AWS Compute Blog
Best practices for Lambda durable functions using a fraud detection example
AWS Lambda durable functions extend the Lambda programming model to build fault-tolerant multi-step applications and AI workflows using familiar programming languages. They preserve progress despite interruptions and execution can suspend for up to one year, for human approvals, scheduled delays, or other external events, without incurring compute charges for on-demand functions.
This post walks through a fraud detection system built with durable functions. It also highlights the best practices that you can apply to your own production workflows, from approval processes to data pipelines to AI agent orchestration. You will learn how to handle concurrent notifications, wait for customer responses, and recover from failures without losing progress. If you are new to durable functions, check out the Introduction to Durable Functions blog post first.
Fraud detection with human-in-the-loop
Consider a credit card fraud detection system, which uses an AI agent to analyze incoming transactions and assign risk scores. For ambiguous cases (medium-risk scores), the system needs human approval before authorizing a transaction. The workflow branches based on risk:
- Low risk (score < 3): Authorize immediately
- High risk (score ≥ 5): Send to the fraud department immediately
- Medium risk (score 3–4): Suspend transaction, send SMS and email to cardholder, wait up to 24 hours for confirmation (wait time is customizable)
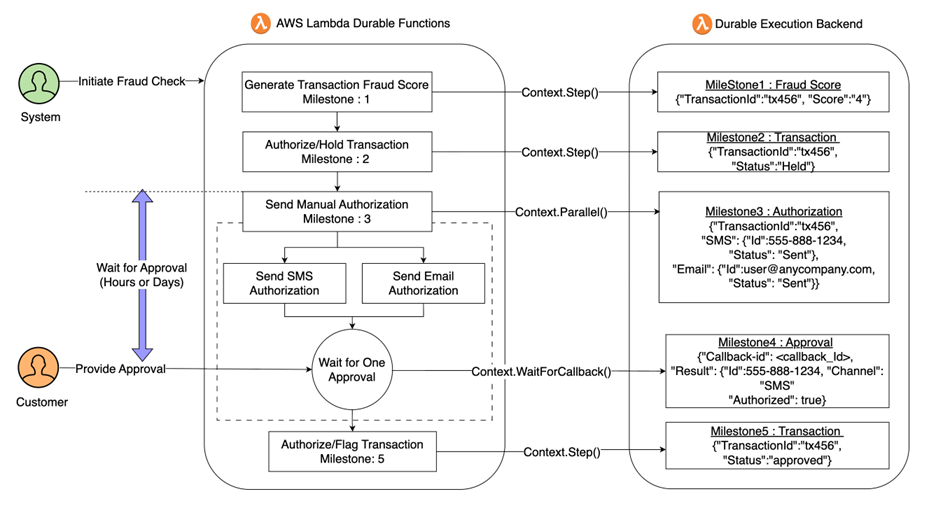
Figure 1. Agentic Fraud Detection with durable Lambda functions
With human-in-the-loop workflows, response times can vary from minutes to hours. These delays introduce the need to durably preserve the state without consuming compute resources while waiting. With financial systems, we must also implement idempotency to guard against duplicate messages (invocations) and recover from failures without reprocessing completed work. To address these requirements, developers implement polling patterns with external state stores like Amazon DynamoDB or Amazon Simple Storage Service (Amazon S3) to manage idempotency, pay for idle compute while waiting for callbacks, introduce external orchestration components, or build asynchronous message-driven systems to handle long-processing tasks.
Lambda durable functions provide a new alternative to address these challenges through durable execution, a pattern that uses checkpoints (saved state snapshots) to preserve progress and replays from saved state to recover from failures or resume after waiting. With checkpointing capabilities, you no longer need to pay Lambda compute charges while waiting, whether for callbacks, scheduled delays, or external events. Learn how to implement durable functions using the complete fraud detection implementation at this GitHub repository. You can deploy it to your AWS account and experiment with the code as you read. The repository includes deployment instructions, sample data, and helper functions for testing.
As we walk through the code, we’ll focus on best practices for designing workflows with durable execution and how to apply these patterns correctly in production workflows.
