AWS Big Data Blog
Export JSON data to Amazon S3 using Amazon Redshift UNLOAD
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics workloads such as high-performance business intelligence (BI) reporting, dashboarding applications, data exploration, and real-time analytics.
As the amount of data generated by IoT devices, social media, and cloud applications continues to grow, organizations are looking to easily and cost-effectively analyze this data with minimal time-to-insight. A vast amount of this data is available in semi-structured format and needs additional extract, transform, and load (ETL) processes to make it accessible or to integrate it with structured data for analysis. Amazon Redshift powers the modern data architecture, which enables you to query data across your data warehouse, data lake, and operational databases to gain faster and deeper insights not possible otherwise. With a modern data architecture, you can store data in semi-structured format in your Amazon Simple Storage Service (Amazon S3) data lake and integrate it with structured data on Amazon Redshift. This allows you to make this data available to other analytics and machine learning applications rather than locking it in a silo.
In this post, we discuss the UNLOAD feature in Amazon Redshift and how to export data from an Amazon Redshift cluster to JSON files on an Amazon S3 data lake.
JSON support features in Amazon Redshift
Amazon Redshift features such as COPY, UNLOAD, and Amazon Redshift Spectrum enable you to move and query data between your data warehouse and data lake.
With the UNLOAD command, you can export a query result set in text, JSON, or Apache Parquet file format to Amazon S3. UNLOAD command is also recommended when you need to retrieve large result sets from your data warehouse. Since UNLOAD processes and exports data in parallel from Amazon Redshift’s compute nodes to Amazon S3, this reduces the network overhead and thus time in reading large number of rows. When using the JSON option with UNLOAD, Amazon Redshift unloads to a JSON file with each line containing a JSON object, representing a full record in the query result. In the JSON file, Amazon Redshift types are unloaded as the closest JSON representation. For example, Boolean values are unloaded as true or false, NULL values are unloaded as null, and timestamp values are unloaded as strings. If a default JSON representation doesn’t suit a particular use case, you can modify it by casting to the desired type in the SELECT query of the UNLOAD statement.
Additionally, to create a valid JSON object, the name of each column in the query result must be unique. If the column names in the query result aren’t unique, the JSON UNLOAD process fails. To avoid this, we recommend using proper column aliases so that each column in the query result remains unique while getting unloaded. We illustrate this behavior later in this post.
With the Amazon Redshift SUPER data type, you can store data in JSON format on local Amazon Redshift tables. This way, you can process the data without any network overhead and use Amazon Redshift schema properties to optimally save and query semi structured data locally. In addition to achieving low latency, you can also use the SUPER data type when your query requires strong consistency, predictable query performance, complex query support, and ease of use with evolving schemas and schemaless data. Amazon Redshift supports writing nested JSON when the query result contains SUPER columns.
Updating and maintaining data with constantly evolving schemas can be challenging and adds extra ETL steps to the analytics pipeline. The JSON file format provides support for schema definition, is lightweight, and is widely used as a data transfer mechanism by different services, tools, and technologies.
Amazon OpenSearch Service is a distributed, open-source search and analytics suite used for a broad set of use cases like real-time application monitoring, log analytics, and website search. It uses JSON as the supported file format for data ingestion. The ability to unload data natively in JSON format from Amazon Redshift into the Amazon S3 data lake reduces complexity and additional data processing steps if that data needs to be ingested into Amazon OpenSearch Service for further analysis.
This is one example of how seamless data movement can help you build an integrated data platform with a data lake on Amazon S3, data warehouse on Amazon Redshift and search and log analytics using Amazon OpenSearch Service and any other JSON-oriented downstream analytics solution. For more information about the Lake House approach, see Build a Lake House Architecture on AWS.
Examples of Amazon Redshift JSON UNLOAD
In this post, we show you the following different scenarios:
- Example 1 – Unload customer data in JSON format into Amazon S3, partitioning output files into partition folders, following the Apache Hive convention, with customer birth month as the partition key. We make a few changes to the columns in the SELECT statement of the UNLOAD command:
- Convert the
c_preferred_cust_flagcolumn from character to Boolean - Remove leading and trailing spaces from the
c_first_name,c_last_name, andc_email_addresscolumns using the Amazon Redshift built-in function btrim
- Convert the
- Example 2 – Unload line item data (with SUPER column) in JSON format into Amazon S3 with data not partitioned
- Example 3 – Unload line item data (With SUPER column) in JSON format into Amazon S3, partitioning output files into partition folders, following the Apache Hive convention, with customer key as the partition key
For the first example, we used the customer table and data from the TPCDS dataset. For examples involving table with SUPER column, we used the customer_orders_lineitem table and data from the following tutorial.
Example 1: Export customer data
For this example, we used the customer table and data from TPCDS dataset. We created the database schema and customer table, and copied data into it. See the following code:
You can create a default AWS Identity and Access Management (IAM) role for your Amazon Redshift cluster to copy from and unload to your Amazon S3 location. For more information, see Use the default IAM role in Amazon Redshift to simplify accessing other AWS services.
In this example, we unloaded customer data for all customers with birth year 1992 in JSON format into Amazon S3 without any partitions. We make the following changes to the UNLOAD statement:
- Convert the
c_preferred_cust_flagcolumn from character to Boolean - Remove leading and trailing spaces from the
c_first_name,c_last_name, andc_email_addresscolumns using thebtrimfunction - Set the maximum size of exported files in Amazon S3 to 64 MB
See the following code:
When we ran the UNLOAD command, we encountered an error because the columns that used the btrim function all attempted to be exported as btrim (which is the default behavior of Amazon Redshift when the same function is applied to multiple columns that are selected together). To avoid this error, we need to use a unique column alias for each column where the btrim function was used.
If we select the c_first_name, c_last_name, and c_email_address columns by applying the btrim function and c_preferred_cust_flag, we can convert them from character to Boolean.
We ran the following query in Amazon Redshift Query Editor v2:
All three columns that used the btrim function are set as btrim in the output result instead of their respective column name.

