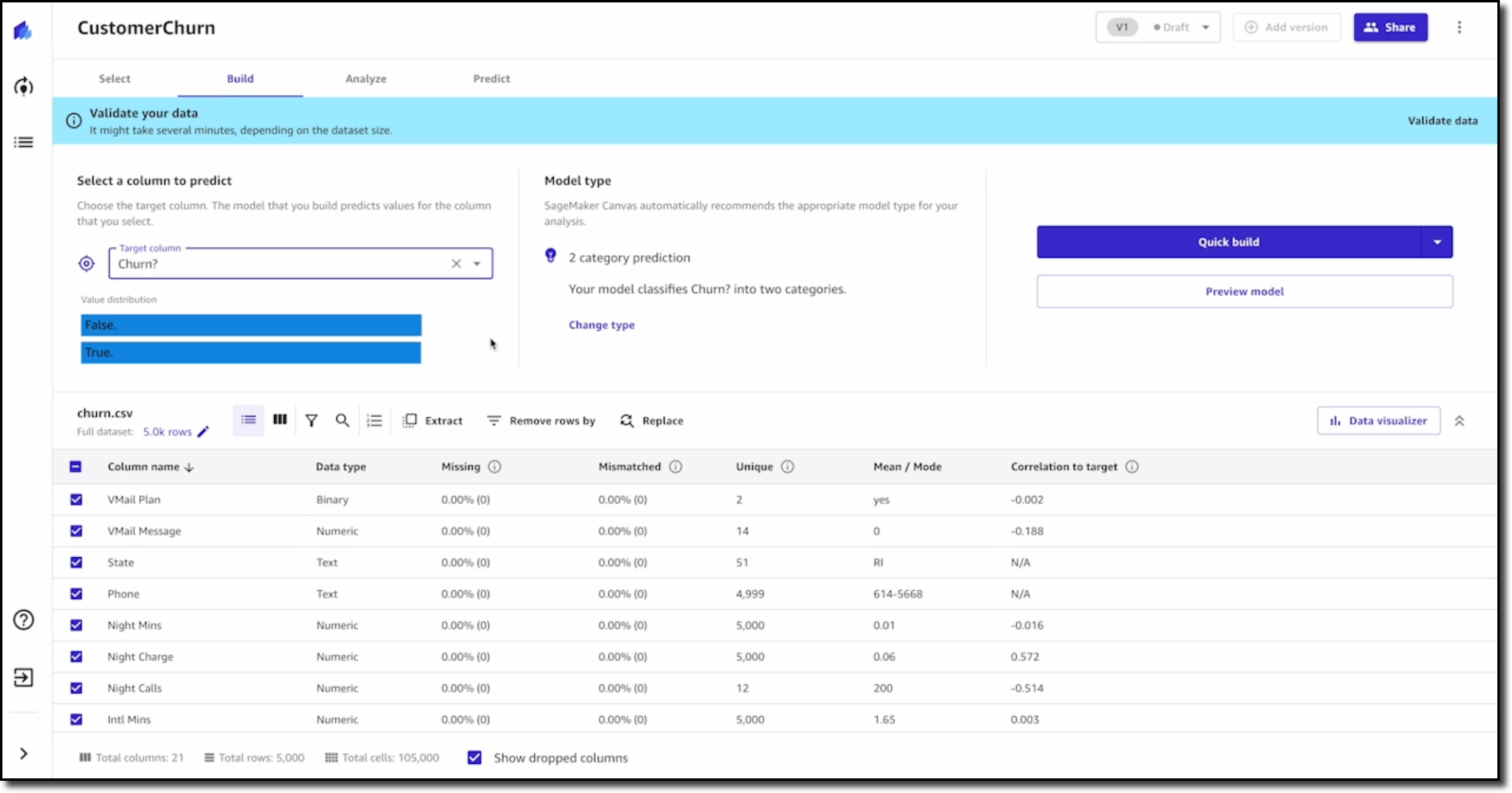
You will learn how to import data and start exploring it. This lesson will explain how to select the right configuration, pick the target column, and show you how to prepare your data for ML.
SageMaker Canvas also recently introduced new visualizations for exploratory data analysis (EDA), including scatter plots, bar charts, and box plots. These visualizations help you analyze the relationships between features in your data sets and comprehend your data better.
