AWS Big Data Blog
On-demand and scheduled scaling of Amazon MSK Express based clusters
Modern streaming workloads are highly dynamic—traffic volumes fluctuate based on time of day, business cycles, or event-driven bursts. Customers need to dynamically scale Apache Kafka clusters up and down to maintain consistent throughput and performance without incurring unnecessary cost. For example, ecommerce platforms see sharp traffic increases during seasonal sales, and financial systems experience load spikes during market hours. Scaling clusters helps teams align cluster capacity with increased ingress throughput in response to these variations, leading to more efficient utilization and a better cost-to-performance ratio.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) Express brokers are a key component to dynamically scaling clusters to meet demand. Express based clusters deliver 3 times higher throughput, 20 times faster scaling capabilities, and 90% faster broker recovery compared to Amazon MSK Provisioned clusters. In addition, Express brokers support intelligent rebalancing for 180 times faster operation performance, so partitions are automatically and consistently well distributed across brokers. This feature is enabled by default for all new Express based clusters and comes at no additional cost to customers. This capability alleviates the need for manual partition management when modifying cluster capacity. Intelligent rebalancing automatically tracks cluster health and triggers partition redistribution when resource imbalances are detected, maintaining performance across brokers.
This post demonstrates how to use the intelligent rebalancing feature and build a custom solution that scales Express based clusters horizontally (adding and removing brokers) dynamically based on Amazon CloudWatch metrics and predefined schedules. The solution provides capacity management while maintaining cluster performance and minimizing overhead.
Overview of Kafka scaling
Scaling Kafka clusters involves adding or removing brokers to the cluster while providing balanced data distribution and uninterrupted service. When new brokers are added, partition reassignment is required to evenly distribute load across the cluster. This process is typically performed manually—either through the Kafka command line tools (kafka-reassign-partitions.sh) or by using automation frameworks such as Cruise Control, which intelligently calculates and executes reassignment plans. During scale-in operations, partitions hosted on the brokers marked for removal must first be migrated to other brokers, leaving the target brokers empty before decommissioning.
Challenges of scaling Kafka dynamically
The complexity of scaling depends heavily on the underlying storage model. In deployments where broker data resides entirely on local storage, scaling involves physical data movement between brokers, which can take considerable time depending on partition size and replication factor. In contrast, environments that use tiered storage shift most of the data to remote object storage such as Amazon Simple Storage Service (Amazon S3), making scaling a largely metadata-driven operation. This significantly reduces data transfer overhead and accelerates both broker addition and removal, enabling more elastic and operationally efficient Kafka clusters.
However, scaling Kafka remains a non-trivial operation due to the interplay between storage, data movement, and broker resource utilization. When partitions are reassigned across brokers, large volumes of data must be copied over the network, often leading to network bandwidth saturation, storage bandwidth exhaustion, and elevated CPU utilization. Depending on data volume and replication factor, partition rebalancing can take several hours, during which time cluster performance and throughput might temporarily degrade and often require additional configuration to throttle the data movement. Although tools like Cruise Control automate this process, they introduce another layer of complexity: selecting the right combination of rebalancing goals (such as disk capacity, network load, or replica distribution) requires a deep understanding of Kafka internals and trade-offs between speed, balance, and stability. As a result, efficient scaling is an optimization problem, demanding careful orchestration of storage, compute, and network resources.
How Express brokers simplify scaling
Express brokers manage Kafka scaling through their decoupled compute and storage architecture. This innovative design enables unlimited storage without pre-provisioning, significantly simplifying cluster sizing and management. The separation of compute and storage resources allows Express brokers to scale faster than standard MSK brokers, enabling rapid cluster expansion within minutes. With Express brokers, administrators can adjust capacity both vertically and horizontally as needed, alleviating the need for over-provisioning. The architecture provides sustained broker throughput during scaling operations, with Express brokers capable of handling 500 MBps ingress and 1000 MBps egress on m7g.16xl instances. For more information about how the scaling process works in Express based clusters, see Express brokers for Amazon MSK: Turbo-charged Kafka scaling with up to 20 times faster performance.