An error occurred in UNLOAD because we didn’t use a column alias.

We added column aliases in the following code:
After we added column aliases, the UNLOAD command completed successfully and files were exported to the desired location in Amazon S3.

The following screenshot shows data is unloaded in JSON format partitioning output files into partition folders, following the Apache Hive convention, with customer birth month as the partition key into Amazon S3 from the Amazon Redshift customer table.
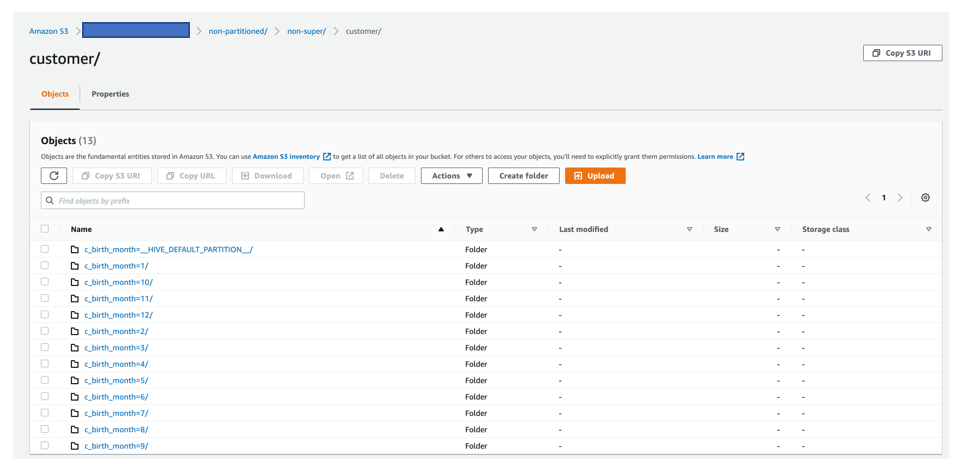
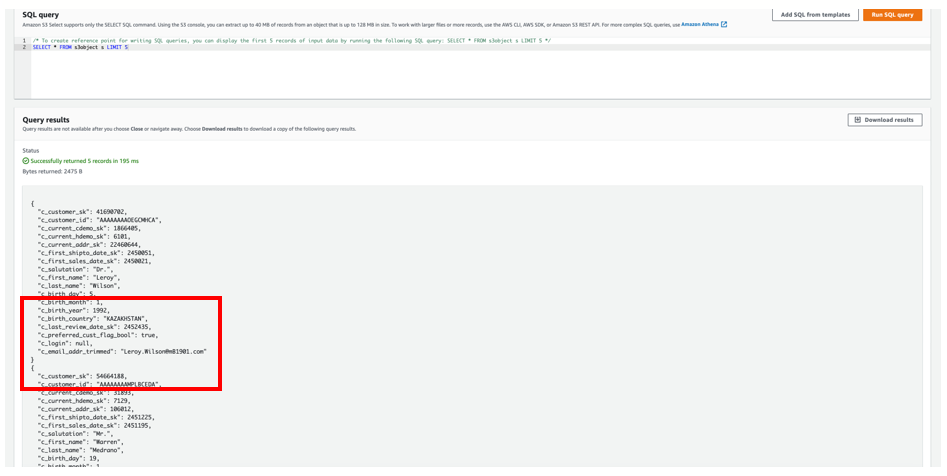
A query with Amazon S3 Select shows a snippet of data in the JSON file on Amazon S3 that was unloaded.