Design steps to be idempotent
Durable execution is designed to preserve progress through checkpoints and replay, but that reliability model means step logic can execute more than once. When steps retry, how do you prevent duplicate actions like charges to the credit card or repeated customer SMS or email notifications?
Durable functions use at-least-once execution by default, executing each step at least one time, potentially more if failures occur. When a step fails, it retries. There are two strategies to design idempotent steps that prevent duplicate side effects: using external API idempotency keys and using the at-most-once step semantics built into durable functions.
Strategy A: External API Idempotency Keys
Notice the configuration:
- idempotency_key in API call: If the step retries, the payment processor recognizes it’s a duplicate request and returns the original result
- Defense in depth: Two layers of protection: Lambda checkpointing and external API idempotency
Each layer provides independent protection. If Lambda’s checkpoint fails, the external API prevents duplicate charges. For legacy systems without idempotency support, where it’s critical that an operation is not executed more than once, use at-most-once semantics:
Strategy B: Use At-Most-Once Semantics
For legacy systems without idempotency support, use at-most-once execution, a delivery feature that executes each step zero or one time, never more:
This checkpoints before step execution, preventing the step from re-execution on retries. The tradeoff? If the step fails, you must decide whether to retry (risking duplicates) or fail the entire workflow.
Use idempotency for critical side effects like payment processing, database writes, external API calls, state transitions, and resource provisioning. Read more about idempotency here.
Prevent duplicate executions with DurableExecutionName
Idempotent steps prevent duplicate side effects within a single execution, but what about duplicate workflow executions running concurrently? For example, duplicate messages in the queue, users clicking “Submit” multiple times in the UI, or the same event arriving via multiple channels like webhook and API. Without protection, each invocation creates a separate durable execution, potentially running the fraud check multiple times, sending duplicate notifications, and creating confusion about which execution is authoritative. Durable functions provide DurableExecutionName to help ensure only one concurrent execution per unique name.
Notice the configuration:
- DurableExecutionName: tx-${transactionId}: Uses the transaction ID as a unique execution identifier
- InvocationType: ‘Event’: Asynchronous invocation supports long-running workflows beyond 15 minutes
- One execution per transaction: If three invocations arrive with the same transaction ID, only the first creates an execution. Subsequent requests with the same execution name and payload receive an idempotent response returning the existing execution’s ARN, rather than creating a new execution.
Lambda durable functions work with Lambda event sources, including event source mappings (ESM) such as Amazon Simple Queue Service (Amazon SQS), Amazon Kinesis, and DynamoDB Streams. ESMs invoke durable functions synchronously and inherit Lambda’s 15-minute invocation limit. Therefore, like direct Request/Response invocations, durable functions executions using event source mappings cannot exceed 15 minutes.
For workflows exceeding 15 minutes, use an intermediary Lambda function between the event source mapping and durable function:
This removes the 15-minute limit, allows executions up to one year, and enables custom execution name parameters for idempotency. Use Powertools for AWS Lambda to prevent duplicate invocations of the durable function when the event source mapping retries the intermediary function. Additionally, configure failure handling for your event source to capture failed invocations for future redrive or replay. For example, dead letter queues for SQS, or on-failure destinations for other event sources.
Match timeouts to invocation type
One important configuration detail ties these patterns together: matching your timeout settings to your invocation type. Lambda synchronous invocations (RequestResponse) have a hard 15-minute timeout limit. If you configure a durable execution to run for 24 hours but invoke it synchronously, the synchronous invocation fails immediately with an exception. Durable functions support workflows up to one year when invoked asynchronously.
And invoke asynchronously:
Notice the configuration:
- Timeout: 300: Lambda function timeout (5 minutes in this example, up to a maximum of 15 minutes). This defines the maximum duration for each active execution phase, including the initial invocation and any subsequent replays. Set this to cover the longest expected active processing time in your workflow.
- ExecutionTimeout: { hours: 25 }: Durable execution timeout covers the workflow’s expected total duration including suspension periods. Set this slightly above the longest wait timeout to avoid edge cases.
- InvocationType: ‘Event’: Asynchronous invocation removes the 15-minute limit and enables executions up to one year.
