AWS Big Data Blog
Deep dive on Amazon MSK tiered storage
In the first post of the series, we described some core concepts of Apache Kafka cluster sizing, the best practices for optimizing the performance, and the cost of your Kafka workload.
This post explains how the underlying infrastructure affects Kafka performance when you use Amazon Managed Streaming for Apache Kafka (Amazon MSK) tiered storage. We delve deep into the core components of Amazon MSK tiered storage and address questions such as: How does read and write work in a tiered storage-enabled cluster?
In the subsequent post, we’ll discuss the latency impact, recommended metrics to monitor, and conclude with guidance on key considerations in a production tiered storage-enabled cluster.
How Amazon MSK tiered storage works
To understand the internal architecture of Amazon MSK tiered storage, let’s first discuss some fundamentals of Kafka topics, partitions, and how read and write works.
A logical stream of data in Kafka is referred to as a topic. A topic is broken down into partitions, which are physical entities used to distribute load across multiple server instances (brokers) that serve reads and writes.
A partition––also designated as topic-partition as it’s relative to a given topic––can be replicated, which means there are several copies of the data in the group of brokers forming a cluster. Each copy is called a replica or a log. One of these replicas, called the leader, serves as the reference. It’s where the ingress traffic is accepted for the topic-partition.
A log is an append-only sequence of log segments. Log segments contain Kafka data records, which are added to the end of the log or the active segment.
Log segments are stored as regular files. On the file system, Kafka identifies the file of a log segment by putting the offset of the first data record it contains in its file name. The offset of a record is simply a monotonic index assigned to a record by Kafka when it’s appended to the log. The segment files of a log are stored in a directory dedicated to the associated topic-partition.
When Kafka reads data from an arbitrary offset, it first looks up the segment that contains that offset from the segment file name, then the specific record location inside that file using an offset index. Offset indexes are materialized on a dedicated file stored with segment files in the topic-partition directory. There is also timeindex to seek by timestamp.
For every partition, Kafka also stores a journal of leadership changes in a file called leader-epoch-checkpoint. This file contains mapping of leader epoch to startOffset of the epoch. Whenever a new leader is elected for a partition by the Kafka controller, this data is updated and propagated to all brokers. A leader epoch is a 32-bit, monotonically increasing number representing continuous period of leadership of a single partition. It’s marked on all the Kafka records. The following code is the local storage layout of topic cars and partition 0 containing two segments (0, 35):
Kafka manages the lifecycle of these segment files. It creates a new one when a new segment needs to be created, for instance, if the current segment reaches its configured max size. It deletes one when the target retention period of the data it contains is reached, or the total maximal size of the log is reached. Data is deleted from the tail of the logs and corresponds to the oldest data of the append-only log of the topic-partition.

KIP-405 or tiered storage in Apache Kafka
The ability to tier data, in other words, transfer data (log, index, timeindex, and leader-epoch-checkpoint) from a local file system to another storage system based on time and size-based retention policies, is a feature built in Apache Kafka as part of KIP-405.
The KIP-405 isn’t in official Kafka version yet. Amazon MSK internally implemented tiered storage functionality on top of official Kafka version 2.8.2. Amazon MSK exposes this functionality on AWS specific 2.8.2.tiered Kafka version. With this feature, you can separate retention settings for local and remote retention. Data in the local tier is retained until the data gets copied to the remote tier even after the local retention expires. Data in the remote tier is retained until the remote retention expires. KIP-405 proposes a pluggable architecture allowing you to plugin custom remote storage and metadata storage backends. The following diagram illustrates the broker three key components.