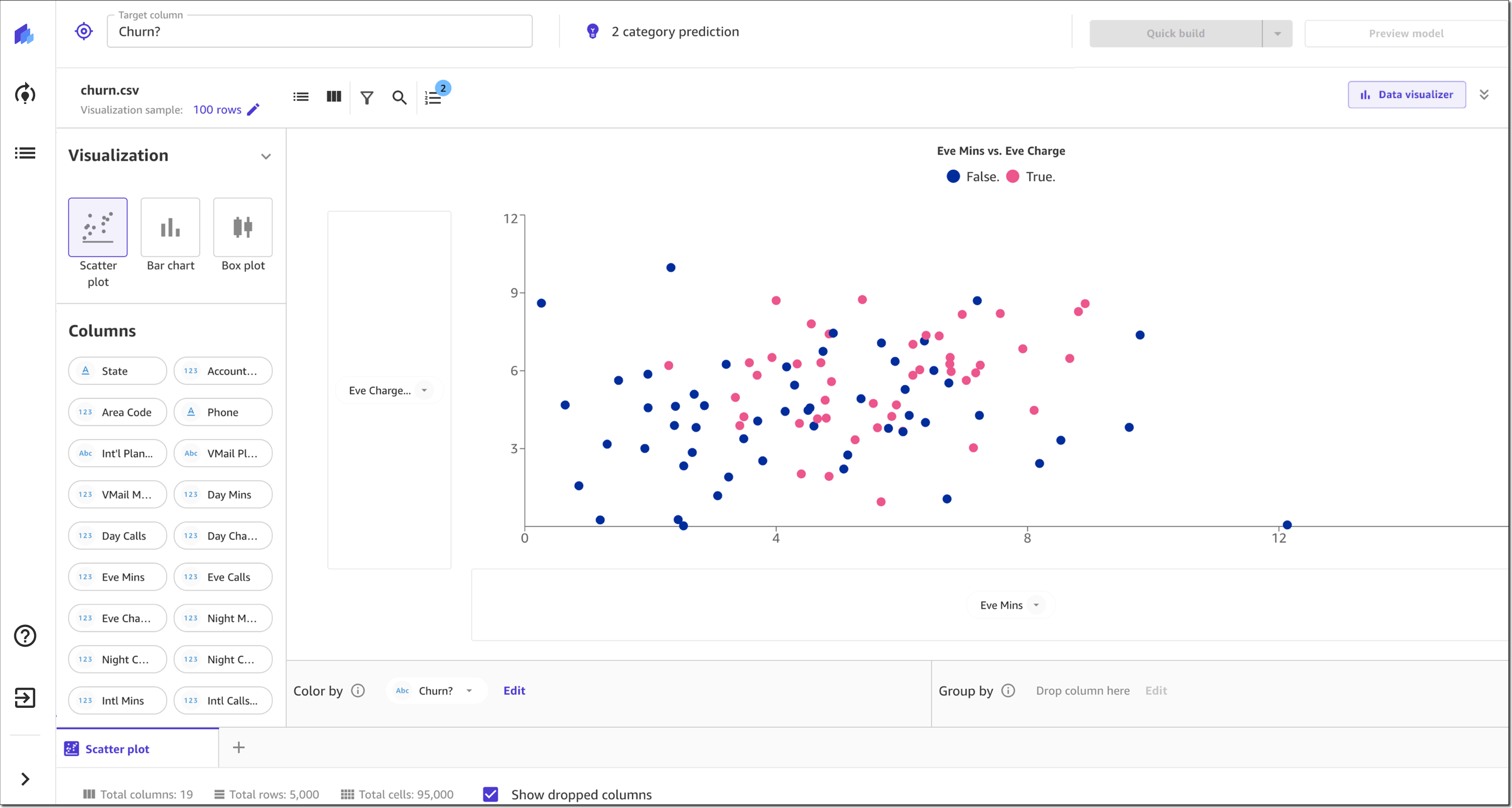
After a final data validation, you can preview the model. This shows you right away how accurate the model might be and, on average, which features or columns have the greatest relative impact on model predictions. Once you are done preparing and validating the data, you can go ahead and build the model.