The column aliases c_first_name, c_last_name, and c_email_addr_trimmed were written into the JSON record as per the SELECT query. Boolean values were saved in c_preferred_cust_flag_bool as well.
Examples 2 and 3: Using the SUPER column
For the next two examples, we used the customer_orders_lineitem table and data. We created the customer_orders_lineitem table and copied data into it with the following code:
Next, we ran a few queries to explore the customer_orders_lineitem table’s data:



Example 2: Without partitions
In this example, we unloaded all the rows of the customer_orders_lineitem table in JSON format into Amazon S3 without any partitions:
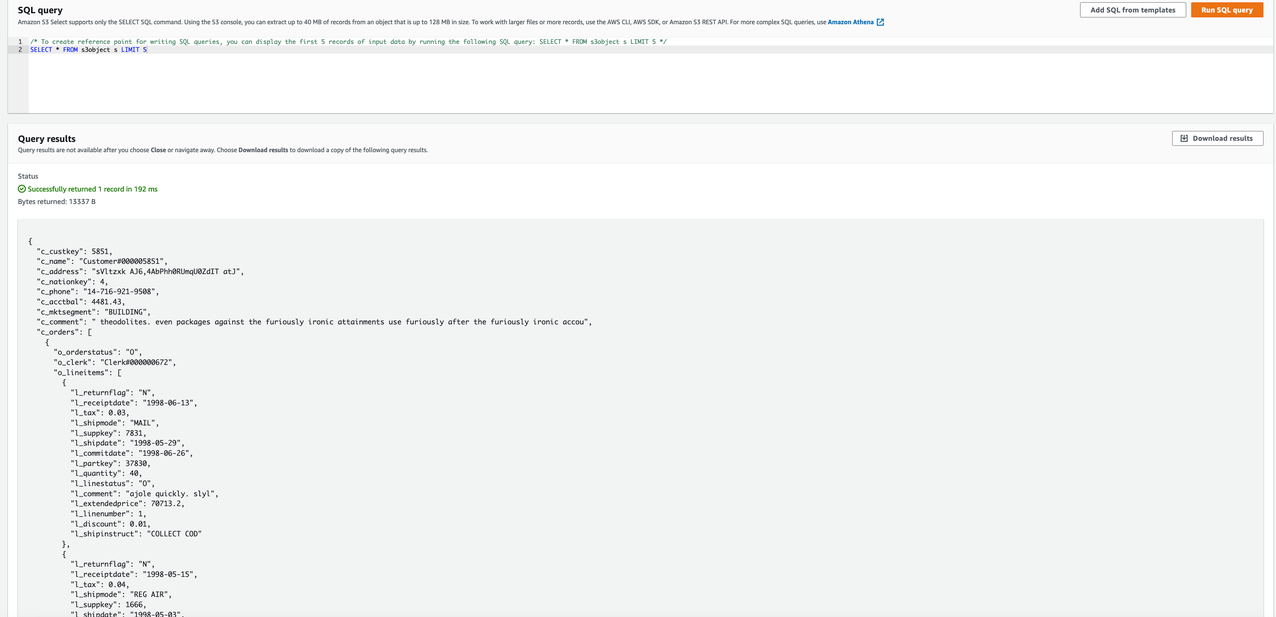
After we run the UNLOAD command, the data is available in the desired Amazon S3 location. The following screenshot shows data is unloaded in JSON format without any partitions into Amazon S3 from the Amazon Redshift customer_orders_lineitem table.

A query with Amazon S3 Select shows a snippet of data in the JSON file on Amazon S3 that was unloaded.

Example 3: With partitions
In this example, we unloaded all the rows of the customer_orders_lineitem table in JSON format partitioning output files into partition folders, following the Apache Hive convention, with customer key as the partition key into Amazon S3:
After we run the UNLOAD command, the data is available in the desired Amazon S3 location. The following screenshot shows data is unloaded in JSON format partitioning output files into partition folders, following the Apache Hive convention, with customer key as the partition key into Amazon S3 from the Amazon Redshift customer_orders_lineitem table.

A query with Amazon S3 Select shows a snippet of data in the JSON file on Amazon S3 that got unloaded.
Conclusion
In this post, we showed how you can use the Amazon Redshift UNLOAD command to unload the result of a query to one or more JSON files into your Amazon S3 location. We also showed how you can partition the data using your choice of partition key while you unload the data. You can use this feature to export data to JSON files into Amazon S3 from your Amazon Redshift cluster or your Amazon Redshift Serverless endpoint to make your data processing simpler and build an integrated data analytics platform.
About the Authors
 Dipankar Kushari is a Senior Analytics Solutions Architect with AWS.
Dipankar Kushari is a Senior Analytics Solutions Architect with AWS.
 Sayali Jojan is a Senior Analytics Solutions Architect with AWS. She has 7 years of experience working with customers to design and build solutions on the AWS Cloud, with a focus on data and analytics.
Sayali Jojan is a Senior Analytics Solutions Architect with AWS. She has 7 years of experience working with customers to design and build solutions on the AWS Cloud, with a focus on data and analytics.
 Cody Cunningham is a Software Development Engineer with AWS, working on data ingestion for Amazon Redshift.
Cody Cunningham is a Software Development Engineer with AWS, working on data ingestion for Amazon Redshift.