AWS Big Data Blog
Create larger SPICE datasets and refresh data faster in Amazon QuickSight with new SPICE features
Amazon QuickSight is a scalable business intelligence (BI) service built for the cloud, which allows insights to be shared with all users in the organization. QuickSight offers SPICE, an in-memory, cloud-native data store that allows end-users to interactively explore data. SPICE provides consistently fast query performance and automatically scales for high concurrency. With SPICE, you save time and cost because you don’t need to retrieve data from the data source (whether a database or data warehouse) every time you change an analysis or update a visual, and you remove the load of concurrent access or analytical complexity off the underlying data source with the data.
Today, we’re introducing incremental refresh in SPICE, with a refresh rate of 15 minutes (four times faster than before), which improves freshness of data in SPICE. In addition, we’re doubling SPICE limits on a per dataset basis to 500 million rows (twice that of our previous 250 million row limit). In this post, we walk through these new capabilities and how you can use them to create SPICE datasets that can help you scale your data to all your users.
What’s new with QuickSight SPICE?
We’ve added the following capabilities to QuickSight:
- Incremental refresh – QuickSight now supports incrementally loading new data to SPICE datasets without needing to refresh the full set of data. With incremental refresh, you can update SPICE datasets in a fraction of the time a full refresh would take, enabling access to the most recent insights much sooner. You can schedule incremental refresh to run up to every 15 minutes on a dataset on SQL-based data sources, such as Amazon Redshift, Amazon Athena, PostgreSQL, Microsoft SQL Server, or Snowflake.
- 500 million row SPICE capacity – The QuickSight SPICE engine now supports datasets up to 500 million rows or 500 GB in size. This change lets you use SPICE for datasets twice as large than before.
In the next sections, we show you how to get started with incremental refresh and 500 million row SPICE capacity.
Create large datasets
Let’s say you’re part of the central data team that has access to data tables in data sources. You want to create a central dataset for analysts. SPICE can now scale to double the capacity, so you can create a large scaled dataset rather than create and maintain several unconnected datasets. You can bring in up to 32 tables (from different data sources) in a single dataset to a total of 500 million rows. You can enjoy the double capacity of SPICE with no extra step—it’s automatically available. To create a dataset, simply choose New Dataset on the Data page. On the Data Prep page for the new dataset, choose Add data to add tables to a single dataset.
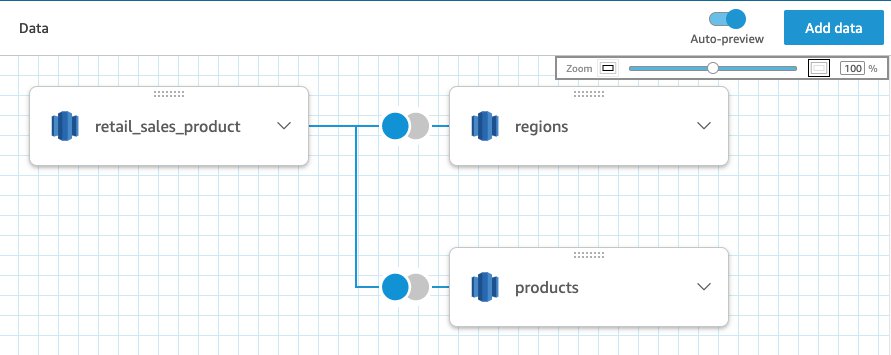
Set up incremental refresh
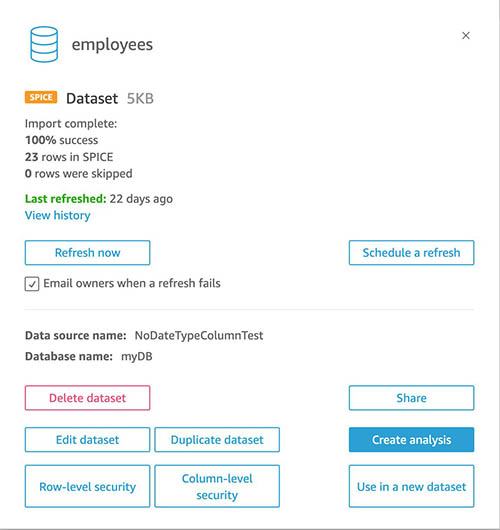
With incremental refresh, QuickSight now allows you to ingest data incrementally for your SQL-based sources (such as Amazon Redshift, Athena, PostgreSQL, or Snowflake) in a specified time period. On the Datasets page, choose the dataset, and choose Refresh now or Schedule a refresh.
For Refresh type, select Incremental refresh.
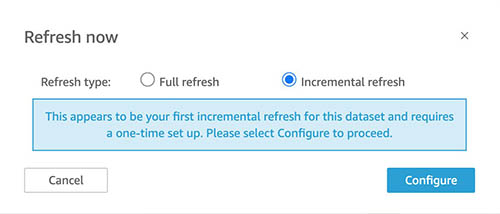
Configure look-back window
While setting up incremental refresh, you have to specify a look-back window (for example, 1 day, 1 week, 6 hours) in which new rows are found, and modified and deleted rows sync. This means that less data needs to be queried and transferred for each refresh, thereby increasing the speed at which ingestions can complete.
Let’s walk through an example to illustrate the concept. We have a dataset that contains 6 months’ worth of sales records: 180,000 records (1,000 records per day). Right now, the dataset contains data from January 1 to June 30, and today is July 1. I run an incremental refresh with a look-back window of 7 days. QuickSight queries the database asking for all data since June 24 (7 days ago): 7,000 records. All the changes since June 24, including deleted, updated, and added data, are propagated into SPICE. The next day, July 2, QuickSight does the same, but querying from June 25 (7,000 records). The end result is that rather than having to ingest 180,000 records every day, you only have to process 7,000 records.