The Lambda function timeout applies to active execution phases (AI calls, notification sending). During suspension (waiting for callbacks), the function isn’t running, so this timeout doesn’t apply. Setting the durable execution timeout to a meaningful boundary prevents workflows from running longer than expected. Without an explicit timeout, executions can run up to the maximum lifetime of one year.
| Synchronous (RequestResponse) | Asynchronous (Event) | |
| Total duration | Under 15 minutes | Up to 1 year |
| Caller needs result | Yes | No |
| Idempotency support | Yes | Yes |
| Waits with suspension | Yes | Yes |
Execute Concurrent Operations with context.parallel()
In the fraud detection workflow, the system notifies the cardholder through multiple channels such as SMS and email. Preserving business logic when executing parallel workflows introduces code complexities such as managing execution state across branches, handling synchronization, and coordinating branch completion. Durable functions simplify parallel workflow implementation using context.parallel(), which executes branches concurrently while maintaining durable checkpoints for each branch and provides configurable options to handle partial completions. By checkpointing and managing the state internally, durable functions help make sure that the state is preserved even if there are retries or failures. Note that context.parallel() manages the internal execution state for each branch. If your branches interact with a shared external state (such as a database), you’re responsible for managing concurrent access to that external state.
Notice the configuration:
- maxConcurrency: 2: Both notifications sent at the same time
- minSuccessful: 1: We only need one channel to succeed, whichever responds first wins
Each parallel branch waits for its callback independently, and the durable execution checkpoints each branch as part of the execution state. Using the minSuccessful parameter, you control the minimum number of successful branch executions required for the parallel operation to complete. In this example, only one of the two branches needs to succeed. Verifications through SMS or email are both valid, and the workflow resumes as soon as either channel completes successfully. We call this the first-response-wins pattern. This pattern works well when you only need a single successful result from any parallel branch and want the remaining branches to stop blocking progress.
But what happens if neither channel responds? Without timeouts, this workflow could remain suspended for up to the configured execution lifetime.
Always configure callback timeouts
Let’s add timeout protection to the parallel verification from the previous section. context.waitForCallback() accepts a timeout option that bounds how long each branch waits before throwing an exception. By wrapping the parallel call in a try/catch, you can implement fallback logic when users don’t respond in time.
Notice what changed from the previous section:
- timeout: { days: 1 }: Each callback branch now has a maximum wait time of 1 day. If neither the email nor SMS callback arrives within that window, a timeout exception is thrown.
- try/catch with timeout detection: The catch block distinguishes between timeout errors and other exceptions. When a timeout occurs, the workflow implements fallback logic by escalating the transaction to the fraud department, while non-timeout errors are re-thrown to be handled by the durable execution retry mechanism.
Without this error handling, the entire execution fails unhandled. The timeout also works with the minSuccessful configuration: if one branch times out but the other succeeds, the parallel operation still completes successfully since only one successful result is required.
For advanced use cases where the callback handler performs long-running work, you can also configure a heartbeatTimeout to detect stalled callbacks before the main timeout expires. See the Lambda Developer Guide for details.
Use callback timeouts for human approvals, external API callbacks, asynchronous processing, and third-party integrations.
Putting it all together: complete fraud detection implementation
Now let’s see how all the best practices work together in the complete fraud detection workflow:
Notice how the best practices work together: context.parallel() sends SMS and email concurrently, resuming when either channel responds. Both callbacks configure 1-day timeouts with try/catch handling that escalates on timeout. The DurableExecutionName: tx-${transactionId} parameter (specified at invocation time, shown in the following CLI example) provides execution-level deduplication, while idempotency keys in the authorization steps prevent duplicate charges at the application layer. Asynchronous invocation (InvocationType: 'Event') enables the 24-hour wait period.