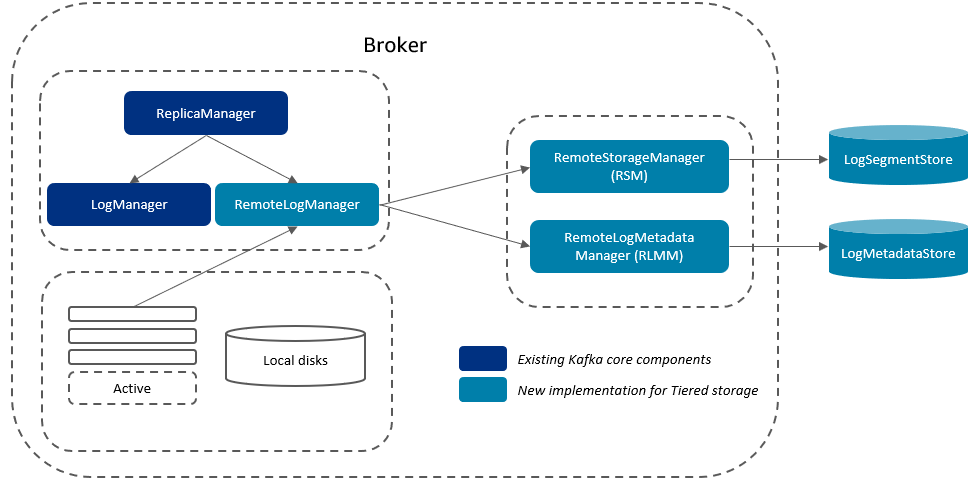
The components are as follows:
- RemoteLogManager (RLM) – A new component corresponding to LogManager for the local tier. It delegates copy, fetch, and delete of completed and non-active partition segments to a pluggable RemoteStorageManager implementation and maintains respective remote log segment metadata through pluggable RemoteLogMetadataManager implementation.
- RemoteStorageManager (RSM) – A pluggable interface that provides the lifecycle of remote log segments.
- RemoteLogMetadataManager (RLMM) – A pluggable interface that provides the lifecycle of metadata about remote log segments.
How data is moved to the remote tier for a tiered storage-enabled topic
In a tiered storage-enabled topic, each completed segment for a topic-partition triggers the leader of the partition to copy the data to the remote storage tier. The completed log segment is removed from the local disks when Amazon MSK finishes moving that log segment to the remote tier and after it meets the local retention policy. This frees up local storage space.
Let’s consider a hypothetical scenario: you have a topic with one partition. Prior to enabling tiered storage for this topic, there are three log segments. One of the segments is active and receiving data, and the other two segments are complete.
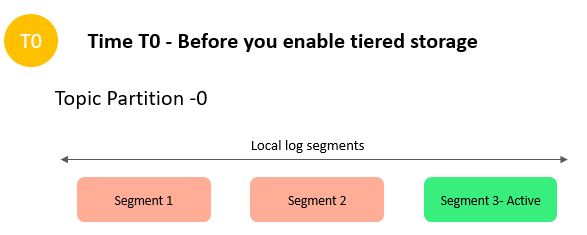
After you enable tiered storage for this topic with two days of local retention and five days of overall retention, Amazon MSK copies log segment 1 and 2 to tiered storage. Amazon MSK also retains the primary storage copy of segments 1 and 2. The active segment 3 isn’t eligible to copy over to tiered storage yet. In this timeline, none of the retention settings are applied yet for any of the messages in segment 1 and segment 2.
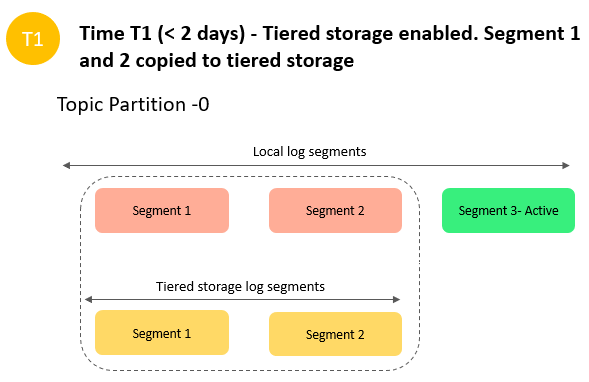
After 2 days, the primary retention settings take effect for the segment 1 and segment 2 that Amazon MSK copied to the tiered storage. Segments 1 and 2 now expire from the local storage. Active segment 3 is neither eligible for expiration nor eligible to copy over to tiered storage yet because it’s an active segment.
