AWS Big Data Blog
Reducing costs for shuffle-heavy Apache Spark workloads with serverless storage for Amazon EMR Serverless
At re:Invent 2025, we announced serverless storage for Amazon EMR Serverless, eliminating the need to provision local disk storage for Apache Spark workloads. Serverless storage of Amazon EMR Serverless reduces data processing costs by up to 20% while helping prevent job failures from disk capacity constraints.
In this post, we explore the cost improvements we observed when benchmarking Apache Spark jobs with serverless storage on EMR Serverless. We take a deeper look at how serverless storage helps reduce costs for shuffle-heavy Spark workloads, and we outline practical guidance on identifying the types of queries that can benefit most from enabling serverless storage in your EMR Serverless Spark jobs.
Benchmark results for EMR 7.12 with serverless storage against standard disks
We conducted the performance and cost savings benchmarking using the TPC-DS dataset at 3TB scale, running 100+ queries that included a mix of high and low shuffle operations. The test configuration utilized Dynamic Resource Allocation (DRA) with no pre-initialized capacity. The system was set up with 20GB of disk space, and Spark configurations included 4 cores and 14GB memory for both driver and executor, with dynamic allocation starting at 3 initial executors (spark.dynamicAllocation.initialExecutors = 3). A comparative analysis was performed between local disk storage and serverless storage configurations. The aim was to assess both total and average cost implications between these storage approaches.
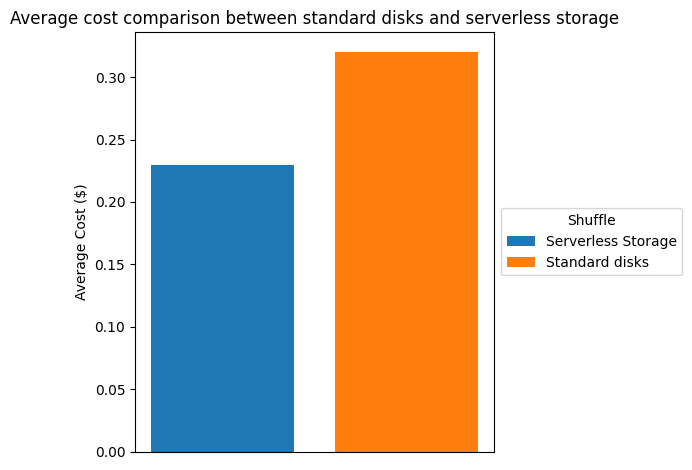
The following table and chart compare the cost reduction we observed in the testing environment described above. Based on us-east-1 pricing, we saw a cost savings of more than 26% when using serverless storage.
| Shuffle | |||
| serverless storage | standard Disks | savings | |
| Total Cost ($) | 24.28 | 33.1 | 26.65% |