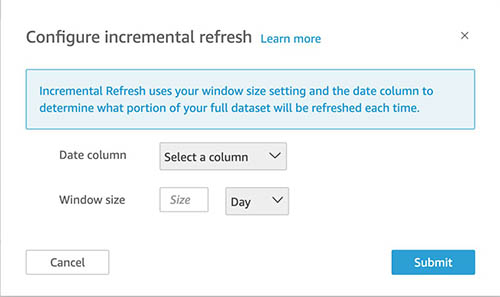
You can set up a look-back window as part of setting up your incremental refresh. After you select Incremental refresh from the steps in the preceding section, choose Configure.
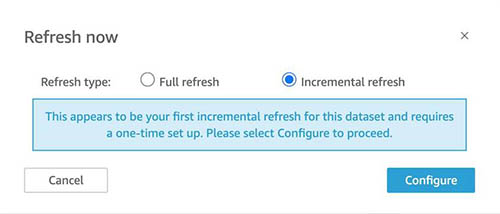
You can choose all eligible date columns to use for look-back and the window size, which QuickSight uses to query for that range. Then choose Submit.
Schedule an incremental refresh
A scheduled SQL incremental refresh allows you to regularly ingest data from a data source to SPICE, incrementally. To set up a scheduled SQL incremental refresh, similar to manual incremental refresh, if this is a first-time setup, you’re prompted to set up a look-back window. After configuration, choose the time zone, repetition interval, and starting time and choose Create.
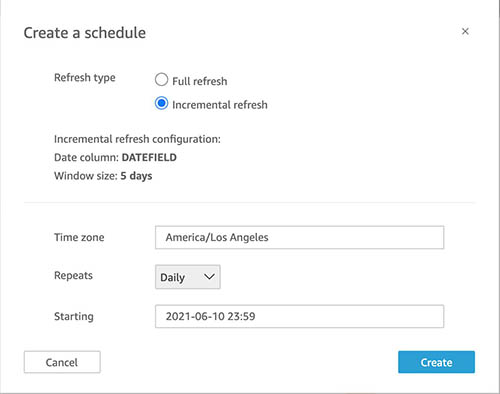
The scheduled refresh begins at the time you specified.
Set up full ingestion
Previously, for SPICE datasets, the only update mechanism in QuickSight was a full refresh. All the data defined by the dataset was queried and transferred into the dataset from its source, fully replacing what previously existed. With incremental refresh, you can update your data every 15 minutes. However, we still recommend a full refresh to make sure your dataset is in sync with the source. You can set up a full ingestion every week on a weekend to not disrupt any business workflows.
Conclusion
With incremental refresh and double SPICE capacity, QuickSight enables you to create datasets to cater to your scaling business needs in the following ways:
- Faster and reliable refreshes – Incremental refreshes are faster because only the most recent data needs to be refreshed and not the entire dataset. Additionally, the refreshes are also more reliable because you don’t need to spend time on long-running queries or any potential network disruptions.
- Large datasets – SPICE can now scale up to 500 million rows, but you don’t have to spend time updating, because you can update incrementally and don’t need to refresh the entire dataset.
- Easy setup with fewer resources – With incremental refresh, you have less data to refresh. This reduces overall consumption of resources needed. The setup process is also much simpler with scheduled incremental refresh.
QuickSight’s SPICE incremental refresh and 500 million row SPICE capacity can help you create scalable and reliable datasets without putting a strain on underlying data sources. These features are now generally available in QuickSight Enterprise Editions in all Regions. Go ahead and try it out! To learn more about refreshing data in QuickSight, see Refreshing Data.
About the Authors
 Shailesh Chauhan is a Product Manager at Amazon QuickSight, AWS’ cloud-native, fully managed BI service. Before QuickSight, Shailesh was global product lead at Uber for all data applications built from ground-up. Earlier, he was a founding team member at ThoughtSpot, where he created world’s first analytics search engine. Shailesh is passionate about building meaningful and impactful products from scratch. He looks forward to helping customers while working with people with great mind and big heart.
Shailesh Chauhan is a Product Manager at Amazon QuickSight, AWS’ cloud-native, fully managed BI service. Before QuickSight, Shailesh was global product lead at Uber for all data applications built from ground-up. Earlier, he was a founding team member at ThoughtSpot, where he created world’s first analytics search engine. Shailesh is passionate about building meaningful and impactful products from scratch. He looks forward to helping customers while working with people with great mind and big heart.
 Anilkumar Senesetti is a Software Development Manager at AWS QuickSight. He leads the Data Ingestion (DI) team that delivers solutions to accelerate ingestion of customers data into SPICE ensuring correctness, durability, consistency and security of the data. With 15 years of industry experience in business intelligence domain, he provides valuable insights across layers to deliver solutions that improve customer experience. He is passionate about predictive analytics and outside of the work, he enjoys building features on astrological website that he owns.
Anilkumar Senesetti is a Software Development Manager at AWS QuickSight. He leads the Data Ingestion (DI) team that delivers solutions to accelerate ingestion of customers data into SPICE ensuring correctness, durability, consistency and security of the data. With 15 years of industry experience in business intelligence domain, he provides valuable insights across layers to deliver solutions that improve customer experience. He is passionate about predictive analytics and outside of the work, he enjoys building features on astrological website that he owns.