Added to this faster scaling capability, when you add or remove brokers from your Express based clusters, intelligent rebalancing automatically redistributes partitions to balance resource utilization across the brokers. This makes sure the cluster continues to operate at peak performance, making scaling in and out possible with a single update operation. Intelligent rebalancing is enabled by default on new Express broker clusters and continuously monitors cluster health for resource imbalances or hotspots. For example, if certain brokers become overloaded due to uneven distribution of partitions or skewed traffic patterns, intelligent rebalancing will automatically move partitions to less utilized brokers to restore balance.
Finally, Express based clusters automate client configuration of broker bootstrap connection strings to allow clients to connect to clusters seamlessly as brokers are added and removed. Express based clusters provide three connection strings, one per Availability Zone, which are independent of the brokers in the cluster. This means clients only need to configure these connection strings to maintain consistent connections as brokers are added or removed. These key capabilities of Express based clusters—rapid scaling, intelligent rebalancing, and dynamic broker bootstrapping—are critical to enabling dynamic scaling in Kafka clusters. In the following section, we explore how we use these capabilities to automate the scaling process of Express based clusters.
On-demand and scheduled scaling
Leveraging fast scaling capabilities of Express brokers together with intelligent rebalancing, you can build a flexible and dynamic scaling solution to optimize your Kafka cluster resources. There are two primary approaches for automatic scaling that balance performance needs with cost efficiency: on-demand and scheduled scaling.
On-demand scaling
On-demand scaling tracks cluster performance and responds to capacity demands. This approach addresses scenarios where workload patterns experience traffic spikes. On-demand scaling tracks Amazon MSK performance indicators as CPU utilization and network ingress and egress throughput per broker. Beyond these infrastructure metrics, the solution also supports using CloudWatch metrics to enable business-logic-driven scaling decisions.
The solution evaluates the performance metrics continuously against configurable thresholds to determine when scaling actions are necessary. When brokers operate above capacity thresholds consistently over a period of time, it invokes an Amazon MSK API to increase the broker count of the cluster. The solution in this post currently supports horizontal scaling (adding and removing brokers) only. Intelligent rebalancing will then automatically redistribute the partitions to spread the load across the new brokers that are added. Similarly, when utilization drops below thresholds, the solution invokes an Amazon MSK API to remove brokers. The rebalancing process automatically moves partitions from the broker marked for removal to other brokers in the cluster. This solution requires topics to have sufficient partitions to support rebalancing to new brokers as brokers are added.
The following diagram illustrates the on-demand scaling workflow.

Scheduled scaling
Scheduled scaling adjusts cluster capacity using time-based triggers. This approach is useful for applications with traffic patterns that correlate with business hours or schedules. For example, ecommerce platforms benefit from scheduled scaling during peak sale periods when customer activity peaks. Scheduled scaling is also useful for customers who want to avoid cluster modification operations during business hours. This solution uses a configurable schedule to scale out the cluster capacity before business hours to handle the anticipated traffic and scale in after business hours to reduce costs. This particular solution currently supports horizontal scaling (adding/removing brokers) only. With scheduled scaling, you can handle specific scenarios such as weekday business hours, weekend maintenance windows, or specific dates. You can also specify the desired number of brokers at scale-out and scale-in.
The following diagram illustrates the scheduled scaling workflow.

Solution overview
This solution provides scaling automation for Express brokers through two approaches:
- On-demand scaling – Tracks built-in cluster performance metrics or custom CloudWatch metrics and adjusts broker capacity when thresholds are crossed
- Scheduled scaling – Scales clusters based on specific schedules
In the following sections, we provide the implementation details for both scaling methods.
Prerequisites
Complete the following steps as prerequisites:
- Create an Express cluster with intelligent rebalancing enabled. The intelligent rebalancing feature is required for this solution to work. Note the Amazon Resource Name (ARN) of the cluster.
- Install Python 3.11 or higher on Amazon Elastic Compute Cloud (Amazon EC2).
- Install the AWS Command Line Interface (AWS CLI) and configure it with your AWS credentials.
- Install the AWS CDK CLI.