| Average Cost ($) | 0.233 | 0.318 | 26.73% |
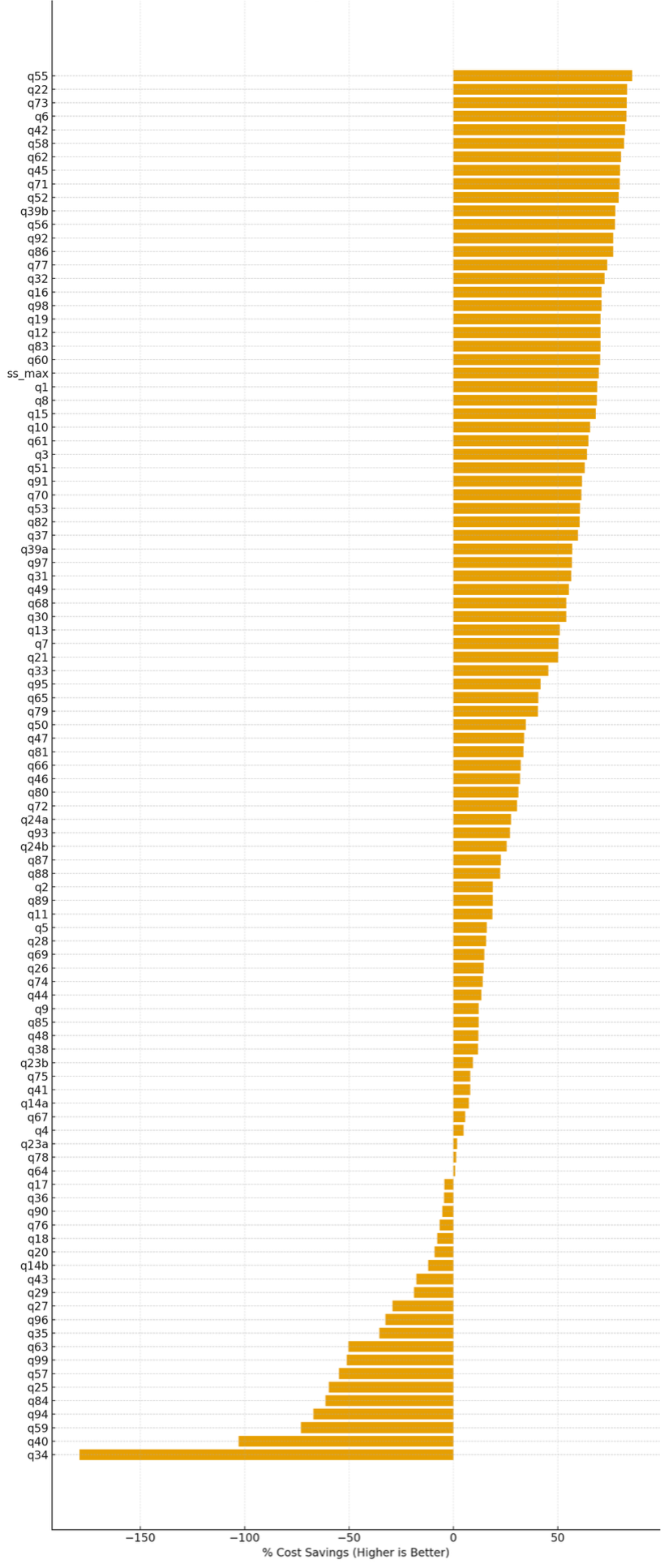
% Relative savings (per query) of serverless storage compared to standard disk shuffle
In this testing, we observed that serverless storage in EMR Serverless reduces cost for approximately 80% of TPC-DS queries. For the queries where it provides benefits, it delivers an average cost saving of approximately 47%, with savings of up to 85%. Queries that regress typically have low shuffle intensity, maintain high parallelism throughout execution, or complete quickly enough that executor scale-down opportunities are minimal. The following figure shows the percentage cost difference for each of the TPC-DS queries when serverless storage was enabled, compared to the baseline configuration without serverless storage. Positive values indicate cost savings (higher is better), while negative values indicate cost regressions.
Percentage cost savings per TPC-DS query with serverless storage enabled
Runtime comparison
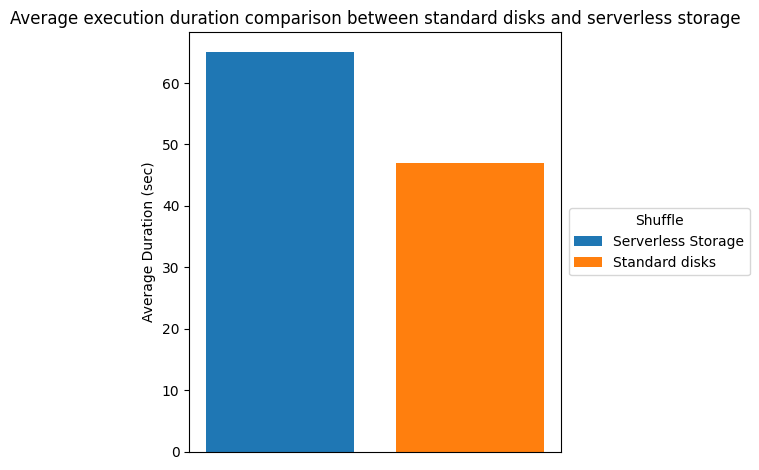
There is significant cost savings due to the increased elasticity from terminating executors earlier. However, job completion time may increase because the shuffle data is stored in serverless storage rather than locally on the executors. The additional read and write latency for shuffle data contributes to the longer runtime. The following table and chart show the runtime comparison, we observed in our testing environment.
| Shuffle | |||
| serverless storage | standard disks | runtime | |
| Total Duration (sec) | 6770.63 | 4908.52 | -37.94% |
| Average Duration (sec) | 65.1 | 47.2 | -37.92% |
Storing shuffle externally and decoupling from the compute allowed the flexibility for EMR Serverless to turn off unused resources dynamically as the state info has been offloaded from the compute. However, these cost savings can be realized only when DRA is on. If DRA is turned off, Spark would keep those unused resources alive adding to the total cost.
