AWS News Blog
Run SUSE Linux Enterprise Server on Cluster Compute Instances

|
You can now run SUSE Linux Enterprise Server on EC2’s Cluster Compute and Cluster GPU instances. As I noted in the post that I wrote last year when this distribution became available on the other instance types, SUSE Linux Enterprise Server is a proven, commercially supported Linux platform that is ideal for development, test, and production workloads. This is the same operating system that runs the IBM Watson DeepQA application that competed against a human opponent (and won) on Jeopardy just last month.
After reading Tony Pearson’s article (How to Build Your Own Watson Jr. In Your Basement), I set out to see how his setup could be replicated on an hourly, pay as you go basis using AWS. Here’s what I came up with:
- Buy the Hardware. With AWS there’s nothing to buy. Simply choose from among the various EC2 instance types. A couple of Cluster Compute Quadruple Extra Large instances should do the trick:
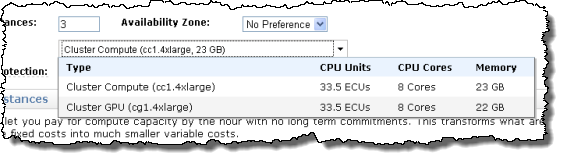
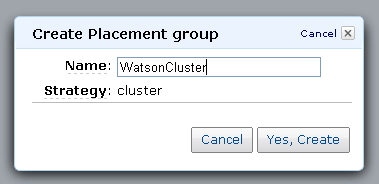
- Establish Networking. Tony recommends 1 Gigabit Ethernet. Create an EC2 Placement Group, and launch the Cluster Compute instances within it to enjoy 10 Gigabit non-blocking connectivity between the instances:
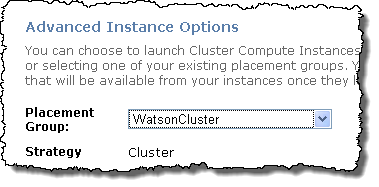
- Install Linux and Middleware. The article recommends SUSE Linux Enterprise Server. You can run it on a Cluster Compute instance by selecting it from the Launch Instances Wizard:

Launch the instances within the placement group in order to get the 10 Gigabit non-blocking connectivity:
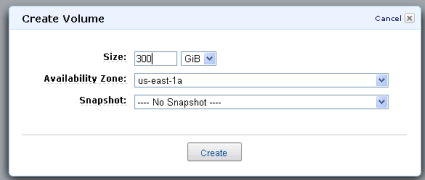
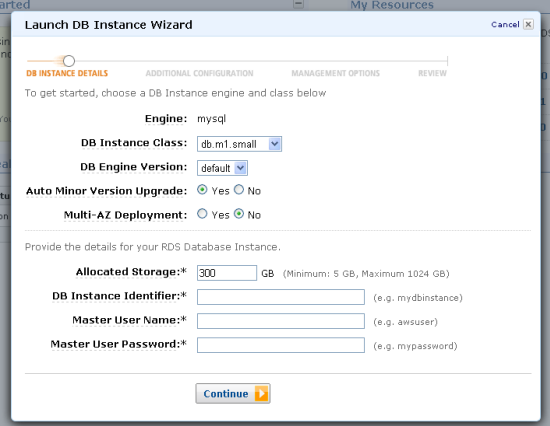
You can use the local storage on the instance, or you can create a 300 GB Elastic Block Store volume for the reference data:
- Download Information Sources. Tony recommends the use of NFS to share files within the cluster. That will work just fine on EC2; see the Linux-NFS-HOWTO for more information. He also notes that you will need a relational database. You can use Apache Derby per his recommendation, or you can start up an Amazon RDS instance so that you don’t have to worry about backups, scaling or other administrative chores (if you do this you might not need the 300 GB EBS volume created in the previous step):
You’ll need some information sources. Check out the AWS Public Data Sets to get started.
- The Query Panel – Parsing the Question. You can download and install OpenNLP and OpenCyc as described in the article. You can run most applications (open source and commercial) on an EC2 instance without making any changes.
- Unstructured Information Management Architecture. This part of the article is a bit hand-wavey. It basically boils down to “write a whole lot of code around the Apache UIMA framework.”
- Parallel Processing. The original Watson application ran in parallel across 2,880 cores. While this would be prohibitive for a basement setup, it is possible to get this much processing power from AWS in short order and (even more importantly) to put it to productive use. Tony recommends the use of the UIMA-AS package for asynchronous scale-out, all managed by Hadoop. Fortunately, Amazon Elastic MapReduce is based on Hadoop, so we are all set:
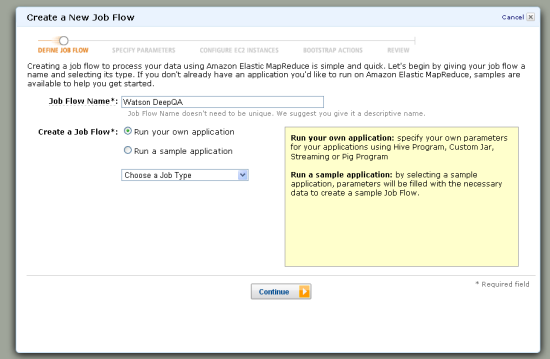
- Testing. Tony recommends a batch-based approach to testing, with questions stored in text files to allow for repetitive testing. Good enough, but you still need to evaluate all of the answers and decide if your tuning is taking you in the desired direction. I’d recommend that you use the Amazon Mechanical Turk instead. You could easily run A/B tests across multiple generations of results.
I really liked Tony’s article because it took something big and complicated and reduced it to a series of smaller and more approachable steps. I hope that you see from my notes above that you can easily create and manage the same types of infrastructure, run the same operating system, and the same applications using AWS, without the need to lift a screwdriver or to max out your credit cards. You could also use Amazon CloudFormation to automate the entire setup so that you could re-create it on demand or make copies for your friends.
Read more about features and pricing on our SUSE Linux Enterprise Server page.
— Jeff;