On-demand scaling solution
The solution uses an AWS Lambda function that is triggered by an Amazon EventBridge scheduler periodically. The Lambda function checks the cluster state and time since the last broker addition or removal was done. This is done to determine if the cluster is ready to scale. If the cluster is ready for scaling, the function collects the CloudWatch metrics that need to be evaluated to make the scaling decision. Based on the scaling configuration and using the metrics in CloudWatch, the function evaluates the scaling logic and executes the scaling decision. The scaling decision can lead to addition or removal of brokers to the cluster. In both cases, intelligent rebalancing handles partition distribution across brokers without manual intervention. You can find more details of the scaling logic in the GitHub repo.
The following diagram illustrates the architecture of the on-demand scaling solution.
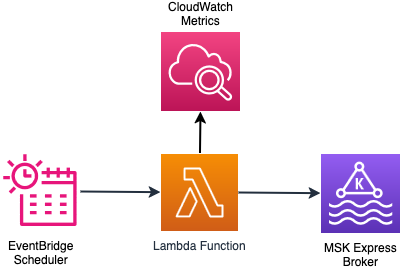
Deploy on-demand scaling solution
Follow these steps to deploy the on-demand scaling infrastructure. For this post, we demonstrate the on-demand scale-out functionality.
- Run the following commands to set the project up:
- Modify the thresholds to match your MSK broker instance size and business requirements by editing
src/config/on_demand_scaling_config.json. Refer to the configuration documentation for more details of the configuration options available.
By default,on_demand_scaling_config.jsonconsiders the express.m7g.large broker instance size. Therefore the scale-in/scale-out ingress/egress thresholds are configured at 70% of the recommended sustained throughput for the instance size. - Bootstrap your environment for use with the AWS CDK.
- Deploy the on-demand scaling AWS CDK application:
The monitoring_frequency_minutes parameter controls how often the EventBridge scheduler invokes the scaling logic Lambda function to evaluate cluster metrics.
The deployment creates the AWS resources required to run the on-demand scaling solution. The details of the resources created are shown in the output of the command.
Test and monitor the on-demand scaling solution
Configure the bootstrap server for your MSK cluster. You can get the bootstrap server from the AWS Management console or using the AWS CLI.
Create a Kafka topic in the cluster. Update the following command for the specific authentication method in Amazon MSK. Refer to the Amazon MSK Labs workshop for more details.
Topics should have a sufficient number of partitions that can be distributed across a larger set of brokers.
Generate load on the MSK cluster to trigger and verify the scaling operations. You can use an existing application that drives load to your cluster. You can also use the kafka-producer-perf-test.sh utility that is bundled as part of the Kafka distribution to generate load:
Monitor the scaling operations by tailing the Lambda function logs:
In the logs, look for the following messages to identify the exact times when scaling operations occurred. The log statements above these messages show the rationale behind the scaling decision:
The solution also creates a CloudWatch dashboard that provides visibility into scaling operations and many other broker metrics. The link to the dashboard is shown in the output of the cdk deploy command.
