AWS Big Data Blog
Use Spark 2.0, Hive 2.1 on Tez, and the latest from the Hadoop ecosystem on Amazon EMR release 5.0
Jonathan Fritz is a Senior Product Manager for Amazon EMR
We are excited to launch Amazon EMR release 5.0 today, giving customers the latest versions of 16 supported open-source applications in the big data ecosystem, including new major versions of Spark and Hive.
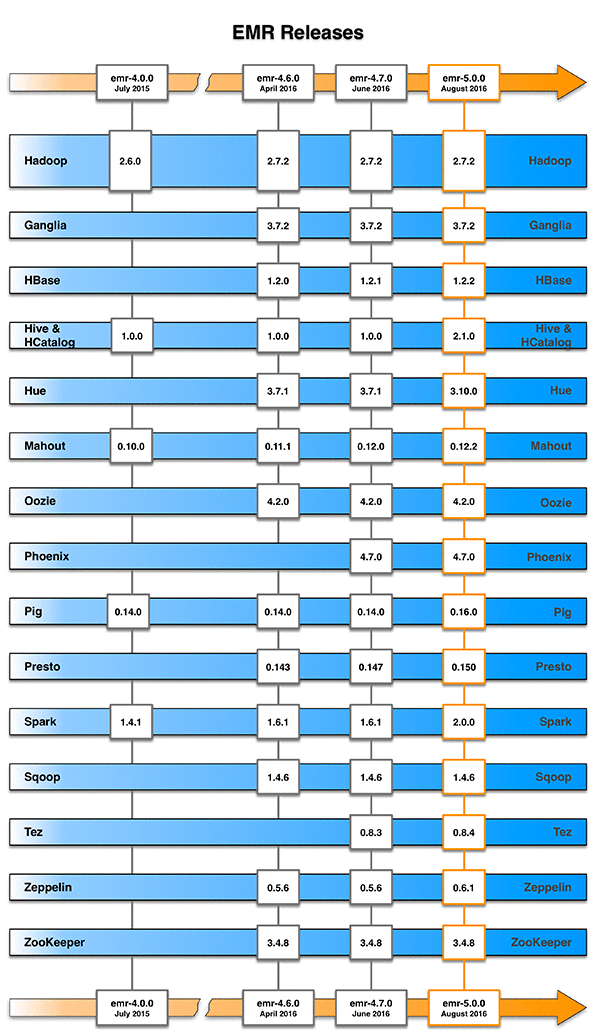
Almost exactly a year ago, we shipped release 4.0, which brought significant improvements to EMR. We based our build and packaging system on Apache Bigtop, moved to standard ports and paths, and streamlined application configuration with configuration objects. Our initial 4.0 release consolidated our set of supported Apache big data applications to Apache Hadoop, Apache Spark, Apache Hive, Apache Pig, and Apache Mahout.
Over the subsequent months, EMR added support for additional open-source projects, unlocking various use cases such as low-latency SQL over datasets in Amazon S3 with Presto, real-time data access and SQL analytics with Apache HBase and Phoenix, collaborative analysis for data science with notebooks in Apache Zeppelin, and designing complex processing workflows with Apache Oozie.
Also, we kept versions of most major projects up-to-date with each EMR release, such as offering the latest version of Spark just a few weeks after the open source release. Each new version of a project had many performance improvements, new features, and bug fixes, and customers demanded these improvements quickly to support their big data architectures.
EMR release 5.0 is a milestone in delivering the most up-to-date, complete selection of open-source applications in the Hadoop ecosystem to our customers:
- Upgrade to Spark 2.0 a week after the Apache release, giving customers access to improved SQL support, significant performance increases, the new Structured Streaming API, and enhanced SparkR support. We have also compiled it with Scala 2.11.
- Upgrade from Hive 1.x to Hive 2.1, which includes a variety of performance enhancements, better Parquet file format support, and bug fixes.
- Trade Hadoop MapReduce for Tez as the default execution engine for Hive and Pig, signaling a greater move from traditional Hadoop MapReduce to newer frameworks like Tez and Spark.
- Add the newest versions of Hue and Zeppelin, notebook and query UIs for Hadoop ecosystem applications, enable data scientists and business intelligence analysts to interact with data even more easily and efficiently.
- Upgrade all sandbox applications are now release on EMR.
- Use the latest versions of all supported applications: Hadoop 2.7.2, Spark 2.0, Presto 0.150, Hive 2.1, Tez 0.8.4, Pig 0.16, HBase 1.2.2, Phoenix 4.7.0, Zeppelin 0.6.1 (Snapshot), Hue 3.10, Oozie 4.2.0, Sqoop 1.4.6, Ganglia 3.7.2, HCatalog 2.1.0, Mahout 0.12.2, and ZooKeeper 3.4.8.
If you have any questions about release 5.0, feedback, or would like to share an interesting use case that leverages these applications, please leave a comment below.
You can also join our live webinar, Introducing Amazon EMR Release 5.0, at 9AM PDT on Tuesday, August 23.