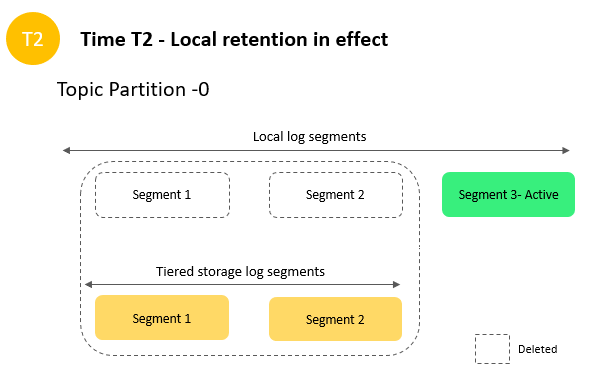
After 5 days, overall retention settings take effect, and Amazon MSK clears log segments 1 and 2 from tiered storage. Segment 3 is neither eligible for expiration nor eligible to copy over to tiered storage yet because it’s active.
That’s how the data lifecycle works on a tiered storage-enabled cluster.

Amazon MSK immediately starts moving data to tiered storage as soon as a segment is closed. The local disks are freed up when Amazon MSK finishes moving that log segment to remote tier and after it meets the local retention policy.
How read works in a tiered storage-enabled topic
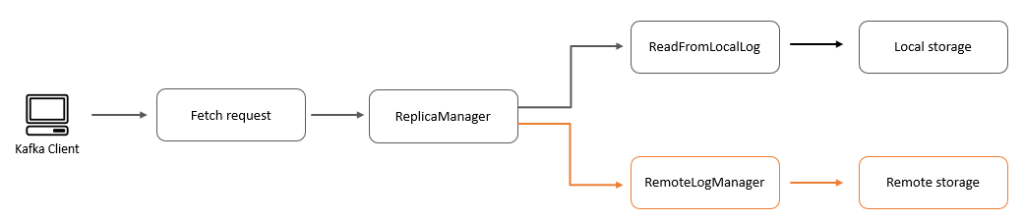
For any read request, ReplicaManager tries to process the request by sending it to ReadFromLocalLog. And if the process returns offset out of range exception, it delegates the read call to RemoteLogManager to read from tiered storage. On the read path, the RemoteStorageManager starts fetching the data in chunks from remote storage, which means that for the first few bytes, your consumer experiences higher latency, but as the system starts buffering the segment locally, your consumer experiences latency similar to reading from local storage. One of the advantages of this approach is that the data is served instantly from the local buffer if there are multiple consumers reading from the same segment.
If your consumer is configured to read from the closest replica, there might be a possibility that the consumer from a different consumer group reads the same remote segment using a different broker. In that case, they experience the same latency behavior we described previously.
Conclusion
In this post, we discussed the core components of the Amazon MSK tiered storage feature and explained how the data lifecycle works in a cluster enabled with tiered storage. Stay tuned for our upcoming post, in which we delve into the best practices for sizing and running a tiered storage-enabled cluster in production.
We would love to hear how you’re building your real-time data streaming applications today. If you’re just getting started with Amazon MSK tiered storage, we recommend getting hands-on with the guidelines available in the tiered storage documentation.
If you have any questions or feedback, please leave them in the comments section.
About the authors
 Nagarjuna Koduru is a Principal Engineer in AWS, currently working for AWS Managed Streaming For Kafka (MSK). He led the teams that built MSK Serverless and MSK Tiered storage products. He previously led the team in Amazon JustWalkOut (JWO) that is responsible for realtime tracking of shopper locations in the store. He played pivotal role in scaling the stateful stream processing infrastructure to support larger store formats and reducing the overall cost of the system. He has keen interest in stream processing, messaging and distributed storage infrastructure.
Nagarjuna Koduru is a Principal Engineer in AWS, currently working for AWS Managed Streaming For Kafka (MSK). He led the teams that built MSK Serverless and MSK Tiered storage products. He previously led the team in Amazon JustWalkOut (JWO) that is responsible for realtime tracking of shopper locations in the store. He played pivotal role in scaling the stateful stream processing infrastructure to support larger store formats and reducing the overall cost of the system. He has keen interest in stream processing, messaging and distributed storage infrastructure.
 Masudur Rahaman Sayem is a Streaming Data Architect at AWS. He works with AWS customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.
Masudur Rahaman Sayem is a Streaming Data Architect at AWS. He works with AWS customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.