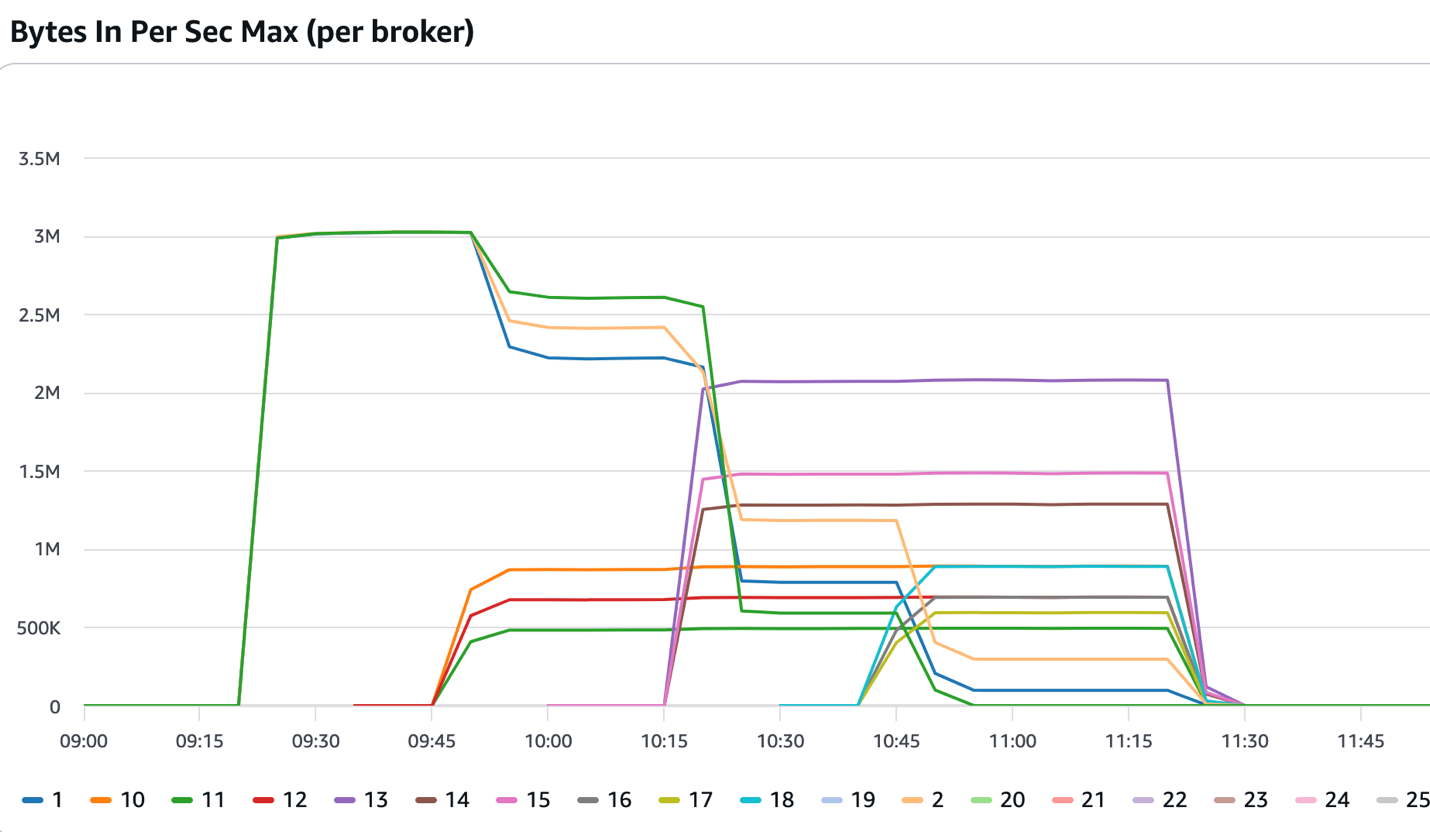
The following figure shows a cluster that started with three brokers. After the 09:15 mark, it received consistent inbound traffic, which exceeded the thresholds set in the solution. The solution added three more brokers that came into service at around the 09:45 mark. Intelligent rebalancing reassigned some of the partitions to the newly added brokers and the incoming traffic was split across six brokers. The solution continued adding more brokers until the cluster had 12 brokers and the intelligent rebalancing feature continued distributing the partitions across the newly added brokers.