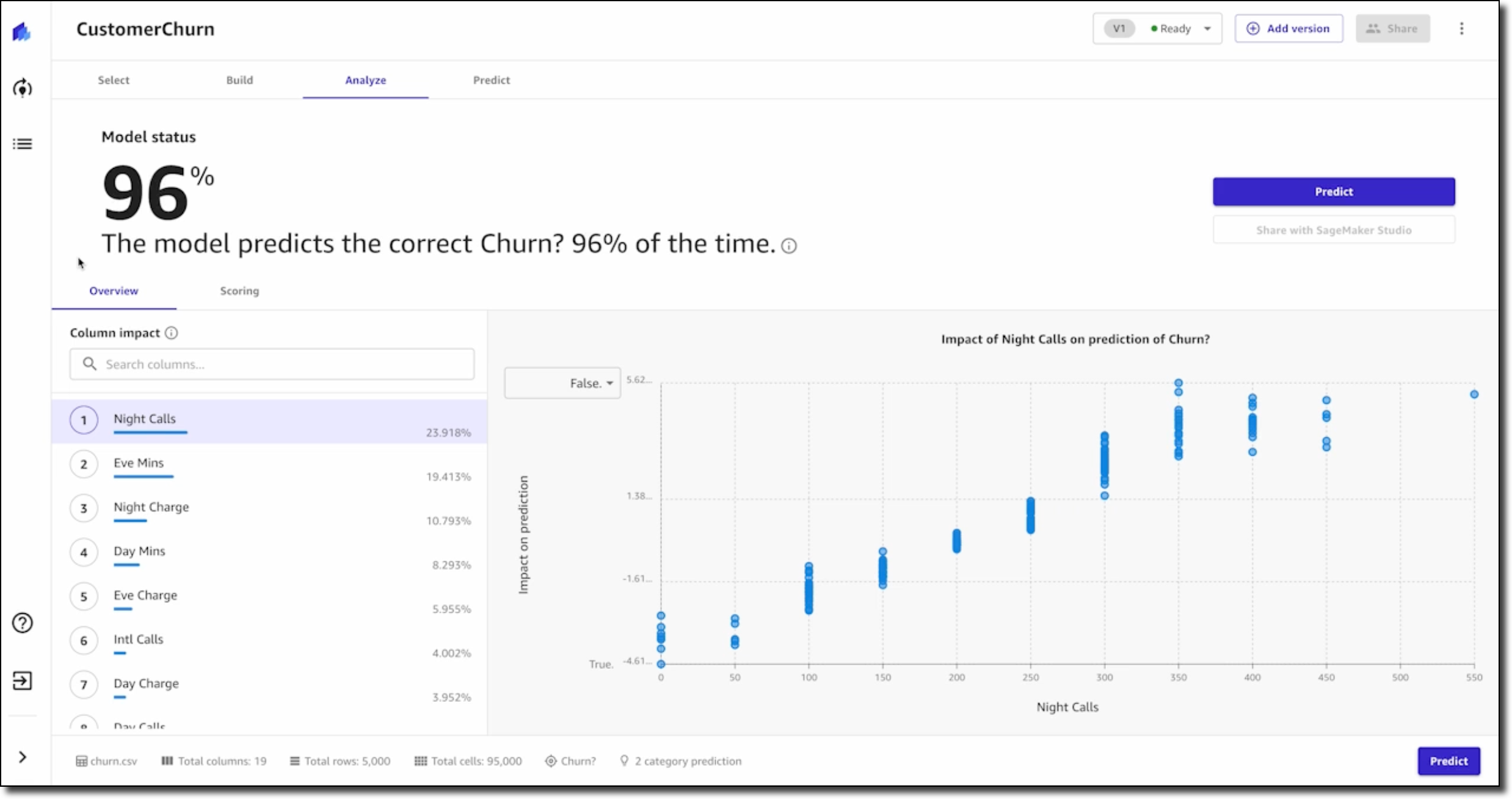
Next, you will learn how to evaluate the performance of the model. You will be able to describe the difference between training data and test data splits and how they are used to derive the model’s accuracy score. The lesson also discusses additional performance metrics and how you can apply domain knowledge to decide if the model is performing well. Once you understand how to evaluate the performance metrics, you have the foundation for making better business decisions.
The second lesson wraps up with some common gotchas to watch out for and shows how to iterate on the model to keep improving performance. You will be able to describe the concept of data leakage as a result of memorization versus generalization and additional model flaws to avoid. You will also learn how to iterate on questions, included features, and sample sizes to keep increasing model performance.
Lesson 3 – Extract Value From ML
In the third lesson, you learn how to extract value from ML to make better decisions. You will be able to generate and read predictions, including predictions on a single row of a spreadsheet, called a single prediction, and predictions on the entire spreadsheet, called batch prediction. You will be able to understand what is impacting predictions and play with different scenarios.
Next, you will learn how to share insights and predictions with others. You will learn how to take visuals from the product, such as feature importance charts or scoring diagrams, and share the insights through presentations or business reports.
The third lesson wraps up with how to collaborate with the data science team or a team member with machine learning expertise. When you build your model using SageMaker Canvas, you can choose either a Quick build or a Standard build. The Quick build usually takes 2–15 minutes and limits the input dataset to a maximum of 50,000 rows. The Standard build usually takes 2–4 hours and generally has a higher accuracy. SageMaker Canvas makes it easy to share a standard build model. In the process, you can reveal the model’s behind-the-scenes complexity down to the code level.