Query patterns that benefit from serverless storage
The cost savings from serverless storage depend heavily on how executor demand changes across stages of a job. In this section, we examine common execution patterns and explain which query shapes are most likely to benefit from serverless storage of EMR Serverless and which query patterns may not benefit from shuffle externalization.
Inverted triangle pattern queries
In order to understand why externalizing the shuffle data can allow such a significant cost savings, consider a simplified query. The following query calculates annual total sales from the TPC-DS dataset by joining the store_sales and date_dim tables, summing the sales amounts per year, and ordering the results.
This query demonstrates that high executor demand during the map phase and low executor demand in the reduce phase is an aggregation query with a high cardinality input and a low cardinality group by.
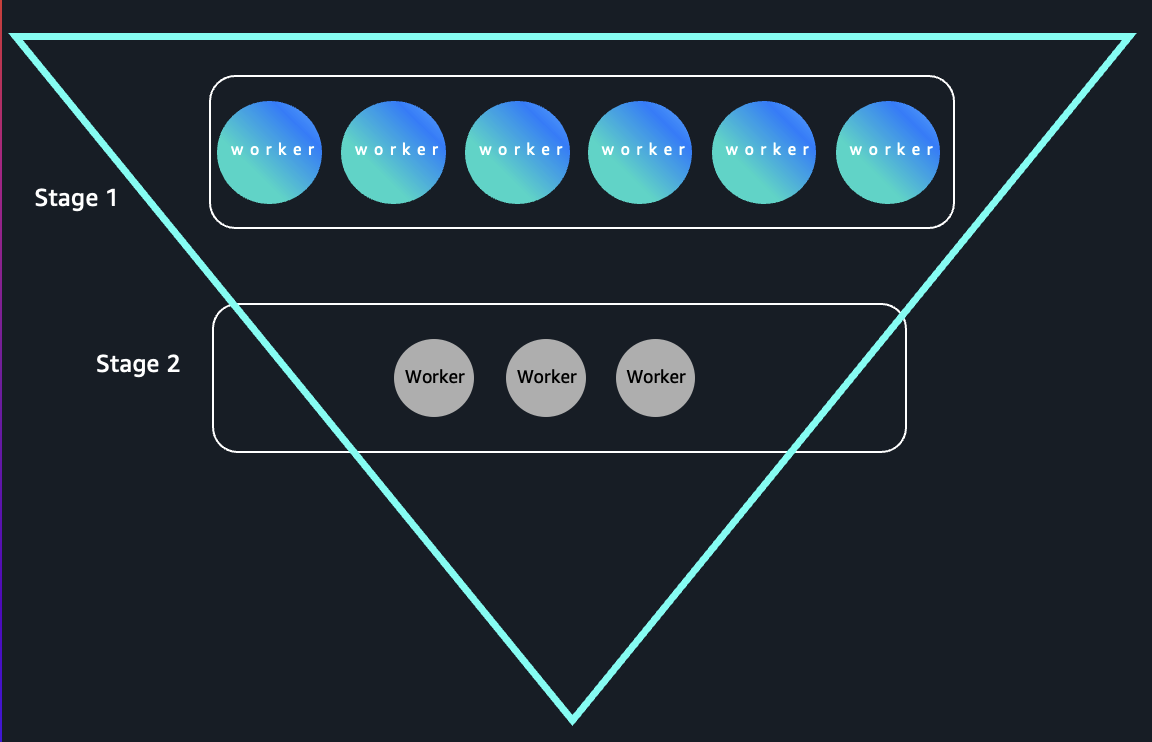
- Stage 1 (High Executor Demand)
The join and read steps scan the entire store_sales and date_dim tables. This often involves billions of rows in large-scale TPC-DS datasets, so Spark will try to parallelize the scan across many executors to maximize read throughput and compute efficiency.