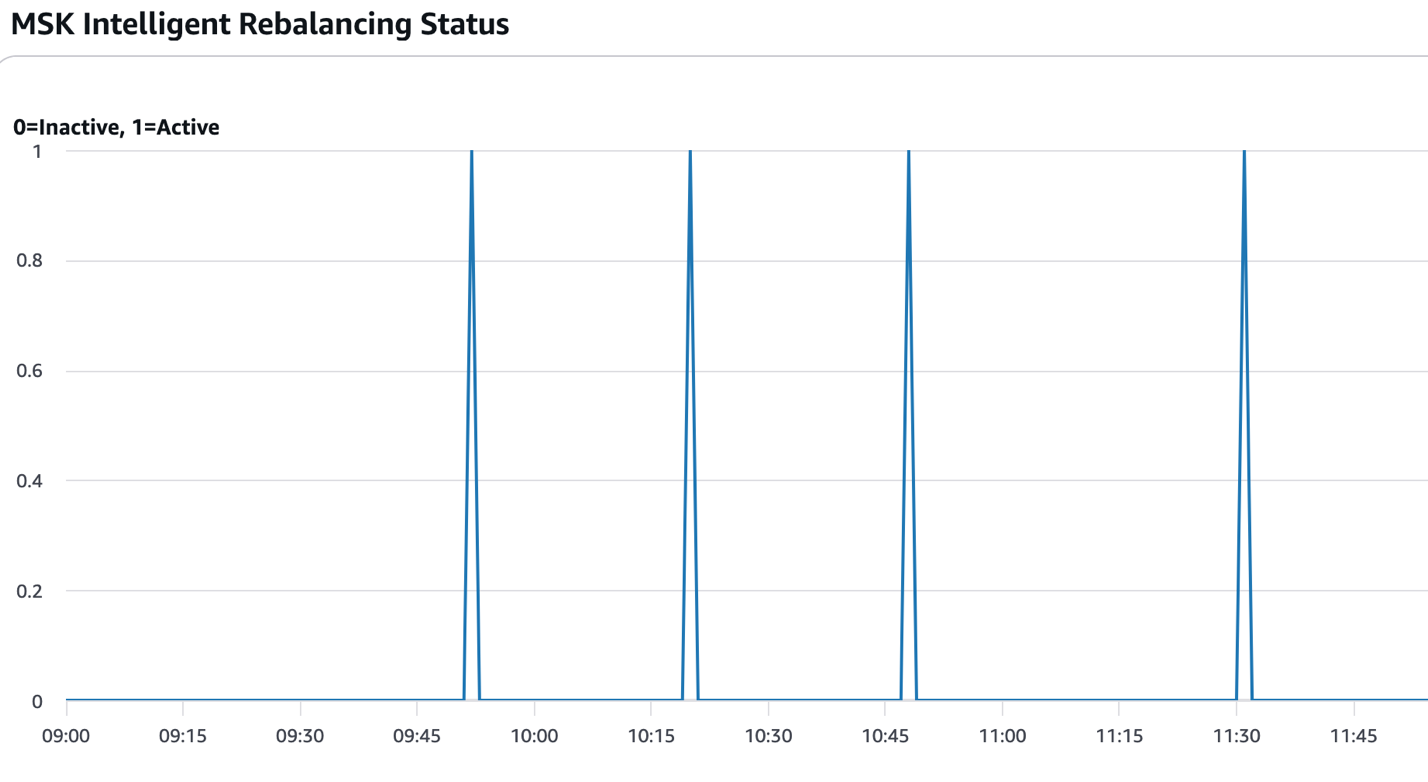
The following figure shows the times when partition rebalancing was active (value=1). In the context of this solution, that typically occurs after new brokers are added or removed and the scaling operations are complete.
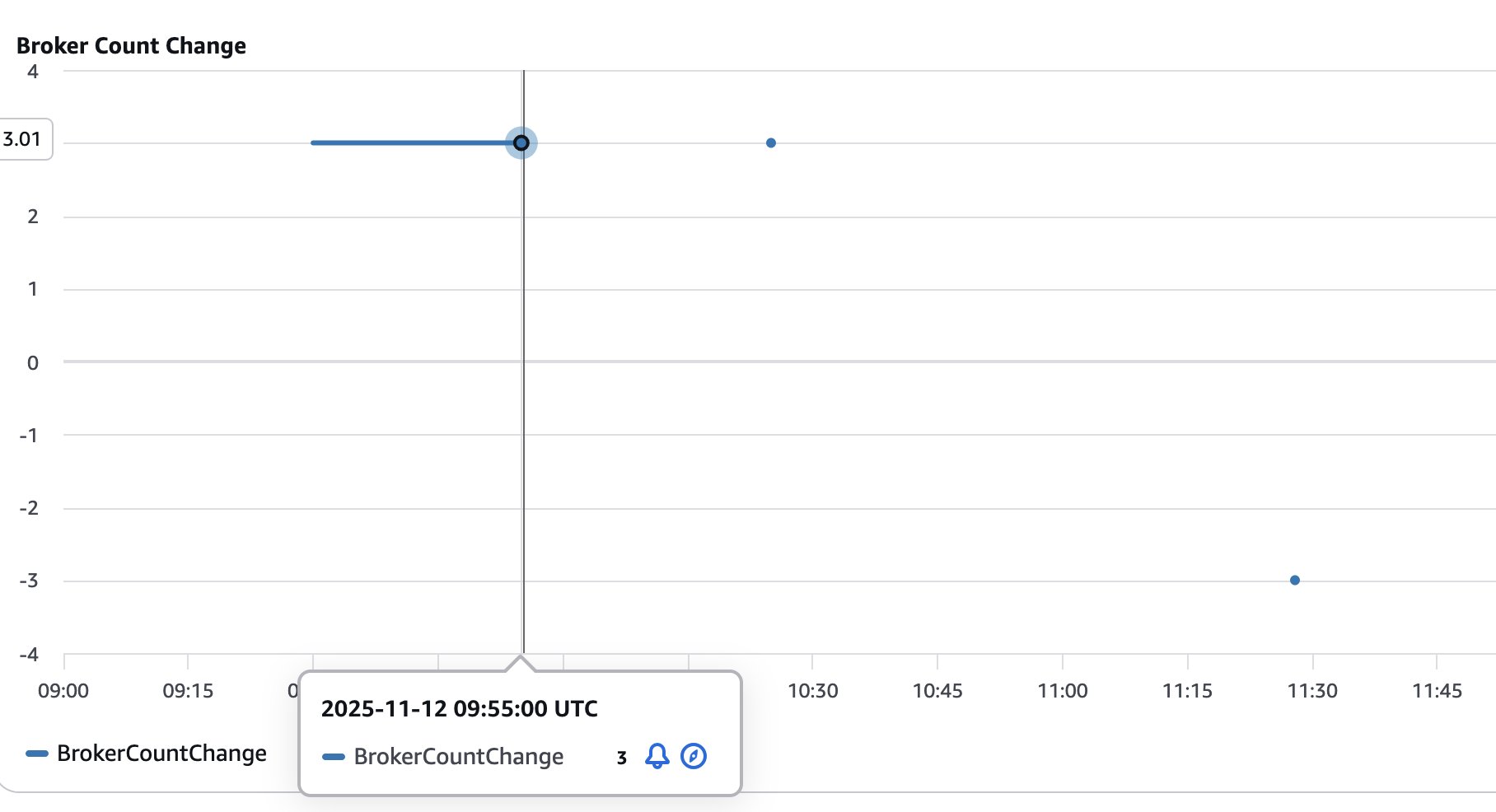
The following figure shows the number of brokers added (positive values) or removed (negative values) from the cluster. This helps visualize and track the size of the cluster as it goes through scaling operations.
Scheduled scaling solution
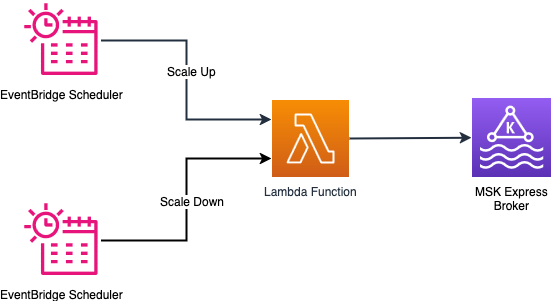
The scheduled scaling implementation supports timing patterns through an EventBridge schedule. You can configure timing to trigger an action using cron expressions. Based on the cron expression, the EventBridge Scheduler triggers a Lambda function at the specified time to scale out or scale in. The Lambda function performs checks if the cluster is ready for a scaling operation and performs the requested scaling operation by invoking the Amazon MSK control plane API. The service allows removing only three brokers at a time from a cluster. The solution handles this scenario by repeatedly removing the brokers in counts of three until the desired number of brokers are reached.
The following diagram illustrates the architecture of the scheduled scaling solution.
