AWS Big Data Blog
Author: Ben Sowell
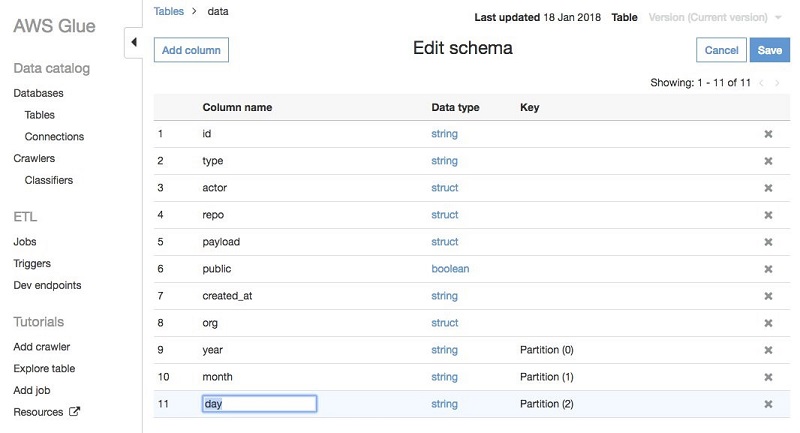
Work with partitioned data in AWS Glue
In this post, we show you how to efficiently process partitioned datasets using AWS Glue. First, we cover how to set up a crawler to automatically scan your partitioned dataset and create a table and partitions in the AWS Glue Data Catalog. Then, we introduce some features of the AWS Glue ETL library for working with partitioned data.