- Stage 2 (Low Executor Demand)
The aggregation is on d_year, which typically has few unique values, such as only a handful of years in the data. This means after the shuffle stage, the reduce phase combines the partial aggregates into a number of keys equal to the number of years (often < 10). Only a few Spark tasks are needed to finish the final aggregation, so most executors become idle.
With shuffle information stored on the local disk, the compute resources associated with these idle executors would still be running in order to keep the shuffle data available. With shuffle data offloaded from the nodes running the executors, with DRA enabled, those nodes with idle executors get released immediately.
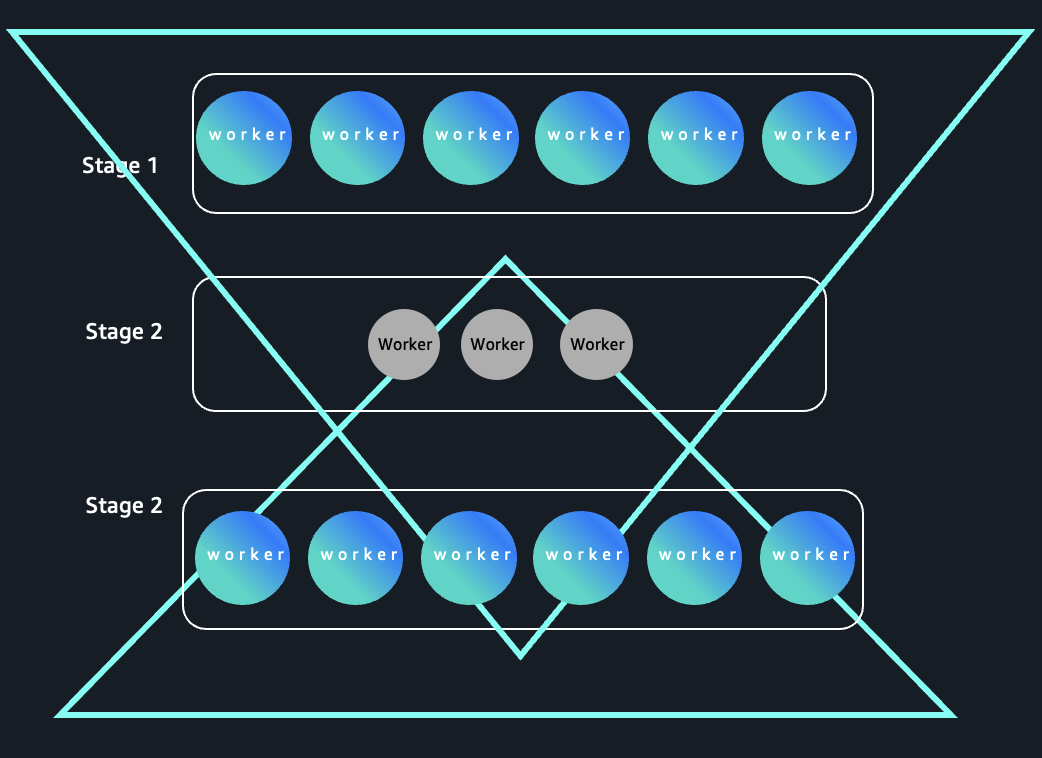
Because early stages process high-cardinality inputs and later stages collapse data into a small number of keys, these queries form an “inverted triangle” execution pattern: wide parallelism at the top and narrow parallelism at the bottom as shown in the following image:
Hourglass pattern queries
Depending upon the complexity of the job, there can be multiple stages with varying demand on number of executors needed for the stage. Such jobs can benefit from greater elasticity obtained by offloading shuffle data to external serverless storage. One such pattern is the hour glass pattern. The following figure shows a workload pattern where executor demand expands, contracts during shuffle-heavy stages, and expands again. Serverless storage of EMR Serverless decouples shuffle data from compute, enabling more efficient scale-down during narrow stages and helping improve cost optimization for elastic workloads.
Hourglass pattern in Spark stage execution
To identify queries of this category, consider the following example, The query progresses through three stages:
- Stage 1: The initial join and filter between
store_salesanditemproduces a wide, high-cardinality intermediate dataset, requiring high parallelism (many executors). - Stage 2: Aggregation groups by a small set of categories such as “Home” or “Electronics”, resulting in a drastic drop in output partitions. So this stage efficiently runs with only a few executors, as there’s little data to parallelize.