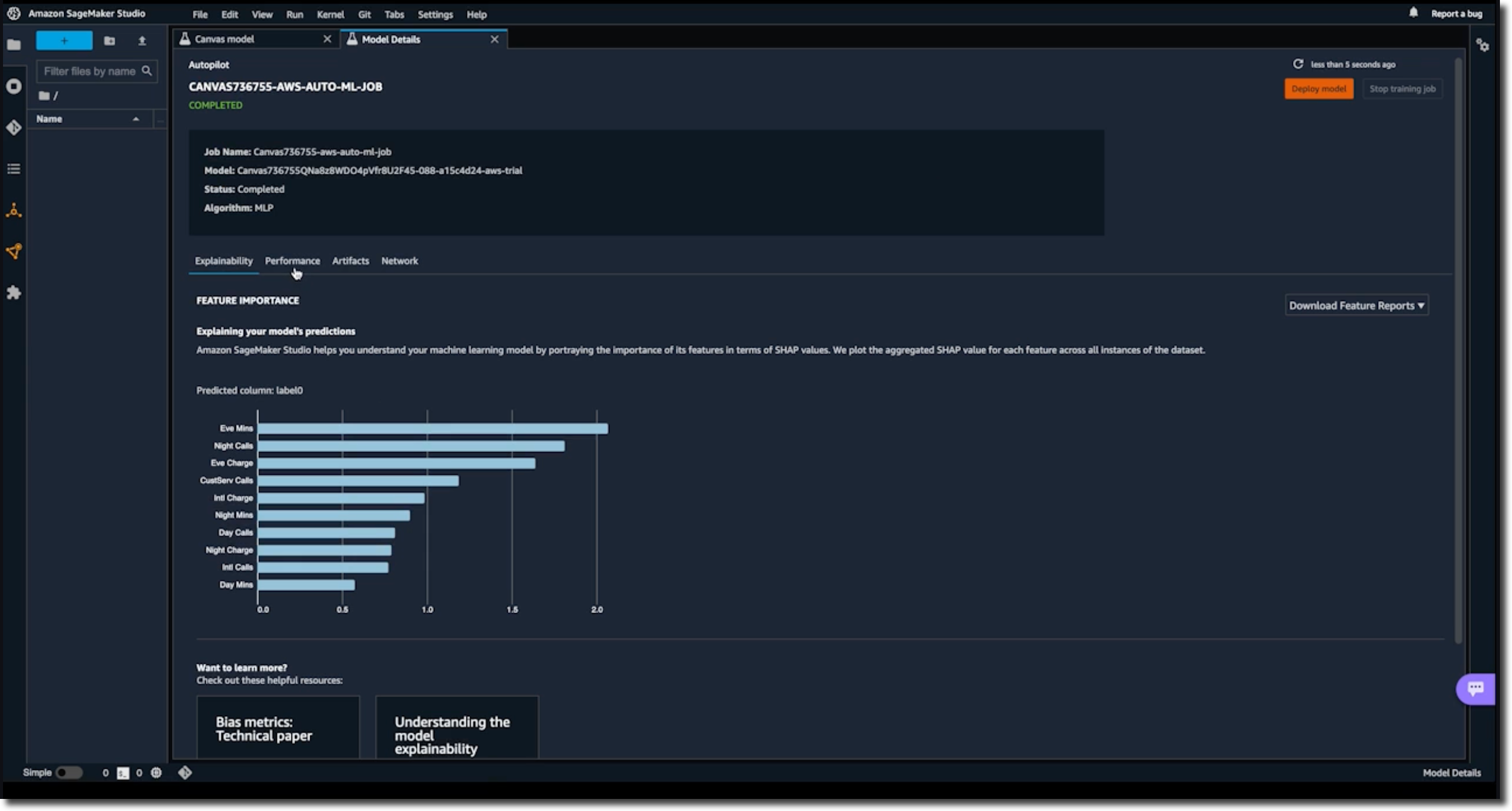
Once you have the trained model open, you can click on the Share button. This creates a link that can be opened in SageMaker Studio, an integrated development environment used by data science teams.

In SageMaker Studio, you can see the transformations to the input data set and detailed information about scoring and artifacts, like the model object. You can also see the Python notebooks for data exploration and feature engineering.
Hands-On Exercises
This course includes seven hands-on labs to put your learning into practice. You will have the opportunity to use no-code ML with SageMaker Canvas to solve real-world challenges based on publicly available datasets.
The labs focus on different business problems across industries, including retail, financial services, manufacturing, healthcare, and life sciences, as well as transport and logistics.
You will have the opportunity to work on customer churn predictions, housing price predictions, sales forecasting, loan predictions, diabetic patient readmission prediction, machine failure predictions, and supply chain delivery on-time predictions.
Register Today
Practical Decision Making using No-Code ML on AWS is a five-hour course for business analysts and anyone who wants to learn how to solve real-life business problems using no-code ML.
Sign up for Practical Decision Making using No-Code ML on AWS today at Coursera!
— Antje