Once deployed, invoke the function asynchronously with a sample transaction to see it in action:
Upon successful invocation, you can view the execution state in the Lambda console’s durable operations view. The execution shows a suspended state, waiting for customer response:
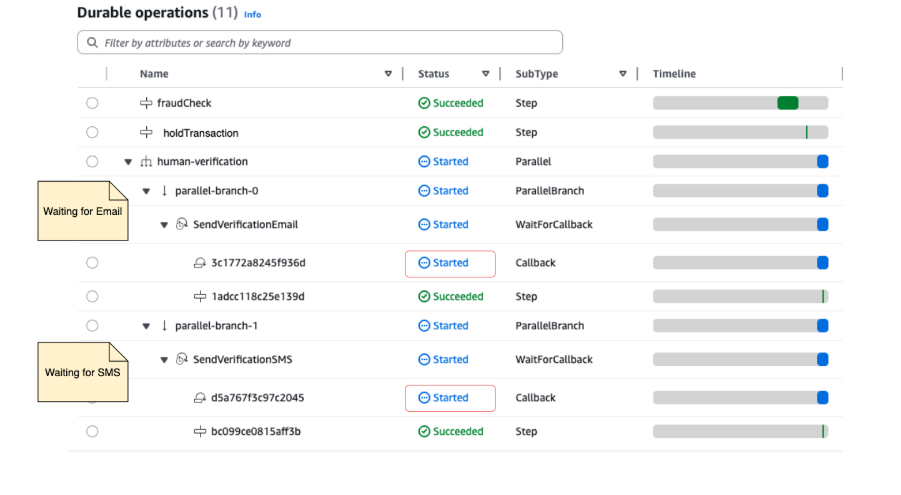
Figure 2: Suspended execution state
Notice the fraudCheck and suspendTransaction steps show as succeeded with checkpointed results. The human-verification parallel operation shows that both SMS and email branches started. The timeline shows the function in a suspended state. Simulate a customer response by sending a callback success through the console, AWS Command Line Interface (AWS CLI) or Lambda API:
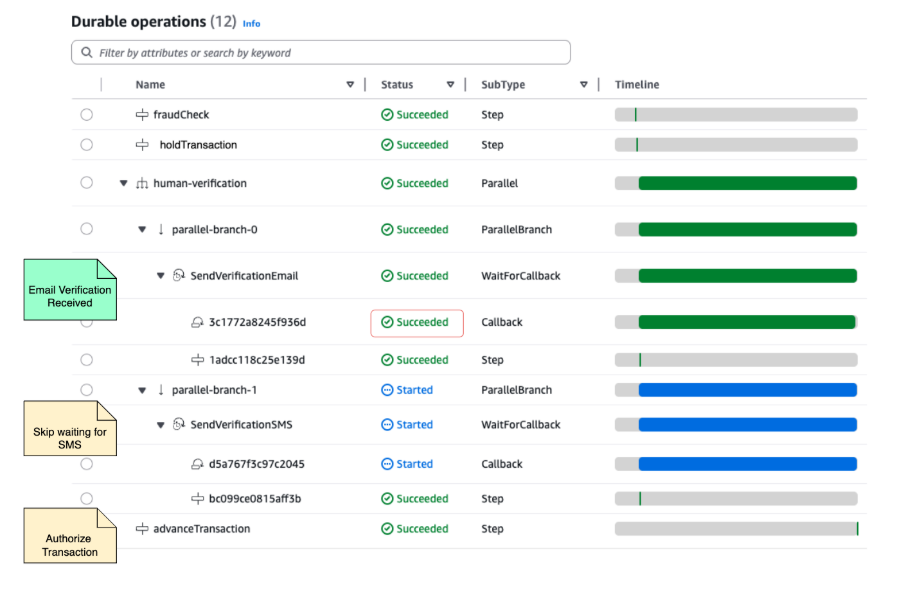
Figure 3: Completed execution with customer approval
After receiving the customer’s approval, the durable execution resumes from its checkpoint, authorizes the transaction, and completes. The execution spanned hours but consumed only seconds of compute time.
Conclusion
With durable functions, Lambda extends beyond single-event processing to power core business processes and long-running workflows, while retaining the operational simplicity, reliability, and scale that define Lambda. You can build applications that run for days or months, survive failures, and resume where they left off, all within the familiar event-driven programming model.
Deploy the fraud detection workflow from our GitHub repository and experiment with human-in-the-loop patterns in your own account. For core concepts, see Introduction to AWS Lambda Durable Functions. For comprehensive documentation, see the Lambda Developer Guide. Browse Serverless Land for reference architectures and discover where durable execution fits in your designs.
Share your feedback, questions, and use cases in the SDK repositories or on re:Post.