- Stage 3: The small result is joined (usually a broadcast join) back to a large fact table with a date dimension, again producing a large result that is well-parallelized, causing Spark to ramp up executor usage for this stage.
This pattern is common for reporting and dimensional analysis scenarios and is effective for demonstrating how Spark dynamically adjusts resource usage across job stages based on cardinality and parallelism needs. Such queries can also benefit from the elasticity enabled by external serverless storage.
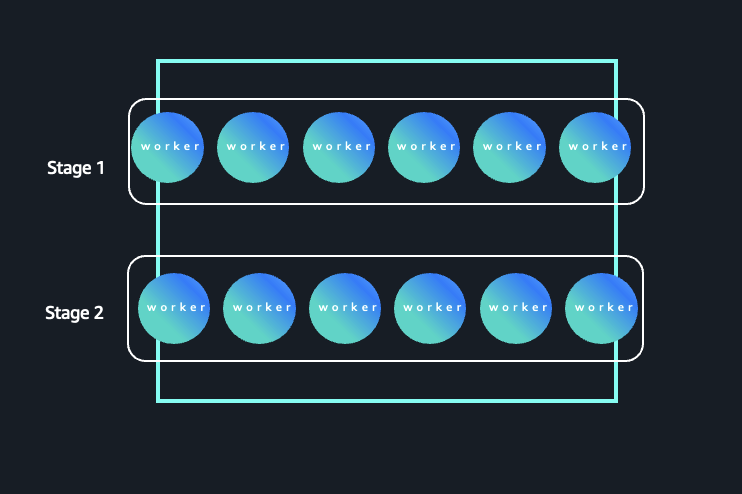
Rectangle pattern queries
Not all queries benefit from externalizing the shuffle. Consider a query where the cardinality is high throughout, meaning both the stages operate on a large number of partitions and keys. Typically, queries that group by high-cardinality columns (such as item or customer) cause most stages to require similar amounts of parallelism. The following figure illustrates a Spark workload where parallelism remains consistently high across stages. In this pattern, both Stage 1 and Stage 2 operate on a large number of partitions and keys, resulting in sustained executor demand throughout the job lifecycle.
High-cardinality execution pattern with sustained parallelism
The following query is the same query that we used in the inverted triangle pattern earlier, with one change. We have replaced the dim_date table (low cardinality) with item (high cardinality).
- Stage 1: Reads the rows from
store_salesand joins withitem, spreading data across many partitions—similar to the original query’s first stage. - Stage 2: The aggregation is by
i_item_id, which normally has thousands to millions of distinct values in real datasets. This keeps parallelism high; many tasks handle non-overlapping keys, and shuffle outputs remain large.
There is no significant drop in cardinality: Because neither stage is reduced to a small group set, most executors stay busy throughout the job’s main phases, with little idle time even after the shuffle. This type of query results in a flatter executor utilization profile because each stage processes a similar volume of work, thus minimizing variation in resource utilization. These rectangle pattern queries will not see the cost benefit from the elasticity obtained by offloading shuffle data. However, there may still be other benefits such as reduction of job failures and performance bottlenecks from disk constraints, freedom from capacity planning and sizing, and provisioning of storage for intermediate data operations.
Conclusion
Serverless storage for Amazon EMR Serverless can deliver substantial cost savings for workloads with dynamic resource patterns, as seen in the 26% average cost savings we observed in our testing environment. By externalizing shuffle data, you can gain the elasticity to release idle executors immediately, demonstrated by the savings reaching up to 85% in our testing environment, on queries following inverted triangle and hourglass patterns when Dynamic Resource Allocation is enabled.Understanding your workload characteristics is key. While rectangle pattern queries may not see dramatic cost reductions, they can still benefit from improved reliability and removal of capacity planning overhead.
To get started: Analyze your job execution patterns, enable Dynamic Resource Allocation, and pilot serverless storage on shuffle-heavy workloads. Looking to reduce your Amazon EMR Serverless costs for Spark workloads? Explore serverless storage for EMR Serverless today.