Configuration parameters
EventBridge schedules support cron expressions for precise timing control, so you can fine-tune scaling operations for specific times of day and days of the week. For example, you can configure scaling to occur at 8:00 AM on weekdays using the cron expression cron(0 8 ? * MON-FRI *). To scale in at 6:00 PM on the same days, use cron(0 18 ? * MON-FRI *). For more patterns, refer to Setting a schedule pattern for scheduled rules (legacy) in Amazon EventBridge. You can also configure the desired broker count to be reached during scale-out and scale-in operations.
Deploy scheduled scaling solution
Follow these steps to deploy the scheduled scaling solution:
- Run the following commands to set the project up:
- Modify the scaling schedule by editing
scaling/cdk/src/config/scheduled_scaling_config.json. Refer to the configuration documentation for more details of the configuration options available. - Deploy the scheduled scaling AWS CDK application:
Test and monitor the scheduled scaling solution
The scheduled scaling is triggered as specified in the EventBridge Scheduler cron. However, if you want to test the scale-out operations, run the following command to manually invoke the Lambda function:
Similarly, you can manually start a scale-in operation by running the following command:
Monitor the scaling operations by tailing the Lambda function logs:
You can monitor scheduled scaling using the CloudWatch dashboard as described in the on-demand scaling section.
Review scaling configuration parameters
The configuration parameters for both on-demand and scheduled scaling are documented in Configuration Options. These configurations give you flexibility to change how and when the scaling happens. It is important to go through the configuration parameters and make sure they meet your business requirement. For on-demand scaling, you can scale the cluster based on built-in performance metrics or custom metrics (for example MessagesInPerSec).
Considerations
Keep in mind the following considerations when deploying either solution:
- EventBridge notifications for scaling failures – Both on-demand and scheduled scaling solutions publish EventBridge notifications when scaling operations fail. Create EventBridge rules to route these failure events to your monitoring and alerting system to detect failures in scaling and respond to them. For details on event sources, types, and payloads, refer to the EventBridge notifications section in the GitHub repo.
- Cool-down period management – Properly configure cool-down periods to prevent scaling oscillations where the cluster repeatedly scales out and scales in rapidly. Oscillations typically occur when traffic patterns have short-term spikes that don’t represent sustained demand. Oscillations can also happen when thresholds are set too close to normal operating levels. Set cool-down periods based on your workload characteristics and the scaling completion times. Also consider different cool-down periods for scale-out vs. scale-in operations by setting longer cool-down periods for scale-in operations (
scale_in_cooldown_minutes) compared to scaling out (scale_out_cooldown_minutes). Test cool-down settings under realistic load patterns before production deployment to achieve optimal performance. - Cost control through monitoring frequency – The solution incurs costs for services like Lambda functions, EventBridge schedules, CloudWatch metrics, and logs that are used in the solution. Both on-demand and scheduled scaling solutions work by running periodically to check the cluster health status and if a scaling operation needs to be performed. The default 1-minute monitoring frequency provides responsive scaling but increases other costs associated with the solution. Consider increasing the monitoring interval based on your workload characteristics to balance scaling responsiveness and the cost incurred by the solution. You can change the monitoring frequency by changing the monitoring_frequency_minutes when you deploy the solution.
- Solution isolation – The on-demand and scheduled scaling solutions were designed and tested in isolation to support predictable behavior and optimal performance. You can deploy either solution, but avoid running both solutions simultaneously on the same cluster. Using both approaches together can cause unpredictable scaling behavior where the solutions might conflict with each other’s scaling decisions, leading to resource contention and potential scaling oscillations. Choose the approach that best matches your workload patterns and deploy only one scaling solution per cluster.
Clean up
Follow these steps to delete the resources created by the solution. Make sure all the scaling operations that are in flight are completed before you run the cleanup.Delete the on-demand scaling solution with the following code:
Delete the scheduled scaling solution with the following code:
Summary
In this post, we showed how to use intelligent rebalancing to scale your Express based cluster based on your business requirements without requiring manual partition rebalancing. You can extend the solution to use the specific CloudWatch metrics that your business depends on to dynamically scale your Kafka cluster. Similarly, you can adjust the scheduled scaling solution to scale out and scale in your cluster when you anticipate significant change in traffic to your cluster at specific times.To learn more about the services used in this solution, refer to the following resources: